1.MapReduce 计数器是什么?
是用于记录job的执行进度和状态的。可以认为是笔记本,记录这数据变化。
2.MapReduce计数器能做什么?
计数器给我们提供一个数据窗口,展示各种细节数据。对MapRed性能优化的评价都计数器表现出来。计数器是一种收集作业统计信息的有效手段。用于统计质量控制或应用级统计。还可以判断系统出现的问题错误。计数器好比一个日记本,你每天记录一点,有一天返回来
看一遍就能看到你的如何成长的,还需要改进什么,一一都记录着。
3.内置计数器
MapReduce 自带了许多默认 Counter,现在我们来分析这些默认 Counter 的含义, 方便大家观察 Job 结果,如输入的字节数、输出的字节数、Map 端输入/输出的字节数 和条数、Reduce 端的输入/输出的字节数和条数等。下面我们只需了解这些内置计数器,知道计数器组名称(groupName)和计数器名称(counterName),以后使用计数器会查找 groupName 和 counterName 即可。
4.实验任务开始(所以的jar包都是hadoop中有在hadoop/share/里自行下载)。
(1)编新程序.
完整代码:
package mr ;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Counters {
public static class MyCounterMap extends Mapper<LongWritable, Text, Text, Text> {
public static Counter ct = null;
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text,
Text>.Context context)
throws java.io.IOException, InterruptedException {
String arr_value[] = value.toString().split("\t");
if (arr_value.length > 3) {
ct = context.getCounter("ErrorCounter", "toolong"); // ErrorCounter 为 组
名,toolong 为组员名
ct.increment(1); // 计数器加一} else if (arr_value.length < 3) {
ct = context.getCounter("ErrorCounter", "tooshort");
ct.increment(1);
}
}
}
public static void main(String[] args) throws IOException, InterruptedException,
ClassNotFoundException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Counters <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Counter");
job.setJarByClass(Counters.class);
