流经网络的数据总是具有相同的类型:字节。这些字节是如何流动的主要取决于我们所说的网络传输—一个帮助我们抽象底层数据传输机制的概念。
1.1、通过netty的异步网络处理
因为 Netty 为每种传输的实现都暴露了相同的 API,所以无论选用哪一种传输的实现,你的
代 码都仍然几乎不受影响。在所有的情况下,传输的实现都依赖于 interface Channel、ChannelPipeline 和 ChannelHandler。接下来,我们使用 Netty 和非阻塞 I/O 来实现逻辑。
1.2、传输API
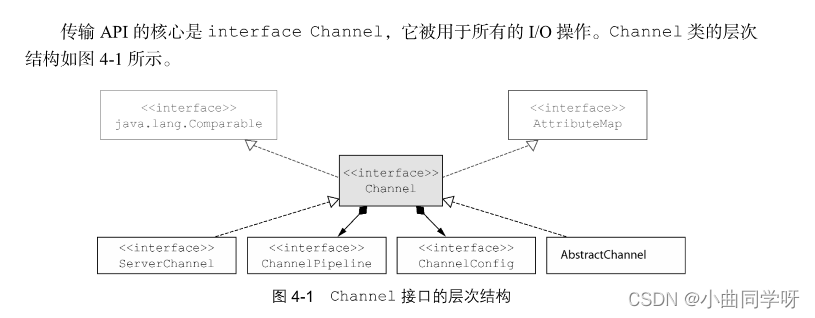
如图所示,每个 Channel 都将会被分配一个 ChannelPipeline 和 ChannelConfig。
ChannelConfig 包含了该 Channel 的所有配置设置,并且支持热更新。由于特定的传输可能
具有独特的设置,所以它可能会实现一个 ChannelConfig 的子类型。(请参考 ChannelConfig
实现对应的 Javadoc。)
由 于 Channel 是独一无二的,所以为了保证顺序将 Channel 声明为 java.lang.Comparable 的一个子接口。因此,如果两个不同的 Channel 实例都返回了相同的散列码,那么 AbstractChannel 中的 compareTo()方法的实现将会抛出一个 Error。
ChannelPipeline 持有所有将应用于入站和出站数据以及事件的 ChannelHandler 实例,这些 ChannelHandler 实现了应用程序用于处理状态变化以及数据处理的逻辑。ChannelHandler 的典型用途包括:
- 将数据从一种格式转换为另一种格式;
- 提供异常的通知;
- 提供 Channel 变为活动的或者非活动的通知;
- 提供当 Channel 注册到 EventLoop 或者从 EventLoop 注销时的通知;
- 提供有关用户自定义事件的通知。
1.2.1、channel方法

Netty 的 Channel 实现是线程安全的,因此你可以存储一个到 Channel 的引用,并且每当你需要向远程节点写数据时,都可以使用它,即使当时许多线程都在使用它。
1.2.2、多线程使用同一个 Channel
public class NettyTest {
// 创建持有要写数据的 ByteBuf
final Channel channel ="";
final ByteBuf buf = Unpooled.copiedBuffer("your data", CharsetUtil.UTF_8).retain();
//创建将数据写到Channel 的 Runnable
Runnable writer = new Runnable() {
@Override
public void run() {
channel.writeAndFlush(buf.duplicate());
}
};
//获取到线程池Executor 的引用
Executor executor = Executors.newCachedThreadPool();
// write in one thread
//递交写任务给线程池以便在某个线程中执行
executor.execute(writer);
// write in another threa
//递交写任务给线程池以便在另一个线程中执行
executor.execute(writer);
}
需要注意的是,消息将会被保证按顺序发送。
1.3、内置传输
Netty 内置了一些可开箱即用的传输。因为并不是它们所有的传输都支持每一种协议,所以你必须选择一个和你的应用程序所使用的协议相容的传输。
1.3.1、 NIO——非阻塞 I/O
NIO 提供了一个所有 I/O 操作的全异步的实现,以块的方式处理数据,采用多路复用的IO模型。
选择器背后的基本概念是充当一个注册表,在那里你将可以请求在 Channel 的状态发生变
化时得到通知。可能的状态变化有:
- 新的 Channel 已被接受并且就绪;
