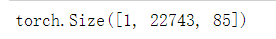1.CBL(conv+bn+LeakyRelu)
def conv2d(filter_in, filter_out, kernel_size, stride=1):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.LeakyReLU(0.1)),
]))
2.SPP(SpatialPyramidPool)
class SpatialPyramidPooling(nn.Module):
def __init__(self, pool_sizes=[5, 9, 13]):
super(SpatialPyramidPooling, self).__init__()
self.maxpools = nn.ModuleList([nn.MaxPool2d(pool_size, 1, pool_size//2) for pool_size in pool_sizes])
def forward(self, x):
features = [maxpool(x) for maxpool in self.maxpools[::-1]]
features = torch.cat(features + [x], dim=1)
return features
3. 卷积+上采样
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
conv2d(in_channels, out_channels, 1),
nn.Upsample(scale_factor=2, mode='nearest')
)
def forward(self, x,):
x = self.upsample(x)
return x
4. 三次卷积块
def make_three_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
5.五次卷积块
def make_five_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
6.最后的Head输出
def yolo_head(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 3),
nn.Conv2d(filters_list[0], filters_list[1], 1),
)
return m
7.HEAD构建
class YoloBody(nn.Module):
def __init__(self, num_anchors, num_classes):
super(YoloBody, self).__init__()
# backbone
self.backbone = darknet53()
self.conv1 = make_three_conv([512,1024],1024)
self.SPP = SpatialPyramidPooling()
self.conv2 = make_three_conv([512,1024],2048)
self.upsample1 = Upsample(512,256) # 上采样
self.conv_for_P4 = conv2d(512,256,1)
self.make_five_conv1 = make_five_conv([256, 512],512)
self.upsample2 = Upsample(256,128)
self.conv_for_P3 = conv2d(256,128,1)
self.make_five_conv2 = make_five_conv([128, 256],256)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
# 4+1+num_classes
final_out_filter2 = num_anchors * (5 + num_classes)
self.yolo_head3 = yolo_head([256, final_out_filter2],128)
self.down_sample1 = conv2d(128,256,3,stride=2) # 下采样
self.make_five_conv3 = make_five_conv([256, 512],512)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter1 = num_anchors * (5 + num_classes)
self.yolo_head2 = yolo_head([512, final_out_filter1],256)
self.down_sample2 = conv2d(256,512,3,stride=2)
self.make_five_conv4 = make_five_conv([512, 1024],1024)
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter0 = num_anchors * (5 + num_classes)
self.yolo_head1 = yolo_head([1024, final_out_filter0],512)
def forward(self, x):
# backbone
x2, x1, x0 = self.backbone(x)
P5 = self.conv1(x0)
P5 = self.SPP(P5)
P5 = self.conv2(P5)
P5_upsample = self.upsample1(P5)
P4 = self.conv_for_P4(x1)
P4 = torch.cat([P4,P5_upsample],axis=1)
P4 = self.make_five_conv1(P4)
P4_upsample = self.upsample2(P4)
P3 = self.conv_for_P3(x2)
P3 = torch.cat([P3,P4_upsample],axis=1)
P3 = self.make_five_conv2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample,P4],axis=1)
P4 = self.make_five_conv3(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample,P5],axis=1)
P5 = self.make_five_conv4(P5)
out2 = self.yolo_head3(P3)
out1 = self.yolo_head2(P4)
out0 = self.yolo_head1(P5)
return out0, out1, out2
测试
# 随机生成输入数据
rgb = torch.randn(1, 3, 608, 608)
# 定义网络
net = YoloBody(3, 80)
# 前向传播
out = net(rgb)
# 打印输出大小
print('-----'*5)
print(out[0].shape)
print('-----'*5)
print(out[1].shape)
print('-----'*5)
print(out[2].shape)
print('-----'*5)

Head的Decode层
1.yolo_decode
# output:(B,A*n_ch,H,W) ---> (B,A,H,W,n_ch)
def yolo_decode(output, num_classes, anchors, num_anchors, scale_x_y):
