主要内容
1.感知器总述
1958年,美国心理学家Frank Posenblatt 提出一种具有单层计算单元的神经网络,称为Perceptron,即感知器。感知器模拟人的视觉接受环境信息,并由神经冲动进行信息传递。感知器研究中首次提出了自组织、自学习的思想,而且对所能解决的问题存在着收敛算法,并能从数学上严格证明,因而对神经网络的研究起了重要的推动作用。感知器的输出一般是0或1,当然也可以是-1或+1,实现对输入的矢量进行分类的目的。
2.感知器模型

图中, n 维向量[a1,a2,…,an]的转置作为感知机的输入,[w1,w2,…,wn]的转置为输入分量连接到感知机的权重(weifht),b 为偏置(bias),f(.)为激活函数,t 为感知机的输出。t 的数学表示为:
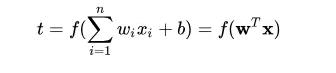
另外,这里的 f(.) 用的是符号函数:
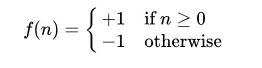
也可以记成:
f(x)= sign(w*x+b)
其中,x为输入向量,sign为符号函数,括号里面大于等于0,则其值为1,括号里面小于0,则其值为-1。w为权值向量,b为偏置。求感知机模型即求模型参数w和b。感知机预测,即通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别1或者-1。
3.感知器策略(建立损失函数)
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个损失函数并通过将损失函数最小化来求w和b。
这里选择的损失函数是误分类点到分类超平面S的总距离。输入空间中任一点x0到超平面S的距离为:
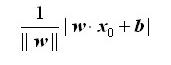
其中,||w||为w的L2范数。就是 w 中每个元素去平方,然后相加开根号,即 ||w|| = √w1^2 + w2^2 +…+ wn^2 。
其次,对于误分类点来说,当-yi (wxi + b)>0时,yi=-1,当-yi(wxi + b)<0时,yi=+1。所以对误分类点(xi, yi)满足:
-yi (wxi +b) > 0
所以误分类点(xi, yi)到分类超平面S的距离是:

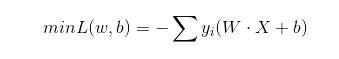
感知器学习的目的是找到合适的权值与阈值,使得感知器的输出、输入之间满足线性可分的函数关系。学习的过程往往很复杂,需要不断的调整权值与阈值,称为“训练”的过程。
若以t表示目标输出,a表示实际输出,则
e=t-a
训练的目的就是使t->a.
一般感知器的传输感受为阈值函数网络的输出a只能是0或1,所以只要网络表达的函数是线性可分的,则函数经过有限次迭代之后,将收敛到正确的权值与阈值,使e=0。
感知器的训练需要提供样本集,每个样本由神经网络的输入向量和输出向量对构成,n个训练样本构成的样本集为:
{p1,t1},{p2,t2}~~~~{pn,tn}
每一步学习过程,对各个神经元的权值与阈值的调整算法是:
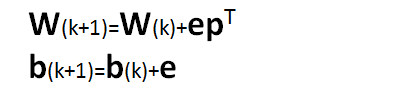
式子中W为权值向量;b为阈值向量;p为输入向量;k为第k步学习过程。上述学习过程称为标准化感知器学习规则,可以用函数learnp实现。
如果输入向量的取值范围很大,一些输入值太大,而一些输入值太小,按照上述公式学习的时间将会很长。为此,阈值的调整可以继续按照上述公式,而权值的调整可以采用归一化方法,即

上述归一化学习方式可以使用函数learnpn实现。
4.感知器算法(梯度下降和随机梯度下降)
4.1梯度下降
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。以山为例,就是坡度最陡的地方,梯度值就是描述坡度有多陡。
研究梯度,就要知道导数、偏导数、方向导数的知识,[机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent) 中讲得非常通俗易懂(原文链接放在参考资料里边).
梯度下降方向就是梯度的反方向,最小化损失函数 L(w,b) 就是先求函数在 w 和 b 两个变量轴上的偏导:
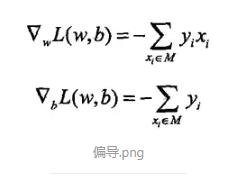
上面的式子,每更新一次参数,需要遍历整个数据集,如果数据集非常大的话,显然是不合适的,为了解决这个问题,只随机选取一个误分类点进行参数更新,这就是随机梯度下降(SGD)。
4.2随机梯度下降

