0.研究的对象:
人的整体特征,包括衣着、体形、发行、姿态等等
1.技术难点:
无正脸照,姿态,配饰,遮挡;拍色角度,图片模糊,室内外环境和光线变化,服装搭配,穿衣风格
2.数据集:
Market1501(清华),DukeMTMC-reID(Duke),CUHK03(香港中文)
3.评价指标:
Rank1:首位命中率
mAP:平均精度均值,要求被检索人在底库中所有的图片都排在最前面,这时mAP 的指标才会高。
4.基本流程:
第一步,从摄像头的监控视频获得原始图片;
第二步,基于这些原始图片把行人的位置检测出来;
第三步,提取检索图和底库图特征,特征匹配(计算欧式距离,根据距离进行排序,排序越靠前相似度越高)
5.常用算法实现
基于表征学习的ReID方法[1-4]
1.把行人重识别问题看做分类(Classification/Identification)问题或者验证(Verification)问题:
这个方案是通过设计分类损失与对比损失,来实现对网络的监督学习。
(1)分类问题是指利用行人的ID或者属性等作为训练标签来训练模型;
(2)验证问题是指输入一对(两张)行人图片,让网络来学习这两张图片是否属于同一个行人。
2.用Classification/Identification loss和verification loss来训练网络,网络输入为若干对行人图片,包括分类子网络(Classification Subnet)和验证子网络(Verification Subnet)。分类子网络对图片进行ID预测,根据预测的ID来计算分类误差损失。验证子网络融合两张图片的特征,判断这两张图片是否属于同一个行人,该子网络实质上等于一个二分类网络。
3.光靠行人的ID信息,模型泛化能力查,额外标注了行人图片的属性特征,例如性别、头发、衣着等属性,通过结合ID损失和属性损失能够提高网络的泛化能力。
4.优缺点:比较鲁棒,训练比较稳定,结果也比较容易复现-----在数据集的domain上过拟合,并且当训练ID增加到一定程度的时候会显得比较乏力
基于度量学习的ReID方法[5-11]
通过网络学习出两张图片相似度。在行人重识别问题上,具体为同一行人的不同图片相似度大于不同行人的不同图片。最后网络的损失函数使得相同行人图片(正样本对)的距离尽可能小,不同行人图片(负样本对)的距离尽可能大。
用的度量学习损失方法有
对比损失(Contrastive loss)[5]、正样本对之间的距离逐渐变小,负样本对之间的距离逐渐变大,从而满足行人重识别任务的需要
三元组损失(Triplet loss)[6-8]、被广泛应用的度量学习损失,之后的大量度量学习方法也是基于三元组损失演变而来。。拉近正样本对之间的距离,推开负样本对之间的距离,最后使得相同ID的行人图片在特征空间里形成聚类,达到行人重识别的目的
四元组损失(Quadruplet loss)[9]、相比于三元组损失只考虑正负样本间的相对距离,四元组添加的第二项不共享ID,所以考虑的是正负样本间的绝对距离。因此,四元组损失通常能让模型学习到更好的表征。
难样本采样三元组损失(Triplet hard loss with batch hard mining, TriHard loss)[10]、更难的样本去训练网络能够提高网络的泛化能力,
边界挖掘损失(Margin sample mining loss, MSML)[11]。
基于局部特征的ReID方法
提取局部特征的思路主要有图像切块[12]、利用骨架关键点定位以及姿态矫正等等。
1.图像切块:图片被垂直等分为若干份,按照顺序送到一个长短时记忆网络,最后的特征融合了所有图像块的局部特
(对图像对齐要求高)
2.解决对齐问题:利用先验知识(预训练的人体姿态和骨架关键点模型)对齐图像
论文[13]先用姿态估计的模型估计出行人的关键点,然后用仿射变换对齐局部图像区域
论文[14]Spindle Net用了14个人体关键点来提取局部特征,用这些关键点来抠出感兴趣区域
