序
声明:以下是博主精心整理的机器学习和AI系列文章,博主后续会不断更新该领域的知识:
有需要的小伙伴赶紧订阅吧。
人工智能的浪潮正在席卷全球,诸多词汇时刻萦绕在我们耳边:人工智能(Artificial Intelligence)、机器学习(Machine Learning)、深度学习(Deep Learning)。不少人对这些高频词汇的含义及其背后的关系总是似懂非懂、一知半解。
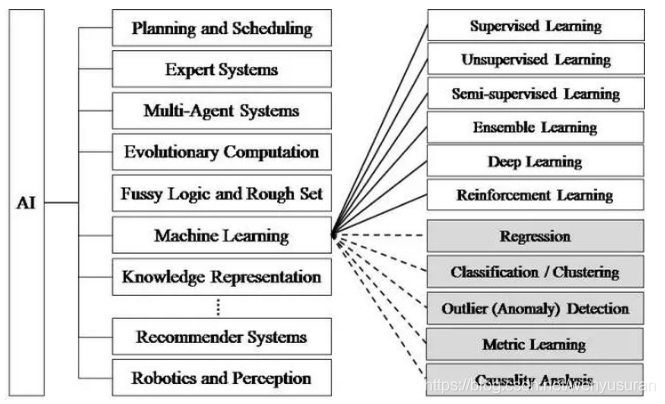
人工智能的研究领域也在不断扩大,上图展示了人工智能研究的各个分支,包括专家系统、机器学习、进化计算、模糊逻辑、计算机视觉、自然语言处理、推荐系统等。
人工智能一定程度上来说是机器学习喝深度学习的深层次应用,要想学好人工智能,我们需要掌握的哪些经典算法呢?
一起来看看吧。
前言
深度学习是很多人面临的一个挑战,因为它在过去的十年中已经慢慢地改变了形式。为了在视觉上设置深度学习,下图展示了AI,机器学习和深度学习三者之间关系的概念。
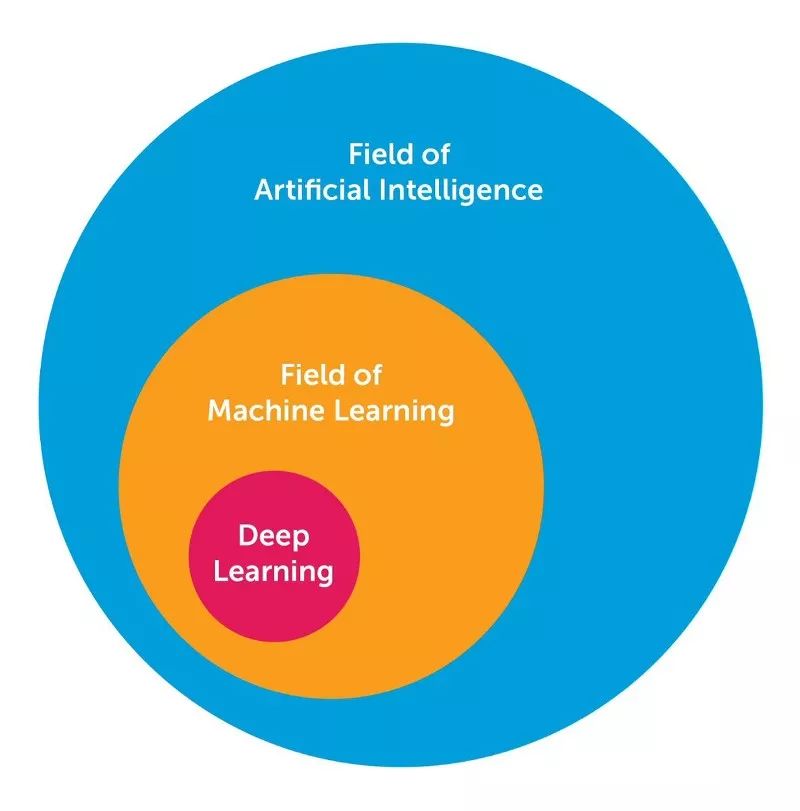
人工智能领域广泛,已经有很长一段时间了,深度学习是机器学习领域的一个子集,AI的一个子领域。
一般将深度学习网络与“典型”前馈多层网络(FP)区分开来的方面如下:
比以前的网络更多的神经元
更复杂的连接层的方式
“寒武纪大爆炸”的计算训练能力
自动特征提取
当我说“更多的神经元”,意思是神经元数量已经上升了多年来表达更复杂的模型。
然后,深度学习可以被定义为具有四个基本网络体系结构之一中的:大量‘参数和层’的神经网络:
无监督的预训练网络
卷积神经网络
回归(复)神经网络
递归神经网络
在本文中,我们主要关注后三种架构。
一、卷积神经网络
是基本上已经跨越使用共享权重的空间延伸的标准神经网络。CNN被设计为通过在内部卷积来识别图像,其看到图像上识别的对象的边缘。
二、回归神经网络
是基本上已经通过具有边缘,其递进给到下一个时间步长,而不是成在同一时间步骤中的下一层跨越时间延长标准神经网络。RNN被设计为识别序列,例如语音信号或文本。它里面的循环意味着网络中存在短暂的内存。
