声明:工作以来主要从事TTS工作,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
(本来想写完整后再发出,大家可以根据选取的文章先看个大概,等闲下来后再详细写。我接下来一个月可能碰到一些事情,更新也将会断断续续,望谅解)
此处的韵律跟前端韵律不同,前端的韵律是从语言学的角度来定义停顿时长,是表现目标,对于所有说话人都是一样。本文所讲的韵律是从声学特征学习的具体表现形式,其内容可包含情感,语速,语音质量等级等等信息,主要使合成的语音更加自然,富有情感,对于每位说话人都是不同。文章按照韵律调整的粒度分为两类:粗粒度和细粒度。粗粒度为句子级别的迁移调控,细粒度为phrase,word,phone的调控。接下来将讲解如下几篇文章:
粗粒度:
1)Towards end-to-end prosody transfer for expressive speech synthesis with tacotron (2018)
https://arxiv.org/pdf/1803.09047.pdf
2)Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis (2018)
https://arxiv.org/pdf/1803.09017.pdf
细粒度:
3)ROBUST AND FINE-GRAINED PROSODY CONTROL OF END-TO-END SPEECH SYNTHESIS (2019)
https://arxiv.org/pdf/1811.02122.pdf
4)FINE-GRAINED ROBUST PROSODY TRANSFER FOR SINGLE-SPEAKER NEURAL TEXT-TO-SPEECH (2019)
https://arxiv.org/pdf/1907.02479.pdf
5)FULLY-HIERARCHICAL FINE-GRAINED PROSODY MODELING FOR INTERPRETABLE SPEECH SYNTHESIS (2020)
