前言
谈到字符串模式匹配算法,莫过于最经典的KMP算法,它由D.E.Knuth,J.H.Morris和V.R.Pratt三位大牛于1977年联合发表提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法),KMP算法可以在O(n+m)的时间复杂度以内完成字符串的匹配操作,其核心思想在于:当一趟匹配过程中出现字符不匹配时,不需要回溯主串的指针,而是利用已经得到的“部分匹配”,将模式串尽可能多地向右“滑动”一段距离,然后继续比较。
说到KMP,也得需要提一下字符串的模式匹配的意义,这也是我们学习KMP及各种字符串匹配算法的意义。字符串的模式匹配是对字符串的基本操作之一,广泛应用于生物信息学、信息检索、拼写检查、语言翻译、数据压缩、网络入侵检测等领域,如何简化其复杂性一直是算法研究中的经典问题。字符串的模式匹配实质上就是寻找模式串T是否在主串S 中,及其出现的位置。由于对字符串匹配的效率要求越来越高, 所以需要不断地改良模式匹配算法,减少其时间复杂度。
说到KMP,也感觉到数学世界的美妙,我们的祖先早在2000多年前就用阴阳(0,1)虚拟的分割了这个世界,而西方近代却用0、1(阴阳)在计算机里虚拟合成了这个世界;还有数学里的那些很奇怪而有趣的问题,比如杨辉三角, Kaprekar 常数,“421陷阱”等,不知道是不是与它们最终都能转化为0、1(阴阳)有关。好了,言归正传,我们只讲KMP。
正文
关于KMP主要难点是next[]数组,模式串的下一个匹配位k及模式串向右移动的距离m,以下我分三步并结合例子讲解三个难点。
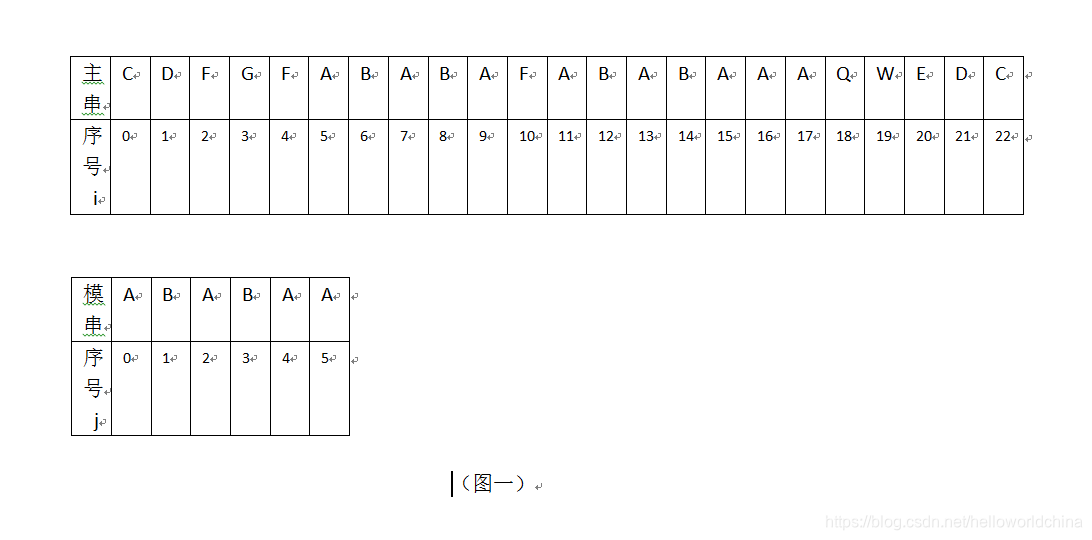
以下选取主串s = “CDFGFABABAFABABAAAQWEDC”,模式串t = “ABABAA”,为研究对象,进行讲解KMP.
第一步:先要明确以下几个概念:
●”前缀”和”后缀”:“前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。例如”ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D].
