也到了4
将 Dropout引入SR任务中,发现可以大幅提升模型的泛化性能,甚至可以将 SRResNet 的提升到优于 RRDB 的程度,而后者参数量是前者的10倍多!
让 Dropout 操作在单图像超分领域再次伟大
论文名称:Reflash Dropout in Image Super-Resolution
论文地址:
https://arxiv.org/pdf/2112.12089.pdf
图像超分辨率 (SR) 是一个经典的低层视觉任务,旨在从低分辨率输入恢复高分辨率图像。得益于强大的卷积神经网络 (CNN),SR 网络可以轻松拟合训练数据,并获得令人印象深刻的结果。为了进一步将他们扩展到真实世界的图像,研究人员开始设计 Blind SR 方法,该方法可以处理未知的下采样核或退化。但是对 SR 训练策略的研究缺比较少。当网络规模显著增加时,过拟合问题会变得突出,导致泛化能力变得很弱。
传统 SR 任务:
-
Dropout 操作最初设计是为了缓解 High-level 视觉任务中的过拟合问题,似乎与 SR 这种 Low-level 任务的本质是冲突的。
-
Dropout 是在训练时随机丢弃掉一些神经元,以产生若干个子网络,这样每个子网络都可以得到训练。但是作为经典的回归问题,SR 具有与 High-level 任务不同的行为:对 Dropout 操作非常敏感。如果我们随机丢弃一些特征或像素,输出性能可能会严重下降。
-
过度拟合在传统的 SR 任务中似乎并不是一个非常严重的问题。
以上几条原因就是为什么 Dropout 没有在传统 SR 任务里面广泛应用的原因。但是目前这种情况发生了变化:过拟合在最近的 Blind SR 任务中是一个主要问题:对一种退化作用的过拟合导致模型在真实世界场景表现不佳,单纯增加数据和网络规模无法持续提高泛化能力。

因此作者从传统 SR 任务开始研究 Dropout 的作用,结论是通过适当地使用 Dropout 操作,SR 模型的性能可以得到显著提高,如下图1所示是不同的实验设置下采用 Dropout 前后的性能对比,可以看到:引入 Dropout 可以大幅提升模型的泛化性能,甚至可以将 SRResNet 的提升到优于 RRDB 的程度,而后者参数量是前者的10倍多!重要的是,添加 Dropout 仅需一行代码,真正无痛涨点!

Dropout 操作
Dropout 操作的关键思想是在训练期间从神经网络中随机丢弃一些 unit (以及它们的连接)。所以在训练阶段,Dropout 操作使得我们每次只更新一部分子网络,而不是整体的大网络,在推理阶段平均所有子网络的结果。
训练时按照伯努利分布以概率 p 随机将输入中的某些元素置为0,并对输出乘以 1/1-p。
Dropout 操作已被证明是一种有效的正则化技术。
Input 可以是任意维度,Output 和 Input 维度一致。
接下来我们讲解三种 PyTorch 为我们提供的 Dropout 操作。
① torch.nn.Dropout(p=0.5,inplace=False)
功能:随机把 Input 里面的一些元素置0,再乘以 1/1-p。
Input:(H, W)
Output:(H, W)
m = nn.Dropout(p=0.2)
input = torch.randn(3, 2)
output = m(input)
print(input)
print(output)
# Input:
tensor([[ 0.7843, 0.0706],
[ 0.4554, -0.3986],
[-0.5532, 0.2141]])
# Output:
tensor([[ 1.5686, 0.0000],
[ 0.9108, -0.7971],
[-1.1065, 0.0000]])
② torch.nn.Dropout2d(p=0.5,inplace=False)
功能:随机把 Input 里面某个 channel 的元素全部置0,再乘以 1/1-p。
Input:(N, C, H, W)
Output:(N, C, H, W)
m = nn.Dropout2d(p=0.5)
input = torch.randn(1, 3, 2, 2)
output = m(input)
print(input)
print(output)
# Input:
tensor([[[[ 0.9778, -1.0291],
[ 1.9370, 0.6675]],
[[ 0.3541, -1.5406],
[ 0.8875, -0.2548]],
[[ 0.9533, 0.1804],
[-2.1946, -1.9770]]]])
# Output:
tensor([[[[0., -0.],
[0., 0.]],
[[0., -0.],
[0., -0.]],
[[0., 0.],
[-0., -0.]]]])
③ torch.nn.Dropout3d(p=0.5,inplace=False)
功能:随机把 Input 里面某个 channel 的元素全部置0,再乘以 1/1-p。
Input:(N, C, D, H, W)
Output:(N, C, D, H, W)
m = nn.Dropout3d(p=0.5)
input = torch.randn(1, 3, 2, 2, 2)
output = m(input)
print(input)
print(output)
# Input:
tensor([[[[[-0.5544, -0.9302],
[ 0.2269, 2.7334]],
[[-1.3619, 0.5699],
[ 0.0862, 0.9609]]],
[[[-1.8406, -2.6052],
[-0.0212, 0.1684]],
[[ 0.7024, -0.2568],
[ 0.3187, -0.7208]]],
[[[ 1.0922, 0.5909],
[-0.7926, 1.9536]],
[[ 1.0438, -0.3441],
[-0.5067, -0.0417]]]]])
# Output:
tensor([[[[[-1.1088, -1.8604],
[ 0.4539, 5.4667]],
[[-2.7237, 1.1397],
[ 0.1724, 1.9217]]],
[[[-3.6813, -5.2105],
[-0.0424, 0.3367]],
[[ 1.4049, -0.5136],
[ 0.6374, -1.4417]]],
[[[ 0.0000, 0.0000],
[-0.0000, 0.0000]],
[[ 0.0000, -0.0000],
[-0.0000, -0.0000]]]]])
有趣的超分实验观察
观察1:对性能不利的 Dropout
这小节的实验是在常规 SR 设置下进行的,其中唯一的退化是双三次下采样。使用的 Dropout 策略是 channel-wise 的 Dropout (即随机将整个 channel 的特征置为0)。如下图2所示,加了 Dropout 操作之后性能急剧下降 (图2a)。这个结果符合我们的常识。这表明回归模型不同于分类模型。在回归中,网络中的每个元素都对最终输出有贡献,最终输出是连续的RGB值,而不是离散的类标签。

