一种用于端到端音频分离的多尺度神经网络
摘要:
大多数声源分离的模型通常是依赖于幅度频谱,然而忽略声音的相位信息,使幅度频谱前端的分离性能依赖于超参数。我们研究了一种时域端到端信源分离模型,允许建模相位信息,避免固定幅度频谱转换。由于音频的高采样,在采样层上使用长时间输入上下文是困难的,但高质量的分离结果是依赖长期的时间相关性。在此背景下,我们提出了Wave-U-Net,一种适应性U-Net的一维时域函数在不同的时间尺度上,反复对feature map进行重新分组,计算和组合feature。
我们进一步改进模型架构,包括一个输出层实施了音源加和、上采样技术和上下文感知的预测框架,以减少输出瑕疵。
唱歌声音分离的实验表明我们的体系结构的性能可与最先进的基于幅度频谱的U-Net体系结构相媲美。
最后,我们揭示了异常值的一个问题目前使用SDR评估指标,并建议报告基于排名的统计数据,以缓解这一问题
1.简介:
目前音频源分离的方法几乎完全依赖于音频信号的谱图表示[6,7],因为它们允许直接访问时间和频率上的组件。特别是对输入混合信号进行短时傅里叶变换(STFT)后,复值谱图被分解为幅值和相位分量。然后,只有大小被输入到参数模型,它返回估计的声源单独声源的光谱图大小。为了产生相应的音频信号,这些幅度与混合相位相结合,然后用反STFT转换到时域。可选地,可以使用Griffin-Lim算法[5]分别为每个源恢复 阶段。
这种方法有几个局限性。首先,STFT输出依赖于许多参数,例如音频帧的大小和重叠,这些参数会影响时间和频率分辨率。
理想情况下,这些参数应该与分离模型的参数一起优化,以最大化特定分离任务的性能。然而,在实践中,转换参数被固定为特定的值。
其次,由于分离模型没有对源相位进行估计,因此通常假设源相位等于混合相位,这对于重叠部分是不正确的。或者,GriffinLim算法可以用于找到一个信号的近似值,这个信号的大小等于估计的大小,但是速度很慢,而且通常不存在这样的信号[8。
最后,在估计源时忽略了混合阶段,这可能会限制性能。因此,分离模型最好是学会直接估计源信号,包括它们的相位。
为了解决上述问题,最近提出了几种直接作用于时域音频信号的音频处理模型,包括语音去噪作为一项与一般音频源分离相关的任务[1,16,18]。在这些初步结果的启发下,我们在本文中研究了完全端到端时域分离系统在面临未解决的挑战时的潜力。
特别是,目前还不清楚这样的系统是否能够有效地处理音频中存在的非常长期的时间依赖性,因为它的采样率很高。
此外,额外的阶段信息是否确实对任务有益,或者嘈杂的阶段是否可能对这样一个系统中的学习动态有害,这一点还不是很明显。
总之,我们在本文中的贡献可以总结如下
- 我们提出了Wave-U-Net,这是对U-Net体系结构的一维调整[7,19],它可以在时域中直接分离源,并且可以考虑大的时间上下文。
- 与以前的工作相比,我们展示了一种为模型提供额外输入上下文的方法,以避免输出窗口边界上的工件[7,16]。
- 为了避免伪影,我们用线性插值后的普通卷积取代了之前工作[7,16]中用于特征图上采样的横纹置换卷积。
- Wave-U-Net实现了良好的多乐器和歌唱声音分离,后者比我们在可比设置下训练的最先进的网络架构[7]的重新实现要好。
- 由于Wave-U-Net可以处理多声道音频,我们比较了立体声与单声道声源分离的性能,
- 重点讨论了常用的信噪比评估指标的一个问题,并提出了一个解决方案。
值得注意的是,我们期望[7]中呈现的当前SOTA模型比我们在这里展示的产生更高的分离质量,因为[7]中使用的训练数据集设计良好、高度无偏且相当大。
但是,我们认为,我们与在类似条件下训练的重新实现的比较可能表明相对的性能改进。
2.相关的工作
为了解决以往文献[6,11,13,14,20,23]中广泛使用的固定谱表示问题,开发了与分离网络联合训练的自适应谱图计算前端[24],该前端对产生的幅值谱图进行操作。尽管性能相对提高了,但是模型并没有利用混合相位来更好地预测源星等,也没有输出源相位,因此必须使用混合相位来进行源信号重构,这两者都限制了性能。