●最大公共前后缀:基于前缀,和后缀概念,在一个字符串中,最长的相同的前缀和后缀称为最长公共前后缀,有的称之为最长首尾串。
●Next[]数组:Next数组主要用来存放最大公共前后缀的长度值,此值定义为K值,即Next[]数组存储一组k值
举例说明:
字符串"A"的前缀和后缀都为空,共有元素的长度为0;
字符串"AB"的前缀为[A],后缀为[B],无共有元素,长度为0;
字符串"ABA"的前缀为[A, AB],后缀为[BA, A],共有元素"A",长度1;
字符串"ABAB"的前缀为[A, AB, ABA],后缀为[BAB, AB, B],共有元素"AB",长度为2;
字符串"ABABA"的前缀为[A, AB, ABA, ABAB],后缀为[BABA, ABA, BA, A],共有元素为"ABA",长度为3;
字符串"ABABAA"的前缀为[A, AB, ABA, ABAB, ABABA],后缀为[BABAA, ABAA, BAA, AA, A],共有元素为"A",长度为1;
综合以上,由字符串"A"、“AB”、“ABA”、“ABAB”、“ABABA”、“ABABAA"六个字符串组成的Next[]数组的值为:“001231”
即Next[]={0,0,1,2,3,1}” 。同理由字符串"A"、“AB”、“ABC”、“ABCD”、“ABCDA”、“ABCDAB”、"ABCDABD"七个字符串组成的Next[]数组的值为:“0000120”
即Next[]={0,0,0,0,1,2,0} 。
●主串S和模式串T进行匹配时的起始位置:均为0;
举例说明:
