本以为经过了前两章后,可以小试牛刀,当把朋友的项目get过来后,哈,果断的报错。继续询问了一下,额还需要安装一下Spark和Hadoop。
一、安装和配置Spark
1、下载地址:http://spark.apache.org/downloads.html
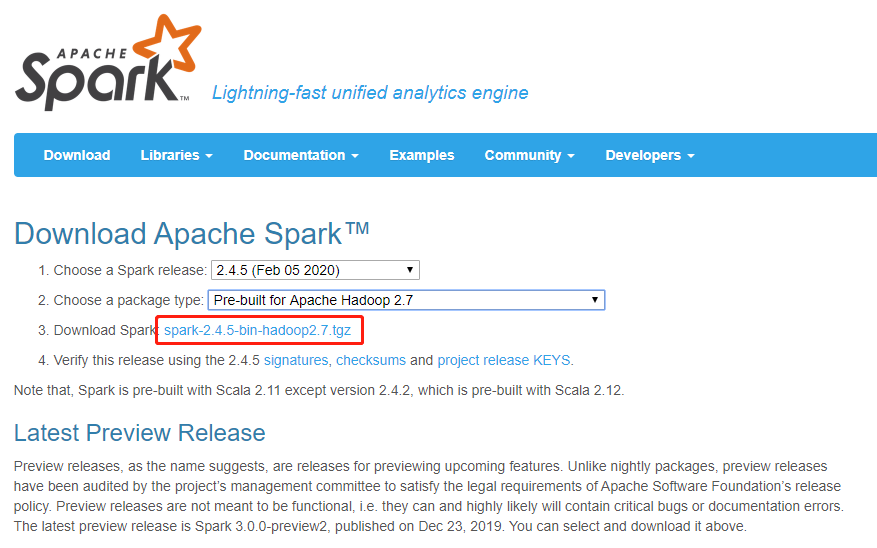
下载的版本是可以选择的,另外Spark对应的Hadoop版本兼容也能直接体现出来。我这里使用的是2.4.5版本的spark
2、解压下载的包,放在你心仪的位置。我是直接放在C盘的(哈,SSD足够大),值得一提的是,在配置环境变量的时候,spark路径不能出现空格(我验证过)
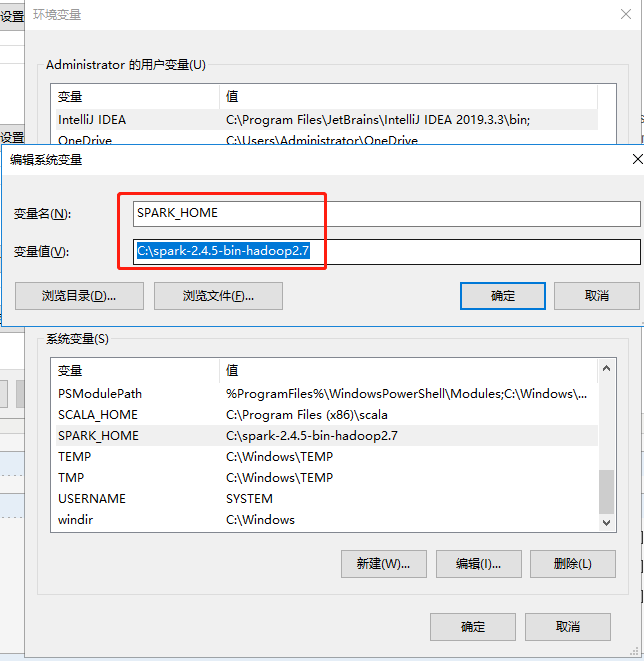
