L0范数是向量中非0元素的个数,若使用L0范数来规则化一个参数矩阵,就是希望其稀疏,大部分元素都是0。但L0范数难以优化求解,L1范数是L0范数的最优凸近似,且比L0范数更易优化求解。
L1和L2为什么能防止过拟合,它们有什么区别?
通过添加正则项,可以使模型的部分参数值都较小甚至趋于0,对应的特征对模型的影响就比较小,相当于对无关特征做了一个惩罚,即使它们的值波动比较大,受限于参数值很小,也不会对模型的输出结果造成太大影响。简而言之,正则化是将模型参数加入到损失函数中,能避免权值过大,模型过于陡峭,从而降低过拟合。
L1正则在损失函数中加入权值向量的L1范数,即参数的绝对值之和,L1会趋向于产生少量的特征,而无关特征权重为0,使权重稀疏:

L2正则在损失函数中加入权值向量的L2范数,即参数的平方和,L2会选择更多的特征,无关特征权重接近于0,使权重平滑:

为什么希望模型参数具有稀疏性呢?
- 实现特征的自动选择:大部分特征可能与输出是没有关系的,在训练数据中考虑这些无关特征可能会获得较小的训练误差,但对未知样本做出预测时,这些学得的无关信息反而会造成干扰,而稀疏规则化算子的引入可以将无关特征的权重置为0
- 可解释性:特征筛选后,特征数目下降易于做出解释
为什么L1正则化可以得到稀疏解,L2正则化可以得到平滑解?从贝叶斯估计的角度看,它们先验分布是什么?
可以从解空间形状、函数叠加、贝叶斯先验这三个角度进行分析。

角度1:解空间形状
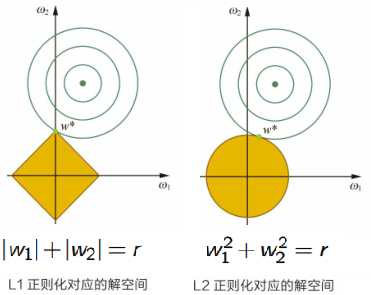
L1正则化相当于为参数定义了一个多边形的解空间,L2正则化相当于为参数定义了一个圆形的解空间。如果目标函数的最优解不是恰好落在解空间内,那么约束条件下的最优解一定是在解空间的边界上,多边形“棱角分明”的解空间更容易在尖角处与目标函数等高线碰撞出稀疏解。原因为:解空间的尖角处并不可微,任何规则化算子在参数wi=0的地方不可微且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。
在二维情况下,黄色部分是L1和L2正则项约束后的解空间,绿色等高线是凸优化问题中目标函数的等高线:
角度2:函数叠加
考虑一维的情况,多维情况类似,如图所示:

假设棕线是原始目标函数L(w)的曲线图,最小值点在蓝点处,且对应的w * 值非0。
加上L2正则化项,目标函数变成 ,其函数曲线为黄色,最小值点在黄点处,对应的w* 的绝对值减小了,但仍然非0。
加上L1正则化项,目标函数变成,其函数曲线为绿色,最小值点在红点处,对应的w是0,产生了稀疏性。
原因:对带L1正则项的目标函数求导,正则项部分产生的导数在原点左边部分是−C,在原点右边部分是C,因此,只要原目标函数的导数绝对值小于C,那么带正则项的目标函数在原点左边部分始终是递减的,在原点右边部分始终是递增的,最小值点自然在原点处。相反,L2正则项在原点处的导数是0,只要原目标函数在原点处的导数不为0,那么最小值点就不会在原点,所以L2只有减小w绝对值的作用,对解空间的稀疏性没有贡献。
在一些在线梯度下降算法中,往往会采用截断梯度法来产生稀疏性,这同L1正则项产生稀疏性的原理是类似的。
角度3:贝叶斯先验
L1正则化相当于对模型参数w引入了拉普拉斯先验,L2正则化相当于引入了高斯先验。拉普拉斯先验分布在极值点(0点)处是一个尖峰,参数w取值为0的可能性更高。高斯分布在极值点(0点)处是平滑的,参数w在极值点附近取不同值的可能性是接近的,这使得L2正则化只会让w更接近0点,但不会等于0。

为什么加入正则项就是定义了一个解空间约束?为什么L1和L2的解空间是不同的?
以L2正则化为例,通过KKT条件解释:“带正则项”和“带约束条件”是等价的,为了约束w的可能取值空间,为该最优化问题加上一个约束,即:w的L2范数的平方不能大于m:
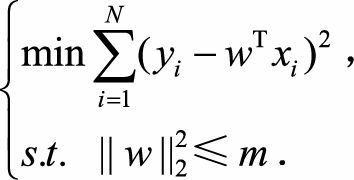
为了求解带约束条件的凸优化问题,写出拉格朗日函数
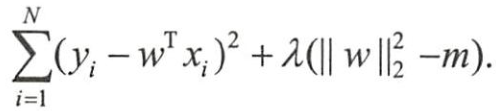
若w*和λ*分别是原问题和对偶问题的最优解,则根据KKT条件,它们应满足
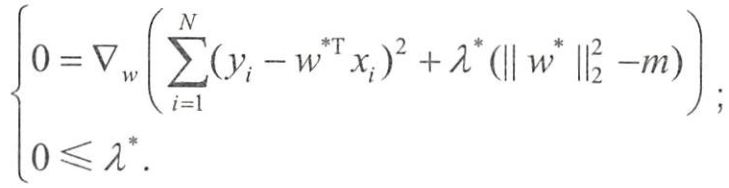
第一个式子就是w*为带L2正则项的优化问题的最优解的条件,而λ*就是L2正则项前面的正则参数。
正则化补充:
弹性网(Elastic Net):

使用正则化的顺序:L2 -> 弹性网 -> L1。特征不是特别多时,L2计算更精准,但计算量较大;特征较多时使用弹性网,同时结合了L1和L2的优势,可以进行特征选择;L1虽然可以进行特征选择,但会损失一些信息,可能会增大模型的偏差。
参数共享:在卷积神经网络中,卷积操作通过参数共享,减少模型参数、降低模型复杂度,从而减少模型过拟合风险
稀疏表征:与L1正则化可以使模型参数稀疏化相似,稀疏表征通过某种惩罚措施来抑制神经网络隐藏层中部分神经元,使其输出为零或接近零,当信息输入神经网络时,只有关键部分神经元处于激活状态。(dropout、LReLU)
从数学角度解释L2为什么能提升模型的泛化能力
https://www.zhihu.com/question/35508851
https://blog.csdn.net/zouxy09/article/details/24971995
https://davidrosenberg.github.io/ml2015/docs/2b.L1L2-regularization.pdf