●模式串下一匹配位:定义为k,即下一次匹配时,主串i不变,模式串的新j值为j=k,即S[i]与T[k]进行比较。
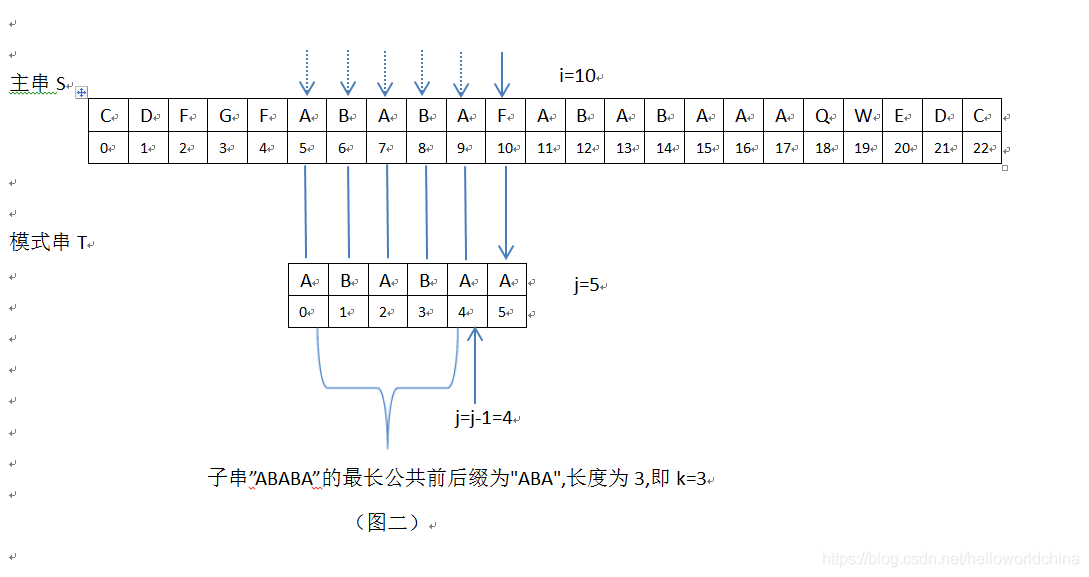
●K如何取值:k=next[j-1],为何用next[j-1]标识,之所以这样是为了更好的理解,j-1的含义是当j=5,i=10,T[5]!=S[10]时,需要取模式串”ABABAA”的next[]数组的第j-1=4位的数组值,此时Next[]={0,0,1,2,3,1}",在此next[]数组中,next[4]=3,即k=3。
注:还可以用另一个方法计算k,模式串j前面(不包括j),即从位置0开始,到4(j-1=4)结束的字符串”ABABA”的最长公共前后缀为"ABA",它的长度值为3,即k=3,如下图:
●模式串T向右滑动的最大距离:定义为m,m=j-k(当j>0时,j为模式串的序号)
●字符串模式匹配时存在的两种情况:
1 当模式串j=0时,即T[0]与主串Si且T[0]!=S[i]时,主串S位置加1,T向右滑动1位,此时j=0,T[0]将与主串Si继续比较。
2 当模式串j>0时,即T[j]与主串Si且T[j]!=S[i]时,此时会用到KMP算法。
第二步:举例演示KMP算法:
1 初始时,i=0,j=0;S[0]=”C”,T[0]=”A”,S[i]!=T[j],匹配失败,此时需要主串S位置加1,模式串T向右移动1位。

2 当i=1,2,3,4时,均匹配失败;此时需要主串S位置加1,模式串T向右移动1位。
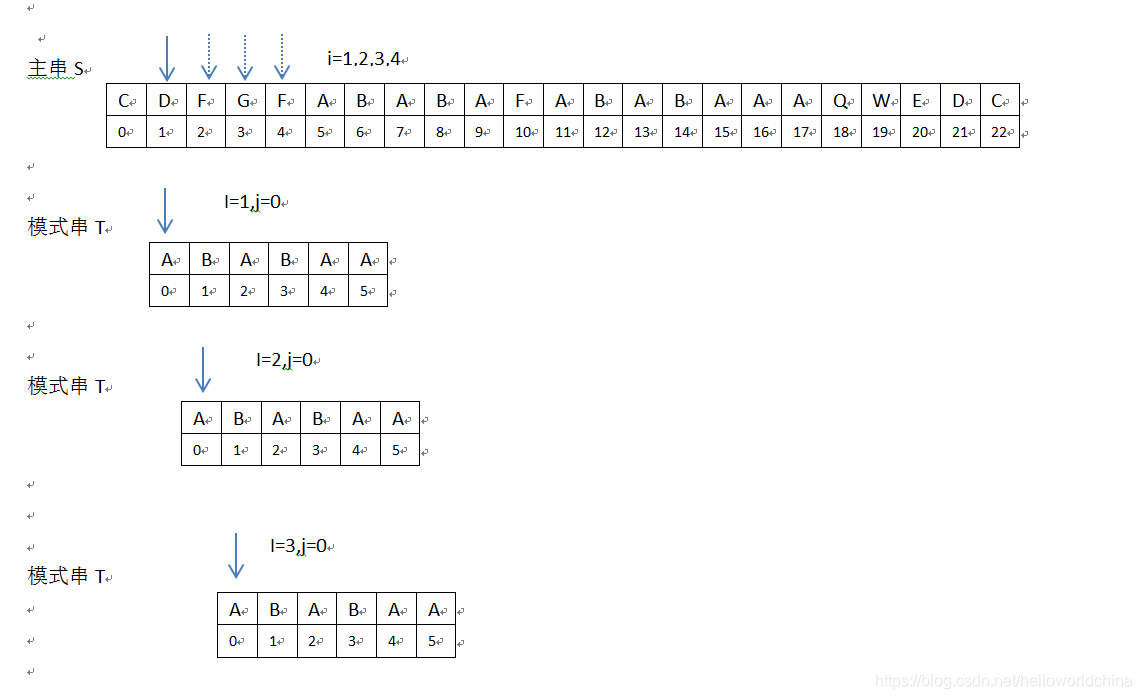