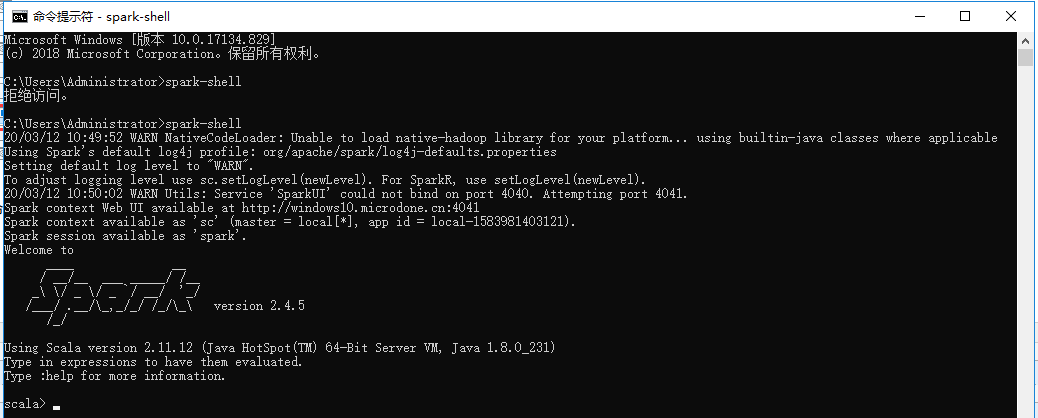
3、在控制台输入spark-shell命令执行安装(建议以管理员身份运行cmd命令行,我遇到一个拒绝访问的问题)

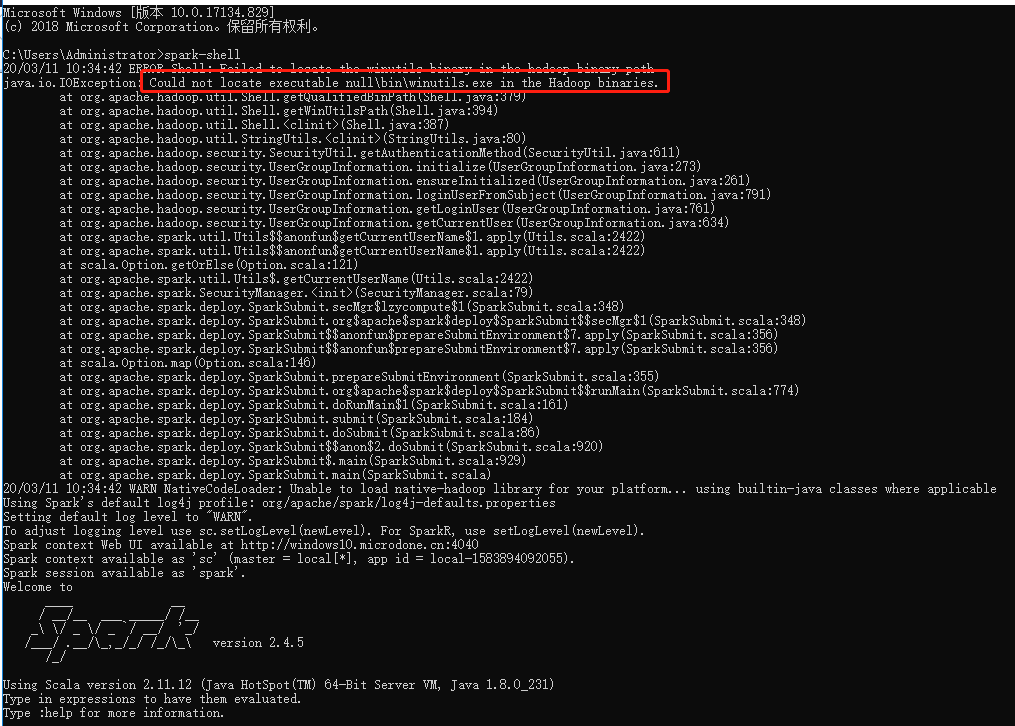
出现下图,表示成功。然后发现有个IO异常,提示我没有找到Hadoop,所以接下来还需要安装与之兼容的Hadoop。
二、安装和配置Hadoop
下载地址:https://hadoop.apache.org/release/2.7.3.html
据朋友说,在2.7.*中,2.7.3稳定一些,所以果断在Apache去选择了2.7.3的版本进行下载,Download tar.gz 是sdk包, Download.src 是 源码包。