三、递归神经网络
更像是一个分层网络,其中输入序列确实没有时间方面,但输入必须以树状方式分层处理。以下10种方法可以应用于所有这些体系结构。
经典算法
1 - 反向传播(BP)
Back-propagation只是一种计算函数偏导数(或梯度)的方法,函数具有函数组成的形式(如神经网络)。当你使用基于梯度的方法(梯度下降只是其中之一)解决优化问题时,你需要在每次迭代中计算函数梯度。

对于神经网络而言,目标函数具有合成的形式
你如何计算梯度?
BP算法是Delta规则的推广,要求每个人工神经元(节点)所使用的激励函数必须是可微的。BP算法特别适合用来训练前向神经网络,有两种常见的方式来做到这一点:
(一)分析微分,你知道函数的形式,只需使用链式规则(基本演算)来计算函数梯度。
(二)使用有限差分进行近似微分。
其中(二)方法的计算量很大,因为评估函数的数量级是 O(N),其中 N 是参数的数量。与分析微分相比,就相形见绌了。然而,有限差分通常用于在调试时验证后端时很有效。
2 - 随机梯度下降(SGD)
想想渐变下降的一种直观的方式是想象一条源于山顶的河流的小路。
梯度下降的目标正是河流努力实现的目标 - 即到达从山上迈着扯着蛋的步子溜向山脚。
现在,如果山的地形是这样形成的,即在到达最终目的地(这是山麓的最低点)之前,河流不必完全停下来,那么这是我们所希望的理想情况。
在机器学习中,我们已经找到了从初始点(山顶)开始的解的全局最小值(或最优值)。
但是,这可能是因为地形的性质使得路径上的几个坑,这可能会迫使河流陷入困境,在机器学习方面,这种‘坑’被称为局部最优。
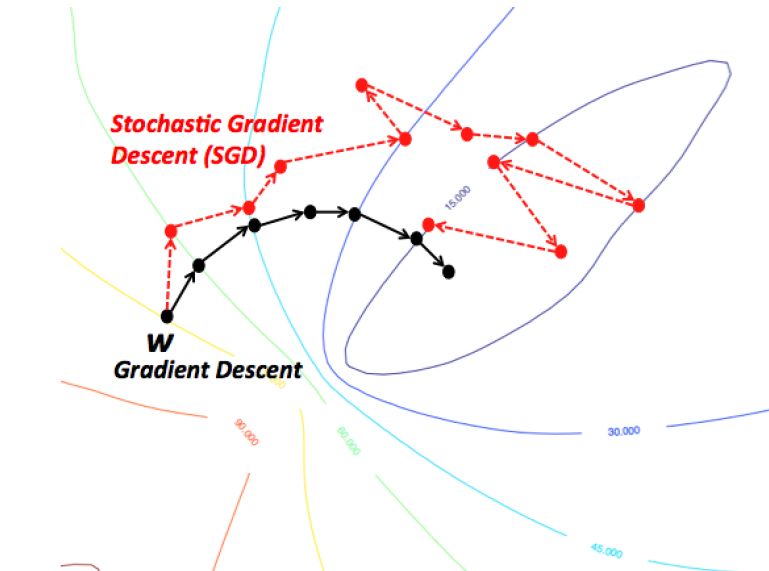
因此,梯度下降倾向于卡在局部最小值,这取决于地形的性质(或ML中的函数)。
但是,当你有一个特殊的山地形(形状像一个碗,在ML术语中称为凸函数),该算法始终保证找到最佳。
你可以想象这再次描绘了一条河流。这些特殊的地形(又称凸函数)总是在ML中优化的祝福。另外,取决于你最初从哪里开始(即函数的初始值),你可能会走上一条不同的路。同样,根据河流的爬升速度(即梯度下降算法的学习速率或步长),你可能会以不同的方式到达最终目的地。
