概述
- 在模型训练可能遇到训练集错误率较小,但是验证集和测试集中错误率较大的问题,出现这种情况的时候,说明模型可能出现了过拟合问题,为了解决过拟合首先会想到正则化,当然也可以增加训练数据集。
为什么正则化可以解决过拟合
-
L2正则化
首先定义损失函数
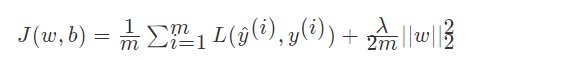
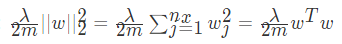
反向传播求得梯度为:
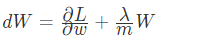
更新梯度:
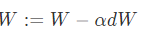
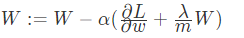
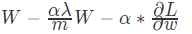
从结果可知:
实际上相当于给权重矩阵W乘以了(1- lamba/m) ,倍的权重系数, 该系数小于1 因此L2被称为权重衰减( lamba称为正则化超参数)正则化参数设置的足够大的情况下,为了使损失函数最小化,权重矩阵 W 就会被设置为接近于 0 的值,对于神经网络相当于消除了很多神经元的影响,这样比较大的神经网络就会变成一个较小的网络,使网络不在变得复杂,从而解决过拟合的问题
-
L1正则化
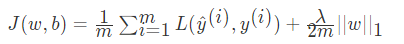
反向传播求得梯度为:

更新梯度:
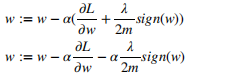
从结果可知:
L1 权重最终减少的是一个常数,使得L1正则化最后得到 w 向量中可能将存在大量的 0,使模型变得稀疏化