观察2:不影响性能的 Dropout
作者还发现一个与上述结论相悖的特例 (图2b),即仅在最后一层的卷积之前添加 Dropout 操作。发现对模型的性能是没有影响的,这意味着:最后一层的特征可以随机 discard 且不会影响回归结果。这些特征发生了什么?这是否意味着回归与分类网络具有某些共性呢?
观察3:对性能有利的 Dropout
作者还发现一种与上述结论相悖的情况 (图2c,d),在多种退化作用 (multiple-degradation) 下,Dropout 操作有益于超分。这意味着:Dropout 操作可以一定程度下改善超分模型的泛化性能。
这种实验的设置为:训练数据包含多种退化作用,即 Real-SRResNet。作者在倒数第二个卷积层添加了 Dropout 操作。测试数据包括双三次下采样数据 (包括在训练数据里面) 和最近邻下采样数据 (不包括在训练数据里面)。从图2 (c)(d) 里面可以看得出来 Dropout 都使性能得以提升,提升了模型的泛化能力。
在超分任务中使用 Dropout
本小节实验的模型为 SRResNet 和 RRDB。本小节的结论可以很容易地推广到其他基于 CNN 模型的 SR 网络,因为它们共享类似的架构。Dropout 作为一种简单灵活的操作,有着多种应用方式。一般来说,Dropout 的效果主要取决于两个方面,一是 Dropout 的位置,二是 Dropout 的策略 (使用的维度和 Dropout 概率 p) 。
Dropout 的位置
如下图3所示为 Dropout 操作的不同使用位置示意图,可以划分为三大类:
-
Dropout before the last-conv
-
Dropout at middle of network
-
Dropout in residual network

Dropout before the last-conv: 如图3(a) 所示,Hinton 等人首先在 High-level 任务中引入了 Dropout,并在最后的 classifier 之前使用。类似地,作者也在输出卷积层 (从64通道到3通道,称之为 last-conv) 之前应用 Dropout。
Dropout at middle of network: 如图3(a) 所示,不失一般性,作者将 SRResNet 残差块 (16个块) 分成四组。每组由四个残差块组成。作者选择 B4、B8、B12、B16 作为代表位置,其中的数字表示在哪个区块之后添加了 Dropout。
Dropout in residual network: 如图3(c) 所示,在一个 block 里面多次添加 Dropout 操作。根据前人的实验,在网络深处使用这种 Dropout block 可以产生好的结果。本文作者设计了3种不同的方法来在 SR 网络中使用 Dropout block,将它们分别命名为 all-part, half-part 和 quarter-part。
Dropout 的策略 (使用的维度和 Dropout 概率 p)
Dropout 操作最初用于全连接层,因此,没有必要确定要丢弃掉哪个维度。但是,在卷积层中使用后,在不同的维度 (element-dropout 和 channel-dropout) 会带来不同的效果。
Dropout 概率 p 决定了 channel 或者 element 的丢弃比例。一般而言,Dropout 概率 p 过大会使性能变差。在分类网络中,50% 的概率不会影响最终的结果但会提升泛化性能。但是,该概率对于 SR 网络来说可能过大了,因为其鲁棒性能相对分类网络而言差很多。为获得可能的性能增益且不影响模型,作者尝试了3种概率:10%、20% 和 30%。
综上所述:Dropout 的位置一共8种不同的设置,Dropout 的维度有2种 (channel 和 dimension),Dropout 的概率有3种 (10%,20%,30%)。作者分别做实验观察它们的结果。
单退化作用实验结果
实验设置: SR 任务通常有两种常用的设置,分别是单退化作用 (single-degradation setting) 和多退化作用 (multi-degradation setting)。多退化作用能够更好地模拟真实世界的退化过程。目前,SR 网络的性能主要取决于其泛化能力。作者遵循了 Real-ESRGAN 中引入的高阶退化模型 (high-order degradation modelling)。
底层任务超详细解读 (三):只用纯合成数据来训练真实世界的盲超分模型 Real-ESRGAN