据我们所知,只有TasNet[12]和MRCAE[4]系统在时域处理音频源分离的一般问题。
任务网络将信号分解成一组基信号和权重
然后在权重上创建一个掩码,最后用来重构源信号。
该模型适用于语音分离任务。
然而,这项工作在概念上做了权衡,允许低延迟应用程序,而我们关注离线应用程序,允许我们利用大量上下文信息。
多分辨率卷积自动编码器(MRCAE)[4]使用了两层卷积和置换卷积。
作者认为,不同的卷积滤波器大小可以检测出不同分辨率的音频频率,但它们只能在一个时间分辨率上工作(输入的分辨率),因为网络不执行任何重采样。
由于输入和输出只包含1025个音频样本(相当于23 ms),因此它只能利用很少的上下文信息。
此外,在测试时,输出段使用规则的间隔重叠,然后合并,这与网络的训练方式不同。
这种不匹配和较小的上下文可能会影响性能,这也解释了为什么所提供的合理示例展示了许多工件。
为了实现语音增强和去噪的目的,开发了SEGAN[16],采用了一种带有编码器和解码器通道的神经网络,该神经网络的每一层的特征图分辨率分别是原来的一半和两倍,特征跳过了编码器和解码器层之间的连接。
当我们使用类似的架构时,我们纠正了生成输出中使用strided transpconvolutions时的别名问题,如[15]所示。
此外,该模型不能很好地预测音频样本接近其边界输出,因为它没有提供额外的输入上下文,这是我们使用带有适当填充的卷积来解决的问题。
目前还不清楚model s的性能能否转移到其他更具挑战性的音频源分离任务上。
Wavenet[1]被用来对[18]进行语音去噪,使每个预测都有一个非因果的条件输入和一个并行的样本输出,它的基础是在上下文信息中使用成倍增长的膨胀因子反复应用扩展卷积。
虽然这种架构具有很高的参数效率,但是内存消耗很高,因为每个由扩展卷积产生的特征图仍然以原始音频采样率作为分辨率。
相比之下,我们的方法是基于具有更多特征和越来越低分辨率的特征图来计算长期依赖关系。
这节省了内存并启用了大量高级功能,这些功能可能不需要样本级别的分辨率就可以使用,比如仪器活动或当前测量中的位置。
3.wave-u-net 模型
我们的目标是分离一个混合波形 转换为K源波形S1;:::;SK
or C为音频通道数, 和 分别为音频样本数。对于具有额外输入上下文的模型变量,我们有 并对输入的中心部分进行预测。
| 模块 | 操作 | 形状 |
|---|---|---|
| 输入 | input | (16384,1) |
| 降采样重复i=1~L | Conv1D( ) Decimate | |
| Decimate | (4,288) | |
| Conv1D( ) | (4,312) | |
| 上采样重复i=1~L | Upsample | |
| Concat(DS block i) | ||
| Conv1D( ) | (16384,24) | |
| Concat(input) | (16384,25) | |
| Conv1D(K,1) | (16382,2) |
Conv1D(x,y)表示一维卷积大小为y的窗口x,包括零填充,之后接一个LeakyReLU 激活函数
Decimate 表示每一个时间步长上,将时间的结果进行二等分
Upsample 上采样,使用线性差值
Concat 连接个高层的信息,结合局部信息x
3.1 基础模型结构
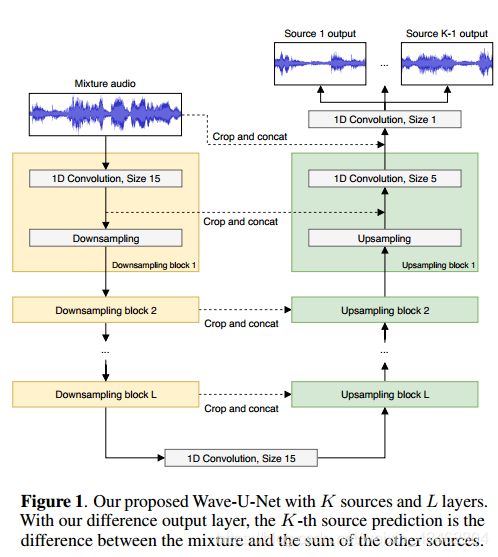
Wave-U-Net架构示意图如图1所示。
它使用向下采样(DS)块在较粗的时间尺度上计算越来越多的高级特性。
这些特征与早期使用上采样(US)块计算出的局部高分辨率特征相结合,生成用于进行预测的多尺度特征。
网络总共有L个层,每个连续层的运行时间分辨率只有前一层的一半。
对于K个估计源,模型返回区间(1;1),每个源音频样本一个。