https://arxiv.org/pdf/2002.03785.pdf
6)Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis (2020)
https://arxiv.org/pdf/2009.08474.pdf
7)MIXTURE DENSITY NETWORK FOR PHONE-LEVEL PROSODY MODELLING IN SPEECH SYNTHESIS (2021)
https://arxiv.org/pdf/2102.00851.pdf
8)AdaSpeech: Adaptive Text to Speech for Custom Voice (2021)
https://arxiv.org/pdf/2103.00993.pdf
第一篇 Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
本文章是首次提出无监督学习来进行韵律的迁移,本文章的做法是使用reference encoder把参考的语音编码成一个vector,该vector就是句子级别的prosody embedding,其包含参考语音的韵律,语速,情感等等信息。
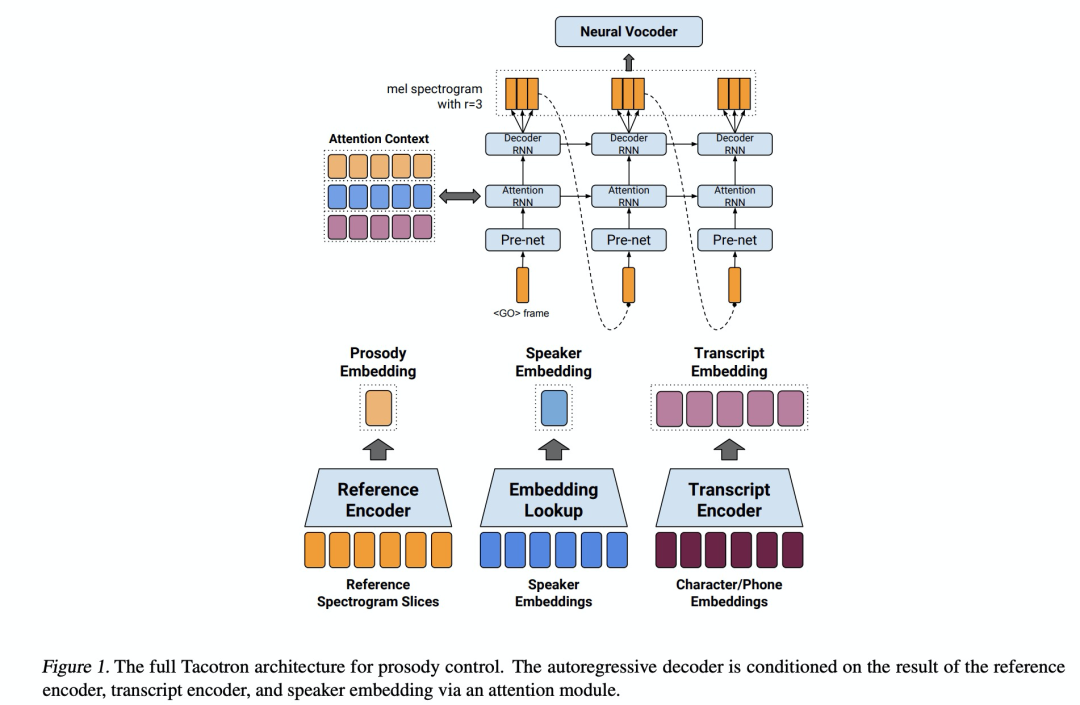
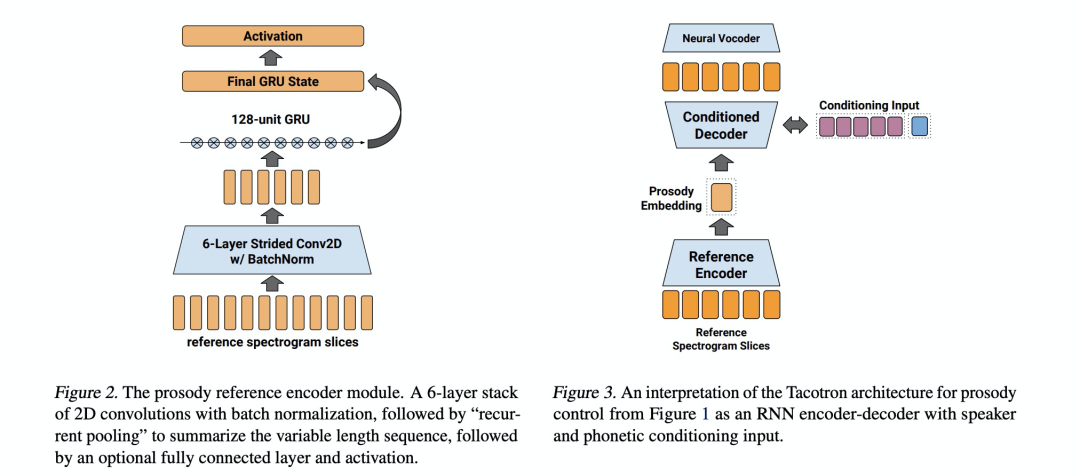
第二篇 Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis
上一篇文章的prosody embedding包含了情感,语速等复杂信息,本文的style tokens可以对上边的prosody embedding进行解耦,使其每个token控制一种style(其实无法完全解耦,每个token还是存在多种信息)。

第三篇 ROBUST AND FINE-GRAINED PROSODY CONTROL OF END-TO-END SPEECH SYNTHESIS
以上两篇都是粗粒度的韵律迁移调控,本文是细粒度的韵律调控:帧级别和音素级别。本文使用的reference encoder是第一篇文章的结构,其韵律信息使用的可变长的韵律信息。


