目录:
T1:马农
T2:马语翻译
T3:马球比赛
T4:数列
回归正题:
T1:马农
题目描述
在观看完战马检阅之后,来自大草原的两兄弟决心成为超级“马农”,专门饲养战马。
兄弟两回到草原,将可以养马的区域,分为 N*N 的单位面积的正方形, 并实地进行考察,归纳出了每个单位面积可以养马所获得的收益。接下来就要开始规划他们各自的马场了。
首先,两人的马场都必须是矩形区域。同时,为了方便两人互相照应,也为了防止马匹互相走散,规定两个马场的矩形区域相邻,且只有一个交点。最后,互不认输的两人希望两个马场的收益相当,这样才不会影响他们兄弟的感情。
现在,兄弟两找到你这位设计师,希望你给他们设计马场,问共有多少种设计方案。
输入
第一行一个整数 N,表示整个草原的大小为 N*N。
接下来 N 行,每行 N 个整数 A(i,j),表示第 i 行第 j 列的单位草地的收成。
(注意:收益可能是负数,养马也不是包赚的,马匹也可能出现生病死亡等意外。)
输出
输出符合两人要求的草原分配方案数。
样例输入
3
1 2 3
4 5 6
7 8 9
样例输出
2
分析:
1.穷举每个矩形的交点,每个交点会把整个区域划分成四块。
2.分别穷举每个区域里的矩形,注意矩形的一个顶点一定为交点。
3.记录收益值,找出对应区域相等收益的个数。
4.加一点优化。
CODE:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
typedef long long LL;
using namespace std;
int n,a[55][55];
int ans,x,flag,head;
int h[2500000*2+10],st[55*55];
int main()
{
freopen("farmer.in","r",stdin);
freopen("farmer.out","w",stdout);
while(~scanf("%d",&n))
{
memset(sum,0,sizeof(sum));
ans=head=0;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
scanf("%d",&x);
a[i][j]=a[i][j-1]+a[i-1][j]-a[i-1][j-1]+x;
}
}
for(int i=1;i<n;i++)
{ //这两个for穷举了交点
for(int j=1;j<n;j++)
{
for(int k=1;k<=i;k++)
{ //这两个是穷举区域里面的矩形
for(int l=1;l<=j;l++)
{ //共四重for,不会超时放心
flag=a[i][j]+a[k-1][l-1]-a[k-1][j]-a[i][l-1]+2500000;
st[head++]=flag;
h[flag]++;
}
}
for(int k=i+1;k<=n;k++)
{
for(int l=j+1;l<=n;l++)
{
flag=a[i][j]+a[k][l]-a[k][j]-a[i][l]+2500000;
ans+=h[flag];
}
}
while(head)
h[st[--head]]=0; //用一个栈清空,数组会超时
for(int k=i+1;k<=n;k++)
{
for(int l=1;l<=j;l++)
{
flag=a[i][l-1]+a[k][j]-a[i][j]-a[k][l-1]+2500000;
st[head++]=flag;
h[flag]++;
}
}
for(int k=1;k<=i;k++)
{
for(int l=j+1;l<=n;l++)
{
flag=a[i][l]+a[k-1][j]-a[k-1][l]-a[i][j]+2500000;
ans+=h[flag];
}
}
while(head)
h[st[--head]]=0;
}
}
printf("%d\n",ans);
}
}
T2:马语翻译
题目描述
随着马场的繁荣,出现了越来越多的新马种。种族之间的沟通不畅严重影响了马场的和谐。这时,科学家发明了马语翻译机器人,正好可以解决这一难题。
机器人有 M 种,每种机器人能完成 K 个马种之间的语言翻译。问,利用这些机器人,能否实现 1 种群和 N 种群的马语翻译。 若可以,找到翻译过程至少需要用到多少种语言。
输入
第一行三个整数 N, K 和 M,分别表示语言数, 每个机器人能翻译的语言数, 机器人的数量。
接下来 M 行,每行 K 个整数。表示每个机器人可以翻译的语言编号(编号从 1 到 N)。
输出
输出最少转换语言的次数。如果无法完成翻译,输出-1。
样例输入
9 3 5
1 2 3
1 4 5
3 6 7
5 6 7
6 8 9
样例输出
4
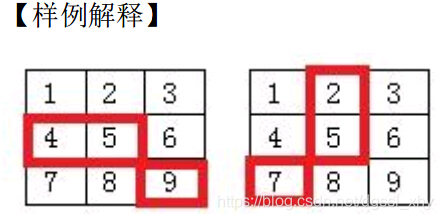
【样例解释】
1-3-6-9 或者 1-5-6-9
分析:
这道题挺简单的扒……
好多人写最短路,就我写BFS?