3 - 学习率衰减
根据随机梯度下降优化程序调整学习率可以提高性能并减少训练时间。有时这被称为 学习速率退火 或 自适应学习速率。
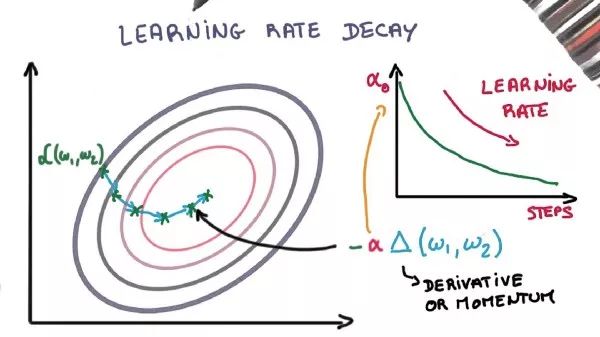
最简单的学习速率:是随着时间的推移而降低学习速度。当使用较大的学习速率值时,它们具有在训练过程开始时进行大的改变的益处,并且降低了学习速率,使得稍后在训练过程中对较小的速率进行训练更新,从而对训练进行更新,这样可以达到早期快速学习好权重并稍后进行微调的效果。
两个流行和易于使用的学习率衰减如下:
在训练过程中逐步降低学习率。
在特定的epochs中降低学习速度比如Adam
4 - Dropout
具有大量参数的深度神经网络是非常强大的机器学习系统,过度拟合也是一个问题,大型网络的使用也很慢,通过在测试时间结合许多不同的大型神经网络的预测,很难处理过度拟合,Dropout是解决这个问题的一种技巧。
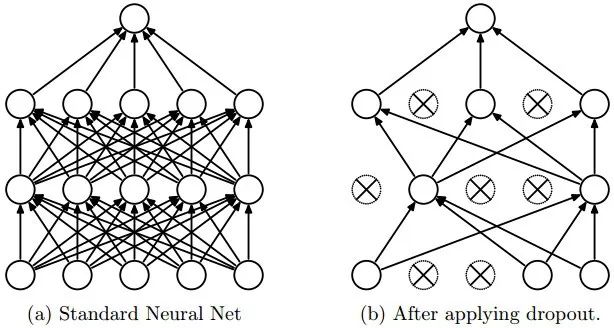
关键的思想是在训练期间从神经网络中随机丢掉某些单元(连同他们的连接),这可以防止单元适应太多
在训练期间,从不同的指数级的“稀疏”网络中剔除样本。
在测试时间,通过简单地使用具有较小权重的单个未解压的网络来容易地近似平均所有这些细化网络的预测的效果。这显着减少了过拟合,并且比其他正则化方法有了重大改进。
Dropout已被证明可以提高神经网络在视觉监控学习任务,语音识别,文档分类和计算生物学的性能,在许多基准数据集上获得最新的结果。
5 - 最大的池化
最大池化是一个基于样本的离散化过程。目标是对输入表示(图像,隐藏层输出矩阵等)进行下采样,降低其维度,并允许对包含在分区域中的特征进行假设。
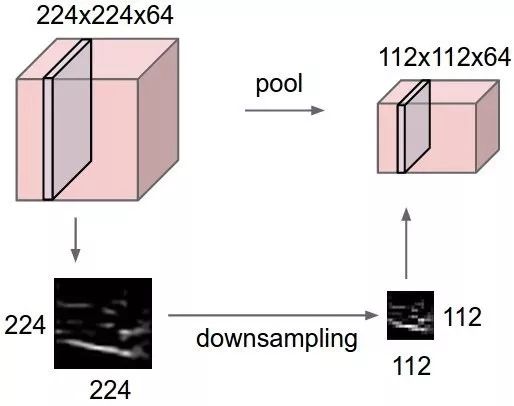
这部分是通过提供表示的抽象形式来解决过度拟合,它通过减少要学习的参数数量来降低计算成本,并为内部表示提供基本的平移不变性,最大池化是通过将最大过滤波器应用于初始表示的通常不重叠的子区域来完成的。