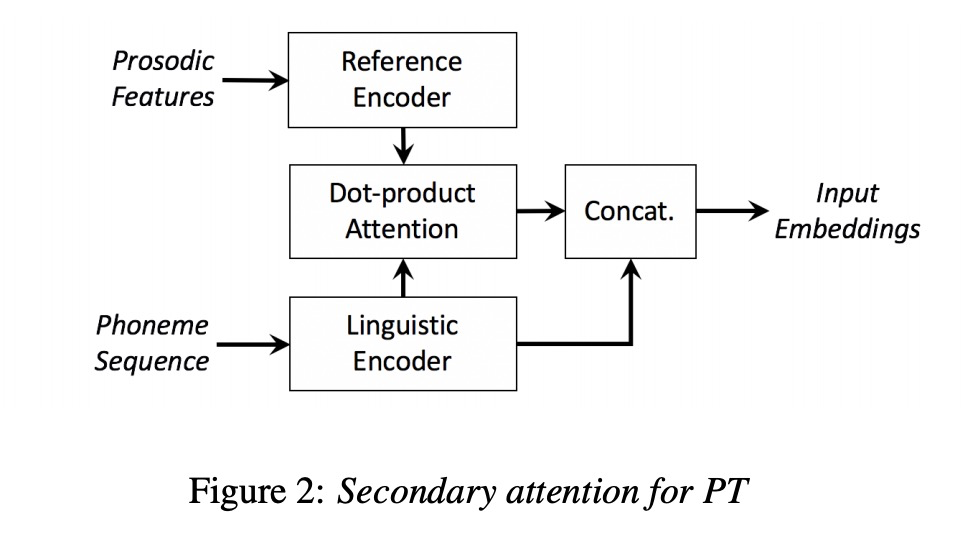
第四篇 FINE-GRAINED ROBUST PROSODY TRANSFER FOR SINGLE-SPEAKER NEURAL TEXT-TO-SPEECH
上篇文章缺点是对unseen speaker和单说话人的韵律进行迁移效果很差,因此本文提出了对参考音频进行单独的信息抽取,其中aggregation phase即信息的抽取。另外本文使用vae对韵律信息预测。
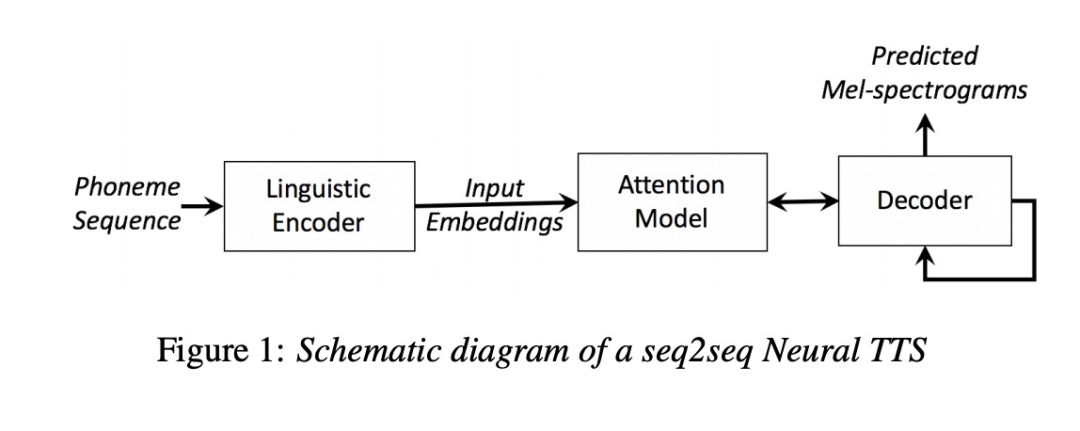
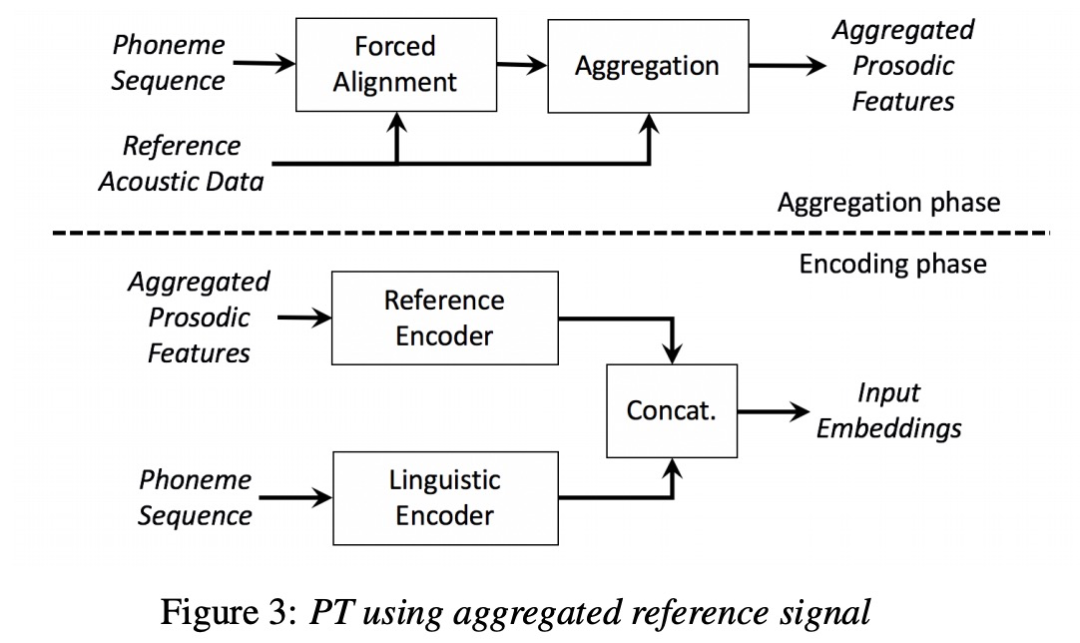
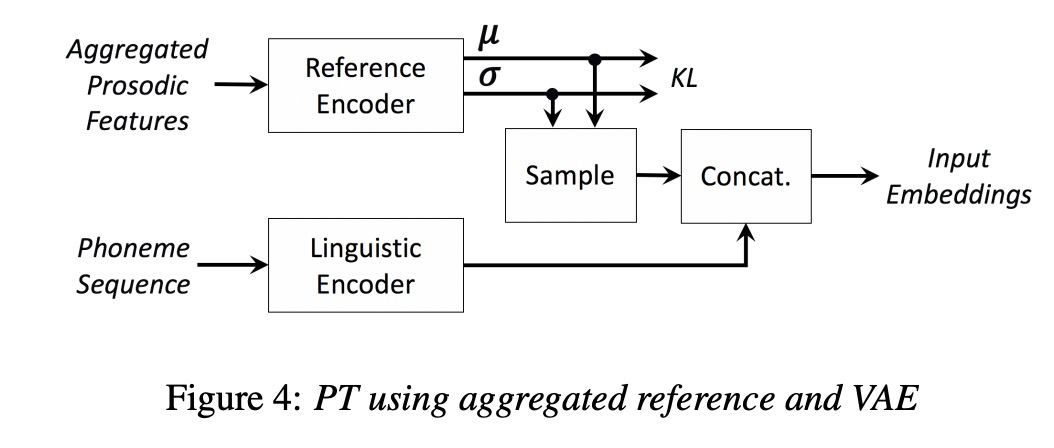
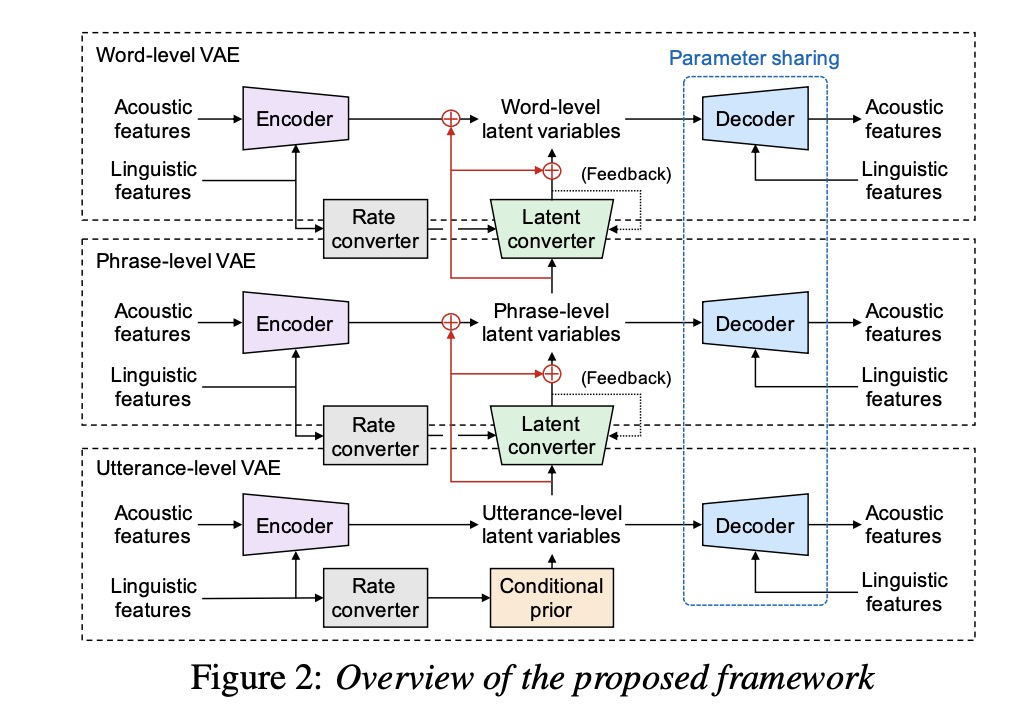
第五篇 FULLY-HIERARCHICAL FINE-GRAINED PROSODY MODELING FOR INTERPRETABLE SPEECH SYNTHESIS