我们在配置环境变量的时候,需要bin文件,而这个bin文件在 sdk包中。
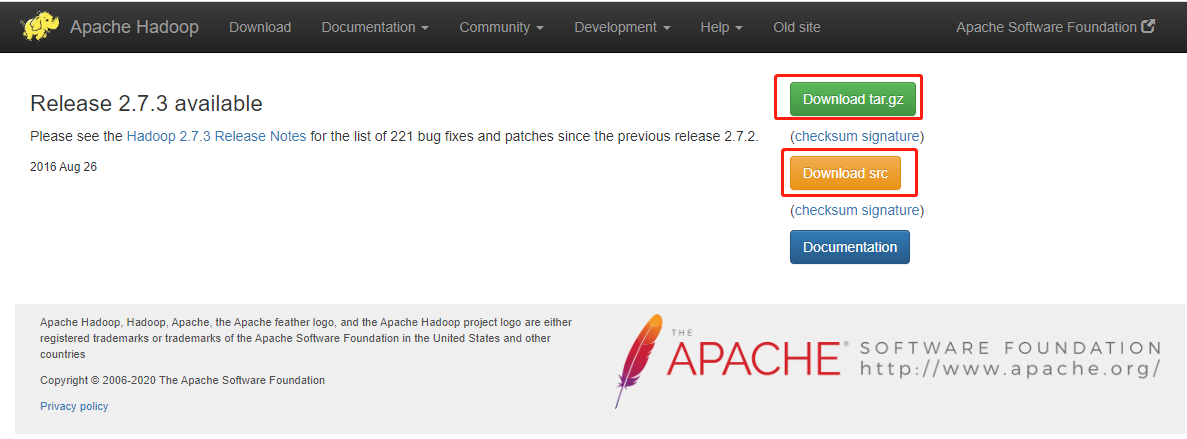
这个下载的速度实在是太慢了,我把下载好的包解压后放在C盘中(任何地方都可以哈,路径不要有汉字和空格),然后就是配置环境变量了
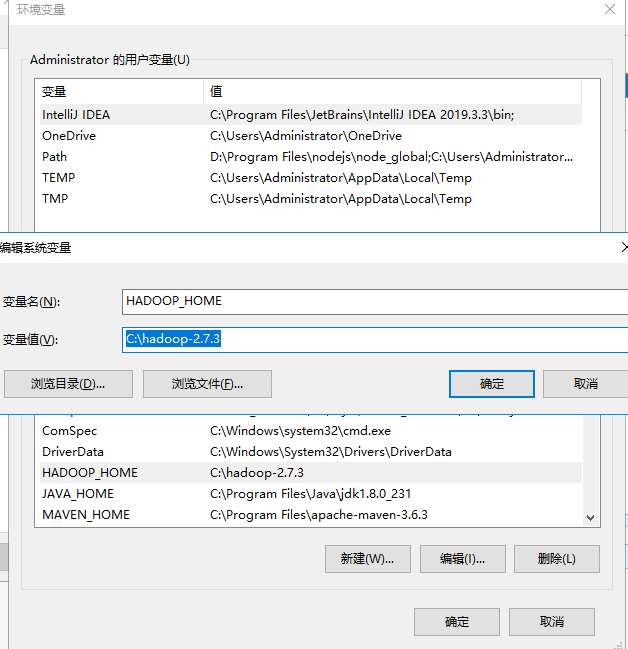
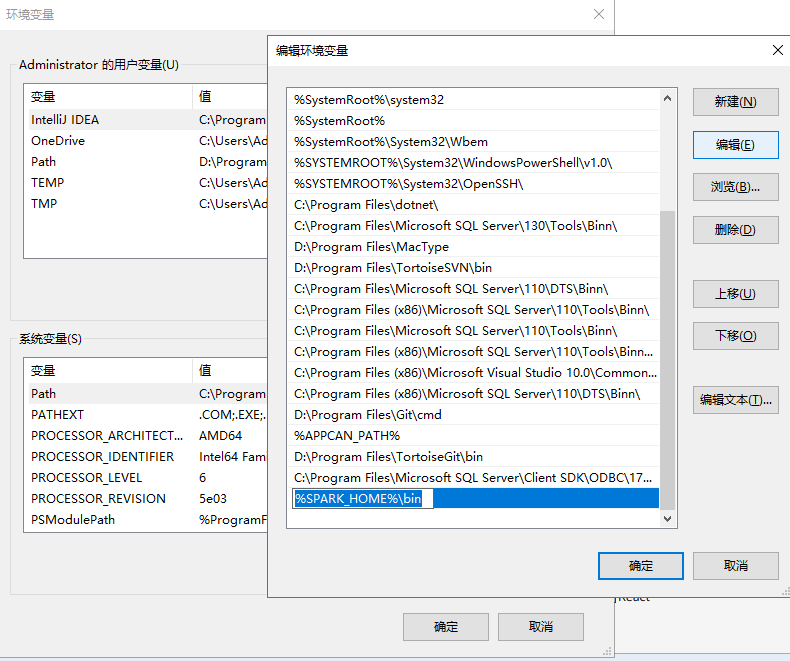
接着配置一下PATH
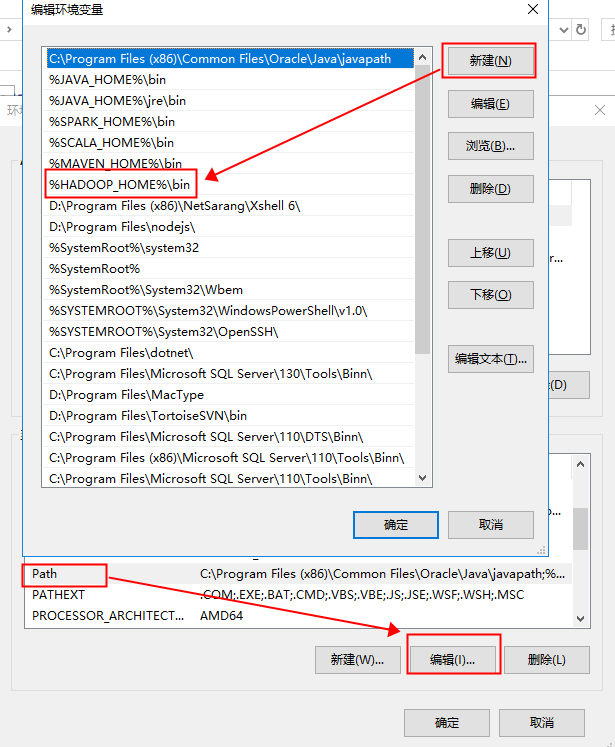
就这样我们就把Hadoop的环境变量配置好了。
