场景描述
在读取一个zip文件的时候,这个zip文件的路径是在如下图红框所示的位置复制的。

程序运行的时候,一直报文件不存在。后改为在文件夹地址栏复制之后就找到文件了。
但两个文件路径字符串看起来是完全一致的,但equels比较和length却不相同,如下图所示。

问题分析
根据上述情况分析,length不同,则char数组长度不同。于是调试两个字符串的char数组和byte数组,结果如下所示。
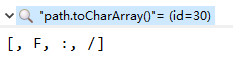
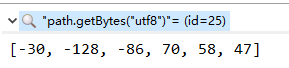
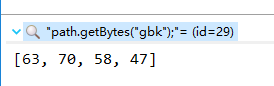
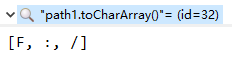

从以上结果中看出,path字符串中有一个不可见字符,其余部分完全相同。所以问题肯定是和这个不可见字符有关。
那么这个字符到底是什么,好奇心驱使我针对这个不可见字符是什么做了以下尝试。
后面为了方便分析去掉其他字符。
1.trim之后依然存在,排除是空格。
2.path.getBytes("gbk");将该字符编码转为GBK后,打印出来的字符为?,对照ASCII表Unicode编码[63]为?, 。这是由utf8转gbk乱码的原因,所以排除是复制的时候乱码导致的。
。这是由utf8转gbk乱码的原因,所以排除是复制的时候乱码导致的。
3.转换该不可见字符的ASCII
char charAt = path.charAt(0);
int c = (int)charAt;
System.out.println(c);
结果为
8234
在这里查询ASCII对照表,该字符的Unicode编码为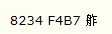 ,但感觉还是不对,不应该是这个字符,此处查询方式不知道对不对,存疑。
,但感觉还是不对,不应该是这个字符,此处查询方式不知道对不对,存疑。
4.想到既然打印这个不可见字符的length为1,那么常用的字符工具类判空结果如何呢。
String path = "";
System.out.println("Hutool---"+StrUtil.isBlank(path));//Hutool cn.hutool.core.util.StrUtil
System.out.println("commons.lang3---"+StringUtils.isBlank(path));//org.apache.commons.lang3.StringUtils
结果如下:
Hutool---true
commons.lang3---false
经过查看Hutool的源码并调试,结果如下。

十六进制的0x202a转成十进制正是该字符的编码8234。
而commons.lang3只进行了空白字符的校验所以结果为false。


原因分析
经过以上分析最终找到这个字符是'\u202a',在\u202a 神奇的控制字符这篇博文中找到答案,博主的情况和我的一样。另外博主提供了一个更方便的分析方法,学到了。
解决方法
path.replaceAll("\u202a", "");
测试结果:
String path = "";
System.out.println("path u202a indexOf = "+path.indexOf("\u202a"));
System.out.println("path length = "+path.length());
String okPath = path.replaceAll("\u202a", "");
System.out.println("okPath u202a indexOf = "+okPath.indexOf("\u202a"));
System.out.println("okPath length = "+okPath.length());
System.out.println("equals = "+okPath.equals(""));
path u202a indexOf = 0
path length = 1
okPath u202a indexOf = -1
okPath length = 0
equals = true
总结
以上记录一下这个问题。
\u代表Unicode编码,是一个字符;
\x对应UTF-8编码的数据,通过转化规则可转换为Unicode编码;
知道原因后再查找资料就容易多了,也证明了上面问题分析中的第3条的查询方式有误。
在这里查询得到相同结果。

参考Unicode Chart