- Channel 连接已经完成;
- Channel 有已经就绪的可供读取的数据;
- Channel 可用于写数据。
选择器运行在一个检查状态变化并对其做出相应响应的线程上,在应用程序对状态的改变做出响应之后,选择器将会被重置,并将重复这个过程。
1.3.2、Epoll—用于 Linux 的本地非阻塞传输
Linux作为高性能网络编程的平台,其重要性与日俱增,这催生了大量先进特性的开发,其中包括epoll——一个高度可扩展的I/O事件通知特性。
Netty为Linux提供了一组NIO API,其以一种和它本身的设计更加一致的方式使用epoll,并且以一种更加轻量的方式使用中断。
2、 ByteBuf
网络数据的基本单位总是字节。Java NIO 提供了 ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。Netty 的 ByteBuffer 替代品是 ByteBuf,一个强大的实现,既解决了 JDK API 的局限性,又为网络应用程序的开发者提供了更好的 API。
ByteBuf 的卓越功能性和灵活性。这也将有助于更好地理解 Netty 数据处理的一般方式。
2.1、ByteBuf 类——Netty 的数据容器
因为所有的网络通信都涉及字节序列的移动,所以高效易用的数据结构明显是必不可少的。Netty 的 ByteBuf 实现满足并超越了这些需求。让我们首先来看看它是如何通过使用不同的索引来简化对它所包含的数据的访问的吧。
2.1.1 、工作原理
ByteBuf 维护了两个不同的索引:一个用于读取,一个用于写入。当你从 ByteBuf 读取时,它readerIndex 将会被递增已经被读取的字节数。同样地,当你写入 ByteBuf 时,它的writerIndex 也会被递增。如图所示:

要了解这些索引两两之间的关系,请考虑一下,如果打算读取字节直到 readerIndex 达到和 writerIndex 同样的值时会发生什么。在那时,你将会到达“可以读取的”数据的末尾。就如同试图读取超出数组末尾的数据一样,试图读取超出该点的数据将会触发一个 IndexOutOf-BoundsException。
名称以 read 或者 write 开头的 ByteBuf 方法,将会推进其对应的索引,而名称以 set 或者 get 开头的操作则不会。后面的这些方法将在作为一个参数传入的一个相对索引上执行操作。可以指定 ByteBuf 的最大容量。试图移动写索引(即 writerIndex)超过这个值将会触发一个异常①。(默认的限制是Integer.MAX_VALUE。)
2.2、Bytebuf的使用
在使用 Netty 时,你将遇到几种常见的围绕 ByteBuf 而构建的使用模式:一个由不同的索引分别控制读访问和写访问的字节数组。
2.2.1、堆缓冲区
最常用的 ByteBuf 模 式是将数据存储在 JVM 的堆空间中。这种模式被 称 为支撑数组(backing array),它能在没有使用池化的情况下提供快速的分配和释放。非常适合于有遗留的数据需要处理的情况。
ByteBuf heapBuf = ...;
if (heapBuf.hasArray()) {
byte[] array = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
int length = heapBuf.readableBytes();
handleArray(array, offset, length);
}
2.2.2、直接缓冲区
直接缓冲区是另外一种 ByteBuf 模式。我们期望用于对象创建的内存分配永远都来自于堆中。
ByteBuffer的Javadoc①明确指出:“直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。”这也就解释了为何直接缓冲区对于网络数据传输是理想的选择。如果你的数据包含在一个在堆上分配的缓冲区中,那么事实上,在通过套接字发送它之前,JVM将会在内部把你的缓冲区复制到一个直接缓冲区中。
直接缓冲区的主要缺点是,相对于基于堆的缓冲区,它们的分配和释放都较为昂贵。
