绪论
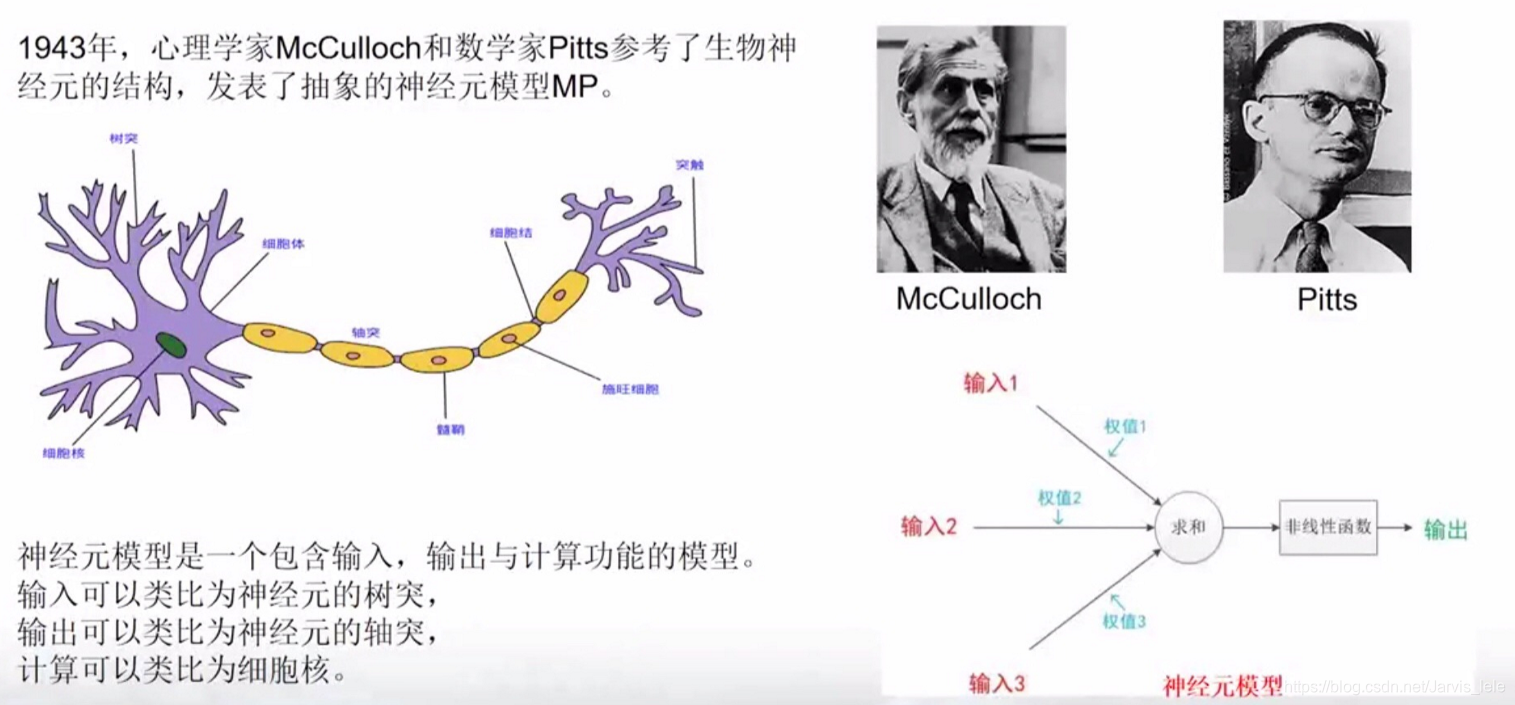
图灵在1950年写过一篇论文《计算机器与智能》,图灵让我们思考:“机器能否拥有智能?(Can machines think?)”这个问题。图灵成功定义了什么是计算机器(即图灵机),但却不能定义什么是智能(Think),没有办法用机器或算法来准确定义。因此图灵设计了一个模拟测试——图灵测试(一种用于判定机器是否具有智能的试验方法)。图灵测试的核心想法是要求计算机在没有直接物理接触的情况下接受人类的询问,并尽可能把自己伪装成人类。

试验过程:提问者和回答者隔开,提问者通过一些装置(如键盘)向机器随意提问。多次测试,如果有超过30%的提问者认为回答问题的是人而不是机器,那么这台机器就通过测试,具有了人工智能。
人工智能&机器学习&深度学习
1、人工智能
机器模拟人的意识和思维。
2、机器学习
机器学习是一种统计学方法,计算机利用已有的数据,得出某种模型,再利用这个模型来预测结果。在历史数据的基础上,不断训练,随经验增加,预测的效果会更好。(以预测班车到达时间为例)
机器学习发展历史回顾

add.“花书”中对于机器学习的描述:Ai系统需要具备自己获取知识的能力,即从原始数据中提取模式的能力,这种能力被称为机器学习。
- 机器学习最主要的应用:
对于连续数据的预测(预测房价)
对于离散数据的分类(判定是否为肿瘤)
3、深度学习
模仿人类的神经网络,在计算机中建立计算机的神经网络。
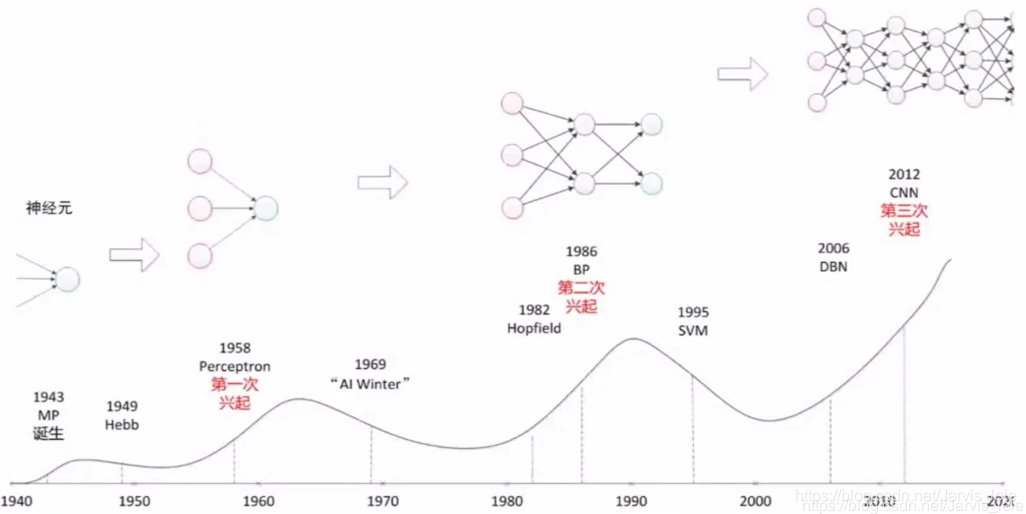
- 神经网络的发展过程:
- 机器学习和深度学习的对比
现在的你应该已经对机器学习和深度学习有所了解,接下来我们将会学习其中一些重点,并比较两种技术。