job.setMapperClass(MyCounterMap.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(2)打包并上传到Ubantu hadoop 中
使用idea 开发工具将代码打包,选择主类为mr.Counters. 假定打包后的文件为Counters.jar。将打包好的用Xftp导入/usr/local/hadoop/share/hadoop/里并应用。
在导包的同时也遇到了一些错误:

这里是提示你的导入的包,缺少了一些部分,需要你导入缺少的那部分才能运行成功,这里的问题解决就需要你重新去hadoop/share/hadoop/lib下把所有的jar导下来。在重新到底idea,把缺少的jar补好就能成功。
成功了就会出现 Usage:Counters (翻译: 用法:计数器)
在windnows 系统 创建 一个Counsers.txt 内容:
jim 1 28
Kate 0 26
tom 1
lily 0 29 22
将Counsers.txt 文件用Xftp上传至/home/主目录下,这样好查询。
(3)登录hadoop系统
sbin/start-all.sh 启动hadoop
Jps 查询进程 5个进程就是启动成功!
(4)输入数据查询结果
创建文件夹 :
Hadooop fs -mkdir -p /usr/counters/in/
Hadoop fs -mkdir -p /usr/counters/out
查询是否创建成功:
Hadoop fs -ls /usr/
cd /usr/counters ls
这2种方法都可以查询出来。
将Counsers.txt文件上传到文件夹中
hadoop fs -put /home/hadoop/counters.txt /user/counters/in/
查询是否上传成功:
hadoop fs -ls /user/counters/in/counters.txt
运行上传的Counters.jar 如果你存到你的路径下 就要cd 到文件路径下在执行
Hadoop jar Counters.jar /usr/counters/in/counters.txt /usr/counters/out
运行结果:
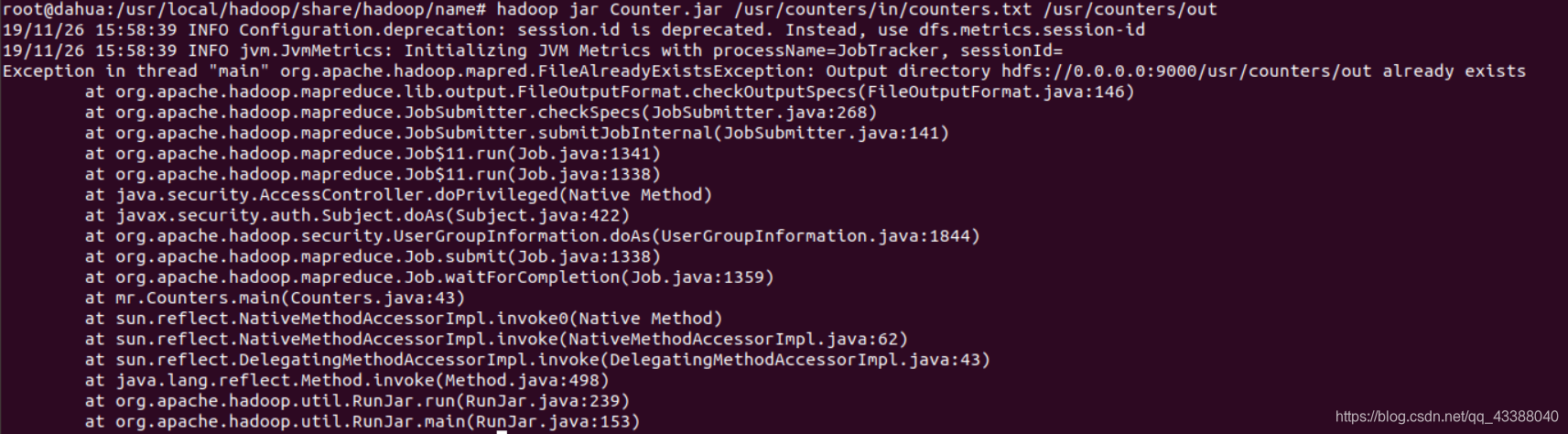
运行报错了 报错问题:你的输出文件已存在 就是我们创建的/usr/counts/out的文件夹 我们删除文件夹创新创建一个就能执行成功。(注:不要创建out,out为你的输出文件)
我的解决方法:
创建文件夹
Hadoop fs -mkdir -p /user/
在运行一遍
Hadoop jar Counters.jar /usr/counters/in/counters.txt /usr/counters/out
执行成功:
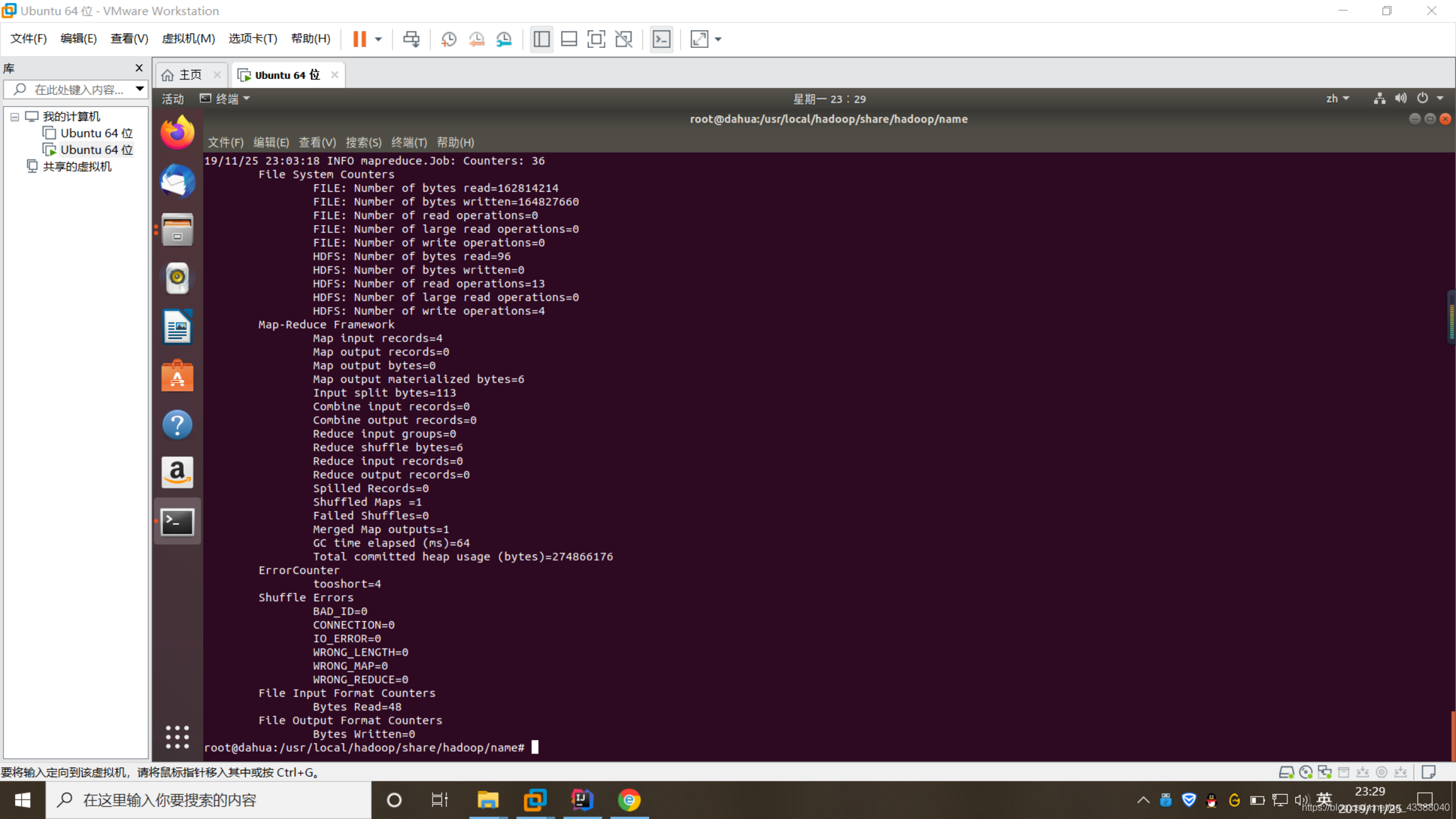
然后查询:
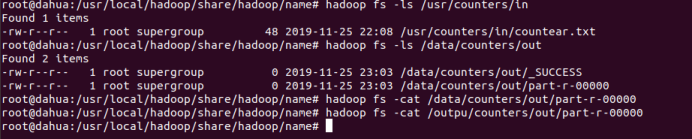
在你储存的路径下就会出现2个文件
计时器的小deom已经完成。感谢你的观看,有问题请您指出,我很乐意接受前辈的指导。