ByteBuf directBuf = ...;
if (!directBuf.hasArray()) {
int length = directBuf.readableBytes();
byte[] array = new byte[length];
directBuf.getBytes(directBuf.readerIndex(), array);
handleArray(array, 0, length);
}
2.2.3、复合缓冲区
第三种也是最后一种模式使用的是复合缓冲区,它为多个 ByteBuf 提供一个聚合视图。在这里你可以根据需要添加或者删除 ByteBuf 实例,这是一个 JDK 的 ByteBuffer 实现完全缺失的特性。
Netty 通过一个 ByteBuf 子类——CompositeByteBuf——实现了这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
/**
* 使用 ByteBuffer 的复合缓冲区模式
**/
// Use an array to hold the message parts
ByteBuffer[] message = new ByteBuffer[] {
header, body };
// Create a new ByteBuffer and use copy to merge the header and body
ByteBuffer message2 =
ByteBuffer.allocate(header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
message2.flip();
2.3 字节级操作
ByteBuf 提供了许多超出基本读、写操作的方法用于修改它的数据。在接下来的章节中,我们将会讨论这些中最重要的部分。
2.3.1、随机访问索引
如同在普通的 Java 字节数组中一样,ByteBuf 的索引是从零开始的:第一个字节的索引是0,最后一个字节的索引总是 capacity() - 1。
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char)b);
}
2.3.2、顺序访问索引
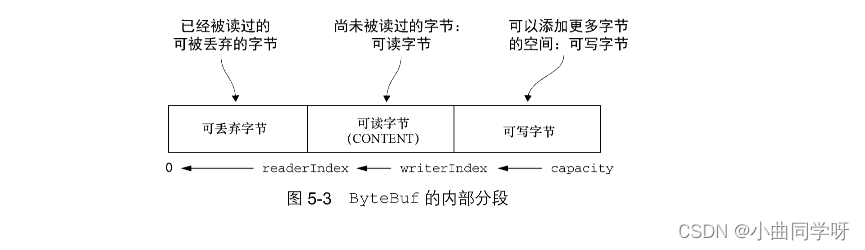
虽然 ByteBuf 同时具有读索引和写索引,但是 JDK 的 ByteBuffer 却只有一个索引,这也就是为什么必须调用 flip()方法来在读模式和写模式之间进行切换的原因。图 5-3 展示了ByteBuf 是如何被它的两个索引划分成 3 个区域的。
2.3.3、可丢弃字节
可丢弃字节的分段包含了已经被读过的字节。通过调用 discardRead-Bytes()方法,可以丢弃它们并回收空间。这个分段的初始大小为 0,存储在 readerIndex 中,会随着 read 操作的执行而增加。
2.3.4、可读字节
ByteBuf 的可读字节分段存储了实际数据。
新分配的、包装的或者复制的缓冲区的默认的readerIndex 值为 0。
任何名称以 read 或者 skip 开头的操作都将检索或者跳过位于当前readerIndex 的数据,并且将它增加已读字节数。
/**
* 读取所有数据
**/
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
2.3.5、可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。
新分配的缓冲区的writerIndex 的默认值为 0。任何名称以 write 开头的操作都将从当前的 writerIndex 处
开始写数据,并将它增加已经写入的字节数。
如果写操作的目标也是 ByteBuf,并且没有指定源索引的值,则源缓冲区的 readerIndex 也同样会被增加相同的大小。
// Fills the writable bytes of a buffer with random integers.
