文章目录
前言
本篇文章通过介绍“有重复词汇的前提下,调整一个文档中,term在文档命中的频率对分数和排名的影响,如何降低词频对得分的影响”案例,来教你Solr/Elasticsearch如何自定义Similarity。
。
一、抛出问题及解决思路
1、问题现象
比如当前solr有如下数据:
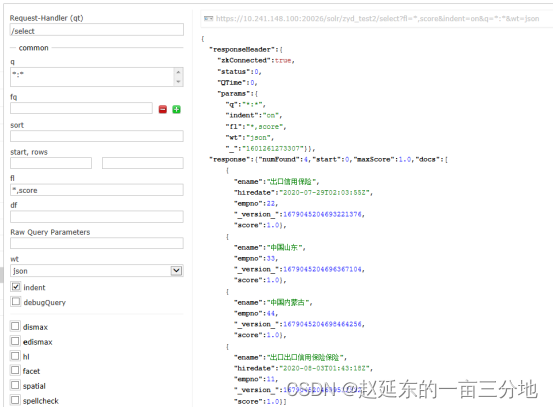
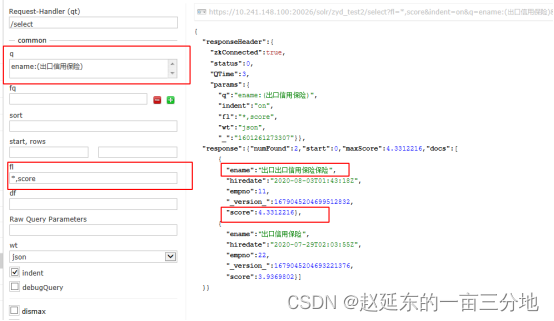
可以看到,当前Solr中有4条doc,名称字段有些是重复的,如果我这个时候想要查询出口信用保险,并且期望命中这个短的doc能够排名第一显示,此时执行查询:
2、问题解决思路
当搜索“出口信用保险”的时候,我们想让返回的带“出口信用保险”的doc排名第一,而不是包含“让出口出口信用保险保险”的doc排名第一显示。换句话说就是想让返回的“出口信用保险”这个doc得分最高,根据得分降序排序能排在第一的位置,但是以Solr目前默认的相似性算法
<similarity class="solr.ClassicSimilarityFactory"/>
来看,它认为“出口出口信用保险保险”与“出口信用保险”更相似,score更高,因为“出口出口信用保险保险”在与“出口信用保险”都能完全匹配检索词“出口信用保险”的基础上还重复匹配到了“出口”、“保险”两个词,我们认为匹配这种重复的词本身是无意义的,如果让tf 的作用变大,明显示会使得它的评分更大,但这有时候不是我们想要的,所以我们想让所有命中词的文档的tf 不受频率的影响,使其tf=1.0f,如下自定义的评分器:
import org.apache.lucene.search.similarities.ClassicSimilarity;
public class TzzSolrSimilarity extends ClassicSimilarity
{
public float tf(float freq)
{
return 1.0F;
}
public float tf(int freq)
{
return 1.0F;
}
}
使用这种评分,对于一个文档来说,一个term在文档出现的频率并不影响分数,在词频不影响最终得分后,因为“出口信用保险”长度比“出口出口信用保险保险”长度更短,按照solr匹配结果长度越短,越相似的原则,“出口信用保险”这个结果就会排在第一名了,比如下面测试:
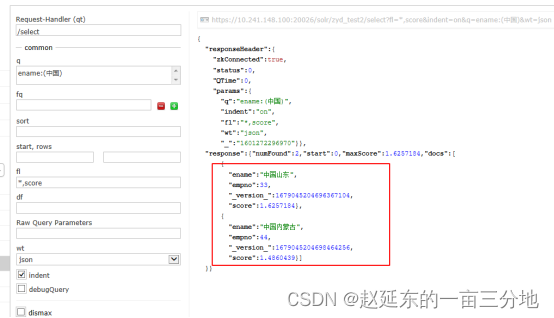
两条数据同时匹配到检索词“中国”,但是由于“中国山东”比“中国内蒙古”更短,得分更高。
3、需求
该如何新增这个自定义Similarity 。
二、新增这个自定义Similarity
整体的操作步骤如下:
1、编写TzzSolrSimilarity类
编写TzzSolrSimilarity类,并打包TzzSolrSimilarity-1.0-SNAPSHOT.jar
2、放置TzzSolrSimilarity-1.0-SNAPSHOT.jar
将TzzSolrSimilarity-1.0-SNAPSHOT.jar拷贝到每个solr所安装的机器的/opt/huawei/Bigdata/FusionInsight_HD_6.5.1.X/install/FusionInsight-Solr-6.2.0/solr-6.2.0/apache-tomcat-8.5.40/webapps/solr/WEB-INF/lib/,并执行
chown omm:wheel /opt/huawei/Bigdata/FusionInsight_HD_6.5.1.X/install/FusionInsight-Solr-6.2.0/solr-6.2.0/apache-tomcat-8.5.40/webapps/solr/WEB-INF/lib/TzzSolrSimilarity-1.0-SNAPSHOT.jar
修改jar包所属用户为omm
3、下载配置
在客户端执行
solrctl confset --get confname /opt/conf/
其中confname为目标配置集,将其下载到/opt/conf目录下
4、managed-schema新增配置
在下载的配置集的managed-schema中增加配置,此处class为第1步中的类的全路径
<similarity class="com.huawei.fusioninsight.solr.similarity.TzzSolrSimilarity">
</similarity>
5、修改solrconfig.xml
在下载的配置集的solrconfig.xml中配置
<lib dir="/opt/huawei/Bigdata/FusionInsight_HD_6.5.1.X/install/FusionInsight-Solr-6.2.0/solr-6.2.0/apache-tomcat-8.5.40/webapps/solr/WEB-INF/lib/" regex="TzzSolrSimilarity*.jar" />
6、 使用solr用户更新配置集
solrctl confset --update confname /opt/conf
其中confname为目标配置集
7、重启solr服务
验证:
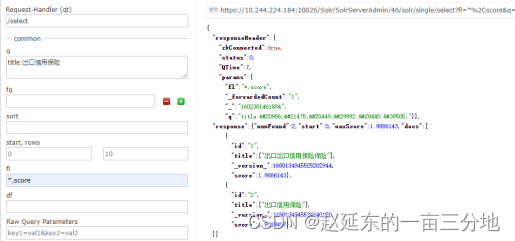
修改之前:
修改之后:
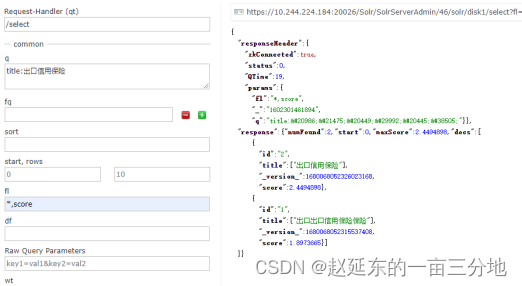
从上面结果我们能够看到,我期望的“出口信用保险” 这个doc已经排名第一了~
这就是一个完整的自定义Similarity过程。
总结
本篇文章通过介绍“有重复词汇的前提下,调整一个文档中,term在文档命中的频率对分数和排名的影响,如何降低词频对得分的影响”案例,来教你Solr/Elasticsearch如何自定义Similarity。