就是建图,遍历图,求出从语言1到语言n之间节点的个数。
结果就是点的个数/2+1.
一定要加快读快写,我没加40分,加了100分。
CODE:
#include<algorithm>
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
int n,k,m,cnt,q[101005],dis[101005],lnk[101005],son[2000005],nxt[2000005];
bool vis[101005];
inline int read()
{
int ret = 0,w = 0;
char ch = 0;
while(!isdigit(ch))
{
w |= ch == '-';
ch = getchar();
}
while(isdigit(ch))
{
ret = (ret << 3) + (ret << 1) + (ch ^ 48);
ch = getchar();
}
return w ? -ret : ret;
} //快读快写
inline void write(int ret)
{
if(ret < 0)
{
putchar('-');
ret = -ret;
}
if(ret > 9)
write(ret / 10);
putchar(ret % 10 + '0');
}
void add(int x,int y)
{ //建立邻接表
son[++cnt] = y;
nxt[cnt] = lnk[x];
lnk[x] = cnt;
}
void bfs()
{ //广搜实现遍历
int head = 0,tail = 1;
q[1] = 1;
vis[1] = 1;
while (head<tail)
{
int x = q[++head];
for (int j = lnk[x];j;j = nxt[j])
if (!vis[son[j]])
{
vis[son[j]] = 1;
dis[son[j]] = dis[x] + 1; //记录
q[++tail] = son[j];
}
}
}
int main()
{
freopen("trans.in","r",stdin);
freopen("trans.out","w",stdout);
n=read();
k=read();
m=read();
for (int i = 1;i <= m;i++)
for (int j = 1;j <= k;j++)
{
int x;
x=read();
add(x,i + n);
add(i + n,x);
//语言之间连一条路
}
bfs();
if (vis[n])
write((dis[n]>>1) + 1); //节点数/2+1,位运算(>>1)更快
else
write(-1);
return 0;
}
T3:马球比赛
题目描述
在解决了马语翻译问题后,马匹数量越来越多,不少乡镇都有了数量可观的马匹,开始出现马球比赛。乡镇之间决定进行马球联赛。
联赛的赛制,主要是比赛双方的马匹数量,成了一个急需解决的问题。首先,所有乡镇都要求,本乡镇所有的马匹都必须参赛,或者都不参赛(若组队的马匹数量不是该镇马匹数量的约数,将无法参赛)。其次,在本乡镇,选出最佳球队,参加乡镇间联赛。
现在,比赛组织方希望满足所有参赛乡镇的要求,并且使得决赛的马匹尽可能多,请你设计每个球队马匹的数量,使得决赛马匹数最大。注意,决赛至少有 2 个队伍晋级。
输入
第一行一个整数 N,表示想要报名参赛的乡镇。
接下来 N 个用空格分开的整数 a(i),表示第 i 个乡镇报名参赛的马匹数。
输出
计算出决赛最大参与的马匹数。
样例输入
【输入样例 1】
3 1 3 6
【输入样例 2】
5 4 6 3 8 9
样例输出
【输出样例 1】
6
【样例解释】 每个队伍 3 匹马,乡镇 1 无法参赛。乡镇 2 和 3 都可以进行比赛,决赛 2 个队伍,共 6匹马。
【输出样例 2】
9
【样例解释】 每个队伍 3 匹马,乡镇 2,3,5 可以参赛。决赛 3 个队伍, 9 匹马。
分析:
这题呢,其实可以递推
首先设f[i]表示以i为参赛标准时,有多少只队伍能参赛。
可以推出:
f[j]=f[j]+f[i] j为i的约数
同理,f[i / j]=f[i / j]+f[i]
然后容易被卡常,就自行脑补
时间复杂度:O(max(a[i])*Σtrunc(sqrt(i)))
i为1~max(a[i])
还是要加快读快写,不加我就70分,加了就100分。
CODE:
#include<cmath>
#include<iomanip>
#include<algorithm>
#include<cstring>
#include<cstdio>
#include<iostream>
using namespace std;
typedef long long LL;
inline int read()
{
int ret = 0,w = 0;
char ch = 0;
while(!isdigit(ch))
{
w |= ch == '-';
ch = getchar();
}
while(isdigit(ch))
{
ret = (ret << 3) + (ret << 1) + (ch ^ 48);
ch = getchar();
}
return w ? -ret : ret;
} //快读快写函数
inline void write(int ret)
{
if(ret < 0)
{
putchar('-');
ret = -ret;
}
if(ret > 9)
write(ret / 10);
putchar(ret % 10 + '0');
}
int f[2000010],p[2000010];
int n,x,y,cmax,maxx;
int main(){
freopen("polo.in","r",stdin);
freopen("polo.out","w",stdout);