这里的 η 指的是学习率,相当于控制下山的步幅,η 太小,函数拟合(收敛)过程会很慢,η 太大,容易在最低点方向震荡,进入死循环。
当没有误分类点的时候,停止参数更新,所得的参数就是感知机学习的结果,这就是感知机的原始形式。下面总结一下参数更新的过程:
(1)预先设定一个 w0 和 b0,即 w 和 b 的初值。
(2)在训练集中选取数据(xi,yi)。
(3)当 yi*(w xi +b) <= 0时,利用随机梯度下降算法进行参数更新。

这种算法的基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。
需要注意的是,这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。为了得到唯一的分类超平面,需要对分类超平面增加约束条件,线性支持向量机就是这个想法。另外,当训练数据集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。而对于线性可分的数据集,算法一定是收敛的,即经过有限次迭代,一定可以得到一个将数据集完全正确划分的分类超平面及感知机模型。
5.感知器MATLAB简单实现
MATLAB神经网络提供了大量的与神经网络感知器相关的函数。在MATLAB工作空间的命令行中输入help percept,便可得到与神经网络感知器相关的信息。
5.1newp函数:
用于创建一个感知器网络,函数的调用格式如下。
net=newp(P,T,TF,LF):其中,P为一个r✖2维的输入向量矩阵,其决定了r维输入向量的最大值和最小值取值范围;T表示神经元的个数;TF表示网络的传输函数,默认值为hardlim;LF表示网络的学习函数,默认值为learnp;net为生成的新感知器神经网络。
小应用:
% 1.1 生成网络
net=newp([0 2],1);%单输入,输入值为[0,2]之间的数
inputweights=net.inputweights{1,1};%第一层的权重为1
biases=net.biases{1};%阈值为1
5.2sim函数:
在MATLAB神经网络工具箱中,提供了sim函数用于进行网络仿真,函数的调用格式如下:
[Y,Pf,Af,E,perf]=sim(net,P,Pi,Ai,T):Y为网络的输出;Pf表示最终的输入延时状态;Af表示最终的层延时状态;E为实际输出与目标矢量之间的误差;perf为网络的性能值;NET为要测试的网络对象;P为网络的输入向量矩阵;Pi为初始的输入延时状态(可省略);Ai为初始的层延时状态(可省略);T为目标矢量(可省略)。
小应用:
% 1.2 网络仿真
net=newp([-2 2;-2 2],1);%两个输入,一个神经元,默认二值激活
net.IW{1,1}=[-1 1];%权重,net.IW{i,j}表示第i层网络第j个神经元的权重向量
net.IW{1,1}
net.b{1}=1;
net.b{1}
p1=[1;1],a1=sim(net,p1)
p2=[1;-1],a2=sim(net,p2)
p3={[1;1] [1 ;-1]},a3=sim(net,p3) %两组数据放一起
p4=[1 1;1 -1],a4=sim(net,p4)%也可以放在矩阵里面
net.IW{1,1}=[3,4];
net.b{1}=[1];
a1=sim(net,p1)
5.3init函数
在matlab中提供了init 函数用于初始化神经网络。
语法如下:
net = init(net) 。init(net)根据最新的网络初始化函数返回神经网络的权值和误差,其结果由net.initFcn,和参数值,net.initparam影响。
小应用:
% 1.3 网络初始化
net=init(net);
wts=net.IW{1,1}
bias=net.b{1}
% 改变权值和阈值为随机数
net.inputweights{1,1}.initFcn='rands';
net.biases{1}.initFcn='rands';
net=init(net);
bias=net.b{1}
wts=net.IW{1,1}
a1=sim(net,p1)
初始化结果:
wts =
0 0
bias =
0
5.4train函数
除了adapt函数应用于神经网络自适应训练外,MATLAB神经网络工具箱还提供了train函数进行网络样本数据训练。函数的调用格式如下:
[net,tr,Y,E,Pf,Af]=train(net,P,T,Pi,Ai):输出参数net为训练后的网络,tr为训练记录,Y为网络输出矢量;E为误差适量,Pf为训练终止时的输入延迟状态;Af为训练终止时的层延迟状态;输入参数net为训练前的网络,P为网络的输入向量矩阵;T表示网络的目标矩阵,默认值为0;Pi表示初始输入延时,默认值为0;Ai表示初始的层延时,默认为0;网络训练是一种通用的学习函数,训练函数重复地把一组输入向量应用到一个网络上,每次都要更新网络,直到达到了某种准则,停止准则可能是到达最大的学习步数,最小的误差梯度或误差目标等。
小应用:
% 2 网络训练
net=init(net);
p1=[2;2];t1=0;p2=[1;-2];t2=1;p3=[-2;2];t3=0;p4=[-1;1];t4=1;
net.trainParam.epochs=1;
net=train(net,p1,t1)
w=net.IW{1,1}
b=net.b{1}
a=sim(net,p1)
net=init(net);
p=[[2;2] [1;-2] [-2;2] [-1;1]];
t=[0 1 0 1];
net.trainParam.epochs=1;
net=train(net,p,t);
a=sim(net,p)
net=init(net);
net.trainParam.epochs=2;
net=train(net,p,t);
a=sim(net,p)
net=init(net);
net.trainParam.epochs=20;
net=train(net,p,t);
a=sim(net,p)

