行人重识别-度量学习
前言
和前面介绍到的表征学习一样,度量学习也是基于全局特征学习的一种方法,且被广泛用于图像检索领域。不同于表征学习通过分类或者验证的方式,度量学习目的在于通过网络学习两张图片的相似度。在行人重识别问题上,表现为同一行人的不同图片之间的相似度远大于不同行人的不同图片。
定义
定义如下一个映射:
将图片从原始域映射到特征域(就是从真实图片提取特征的意思),之后再定义一个距离度量函数:
来计算两个特征之间的的距离。
注:这个距离度量函数并不唯一,只要是能够在特征空间描述特征向量的相似度的函数都可以作为距离度量函数。当然为了实现端到端训练的函数,度量函数应尽可能连续可导,常用的是归一化特征的欧氏距离或者特征的余弦距离。

最后通过最小化网络的度量损失, 来寻找一个最优的映射f(x), 使得相同行人两张图片(正样本对)的距离尽可能小, 不同行人两张图片(负样本对)的距离尽可能大。而这个映射f(x), 就是我们训练得到的深度卷积网络。
度量损失
常用的度量学习损失方法包括对比损失、三元组损失、改进三元组损失、四元组损失。
传统度量损失
 传统的度量学习的方式如上图,对两张图片提取特征,按照上述公式计算,通过调整中间方阵的数值使得距离Dm尽可能小。当然,现如今大多都在使用深度度量学习的方法,因此不再赘述。
传统的度量学习的方式如上图,对两张图片提取特征,按照上述公式计算,通过调整中间方阵的数值使得距离Dm尽可能小。当然,现如今大多都在使用深度度量学习的方法,因此不再赘述。
对比损失
 对比损失的输入是两张图片,这里两张图片可以是同一行人的图片(正样本),也可以是不同行人的图片(负样本)。通过将一对图片输入孪生网络进行训练,调节相应参数,最终使得正样本间的距离趋近于0,负样本的距离大于某个给定值α。
对比损失的输入是两张图片,这里两张图片可以是同一行人的图片(正样本),也可以是不同行人的图片(负样本)。通过将一对图片输入孪生网络进行训练,调节相应参数,最终使得正样本间的距离趋近于0,负样本的距离大于某个给定值α。
对比损失函数:
解释一下这个函数,对于每一对训练图片,都会给一个标签y,y=1表示两张图片同属于一个人,此时激活该函数的前半部分,只有尽可能缩小a,b之间的距离,才能使得损失尽可能小;同理当y=0时,会激活函数的后半部分,此时前半部分为0,应保证a,b,也就是负样本之间的距离超过给定值α,才能使得损失尽可能小。
三元组损失
 三元组损失的输入是三张图片,包括原始图片Anchor(a),以及对应的正样本(p)和负样本(n),训练模型应使得正样本之间的距离+某个阈值仍然小于负样本之间的距离,如下:
三元组损失的输入是三张图片,包括原始图片Anchor(a),以及对应的正样本(p)和负样本(n),训练模型应使得正样本之间的距离+某个阈值仍然小于负样本之间的距离,如下:
 这种方式仅考虑了正负样本之间的相对距离,而并没有考虑正样本对之间的绝对距离:
这种方式仅考虑了正负样本之间的相对距离,而并没有考虑正样本对之间的绝对距离: 为此提出了改进三元组损失:
为此提出了改进三元组损失:

四元组损失
顾名思义,四元组损失是一次输入四张图片,比三元组损失又多了一张负样本图片,如下图所示:
 固定图片为a,正样本图片p,负样本图片n1,n2,且n1,n2属于不同的行人ID,四元组的损失表示为:
固定图片为a,正样本图片p,负样本图片n1,n2,且n1,n2属于不同的行人ID,四元组的损失表示为:

α和β是手动设置的正常数,通常设置β小于α,前一项作为强推动,只考虑正负样本间的相对距离,共享了固定图片a,在推开负样本对a和n1影响的同时,也会直接影响a的特性,造成正样本对距离不好控制;第二项作为弱推动,第二项负样本对和正样本不共享ID,考虑的是正负样本的绝对距离,在推开负样本的同时不会影响a的特性。
Triplet loss with hard example mining (TriHard loss)
难样本挖掘
随机样本的挑选可能经常会挑选出一些容易识别的样本对组成训练批量(batch),导致网络泛化能力受限(和你天天算10以内加减法,时间长了,两位数的加减法你都得想半天是一个道理)。
那么如何挑去难样本呢?
即挑选出一个训练Batch中特征向量距离比较大(非常不像)的正样本,以及和特征向量距离比较小的(非常像)的负样本对来训练网络。
使用这种技术可以明显改进度量学习方法的性能,加快网络的收敛,并且可以很方便地在原有度量学习方法上进行扩展。
实现(只考虑了极端样本的信息)
核心思想是:对于每一个训练batch挑选P个ID的行人,每个行人,随机挑选K张不同的图片,即一个batch含有P×K张图片。之后对于batch中的每一张图片a,我们可以挑选一个最难的正样本和一个最难的负样本和a组成一个三元组。首先我们定义和a为相同ID的图片集为A,剩下不同ID的图
片集为B,则TriHard损失表示为:
 如下图,红色表示正样本,绿色表示负样本,挑选正样本的最大值和负样本的最小值:
如下图,红色表示正样本,绿色表示负样本,挑选正样本的最大值和负样本的最小值:


自适应权重
自适应权重损失根据样本对之间的距离计算自适应权重,对于正样本对,距离越大,权重越大;对于负样本对,距离越大,权重越小:

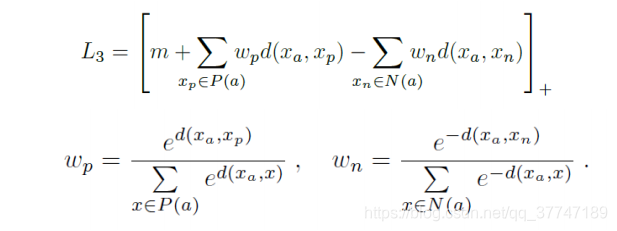
总结
度量学习可以近似看作为样本在特征空间进行聚类, 表征学习可以近似看作为学习样本在特征空间的分界面. 正样本距离拉近的过程使得类内距离缩小, 负样本距离推开的过程使得类间距离增大, 最终收敛时样本在特征空间呈现聚类效应. 度量学习和表征学习相比, 优势在于网络末尾不需要接一个分类的全连接层, 因此对于训练集的行人 ID 数量并不敏感, 可以应用于训练超大规模数据集的网络. 总体而言, 度量学习比表征学习使用的更加广泛, 性能表现也略微优于表征学习. 但是目前行人重识别的数据集规模还依然有限, 表征学习的方法也依然得到使用, 而同时融合度量学习和表征学习训练网络的思路也在逐渐变得流行.