3 当i=5,6,7,8,9,j=0,1,2,3,4时,匹配成功,此时主串S位置加1,模式串T位置加1位。
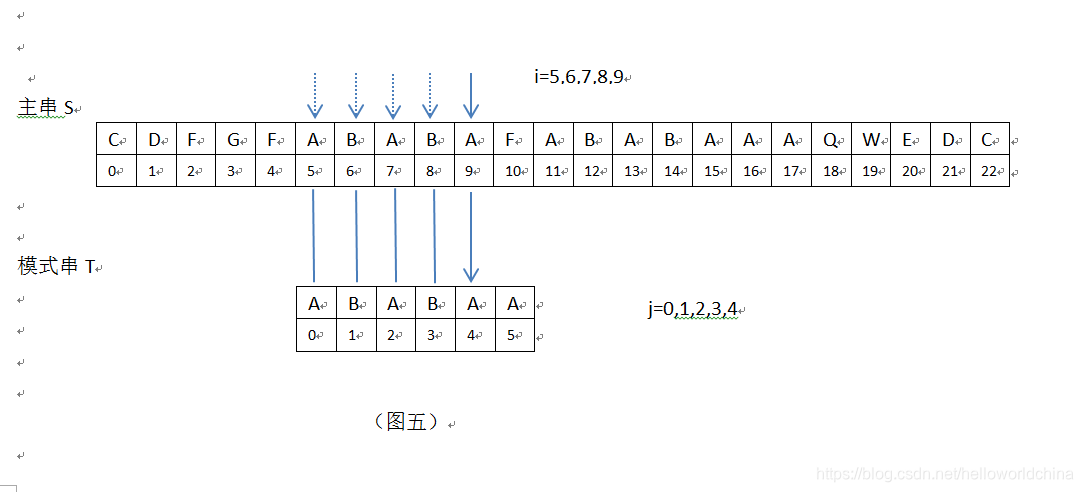
4 当i=10,j=5时,匹配失败,S[10]=“F”, T[5]=“A”,S[10]!=T[5],见下:
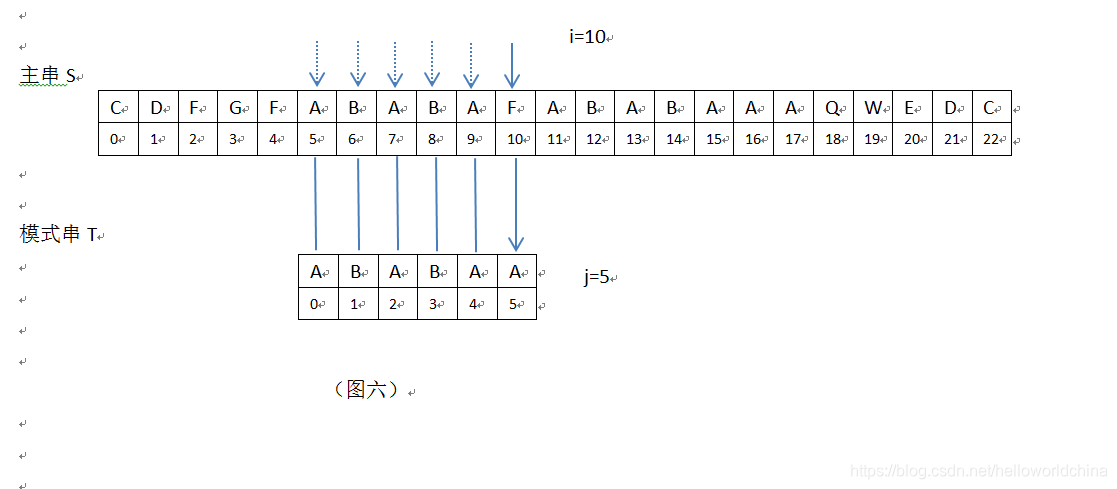
5在上图,i=10,j=5,接下来继续匹配时,需要主串中S[i]位置不变(i=10),模式串位置变为T[k],现在需要求k值。根据公式k=next[j-1],需要取模式串”ABABAA”的next[]数组的第j-1=5-1=4位的数组值,此时Next[]={0,0,1,2,3,1}",在此next[]数组中,next[4]=3,即k=3(j前面字符串”ABABA”的最长公共前后缀为"ABA",它的长度值为3,即k=3);此时,根据KMP算法,i=10不变,模式串T向右滑动m=j-k=5-3=2位,模式串新的j值为j=k=3,见下:
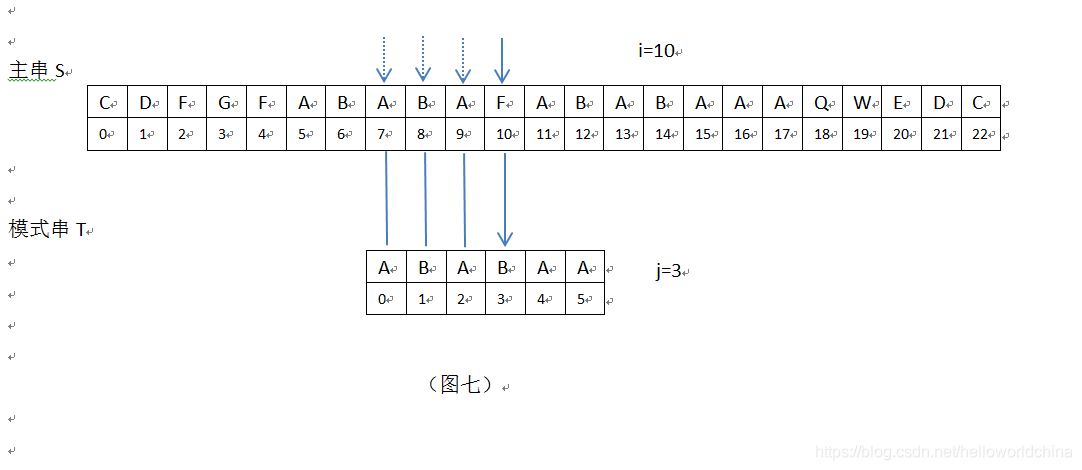
6在上图,i=10,j=3,S[i]=S[10]=”F” ,T[j]=T[3]=”B”,S[10]!=T[3],接下来继续匹配时,需要主串中S[i]位置不变(i=10),模式串位置变为T[k],现在需要求k值。根据公式k=next[j-1],需要取模式串”ABABAA”的next[]数组的第j-1=3-1=2位的数组值,此时Next[]={0,0,1,2,3,1}",在此next[]数组中,next[2]=1,即k=1(j前面字符串”ABA”的最长公共前后缀为"A",它的长度值为1,即k=1);此时,根据KMP算法,i=10不变,模式串T向右滑动m=j-k=3-1=2位,模式串新的j值为j=k=1,见下:
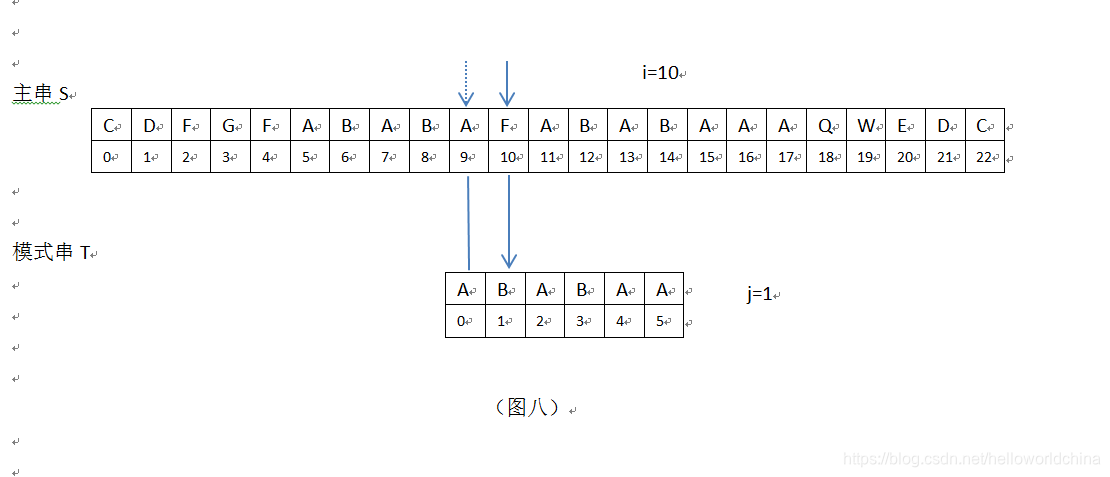
7在上图,i=10,j=1,S[i]=S[10]=”F” ,T[j]=T[1]=”B”,S[10]!=T[1],接下来继续匹配时,需要主串中S[i]位置不变(i=10),模式串位置变为T[k],现在需要求k值。根据公式k=next[j-1],需要取模式串”ABABAA”的next[]数组的第j-1=1-1=0位的数组值,此时Next[]={0,0,1,2,3,1}",在此next[]数组中,next[0]=0,即k=0(j前面字符串”A”,无最长公共前后缀,它的长度值为0,即k=0);此时,根据KMP算法,i=10不变,模式串T向右滑动m=j-k=1-0=1位,模式串新的j值为j=k=0,见下:
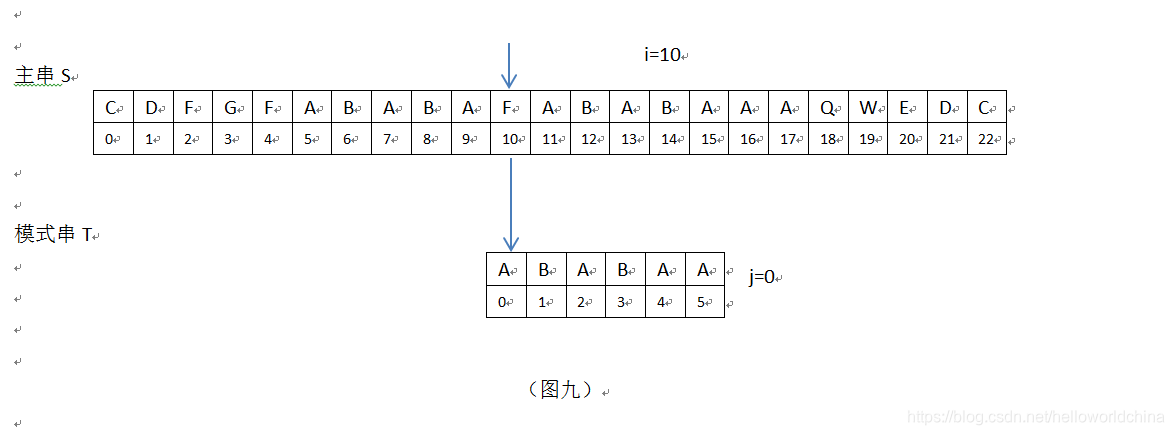
8在上图,i=10,j=0,S[i]=S[10]=”F” ,T[j]=T[0]=”A”,S[10]!=T[0],这属于上面提到的字符串匹配时遇到的第一种情况,主串S位置加1,T向右滑动1位,继续比较;这样,i=11,j=0,见下:
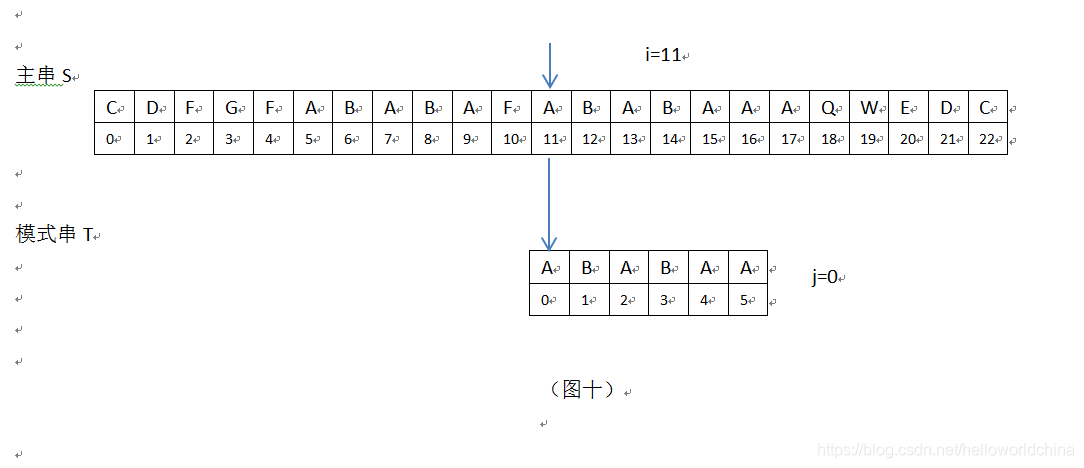
接下来,当i=12,13,14,15,16,j=1,2,3,4,5,匹配成功,模式串T在主串中的位置为11。