5.5adapt函数
构建感知器神经元模型后,需要对输入样本数据进行网络权重和阈值的调整,训练网络使其输出性能满足目标设置,在MATLAB神经网络工具箱中,使用adapt函数进行神经网络的自适应训练,函数调用格式如下:
[net,Y,E,Pf,Af]=adapt(net,P,T,Pi,Ai):其中,输入参数net为待自适应的神经网络;P为网络输入;T为网络目标,默认为0;Pi为初始输入延迟,默认为0;Ai为初始层延迟,默认为0;输出net参数为自适应后的圣经网络;Y为网络输出;E为网络误差;Pf为最终输入延迟;Af为最终层延迟。
小应用:
(PS:plot为做图函数)
% 3. 二输入感知器分类可视化问题
P=[-0.5 1 0.5 -0.1;-0.5 1 -0.5 1];
T=[1 1 0 1]
net=newp([-1 1;-1 1],1);
plotpv(P,T);
plotpc(net.IW{1,1},net.b{1});
%hold on;
%plotpv(P,T);
net=adapt(net,P,T);
net.IW{1,1}
net.b{1}
plotpv(P,T);
plotpc(net.IW{1,1},net.b{1})
net.adaptParam.passes=3;
net=adapt(net,P,T);
net.IW{1,1}
net.b{1}
plotpc(net.IW{1},net.b{1})
net.adaptParam.passes=6;
net=adapt(net,P,T)
net.IW{1,1}
net.b{1}
plotpv(P,T);
plotpc(net.IW{1},net.b{1})
plotpc(net.IW{1},net.b{1})
%仿真
a=sim(net,p);
plotpv(p,a)
p=[0.7;1.2]
a=sim(net,p);
plotpv(p,a);
hold on;
plotpv(P,T);
plotpc(net.IW{1},net.b{1})
%感知器能够正确分类,从而网络可行。

5.6其他可能用到的函数
axis函数
坐标轴的控制函数axis,调用格式如下:
axis([xmin,xmax,ymin,ymax,zmin,zmax])
用此命令可以控制坐标轴的范围.
与axis相关的几条常用命令还有:
axis auto 自动模式,使得图形的坐标范围满足图中一切图元素
axis equal 严格控制各坐标的分度使其相等
axis square 使绘图区为正方形
axis on 恢复对坐标轴的一切设置
axis off 取消对坐标轴的一切设置
axis manual 以当前的坐标限制图形的绘制
mae函数
在MATLAB神经网络工具中提供了mae函数用于求平均绝对误差性能,感知器的学习规则为调整网络的权值和偏值,使网路的平均绝对误差和最小。mae函数的调用格式如下:
perf=mae(E,Y,X,FP):E为误差矩阵或向量(E=T-Y,T表示网络的目标向量);Y为网络的输出向量(可忽略);X为所有权值和偏值向量(可忽略);FP为性能参数(可忽略);perf表示平均绝对误差。
4个小实验应用:
matlab绘图句柄使用的教学链接
1.标准化学习规则训练奇异样本
P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1.0 50]
T=[1 1 0 0 1];
net=newp([-40 1;-1 50],1);
plotpv(P,T);%标出所有点
hold on;
linehandle=plotpc(net.IW{1},net.b{1});%画出分类线
E=1;
net.adaptParam.passes=3;%passes决定在训练过程中训练值重复的次数。
while (sse(E))%sse函数是用来判定误差E的函数
[net,Y,E]=adapt(net,P,T);
linehandle=plotpc(net.IW{1},net.b{1},linehandle);
drawnow;
end;
axis([-2 2 -2 2]);
net.IW{1}
net.b{1}