n=read();
cmax=0; //优化循环次数的变量
for(int i=1;i<=n;i++)
{
f[i]=read();
p[f[i]]++;
cmax=max(cmax,f[i]); //找最大的
}
maxx=n;
if(cmax==2000000) cmax/=20;
for(int i=2;i<=cmax;i++)
{
if(p[i]!=0)
{
for(int j=2;j<=sqrt(i);j++) //j*j<=i也行
{
if(i%j==0) //约数
{
p[j]+=p[i];
if(j*j!=i)
{
p[i/j]+=p[i]; //同理
}
}
}
}
}
if(cmax==100000) cmax*=20;
for(int i=2;i<=cmax;i++)
{
if(p[i]>1) maxx=max(maxx,p[i]*i);
}
write(maxx);
return 0;
}
T4:数列
题目描述
给定一个长度为N的数列,求一段连续的子数列满足该子数列中的各元素的平均数大于A,输出可行方案的总数。
输入
第一行两个整数N,A
接下来N个整数,代表数列的N个元素。
输出
一个整数,即可行的方案数。
样例输入
5 1
1 2 3 4 5
样例输出
14
分析:
其实对于每一次的输入的数rp[i],我们都将它减去平均数m,然后全部做一遍前缀和。
首先我们知道对于某个前缀和sum[i],如果它>0就先给答案+1
然后如果sum[i] < sum[j],i < j就代表在区间[l,r]内的总和是绝对比m大的,就累加1
然后我们怎么去处理sum[j]>sum[i]的情况呢,我们发现如果强行去枚举
时间复杂度就是O(Σ N),很明显会炸时间
然后我们可以想到树状数组,
先将处理出来的sum全部离散,因为离散后其的大小关系如sum[i] < sum[j]是不变的,然后离散后其的最坏情况最大值就是N,即100000,树状数组就只需要开到100000了,
然后枚举sum,
每次对于一个sum[i]
ans累加其树状数组中1~i-1的值,用x-x & (-x)去递减
然后将这个数丢进树状内
用x+x & (-x)去 递加,tree[x]=tree[x]+1
然后这样的时间复杂度就做到了O(N log N)
CODE:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
typedef long long LL;
LL d[100001],rp[100001],sum[100001],f[100001];
LL x,i,j,n,m,pd;
LL ans;
int main()
{
//freopen("sequence.in","r",stdin);
//freopen("sequence.out","w",stdout);
scanf("%d%d",&n,&m);
ans=0;
for(i=1;i<=n;i++)
{
scanf("%d",&rp[i]);
rp[i]-=m; //先减一次
sum[i]=sum[i-1]+rp[i]; //前缀和
if(sum[i]>0) ans++; //>0,先++ans
d[i]=i; //记录位置
}
sort(sum,sum+n+1); //排序前缀和
for (int i=1;i<=n;i++)
{
if (sum[i]!=pd||i==1) x++;
pd=sum[i];
sum[i]=x;
}
sort(d,d+n+1); //排序位置
for (int i=1;i<=n;i++)
{
for (int j=sum[i]-1;j>=1;j-=j&(-j)) //递减
ans+=f[j]; //累加
for (int j=sum[i];j<=x;j+=j&(-j)) //递加
f[j]++;
}
cout<<ans;
return 0;
}
然而十分有道理的分析只有10分。。
把数组改成结构体存储就OK啦!
CODE:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<cmath>
using namespace std;
long long n,m,rp[100000+5],t,ans,f[100000+5],p; //改long long
struct node
{ //结构体存位置与前缀和
long long sum,place;
};
node b[100000+5];
bool cmp(node a,node b)
{
return a.sum<b.sum; //排序前缀和
}
bool cnp(node a,node b)
{
return a.place<b.place; //排序位置
}
int main()
{
freopen("sequence.in","r",stdin);
freopen("sequence.out","w",stdout);
cin>>n>>m;
for (int i=1;i<=n;i++)
{
scanf("%lld",&rp[i]);
rp[i]-=m; //先减一遍
b[i].sum=b[i-1].sum+rp[i]; //求前缀和
b[i].place=i; //记录位置
if (b[i].sum>=1) ans++; //累加
}
sort(b+1,b+n+1,cmp); //排序一遍前缀和
for (int i=1;i<=n;i++)
{
if (b[i].sum!=p||i==1) t++;
p=b[i].sum;
b[i].sum=t;
}
sort(b+1,b+n+1,cnp); //排序一遍位置
for (int i=1;i<=n;i++)
{
for (int j=b[i].sum-1;j>=1;j-=j&(-j)) //递减
ans+=f[j]; //累加
for (int j=b[i].sum;j<=t;j+=j&(-j)) //递加
f[j]++;
}
cout<<ans;
return 0;
}
