前言

论文地址:https://aclanthology.org/2021.emnlp-main.261/
前人工作&存在问题
UNMT:使用iterative BT来构造伪并行语料,而BT所产生的并行语料质量是UNMT训练的一个关键。
UG(universal grammar):不同语种的句子共享句法结构,可能会给UNMT训练带去更好的监督。
- 共享constituent label
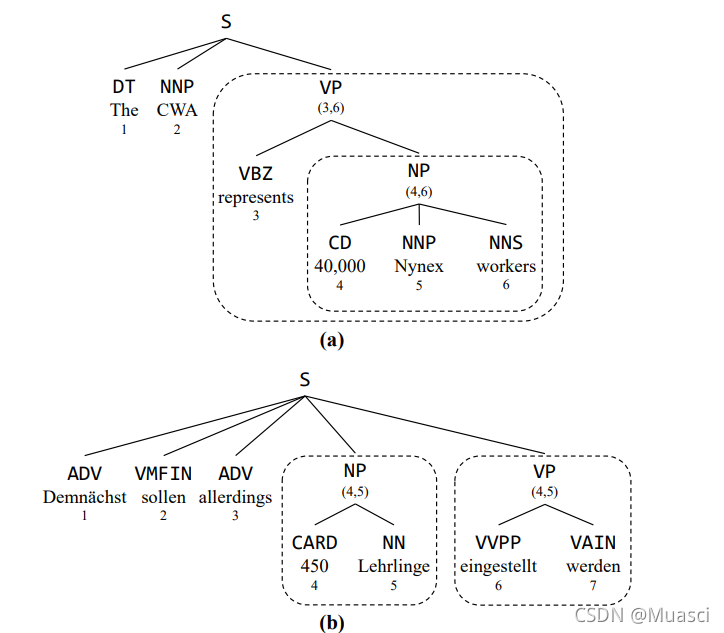
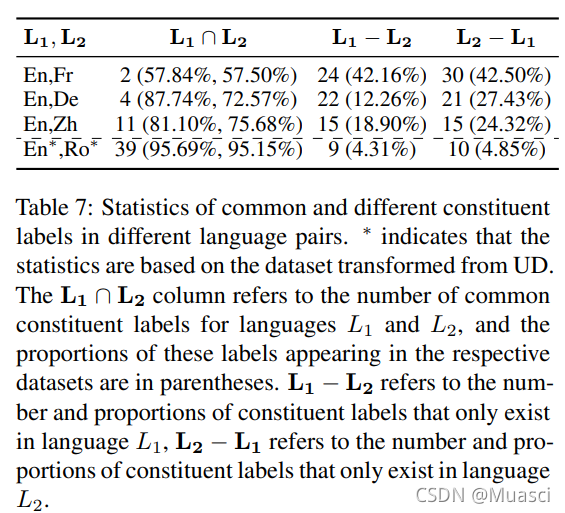
- constituent label的重叠(overlap)
MLM:mlm可以和句法结合起来(constMLM)。
本文贡献
本文提出的CONSTMLM方法,在UNMT训练阶段,引入了对constituent的mask,让模型去预测mask的单词,并预测constituent label,从而加强UNMT训练对encoder-only\encoder-decoder监督;为解决太长的span mask丢失太多有效信息的问题,本文又提出CONSTBTLM方法,通过把BT翻译出来的句子作为额外的输入,来弥补信息的确实,从而扩大可以mask的span长度。
具体方法
CONSTMLM:

CONSTBTLM:

masked span的选择:个人理解:对于一个句子,先用constituent parser构造tree,然后得到m个节点,然后根据长度比例r过滤掉太长的span。
具体实验
和其它一些UNMT baseline的比较
如图4所示,CONSTBTLM效果最好。而且,constituent label重叠较高的语言对的提升更大。

利用句法的信息加强监督 是否和 利用并行语料来做半监督 起到了相同的作用?
如图5所示,个人理解:constituent trees的增多,同一个句子的tree版本就增多,经过mask
,更多的带有span mask的样本可以被用于采样。constituent信息带来了更多监督。

span过滤长度
随着r增大,更长的span得到保留,用于mask。CONSTMLM的性能随之下降,而CONSTBTLM由于BT带来了更多的信息,能够容纳更长的masked span。

单词对齐
既然文章重新训练了XLM,得到的UNMT效果也不同,那为什么表中的XLM结果还是更原文一样?可能的解释是:图4中重新训练的XLM指的是load XLM权重,重新训练的UNMT;而图7中的XLM没进行UNMT的训练。

在训练UNMT时,不同的span mask策略、训练目标
考虑其它两种策略:
- LIMIT-BERT:不做consituent label的prediction
- SPANBERT:在LIMIT-BERT的基础上,
constituentspan mask
如图8所示,LIMIT-BERT差是因为:预测constituent span是costly的(?),对于同一个句子的同一个syntactic parse tree,不同的constituent的mask带来了不同的样本,不同的样本有不同的constituent label,而如果不去预测之,模型的性能会被限制(?)