① 数据依赖性
深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长。当数据很少时,深度学习算法的性能并不好。这是因为深度学习算法需要大量的数据来完美地理解它。另一方面,在这种情况下,传统的机器学习算法使用制定的规则,性能会比较好。下图总结了这一事实。
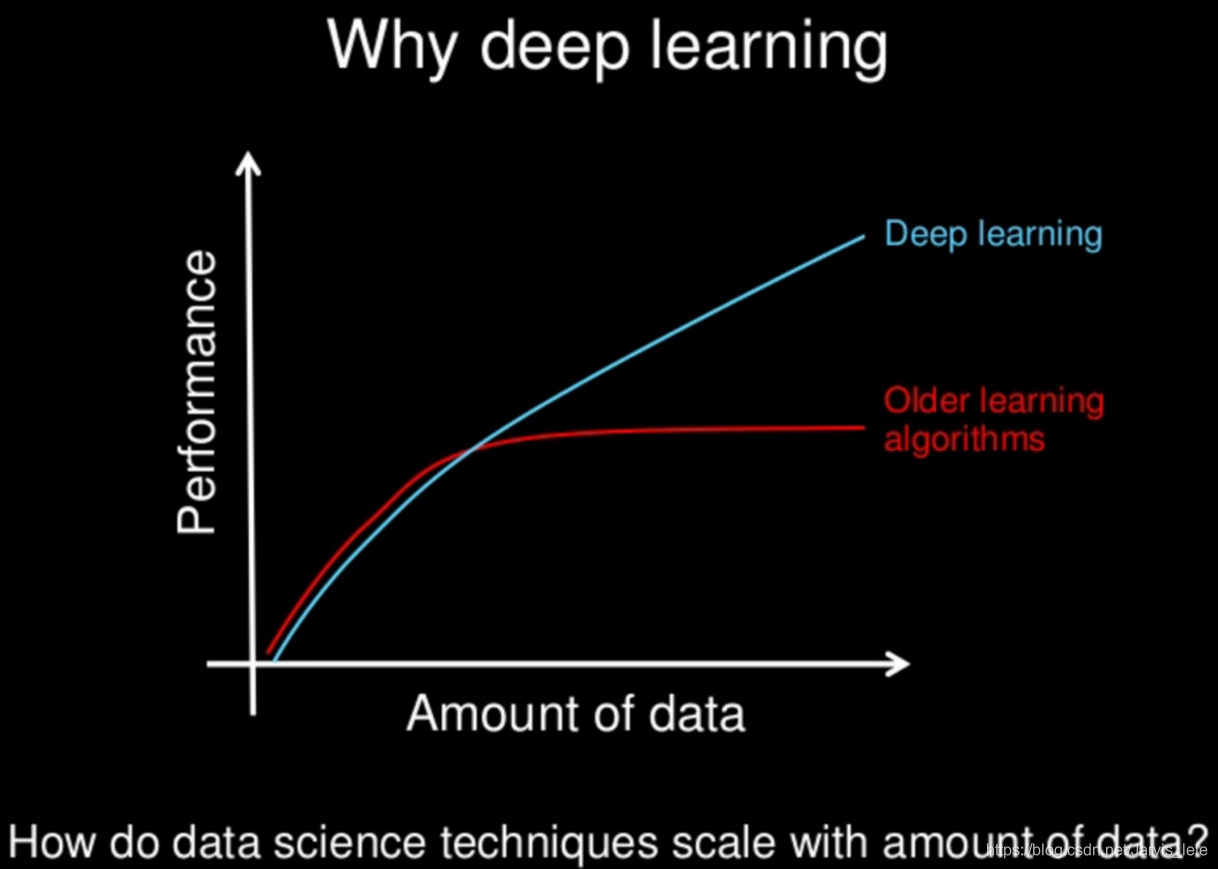
② 特征处理
特征处理是将领域知识放入特征提取器里面来减少数据的复杂度并生成使学习算法工作的更好的模式的过程。特征处理过程很耗时而且需要专业知识。
在机器学习中,大多数应用的特征都需要专家确定然后编码为一种数据类型。
特征可以使像素值、形状、纹理、位置和方向。大多数机器学习算法的性能依赖于所提取的特征的准确度。
深度学习尝试从数据中直接获取高等级的特征,这是深度学习与传统机器学习算法的主要的不同。基于此,深度学习削减了对每一个问题设计特征提取器的工作。例如,卷积神经网络尝试在前边的层学习低等级的特征(边界,线条),然后学习部分人脸,然后是高级的人脸的描述。更多信息可以阅读神经网络机器在深度学习里面的有趣应用。
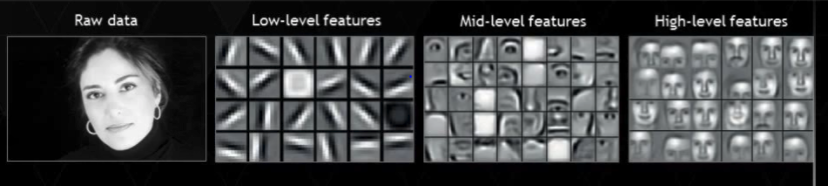
③ 问题解决方式
当应用传统机器学习算法解决问题的时候,传统机器学习通常会将问题分解为多个子问题并逐个子问题解决最后结合所有子问题的结果获得最终结果。相反,深度学习提倡直接的端到端的解决问题。
举例说明:
假设有一个多物体检测的任务需要图像中的物体的类型和各物体在图像中的位置。