2.另外一种网络修正学习(非标准化学习规则learnp)
hold off;
net=init(net);
net.adaptParam.passes=3;
net=adapt(net,P,T);
plotpc(net.IW{1},net.b{1});
axis([-2 2 -2 2]);
net.IW{1}
net.b{1}
%无法正确分类
%标准化学习规则网络训练速度要快!

3.训练奇异样本
用标准化感知器学习规则(标准化学习数learnpn)进行分类
非标准化感知器学习规则训练奇异样本的结果
%用标准化感知器学习规则(标准化学习数learnpn)进行分类
net=newp([-40 1;-1 50],1,'hardlim','learnpn');
plotpv(P,T);
linehandle=plotpc(net.IW{1},net.b{1});
e=1;
net.adaptParam.passes=3;
net=init(net);
linehandle=plotpc(net.IW{1},net.b{1});
while (sse(e))
[net,Y,e]=adapt(net,P,T);
linehandle=plotpc(net.IW{1},net.b{1},linehandle);
end;
axis([-2 2 -2 2]);
net.IW{1}%权重
net.b{1}%阈值
%正确分类
%非标准化感知器学习规则训练奇异样本的结果
net=newp([-40 1;-1 50],1);
net.trainParam.epochs=30;
net=train(net,P,T);
pause;
linehandle=plotpc(net.IW{1},net.b{1});
hold on;
plotpv(P,T);
linehandle=plotpc(net.IW{1},net.b{1});
axis([-2 2 -2 2]);


Neural Network(结构):2输入,1输出,中间1个隐藏层,有一个节点
Algorithms(训练算法):这里是trainc - 循环顺序权重/阈值的训练;误差指标为mae
Progress(训练进度):
Epoch:训练次数;右边显示最大的训练次数,进度条中是实际训练的次数
Time:训练时间,也就是本次训练使用的时间
Performance:性能指标;本例子中为平均绝对误差(mae)的最大值。精度条中显示的是当前的平均绝对误差;进度条右边显示的是设定的平均绝对误差(如果当前的平均绝对误差小于设定值,则停止训练),这个指标可以用.trainParam.goal参数设定。
Gradiengt:梯度;进度条中显示的当前的梯度值,其右边显示的是设定的梯度值。如果当前的梯度值达到了设定值,则停止训练。
Mu: trainParam这个结构体的参数,确定学习根据牛顿法还是梯度法
validation check为泛化能力检查(若连续6次训练误差不降反升,则强行结束训练)
Plots(作图):分别点击2个按钮能看到误差变化曲线,分别用于绘制当前神经网络的性能图,训练状态。
4.设计多个感知器神经元解决分类问题
两条线分三类:
p=[1.0 1.2 2.0 -0.8; 2.0 0.9 -0.5 0.7]
t=[1 1 0 1;0 1 1 0]
plotpv(p,t);
hold on;
net=newp([-0.8 1.2; -0.5 2.0],2);
linehandle=plotpc(net.IW{1},net.b{1});
net=newp([-0.8 1.2; -0.5 2.0],2);
linehandle=plotpc(net.IW{1},net.b{1});
e=1;
net=init(net);
while (sse(e))
[net,y,e]=adapt(net,p,t);
linehandle=plotpc(net.IW{1},net.b{1},linehandle);
drawnow;
end;

6小结
感知器的诞生意义就是有了一种自调节,收敛的识别算法,虽然只是简单的线性识别,但是在这个基础之上改造就可以慢慢向更复杂,功能更全的识别迈进。
(附一个单层感知器与多层感知器区别的文章单层感知器)
感谢阅读:)