此时我们回到我们在运行spark-shell 会报错的情况,当时我们认为是没有安装 Hadoop导致的,那么我们接着测试一下会发现仍旧报错。
哈,然后回想一下Hadoop是运行在 Linux系统下的,所以根据错误发现缺少winutils.exe文件,果断去找了一下与之匹配的exe文件,最终在花了14C币的情况下,在csdn下载了一个。
将下载好文件 放到 Hadoop的bin目录
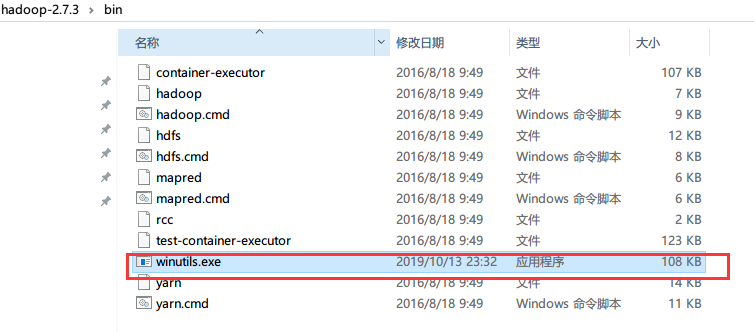
再次运行spark-shell命令,此次就完美通过了。
大功告成!!!
结尾声明:我是一个初学者,有很多不懂的地方,入驻博客园,一是因为记录一下在过程,做个笔记;二是希望对和我们一样“自摸”的小伙伴有那么一丢丢帮助!