传统机器学会将问题分解为两步:物体检测和物体识别。首先,使用一个边界框检测算法扫描整张图片找到可能的是物体的区域;然后使用物体识别算法(例如 SVM 结合 HOG )对上一步检测出来的物体进行识别。
相反,深度学习会直接将输入数据进行运算得到输出结果。例如可以直接将图片传给 YOLO 网络(一种深度学习算法),YOLO 网络会给出图片中的物体和名称。
④ 执行时间
通常情况下,训练一个深度学习算法需要很长的时间。这是因为深度学习算法中参数很多,因此训练算法需要消耗更长的时间。最先进的深度学习算法 ResNet完整地训练一次需要消耗两周的时间,而机器学习的训练会消耗的时间相对较少,只需要几秒钟到几小时的时间。
但两者测试的时间上是完全相反。深度学习算法在测试时只需要很少的时间去运行。如果跟 k-nearest neighbors(一种机器学习算法)相比较,测试时间会随着数据量的提升而增加。不过这不适用于所有的机器学习算法,因为有些机器学习算法的测试时间也很短。
⑤ 可解释性
至关重要的一点,我们把可解释性作为比较机器学习和深度学习的一个因素。
我们看个例子。假设我们适用深度学习去自动为文章评分。深度学习可以达到接近人的标准,这是相当惊人的性能表现。但是这仍然有个问题。深度学习算法不会告诉你为什么它会给出这个分数。当然,在数学的角度上,你可以找出来哪一个深度神经网络节点被激活了。但是我们不知道神经元应该是什么模型,我们也不知道这些神经单元层要共同做什么。所以无法解释结果是如何产生的。
另一方面,为了解释为什么算法这样选择,像决策树(decision trees)这样机器学习算法给出了明确的规则,所以解释决策背后的推理是很容易的。因此,决策树和线性/逻辑回归这样的算法主要用于工业上的可解释性。
4、三者关系


