前言:
由于python的图像识别库pytesseract太垃圾的缘故,我使用的是百度的OCR接口,使用之前需要去百度AI注册账号并创建一个接口来给自己调用,创建方法网上一大堆教程自己搜,这篇文章主要是自己备用以后可能会用到,在此记录。
使用前先安装:
pip install baidu-aip
测试图片:

返回结果:
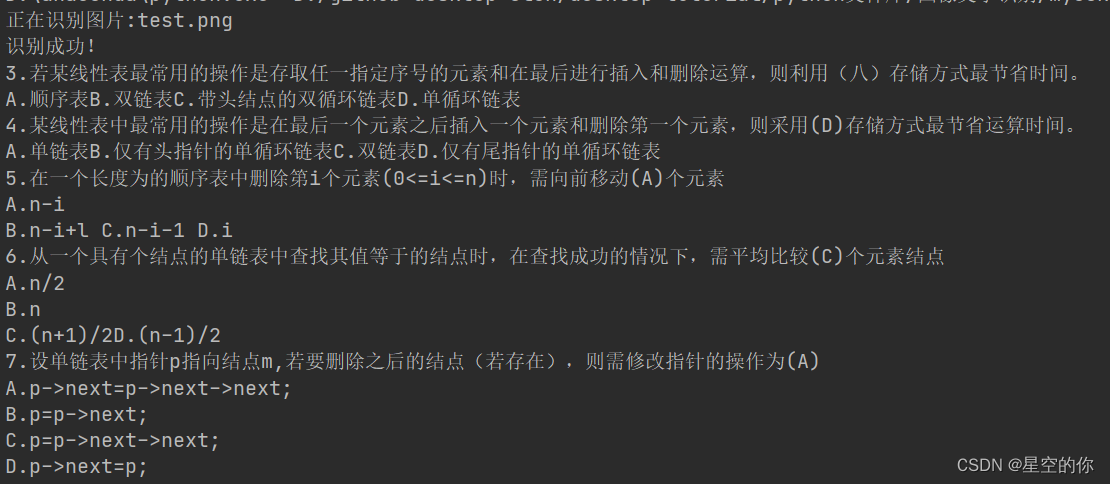
代码如下:
from os import path
from aip import AipOcr # 调取百度AI接口所需库
from PIL import Image # 处理图片的库
import numpy as np
#用你自己创建好的key
APP_ID = ''
API_KEY = ''
SECRECT_KEY = ''
# 利用百度api识别文本,并保存提取图片中的文字
def connectOCR(imgPath,model="normal"):
filename = path.basename(imgPath) # 将图片路径赋值给filename
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
with open(imgPath,'rb') as f:
print("正在识别图片:" + filename)
content=f.read()
if(model=="high"):
message = client.basicAccurate(content) # 通用文字高精度识
else:
message = client.basicGeneral(content) # 通用文字识别
print("识别成功!")
return message
# 调整原始图片
def compress(imgPath):
img = Image.open(imgPath)
width, height = img.size
while width * height > 4000000: # 该数值压缩后的图片大约两百多k
width = width // 2
height = height // 2
new_img = img.resize((width, height), Image.BILINEAR) # 重置图片大小和质量
'''
Image.NEAREST :低质量;Image.BILINEAR:双线性;Image.BICUBIC :三次样条插值;Image.ANTIALIAS:高质量
'''
new_img.save("tmp.png")
#灰度化
def grayScale(imgPath):
img=Image.open(imgPath)
img.convert('L')
img.save("tmp.png")
#二值化
def binary(imgPath,num):
img=Image.open(imgPath)
img = np.array(img.convert('L'))
img = np.where(img[...,:] < num, 0, 255)
img.save("tmp.png")
if __name__ == '__main__':
res = connectOCR("test.png")
for word in res['words_result']:
for key, value in word.items():
print(value)