详细的体系结构如表1所示。Conv1D(x,y)表示与大小为y的x过滤器的一维卷积。它包括基本架构的零填充,然后是一个LeakyReLU激活(除了最后一个使用tanh的激活)。每隔一个时间步抽取丢弃特征使时间分辨率减半。
Upsample在时间方向上以2倍的倍数执行上采样,对此我们使用线性插值(详见3.1.1节)。Concat(x)将当前的高级特性与更多的本地特性x连接起来。在基本架构的扩展(见下文)中,Conv1D不涉及零填充,x首先被中心裁剪,因此它具有与当前层相同的时间步长。
3.1.1避免因向上采样而产生的混叠伪影
许多相关的方法都是使用带跨步的转置卷积对特征图进行向上采样[7,16]。
这可以在输出中引入混叠效果,如图像生成网络[15]的情况所示。
在最初的测试中,我们还发现了在我们的Wave-U-Net模型中以高频嗡嗡噪声的形式使用卷积作为上采样块时产生的伪迹。
置换卷积的滤波器大小为k,步幅为x >
1可以看作是卷积,应用于特征映射,在每个原始值[2]之间填充x 1个零。
我们怀疑,在没有后续低通滤波的情况下,零交织将高频模式引入到特征图中,如图2所示,这也导致了最终输出中的高频噪声。
因此,我们对上采样进行线性插值,以保证特征空间的时间连续性,而不是进行移位的大步卷积,然后进行正常的卷积。
在最初的测试中,我们没有观察到任何高频声音伪影在输出时都与此技术取得了非常相似的性能。
3.2架构改进
上一节描述了Wave-U-Net的基线变量。
下面,我们将描述Wave-U-Net的一系列架构改进,旨在提高模型性能。
我们的基线模型通过独立地应用K个卷积滤波器,并在最后一个feature map上加入tanh非线性,输出每个K个源的一个源估计。
在我们考虑的分离任务中,混合信号是其源信号分量的和:
由于我们的基线模型不受这种方式的约束,它必须近似地学习这个规则,以避免非常不可能的输出,这可能会减慢学习速度并降低性能。
因此,我们使用不同的输出层限制输出
,执行
:只有K-1卷积过滤器的大小应用的最后特征映射网络,其次是双曲正切非线性,估计第一个K -1源信号。
最后一个源被简单地计算为
。
这种类型的输出也用于语音去噪[18]作为节能的一部分损失,而且可以找到类似的想法非常普遍在spectrogrambased源分离面具的形式分发的能量输入混合大小输出源。我们研究了引入该层及其可加性假设的影响,因为它取决于数据满足该可加性的程度。
3.2.2在适当的输入上下文和重新采样的情况下进行预测
在之前的工作[4,7,16]中,在适当的输入上下文和重新采样的情况下,在进行卷积之前,输入和feature map用0填充,这样得到的feature map的维数不会发生变化,如图2a所示。
这简化了网络s的实现,因为输入和输出维度是相同的。
这种方式有效地扩展了输入,在输入的开始和结束都使用了静音。
然而,从全音频信号中的随机位置出发,边界处的信息就变得人为了,也就是说,这个摘录的时间背景在全音频信号中给出,但被忽略,并假定为无声的。
如果没有适当的上下文信息,网络就很难预测序列开始和结束附近的输出值。
因此,在测试时简单地将输出连接为非重叠段来获得完整音频信号的预测,可以在段边界上创建可听的构件,因为在没有正确上下文信息的情况下,相邻输出可能不一致。
在第5.2节中,我们将在实践中调查这种行为
作为一种解决方案,我们使用没有隐式填充的卷积,并提供比输出预测更大的混合输入,以便在正确的音频上下文中计算卷积(参见图2b)。
由于这减少了特征映射的大小,我们限制了网络可能的输出大小,以便使特征映射总是足够大,以满足后续的卷积。
此外,当重新采样feature maps时,feature dimensions往往恰好减半或加倍[7,16],如图2a所示,对于转置的strided convolution。
然而,这必然涉及到在边界外推至少一个值,这又会引入工件。
相反,我们只在已知的邻近值之间插入,并保留最开始和最后的项,从n产生2n1项,反之亦然,如图2b所示。