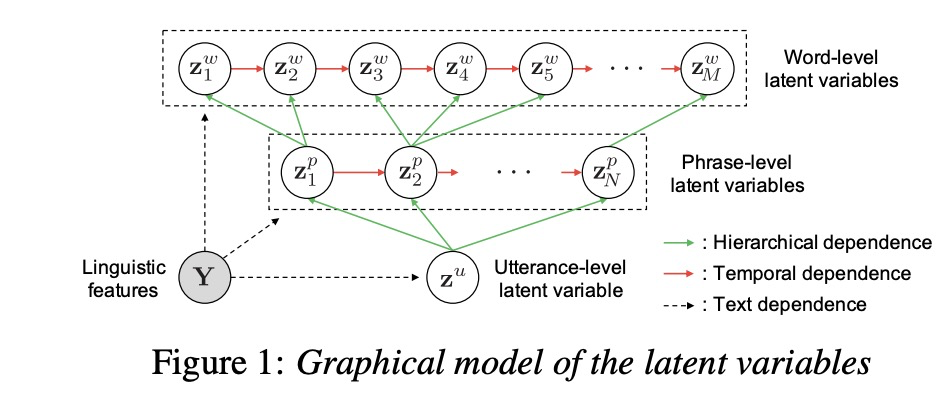
提出了多级韵律架构,而且提出了condition VAE架构。
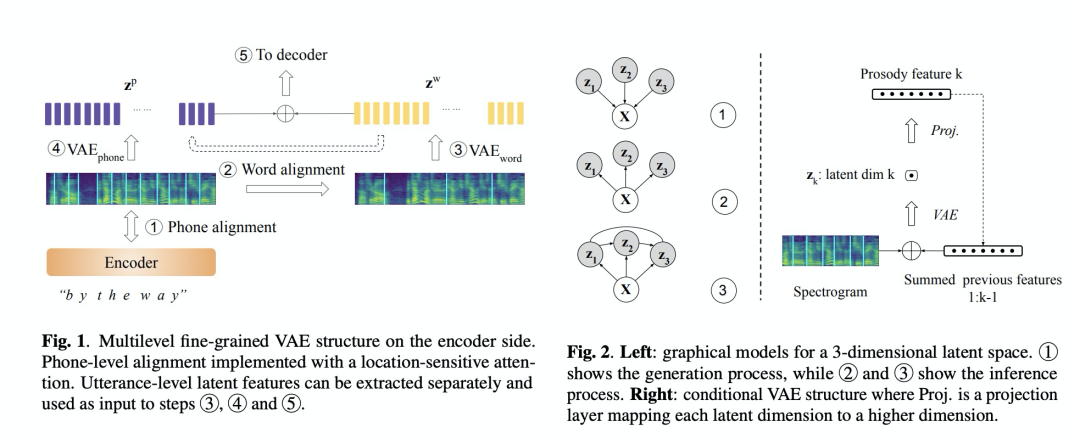
第六篇 Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis
本文提出不需要参考样音的多粒度韵律模型。
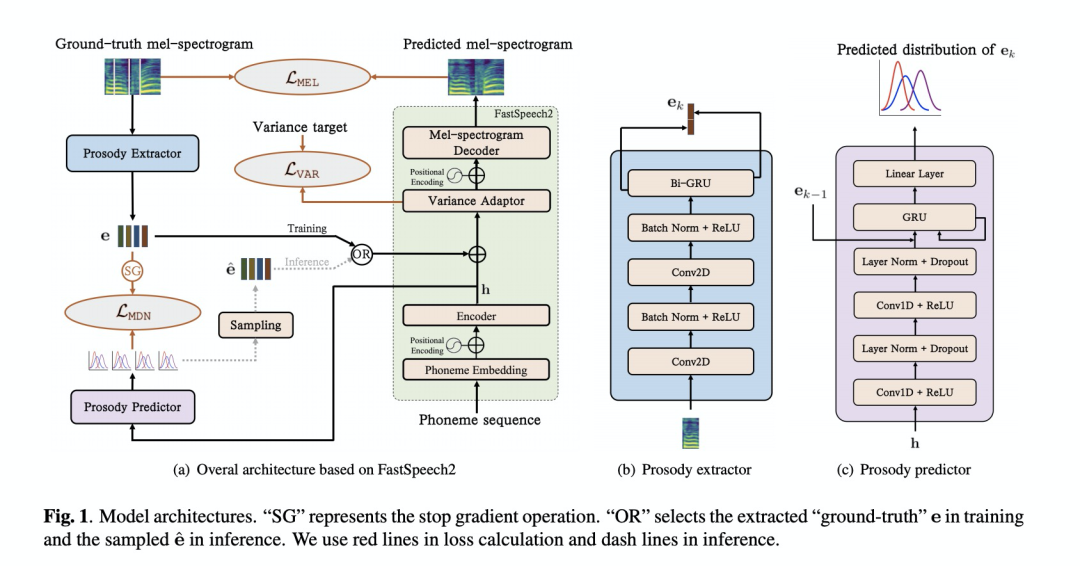
第七篇 MIXTURE DENSITY NETWORK FOR PHONE-LEVEL PROSODY MODELLING IN SPEECH SYNTHESIS
本文使用GMM对音素级的韵律进行建模
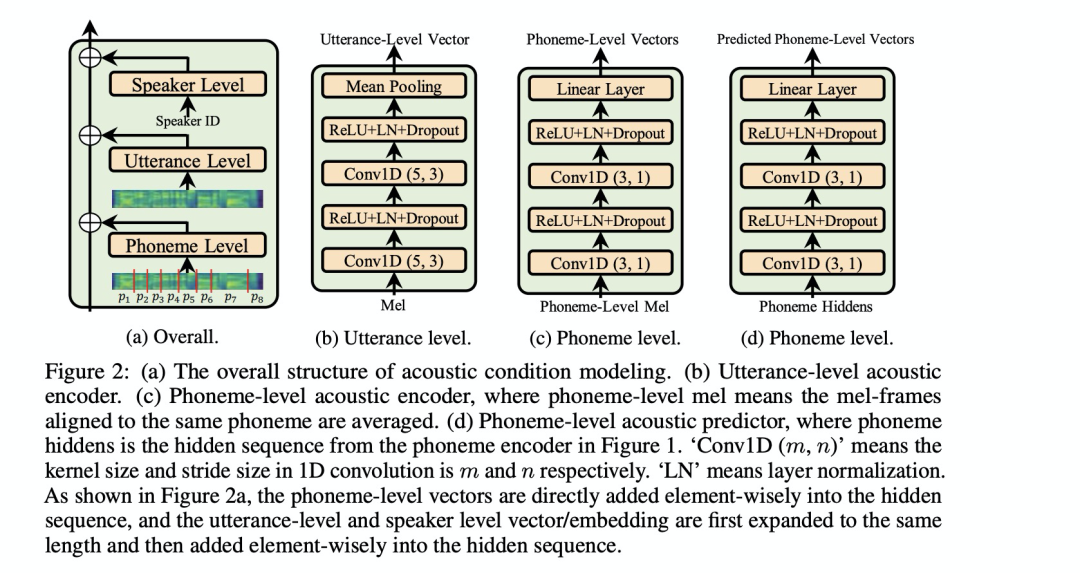
第八篇 AdaSpeech: Adaptive Text to Speech for Custom Voice