对于输入的一张行人图片,有一个预训练好的骨架关键点提取CNN(蓝色表示)来获得14个人体关键点,从而得到7个ROI区域,其中包括三个大区域(头、上身、下身)和四个四肢小区域。这7个ROI区域和原始图片进入同一个CNN网络提取特征。原始图片经过完整的CNN得到一个全局特征。三个大区域经过FEN-C2和FEN-C3子网络得到三个局部特征。四个四肢区域经过FEN-C3子网络得到四个局部特征。之后这8个特征按照图示的方式在不同的尺度进行联结,最终得到一个融合全局特征和多个尺度局部特征的行人重识别特征。
论文[15]提出了一种全局-局部对齐特征描述子,来解决行人姿态变化的问题。GLAD利用提取的人体关键点把图片分为头部、上身和下身三个部分。之后将整图和三个局部图片一起输入到一个参数共享CNN网络中,最后提取的特征融合了全局和局部的特征。和Spindle Net略微不同的是四个输入图片各自计算对应的损失,而不是融合为一个特征计算一个总的损失。
以上所有的局部特征对齐方法都需要一个额外的骨架关键点或者姿态估计的模型。而训练一个可以达到实用程度的模型需要收集足够多的训练数据,这个代价是非常大的。为了解决以上问题,提出AlignedReID
论文[16]AlignedReID提出基于SP距离的自动对齐模型,在不需要骨架关键点或者姿态估计的模型等额外信息的情况下来自动对齐局部特征。而采用的方法就是动态对齐算法,或者也叫最短路径距离。这个最短距离就是自动计算出的local distance。
6.应用场景
与人脸识别结合:当看不到人脸的时候用 ReID 技术去识别,可以延长行人在摄像头连续跟踪的时空延续性
智能安防:ReID 根据嫌疑犯照片,去监控视频库里去收集嫌疑犯出现的视频段。
智能寻人系统:将行人照片输入到 ReID 系统里,实时的在所有监控摄像头寻找这个小朋友的照片
相册聚类,家庭机器人
7.技术展望
第一个:ReID 的数据难获取,用无监督学习去提高 ReID 效果,降低数据采集的依赖性(GAN生成数据来帮助 ReID 数据增强,)
第二个,基于视频的 ReID。
第三个,跨模态的 ReID
第四个,跨场景的迁移学习
第五个,应用系统设计。相当于设计一套系统让 ReID 这个技术实际应用到行人检索等技术上去。
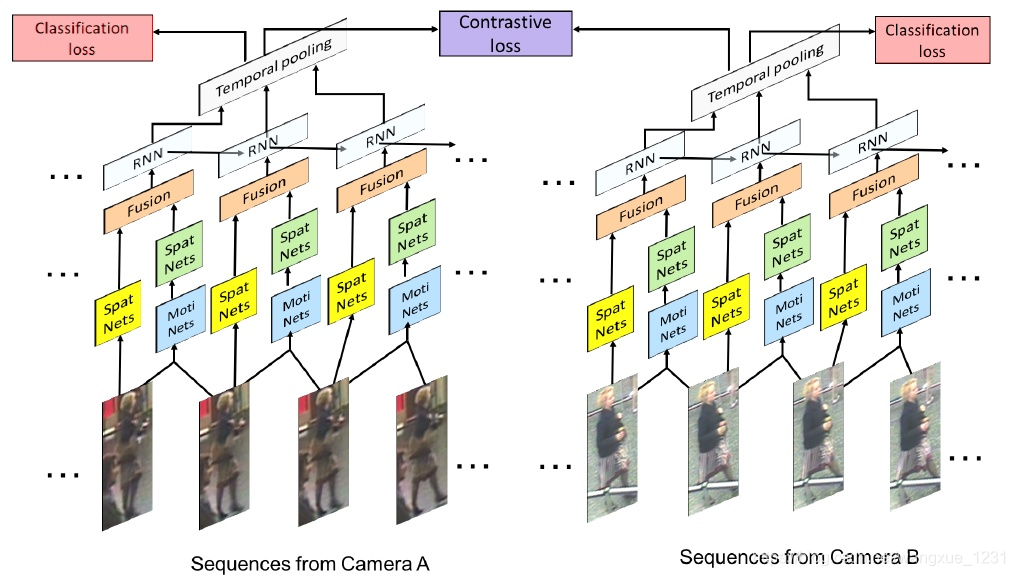
基于视频序列的ReID方法[17-24]
不仅考虑了图像的内容信息,还考虑了帧与帧之间的运动信息等。
主要思想是利用CNN 来提取空间特征的同时利用递归循环网络来提取时序特征。
网络输入为图像序列。每张图像都经过一个共享的CNN提取出图像空间内容特征,之后这些特征向量被输入到一个RNN网络去提取最终的特征。最终的特征融合了单帧图像的内容特征和帧与帧之间的运动特征。而这个特征用于代替前面单帧方法的图像特征来训练网络。
代表方法之一是累计运动背景网络[23] ,输入是原始的图像序列和提取的光流序列。提取光流信息,
在遮挡较严重的情况下,利用一个pose estimation的网络,
基于GAN造图的ReID方法
1.[25]GAN造图随机
2.[26]可以控制的生成图,克服不同的摄像头存在着bias,用GAN将一个摄像头的图片transfer到另外一个摄像头,ID是明确的
3.[27]环境造成数据集存在bias,用GAN把一个数据集的行人迁移到另外一个数据集
4.[28] 为了克服姿态的不同,用GAN造出了一系列标准的姿态图片
测试方法:
1.输入一对行人,输出该对行人的相似度,按相似度排序
2.输入单个人,提取特征,计算与其他人欧式距离,按距离排序(快,常用)
步骤:
1.Feature Extractor:CNN
2.Feature Matching
基于预先定义的位置,(gloabl,local stripes局部条纹,grid patches网格补丁)
基于semantic region语义(Person parts, salient regions显著和attention regions)

stripes方法:有三个方面的工作:
1.DeepMetric深度测量(把一幅图片强行分成三大块,每一大块做一个SCNN,再将各个部分整合)
(ICPR 2014 Deepmetric learning for practical person re-identification)
2.DeepReID(把一个人的结构分成很多小块,一横块分四小块,每一个小块进行操作。这个方法比较直 接,更加细致。缺陷是在识别较为复杂的情况时,或者任何人之间特征区分较差时会受到噪音干扰。)
