参考自:
Introducing data center fabric, the next-generation Facebook data center network
Facebook’s Data Center Fabric
背景
Facebook的用户已经超过10多亿,而且还在迅速增长。为了能够给用户提供实时的体验,Facebook为数据中心设计了一个高可扩展,高性能的网络架构 data center fabric。
虽然这个网络架构实际上在14年已经实施了,但是其中的一些设计理念在今天的一些数据中心里依然有很好的参考价值。
传统的挑战
下面首先看看Facebook在如此大的用户规模下,将会面临哪些挑战。这些Facebook曾经走过的路也是其他在发展中的数据中心将要面临货已经面临的问题。
高速发展
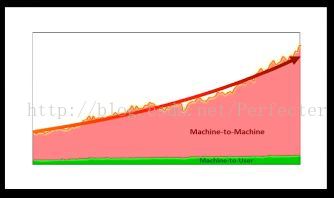
首先,随着用户数量的急剧增长,业务规模不断扩大,数据中心的公网出口流量非常大,并且还在持续增长。与此同时,数据中心内部的流量比公网流量大几个数量级。
在Facebook的数据中心内部,后端分层的服务和程序都是分布式且在逻辑上互联的。这些服务为前段用户提供实时的体验。虽然有不断地优化,但是流量在一年内还是会翻番。
所以支持高速发展的能力将成为设计基础设施的核心理念。同时还要保证网络架构足够精简,易于管理。
如下图,绿色的部分是公网流量的增长速度,红色是内部流量的增长。
Cluster的局限
传统的数据中心的网络是以Cluster为基础建设的。一个Cluster中部署上百个机架,每个机架里有交换机,并且这些交换机再接入到性能更好的汇聚交换机上。
虽然Facebook之前也做过一些改进,比如开发了一个“four-post”的layer3架构,提供3+1的集群交换机冗余,能力是以前的10倍。但这种架构还是基于Cluster的,还是有一些限制。首先,Cluster的规模受到交换机端口密度的影响。这些高性能、大规格的交换机往往集中在某几家厂商手里,也就是说受到厂商的制约。其次,硬件性能的增长往往赶不上业务的需求。而且这些高端的硬件往往都有独特的内部架构,需要具备额外的硬件和软件知识才能很好地驾驭,这无疑又是一个打击。在大规模场景下,软硬件的失效问题也成为很重要的考虑点。
更难的在于,需要在集群规模、内部带宽、外部带宽之间做出平衡。实际上,Cluster这个概念也就源自于这些网络的限制。集群简单讲,就是部署在高性能网络池内的大规模计算资源,而往往人们假设集群之间的流量远远小于集群内部的流量,基于这个假设,一些需要交互的程序往往就部署在同一个集群内。这实际上就限制了服务的规模,大规模的服务都是分布式的,不应该有这个限制。
fabric网络
Facebook的下一代网络的宗旨就是整个数据中心建立在一套高性能网络之上,而不是分层的Cluster系统。而且能够快速的扩展规模和性能,每次扩容时,都不会影响已经部署的基础架构。
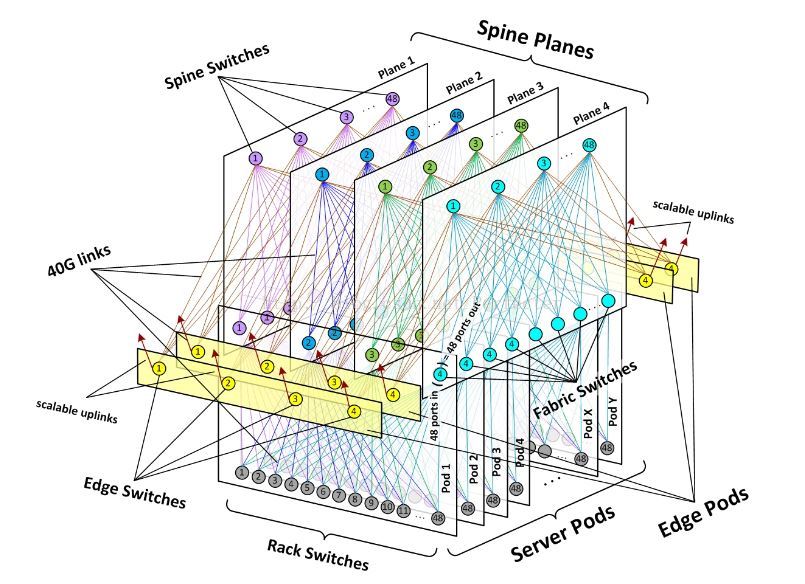
为了达到这个目的,Facebook将网络分解成为小的单元——server pod,并且pod直接全互联。
fabric
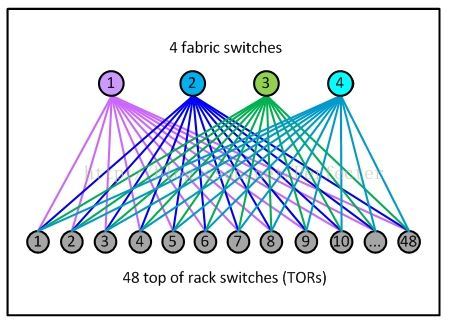
如下图,一个pod里面最多有48个机架,每个机架和4个fabric交换机相连,每个机架交换机有4*40G总共160G的出口带宽。机架内部的服务器之间10G互联
spine
pod之间的互联依靠下图的spine交换机,每个spine平面最多有48个独立的spine交换机。这样一来,pod之间就形成了一个高性能的全互联网络。
而edge平面的交换机则负责出口流量。
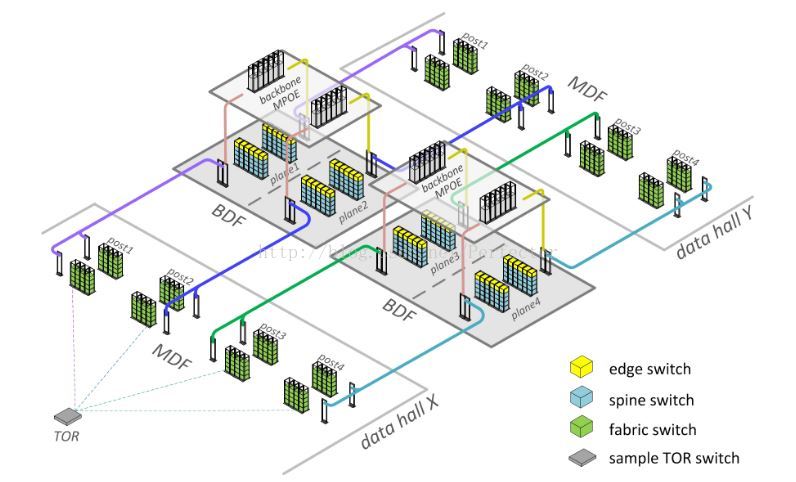
物理架构
如下图可以看到,专门用于放置各类交换机的机架规模也不小
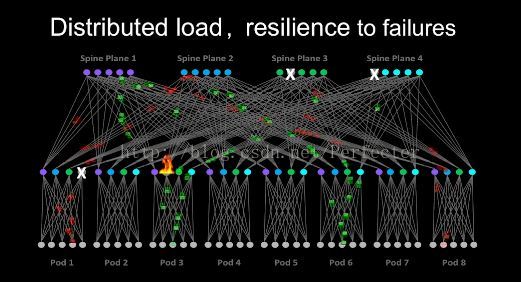
效果
如下图可以看出,所有机架之间的路基可能有多种,路径根据流量的负责自动选择,能够容忍若干网络路径的故障。