6 - 批量标准化(有时也称归一化)
当然,包括深度网络的神经网络需要仔细调整权重,初始化和学习参数。
权重问题:
无论权重的初始化如何,无论是随机的还是经验性的选择,它们都远离学习权重。考虑一个小批量,在最初的时期,将会有许多异常值在所需的功能激活方面。
深层神经网络本身是不适宜的,即初始层中的小扰动导致后面层的大变化。
在反向传播过程中,这些现象会导致对梯度的分离,这意味着在学习权重以产生所需输出之前,梯度必须补偿异常值。这导致需要额外的epoch来收敛。

批量归一化使这些梯度从分散到正常值,并在小批量范围内流向共同目标(通过归一化)
学习率问题:一般来说,学习率保持较低,只有一小部分的梯度校正权重,原因是异常激活的梯度不应影响学习的激活。通过批量标准化,这些异常激活减少,因此可以使用更高的学习速度来加速学习过程。
7-LSTM网络:
LSTM网络具有以下三个方面,使其与常规神经网络中的常见神经元不同:
它决定何时让输入进入神经元。
它决定何时记住上一个时间中计算的内容
它决定何时让输出传递到下一个时间戳。
LSTM的优点在于它根据当前的输入本身来决定所有这些,所以如果你看下面的图表:
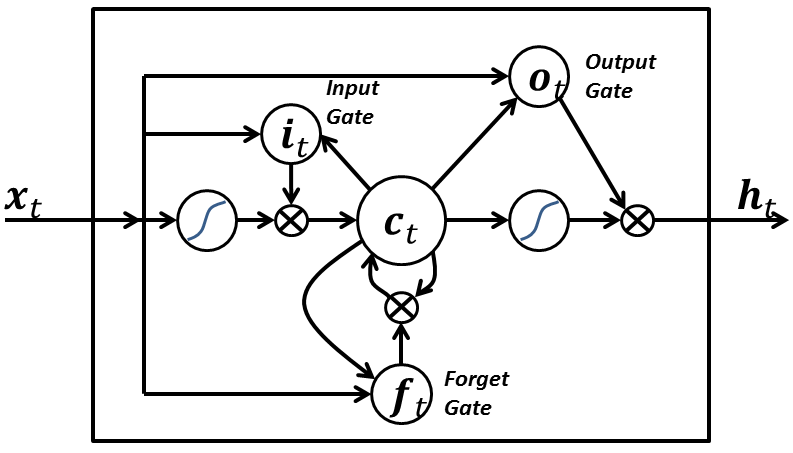
当前时间标记处的输入信号x(t)决定所有上述3个点。
输入门决定点1.遗忘门在点2的决策,输出门在点3输出决策,单独的输入是能够采取所有这三个决策,这受到我们的大脑如何工作的启发,并且可以基于输入来处理突然的上下文切换。
8-Skip-gram
词嵌入模型 的目标是为每个词汇项学习一个高维密集表示,其中嵌入向量之间的相似性显示了相应词语之间的语义或句法相似性。
Skip-gram是学习单词嵌入算法的模型,此模型(以及许多其他的词语嵌入模型)背后的主要思想如下:如果 两个词汇词汇共享相似的上下文,则它们是相似的。
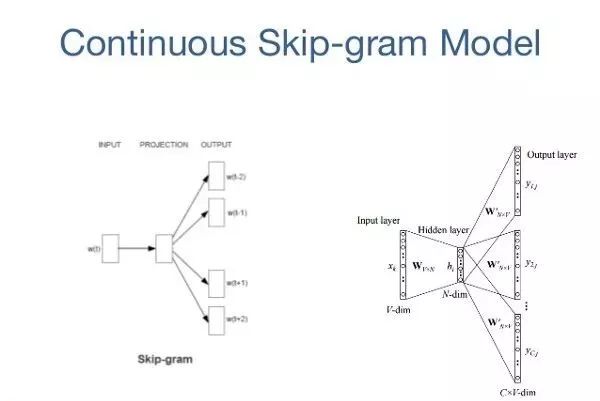
换句话说,假设你有一个句子,就像“猫是哺乳动物”一样,如果你用“狗”而不是“猫”,这个句子还是一个有意义的句子,所以在这个例子中,“狗”和“猫”可以共享相同的语境(即“是哺乳动物”)。