为了在保持边界值不变的情况下,恢复抽取后的中间值,我们保证特征图的维数为奇数。
3.2.3立体通道为了适应C通道的多通道输入,我们简单地将输入M从lm1改为lmc矩阵。
由于第二维被视为一个特征信道,所以网络的第一个卷积考虑了所有的输入信道。
对于带有C通道的多通道输出,我们修改了输出组件,使其具有K个独立的卷积层,每个层有大小为1的过滤器和C过滤器。
对于不同的输出层,我们只使用k1这样的卷积层。
我们在C = 2的情况下使用这种简单的方法对立体声录音进行实验,并研究使用立体声而不是单声道估计时源分离指标的改进程度。
3.2.4上采样的Wave-U-net
线性插值学习上采样简单,无参数,鼓励特征连续性。
但是,这可能对网络容量的限制太大了。
也许,这些特征图中使用的特征空间并不是结构化的,因此特征空间中两点之间的线性插值本身就是一个有用的点,因此,一个学习的上采样可以进一步提高性能。
为此,我们提出了学习上采样层。
这可以实现为一个一维卷积跨越时间与F滤波器的大小为2,没有填充与适当的约束矩阵。学习的插值层可以被看作是简单线性插值的概括,因为它允许特征的凸组合与权重0:5之外。
4. 实验
我们以低音、鼓、吉他、人声和其他乐器为分类,评估我们的模型在两项任务上的表现:唱腔分离和音乐分离。
4.1 数据集
来自MUSDB[17]多径数据库训练分区的75条轨迹被随机分配给我们的训练集,剩下的25条轨迹形成验证集,用于早期停止。
在包含50首歌曲的MUSDB测试分区上评估最终性能。
对于歌唱语音分离,我们还将整个CCMixter数据库[9]添加到训练集中。作为两个任务的数据扩充,我们将源信号乘以一个从间隔[0:7]中均匀选择的因子;
设置输入混合信号为源信号的和。
不做进一步的数据预处理,只转换到单声道(立体声模型除外),并向下采样到22050 Hz。
4.2训练过程
在训练过程中,随机采样音频摘要,并对带有输入上下文的模型进行相应的输入填充。
作为损失,我们在批处理中对所有源输出样本使用均方误差(MSE)。
我们使用与学习速率0:0001亚当优化器,衰减率β1 = 0:9β2 = 0:999和批处理大小为16。
我们将2000个迭代定义为一个epoch,并在验证集没有改进的20个epoch之后执行早期停止,以MSE损失来度量。
之后,对最后一个模型进行进一步微调,批量增加一倍,学习率降低到0:00001,再次调整到20个epoch,验证损失没有改善。
最后选择验证损失最优的模型。
4.3模型设置以及变量
对于我们的基线模型,我们使用Lm = Ls = 16384输入和输出样本,L = 12层,Fc =每层24个额外的过滤器,以及过滤器大小fd = 15和fu = 5
确定的影响3.2节中描述的模型改进,我们训练一个基线模型M1如3.1节所述和模型M2 M5,添加不同的输出层从3.2.1节(M2),输入上下文和重采样3.2.2节(M3),立体声通道从3.2.3节(M4),和学习从3.2.4条部分upsampling (M5),也包含所有的特征分别之前的模型。
我们将上述(M4)的最佳模型应用于多仪器分离(M6)。
具有输入上下文(M3到M6)的模型有Lm = 147443输入和Ls = 16389输出样本。
为了与之前的工作进行比较,我们还训练了基于声谱图的U-Net架构7,实现了最先进的声音分离性能,并在相同的条件下训练了一个Wave-U-Net比较模型(M7),这两个模型都使用了基于音频的MSE损耗和采样到8192 Hz的mono信号。
M4 M7是基于最好的模型,但将Lm = 233459和Ls = 102405相比有非常相似的输出尺寸得以(Ls = 98650个样本),Fc = 34使我们的网络一样的大小得以参数(20米),和初始批量大小设置为四由于高数量的内存需要每个样品。
为了训练U7,我们通过反STFT操作反向传播误差,该操作用于从估计的谱图大小和混合相位构建源音频信号。