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
2.3.6、读写操作
正如我们所提到过的,有两种类别的读/写操作:
- get()和 set()操作,从给定的索引开始,并且保持索引不变;
- read()和 write()操 作,从给定的索引开始,并且会根据已经访问过的字节数对索 引进行调整。
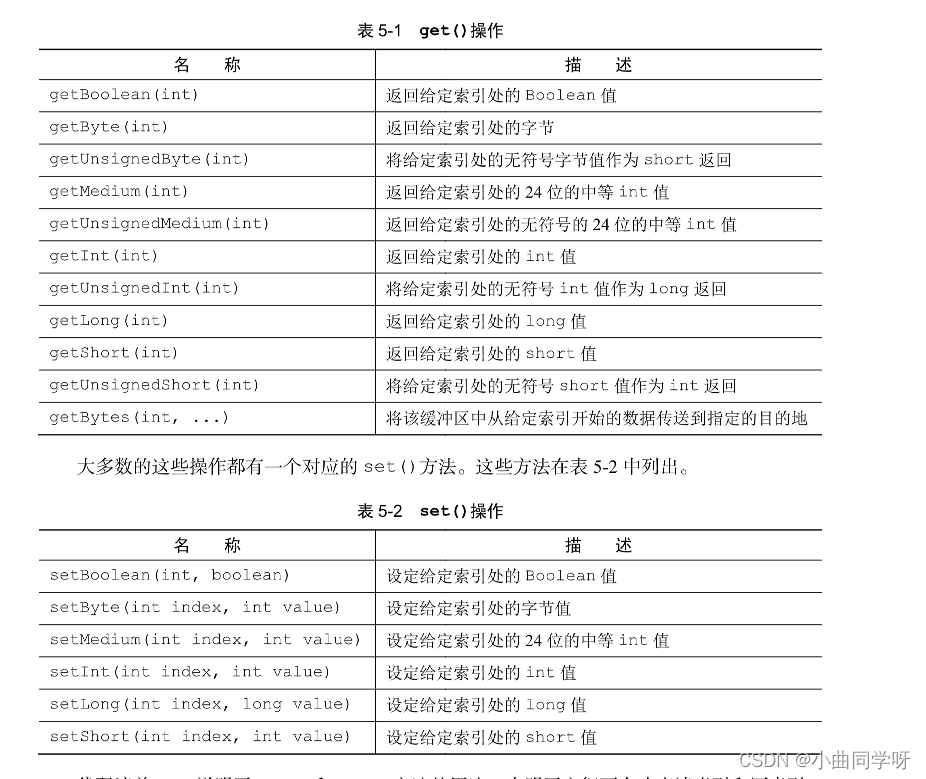
表 5-1 列举了最常用的 get()方法。完整列表请参考对应的 API 文档。
2.4、ByteBuf 分配
管理 ByteBuf 实例的不同方式。
2.4.1、按需分配:ByteBufAllocator 接口
为了降低分配和释放内存的开销,Netty 通 过 interface ByteBufAllocator 实现 了(ByteBuf 的)池化,它可以用来分配我们所描述过的任意类型的 ByteBuf 实例。
/**
* 获取一个到 ByteBufAllocator 的引用
**/
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc();
....
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator2 = ctx.alloc();
Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和Unpooled-ByteBufAllocator。前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。
此实现使用了一种称为jemalloc的已被大量现代操作系统所采用的高效方法来分配内存。后者的实现不池化ByteBuf实例,并且在每次它被调用时都会返回一个新的实例。
2.4.2、Unpooled 缓冲区
可能某些情况下,你未能获取一个到 ByteBufAllocator 的引用。对于这种情况,Netty 提供了一个简单的称为 Unpooled 的工具类,它提供了静态的辅助方法来创建未池化的 ByteBuf实例。

3、小结
探讨了 Netty 的基于 ByteBuf 的数据容器。
我们讨论过的要点有:
- 使用不同的读索引和写索引来控制数据访问;
- 使用内存的不同方式——基于字节数组和直接缓冲区;
- 通过 CompositeByteBuf 生成多个 ByteBuf 的聚合视图;
- 数据访问方法——搜索、切片以及复制;
- 读、写、获取和设置 API;
- ByteBufAllocator 池化。