
声明:语音信号处理(DSP)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Handling Background Noise in Neural Speech Generation
本文章是google在2021.02.23更新的文章,主要研究在语音编码器如何处理背景噪声,使声码器合成的语音质量更高。具体的文章链接
https://arxiv.org/pdf/2102.11906.pdf
(此类文章Wie经验分享类)
1 研究背景
低码率的语音编码器(语音编码器可参考http://www.ece.ubc.ca/~brucew/ebook/VOIP/004.pdf)由于基于神经网络的声码器的发展音质得到巨大提高。当输入的语音存有噪声的时候,语音编码器的音质将会下降,因此本文实验如何来处理该噪声,使合成的音质更高。
2 详细设计

本文主要在声码器前端加入denoiser模型来去噪。其实验主要对比以下5种方案:
1)c2c: clean-to-clean
2) n2n: noise-to-noisy
3) n2c: noise-to-clean
4) dc2c:在c2c前边使用denoiser模型进行处理
5) dn2n:在n2n前边使用denoiser模型进行处理
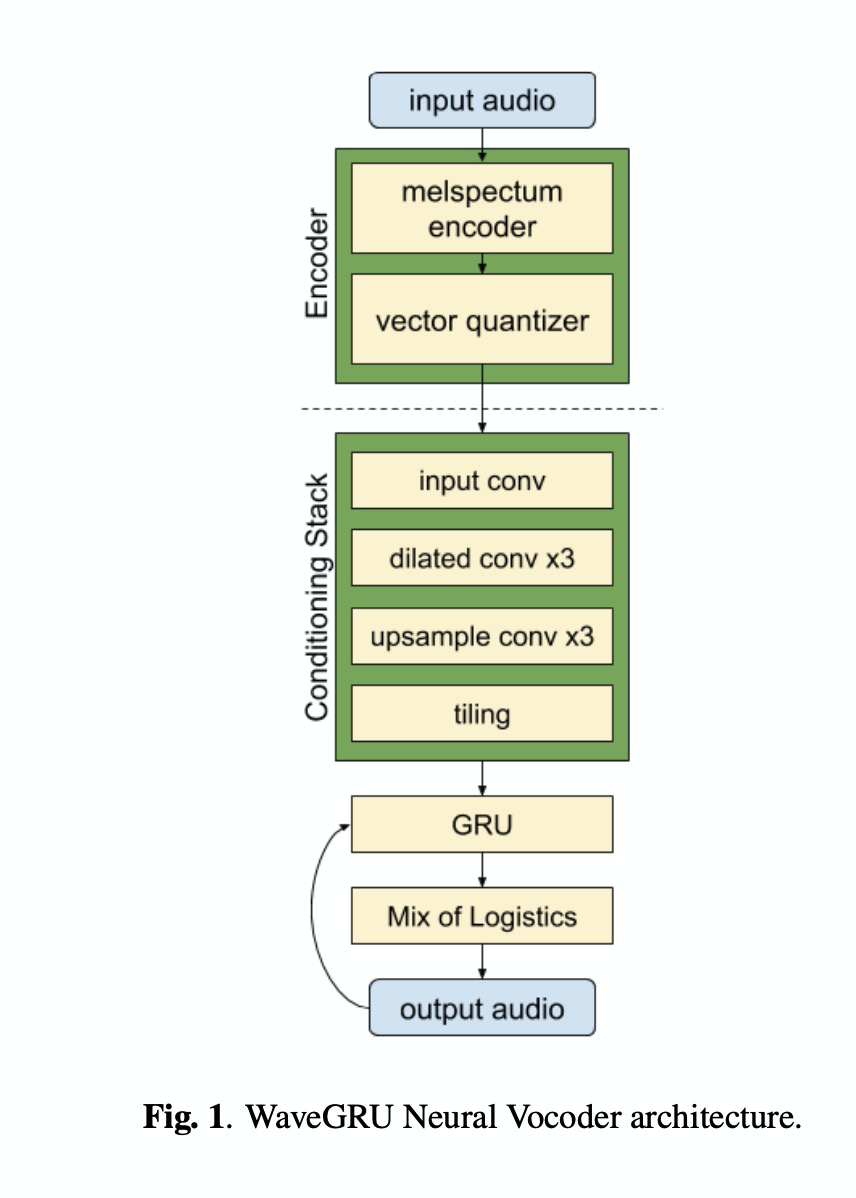
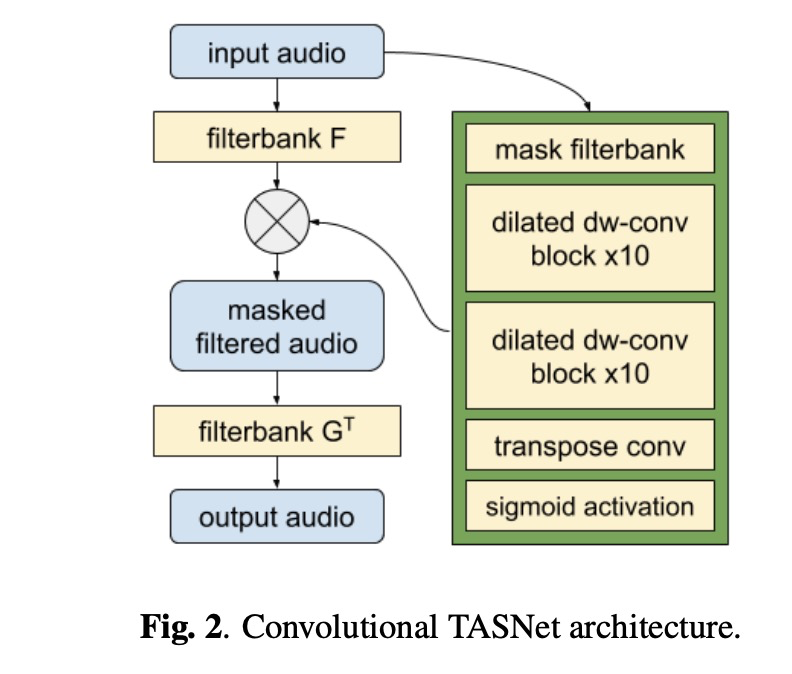
其中本文设计的声码器waveGRU如图1所示,其中encoder是把波形转成log melspectra,decoder把log melspectra转成语音波形。denoiser的模型TASNet如图2所示。
3 实验
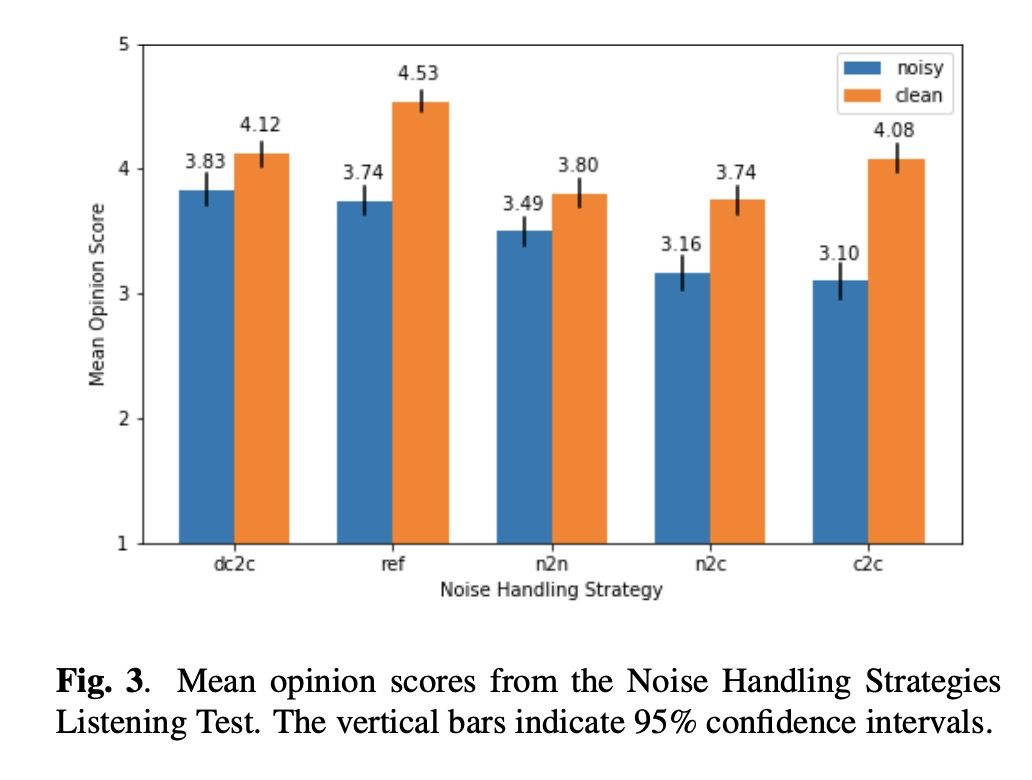
实验先对比clean和noise的MOS值,clean的较高(图3)。以上几种方案的对比结果如下:
1)c2c: 可以很好处理clean的语音,但不能处理带噪的语音;
2)n2n:可以提高带噪语音质量,但牺牲了干净语音质量;
3)n2c:可以提高带噪语音质量,但会造成音素丢失;
4)dc2c:可以很好处理干净和带噪数据;
table1在n2n上展示使用denoiser具有提高音质效果。

4 总结
本文采用不同策略来处理神经网络噪声,使其可以很好的处理干净和带噪数据。