9 - Continuous Bag Of Words(CBOW)
在自然语言处理问题中,我们希望学习将文档中的每个单词表示为一个数字的向量,使得出现在相似的上下文中的单词具有彼此接近的向量。
在连续的单词模型中,目标是能够使用围绕特定单词的上下文并预测特定单词,基于上述假设,你可以考虑一个上下文窗口(一个包含k个连续项的窗口)
然后你应该跳过其中一个单词,试着去学习一个能够得到除跳过项外的所有项的神经网络,并预测跳过的项,如果两个词在一个大语料库中反复共享相似的语境,则这些词的嵌入向量将具有相近的向量。

我们通过在一个大的语料库中采取大量的句子来做到这一点,每当我们看到一个单词时,我们就会听到这个单词。然后,我们将上下文单词输入到一个神经网络,并在这个上下文的中心预测单词。
当我们有成千上万个这样的上下文单词和中心词时,我们有一个神经网络数据集的实例。我们训练神经网络,最后编码的隐藏层输出表示特定单词的嵌入。恰巧当我们通过大量的句子进行训练时,类似语境中的单词得到相似的向量。
10 - 迁移学习(brilliant idea)
让我们考虑一下图像如何穿过卷积神经网络,假设你有一个图像,你应用卷积,并得到像素的组合作为输出。
假设他们是边缘。现在再次应用卷积,所以现在你的输出是边或线的组合。现在再次应用卷积,所以你的输出是线的组合等等。
你可以把它看作是每一层寻找一个特定的模式,神经网络的最后一层往往会变得非常细化。在ImageNet上,你的网络最后一层就是寻找baby,狗或飞机等等。你可能会看到网络寻找眼睛或耳朵或嘴巴或轮子。
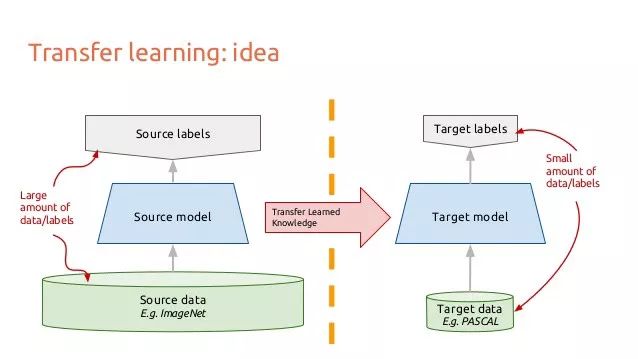
深度CNN中的每一层都逐渐建立起越来越高层次的特征表征,最后几层往往是专门针对你输入模型的任何数据。另一方面,早期的图层更为通用,在一大类图片中有许多简单的图案。
转移学习就是当你在一个数据集上训练CNN时,切掉最后一层,在不同的数据集上重新训练最后一层的模型,直观地说,你正在重新训练模型以识别不同的高级功能。因此,训练时间会减少很多,所以当你没有足够的数据或者训练需要太多的资源时,迁移学习是一个有用的工具。