第三步:代码实现
1 next[]数组代码:
public static int[] kmpNext(String str){
int[] next = new int[str.length()];
next[0] = 0;
for(int j = 1,k = 0; j < str.length(); j++){
while(k > 0 && str.charAt(k) != str.charAt(j)){
k = next[k - 1];
}
if(str.charAt(j) == str.charAt(k)){
k++;
}
next[j] = k;
}
return next;
}
2 kmp代码
public static int kmp(String s, String t,int[] next){//s文本串 t 模式串
for(int i = 0, j = 0; i < s.length(); i++){
while(j > 0 && s.charAt(i) != t.charAt(j)){
j = next[j - 1]; //下一个匹配位为next数组的第j-1位
}
if(s.charAt(i) == t.charAt(j)){
j++;//主串通过i进行加1,模式串通过j加1
}
if(j == t.length()){
return i-j+1;//返回匹配位置
}
}
return -1;
}
3 打印next[]数组代码
public static void printNext(String s){
System.out.println("********************");
int[] nextI = kmpNext(s);
System.out.print("模式串:'"+s+"'的next[]数组为:[");
for(int i = 0; i < (nextI.length); i++){
System.out.print(nextI[i]+" ");
}
System.out.println("]");
System.out.println("模式串长度为:"+nextI.length);
}
4 主函数代码
public static void main(String[] args){
String s = "CDFGFABABAFABABAAAQWEDC";
String t = "ABABAA";
int[] next = kmpNext(t);
int res = kmp(s, t,next);
if (res!=-1){
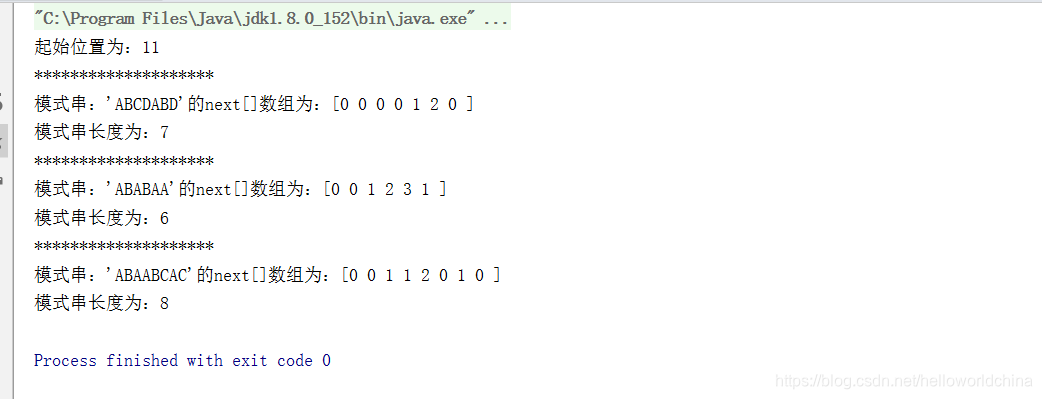
System.out.println("起始位置为:"+res);
}
else System.out.println("主串中不包含字符串:"+t);
printNext("ABCDABD");
printNext("ABABAA");
printNext("ABAABCAC");
}
5运行结果
尾记
文中所述的KMP算法前提是保持主串的i不变,模式串进行向滑动,从算法上来说还不够快,在有些匹配情况下,要更进一步的优化,需要i也要加1,同时模式串也要向右滑动1位。笔者日后会进一步优化KMP算法。