(CVPR 2014 DeepReID Deep Filter Pairing Neural Network for Person Re Identification)
3.AlignedReID对齐(动态规划计算距离,需要动态匹配的过程,匹配水平的pooling和global pooling,再将两部分融合,得到local distance和global distance,再加 入hardsample mining。)
(CVPR 2017 AlignedReID:Surpassing Human-Level Performance in Person Re-Identification)
代码
grids方法:思路是基于网格,主要有两个工作:
1.IDLA:将两个图片转化匹配,认为在另一个图像的邻域网格总能找到匹配。在难以匹配的情况下,可 以到邻域寻找匹配,所以性能提高很多
(CVPR 2015 An inmproved deep learnng archiecture for person re-identification)
2.DCSL:网络结构转化成一个空间金字塔,在一层匹配不了的情况下,到上一层匹配。
(IJCAI 2016 Semantics-Aware Deep Correspondence Structure Learning for Robust Person Re-identification )
attention方法:借助自然语言和图像语言做特征选择
1.Part-Aligned:部件对齐
将一个人进行匹配时不是所有区域都参与到匹配中,加入attention map,自动发现适合做re-identify的pattern,再做triplet loss,能够在性能上提高7到8个点。
(ICCV 2017 Deeply-Learned Part-Aligned Representations for Person Re-Identification)有代码,简单有效
2.HydraPlus-Net
HPNet很复杂,有多层attention,attention map有多个layer,还有遗忘skip的功能,需要把很多过程整合起来得到一个结果。
模型有进一步的提高,但是在market数据集上比我们的效果差一点。方法越来越复杂,可能在某个数据集上表现越来越好,但是可能泛化能 力越来越差。而我们的模型简单,泛化能力强。
(ICCV 2017 HydraPlus-Net:Attentive Deep Features for Pedestrian Analysis) 有代码
3.HA-CNN
下面这个attention regions learning的方法进一步深化,定义了两种attention,一种是 hard attention,有主干道,一种是soft attention,加入一些分支,然后把soft和hard枝干 融合。最后只放出market数据集的结果,相比HA-CNN提高很多,但没有放出CHUK03的结果,无法重 复实验。
(CVPR 2018 Harmonious Attention Network for Person Re-Identification)
pose方法
1.PDC
将Pose信息嵌入到结构网络中,生成一个modified结构图像,然后对这个结构图像进行识别,效果会有极大提高。
(ICCV 2017 Pose-driven Deep Convolutional Model for Persion Re-identification)
2.PSE
PSE引入视角关系,将多视角结构进行整合,最后得到的结果也还不错。
(CVPR 2018 A Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking)
[参考资料]
1.行人再识别年度进展
https://mp.weixin.qq.com/s/leuILzYz40PqrwsCatYhPw
3.行人重识别技术实现与应用场景https://blog.csdn.net/ctwy291314/article/details/83618646