在[7]之后,我们也对同样的模型进行了频谱强度(U7a)的L1损失的训练。
自培训过程和损失是完全相同的网络得以和M7,我们可以相当比较这两种架构,确保性能差异并不仅仅因为出现的训练数据量或使用何种类型的损失函数,并与spectrogrambased损失(U7a)。
尽管我们努力进行了全面的模型比较,但请注意,在[7]中使用的一些训练设置(如学习率)可能与我们的有所不同(而且部分未知),并且使用U7和U7a可以提供比这里显示的更好的性能,即使使用相同的数据集也是如此。
| Model name (from paper) | Description | Separate vocals or multi-instrument? | Command for training |
|---|---|---|---|
| M1 | Baseline Wave-U-Net model | Vocals | python Training.py |
| M2 | M1 + difference output layer | Vocals | python Training.py with cfg.baseline_diff |
| M3 | M2 + proper input context | Vocals | python Training.py with cfg.baseline_context |
| M4 | BEST-PERFORMING: M3 + Stereo I/O | Vocals | python Training.py with cfg.baseline_stereo |
| M5 | M4 + Learned upsampling layer | Vocals | python Training.py with cfg.full |
| M6 | M4 applied to multi-instrument sep. | Multi-instrument | python Training.py with cfg.full_multi_instrument |
| M7 | Wave-U-Net model to compare with SotA models U7,U7a | Vocals | python Training.py with cfg.baseline_comparison |
| U7 | U-Net replication from prior work, audio-based MSE loss | Vocals | python Training.py with cfg.unet_spectrogram |
| U7a | Like U7, but with L1 magnitude loss | Vocals | python Training.py with cfg.unet_spectrogram_l1 |
We also include the following models not part of the paper (also with pre-trained weights for download!):
| Model name (not in paper) | Description | Separate vocals or multi-instrument? | Command for training |
|---|---|---|---|
| M5-HighSR | M5 with 44.1 KHz sampling rate | Vocals | python Training.py with cfg.full_44KHz |
M5-HighSR is our best vocal separator, reaching a median (mean) vocal/acc SDR of 4.95 (1.01) and 11.16 (12.87), respectively.