《MATLAB 神经网络43个案例分析》:第30章 基于随机森林思想的组合分类器设计——乳腺癌诊断
1. 前言
《MATLAB 神经网络43个案例分析》是MATLAB技术论坛(www.matlabsky.com)策划,由王小川老师主导,2013年北京航空航天大学出版社出版的关于MATLAB为工具的一本MATLAB实例教学书籍,是在《MATLAB神经网络30个案例分析》的基础上修改、补充而成的,秉承着“理论讲解—案例分析—应用扩展”这一特色,帮助读者更加直观、生动地学习神经网络。
《MATLAB神经网络43个案例分析》共有43章,内容涵盖常见的神经网络(BP、RBF、SOM、Hopfield、Elman、LVQ、Kohonen、GRNN、NARX等)以及相关智能算法(SVM、决策树、随机森林、极限学习机等)。同时,部分章节也涉及了常见的优化算法(遗传算法、蚁群算法等)与神经网络的结合问题。此外,《MATLAB神经网络43个案例分析》还介绍了MATLAB R2012b中神经网络工具箱的新增功能与特性,如神经网络并行计算、定制神经网络、神经网络高效编程等。
近年来随着人工智能研究的兴起,神经网络这个相关方向也迎来了又一阵研究热潮,由于其在信号处理领域中的不俗表现,神经网络方法也在不断深入应用到语音和图像方向的各种应用当中,本文结合书中案例,对其进行仿真实现,也算是进行一次重新学习,希望可以温故知新,加强并提升自己对神经网络这一方法在各领域中应用的理解与实践。自己正好在多抓鱼上入手了这本书,下面开始进行仿真示例,主要以介绍各章节中源码应用示例为主,本文主要基于MATLAB2015b(32位)平台仿真实现,这是本书第三十章基于随机森林思想的组合分类器设计实例,话不多说,开始!
2. MATLAB 仿真示例
打开MATLAB,点击“主页”,点击“打开”,找到示例文件
选中main.m,点击“打开”
main.m源码如下:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%功能:基于随机森林思想的组合分类器设计
%环境:Win7,Matlab2015b
%Modi: C.S
%时间:2022-06-20
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 基于随机森林思想的组合分类器设计
%% 清空环境变量
clear all
clc
warning off
tic
%% 导入数据
load data.mat
% 随机产生训练集/测试集
a = randperm(569);
Train = data(a(1:500),:);
Test = data(a(501:end),:);
% 训练数据
P_train = Train(:,3:end);
T_train = Train(:,2);
% 测试数据
P_test = Test(:,3:end);
T_test = Test(:,2);
%% 创建随机森林分类器
model = classRF_train(P_train,T_train);
%% 仿真测试
[T_sim,votes] = classRF_predict(P_test,model);
%% 结果分析
count_B = length(find(T_train == 1));
count_M = length(find(T_train == 2));
total_B = length(find(data(:,2) == 1));
total_M = length(find(data(:,2) == 2));
number_B = length(find(T_test == 1));
number_M = length(find(T_test == 2));
number_B_sim = length(find(T_sim == 1 & T_test == 1));
number_M_sim = length(find(T_sim == 2 & T_test == 2));
disp(['病例总数:' num2str(569)...
' 良性:' num2str(total_B)...
' 恶性:' num2str(total_M)]);
disp(['训练集病例总数:' num2str(500)...
' 良性:' num2str(count_B)...
' 恶性:' num2str(count_M)]);
disp(['测试集病例总数:' num2str(69)...
' 良性:' num2str(number_B)...
' 恶性:' num2str(number_M)]);
disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)...
' 误诊:' num2str(number_B - number_B_sim)...
' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']);
disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)...
' 误诊:' num2str(number_M - number_M_sim)...
' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']);
%% 绘图
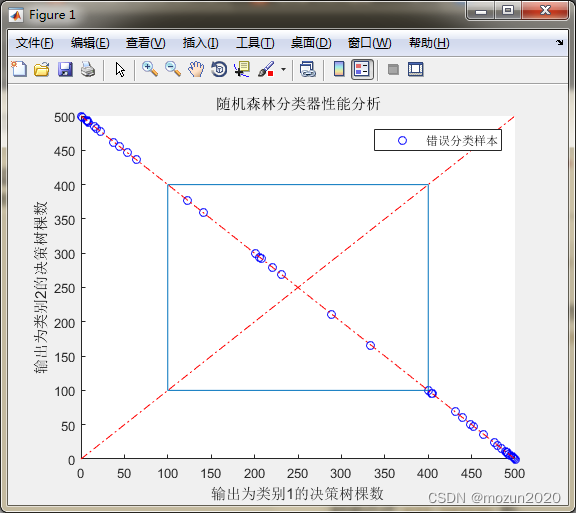
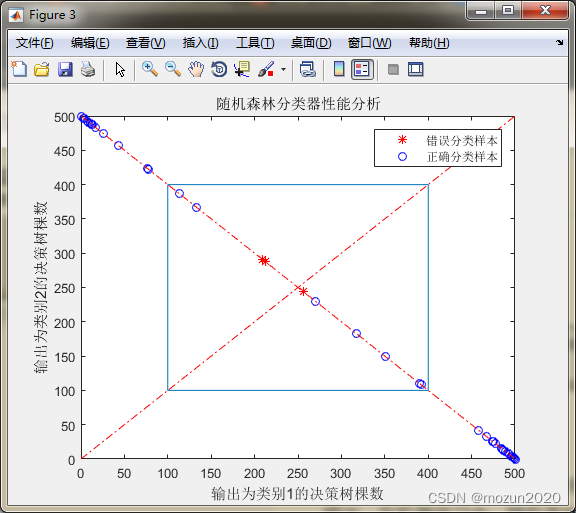
figure
index = find(T_sim ~= T_test);
plot(votes(index,1),votes(index,2),'r*')
hold on
index = find(T_sim == T_test);
plot(votes(index,1),votes(index,2),'bo')
hold on
legend('错误分类样本','正确分类样本')
plot(0:500,500:-1:0,'r-.')
hold on
plot(0:500,0:500,'r-.')
hold on
line([100 400 400 100 100],[100 100 400 400 100])
xlabel('输出为类别1的决策树棵数')
ylabel('输出为类别2的决策树棵数')
title('随机森林分类器性能分析')
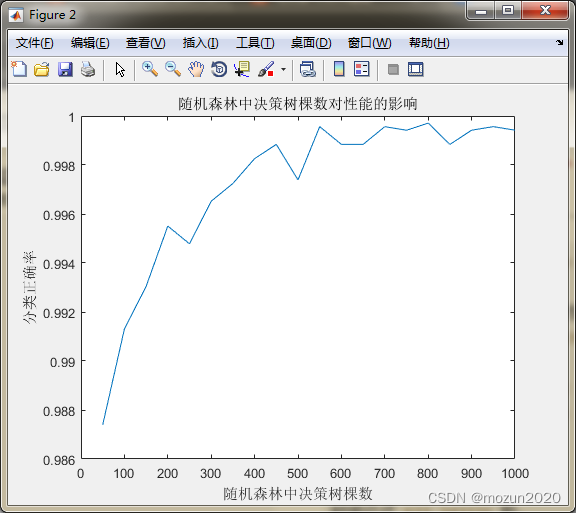
%% 随机森林中决策树棵数对性能的影响
Accuracy = zeros(1,20);
for i = 50:50:1000
%i
%每种情况,运行100次,取平均值
accuracy = zeros(1,100);
for k = 1:100
% 创建随机森林
model = classRF_train(P_train,T_train,i);
% 仿真测试
T_sim = classRF_predict(P_test,model);
accuracy(k) = length(find(T_sim == T_test)) / length(T_test);
end
Accuracy(i/50) = mean(accuracy);
end
% 绘图
figure
plot(50:50:1000,Accuracy)
xlabel('随机森林中决策树棵数')
ylabel('分类正确率')
title('随机森林中决策树棵数对性能的影响')
toc
添加完毕,点击“运行”,开始仿真,输出仿真结果如下:
Setting to defaults 500 trees and mtry=5
病例总数:569 良性:357 恶性:212
训练集病例总数:500 良性:319 恶性:181
测试集病例总数:69 良性:38 恶性:31
良性乳腺肿瘤确诊:36 误诊:2 确诊率p1=94.7368%
恶性乳腺肿瘤确诊:30 误诊:1 确诊率p2=96.7742%
时间已过 622.343231 秒。

3. 小结
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出。在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 “Random Forests” 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 “Bootstrap aggregating” 想法和 Ho 的"random subspace method"以建造决策树的集合。在视觉机器学习中0讲专栏中也有专门针对随机森林的仿真示例,文末链接可访问。对本章内容感兴趣或者想充分学习了解的,建议去研习书中第三十章节的内容。后期会对其中一些知识点在自己理解的基础上进行补充,欢迎大家一起学习交流。