device = None
cuda_check = output.is_cuda
if cuda_check:
device = output.get_device()
n_ch = 4+1+num_classes # n_ch == [tw,ty,tw,th,obj,class]
A = num_anchors
B = output.size(0)
H = output.size(2)
W = output.size(3)
# (B,A,n_ch,H,W) ---> (B,A,H,W,n_ch)
output = output.view(B, A, n_ch, H, W).permute(0,1,3,4,2).contiguous()
bx, by = output[..., 0], output[..., 1]
bw, bh = output[..., 2], output[..., 3]
det_confs = output[..., 4]
cls_confs = output[..., 5:]
bx = torch.sigmoid(bx)
by = torch.sigmoid(by)
bw = torch.exp(bw)*scale_x_y - 0.5*(scale_x_y-1)
bh = torch.exp(bh)*scale_x_y - 0.5*(scale_x_y-1)
det_confs = torch.sigmoid(det_confs)
cls_confs = torch.sigmoid(cls_confs)
grid_x = torch.arange(W, dtype=torch.float).repeat(1, 3, W, 1).to(device)
grid_y = torch.arange(H, dtype=torch.float).repeat(1, 3, H, 1).permute(0, 1, 3, 2).to(device)
bx += grid_x
by += grid_y
for i in range(num_anchors):
bw[:, i, :, :] *= anchors[i*2]
bh[:, i, :, :] *= anchors[i*2+1]
bx = (bx / W).unsqueeze(-1)
by = (by / H).unsqueeze(-1)
bw = (bw / W).unsqueeze(-1)
bh = (bh / H).unsqueeze(-1)
#boxes = torch.cat((x1,y1,x2,y2), dim=-1).reshape(B, A*H*W, 4).view(B, A*H*W, 1, 4)
boxes = torch.cat((bx, by, bw, bh), dim=-1).reshape(B, A * H * W, 4)
det_confs = det_confs.unsqueeze(-1).reshape(B, A*H*W, 1)
cls_confs =cls_confs.reshape(B, A*H*W, num_classes)
# confs = (det_confs.unsqueeze(-1)*cls_confs).reshape(B, A*H*W, num_classes)
outputs = torch.cat([boxes, det_confs, cls_confs], dim=-1)
#return boxes, confs
return outputs
class YoloLayer(nn.Module):
''' Yolo layer
model_out: while inference,is post-processing inside or outside the model
true:outside
'''
def __init__(self, img_size, anchor_masks=[], num_classes=80, anchors=[], num_anchors=9, scale_x_y=1):
super(YoloLayer, self).__init__()
#[6,7,8]
self.anchor_masks = anchor_masks
#类别
self.num_classes = num_classes
#
if type(anchors) == np.ndarray:
self.anchors = anchors.tolist()
else:
self.anchors = anchors
print(self.anchors)
print(type(self.anchors))
self.num_anchors = num_anchors
self.anchor_step = len(self.anchors) // num_anchors
print(self.anchor_step)
self.scale_x_y = scale_x_y
self.feature_length = [img_size[0]//8,img_size[0]//16,img_size[0]//32]
self.img_size = img_size
def forward(self, output):
if self.training:
return output
in_w = output.size(3)
anchor_index = self.anchor_masks[self.feature_length.index(in_w)]
stride_w = self.img_size[0] / in_w
masked_anchors = []
for m in anchor_index:
masked_anchors += self.anchors[m * self.anchor_step:(m + 1) * self.anchor_step]
self.masked_anchors = [anchor / stride_w for anchor in masked_anchors]
data = yolo_decode(output, self.num_classes, self.masked_anchors, len(anchor_index),scale_x_y=self.scale_x_y)
return data
测试
import os
import numpy as np
def get_anchors():
anchors_path = os.path.expanduser('yolo_anchors_coco.txt')
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
print(anchors)
return anchors
anchors = get_anchors()
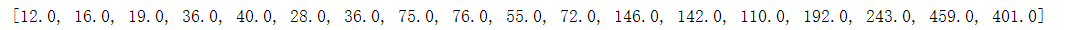
yolo_decodes = []
anchor_masks = [[0,1,2],[3,4,5],[6,7,8]]
for i in range(3):
head = YoloLayer((608, 608, 3), anchor_masks,80,
anchors, len(anchors)//2).eval()
yolo_decodes.append(head)

output_list = [] # 存放解码后的输出预测
for i in range(3):
output_list.append(yolo_decodes[i](out[i]))
output = torch.cat(output_list, 1)
print(output.shape)