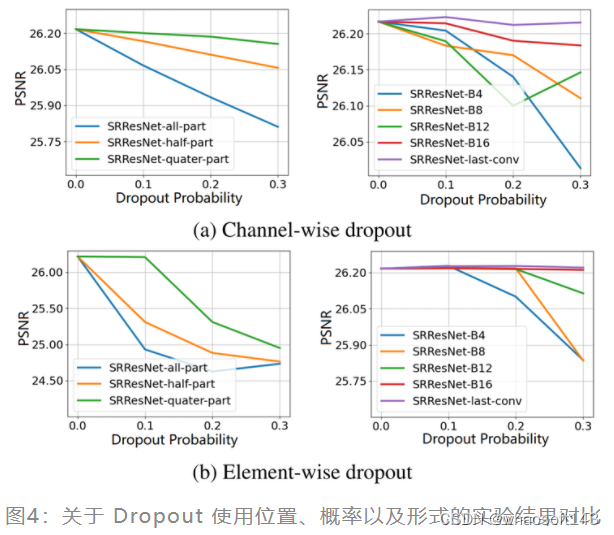
在该部分实验中,作者以 bicubic 退化配置探索 Dropout 的使用方式。下图3给出了关于 Dropout 使用位置、概率以及形式的实验结果对比,从中可以看到:
-
图4 (d):不同的 Dropout 位置带来的模型性能也不相同,在只使用一次 Dropout 的情况下,它的位置越靠近输出,性能下降越少。
-
图4 (a):当使用多个 Dropout 时,Dropout 数量的增加会导致性能的下降。
-
图4 (a)(b):使用 element-wise 的 Dropout 操作会使性能下降,而 channel-wise 的 Dropout 通常性能更好。
-
图4 (b):Dropout 概率 p 越大,SR 模型性能越差,但是对 last-conv 使用10%的 Dropout 却带来性能的略微提升,这说明 last-conv + channel-wise Dropout 的实用组合可以带来有意义且鲁棒的结果。
多退化作用实验结果
多退化作用能够更好地模拟真实世界的退化过程。在这一小节的实验里面,作者遵循了 Real-ESRGAN 中引入的高阶退化模型 (high-order degradation modelling)。
在多退化作用的训练设置下,SR 网络需要学习如何同时恢复多个不同的退化作用。让 SR 网络直接学习解决所有的退化作用将使 SR 网络在单一的退化作用上表现不佳。但作者发现在多退化作用的设置下,通过引入 Dropout 可以显著改善性能。如下图5所示,作者测试了一些常见退化和复杂退化组合的性能。
图5中的每一大行是8种不同退化作用的 Dropout 结果和不使用 Dropout 的结果以及带来的提升。作者使用 bicubic,blur,noise 和 jpeg 来产生退化作用。Gaussian blur ('b'):kernel size=21,标准差为2;Gaussian noise ('n'):标准差为20;JPEG compression ('j'):quality=50。
红色字体代表 Real-SRResNet (w/ Dropout) 的性能优于 Real-RRDB (wo Dropout),将近一半字体是红色的。但是 Real-RRDB 的参数量是 Real-SRResNet 的十多倍!而且,添加 Dropout 仅需一行code:One line of code is worth a ten-fold increase in the model parameters (来自原文)。
 如下图6所示是使用 Dropout 前后模型的可视化效果对比,可以看到:使用 Dropout的模型具有更好的内容重建、伪影移除以及降噪效果。
如下图6所示是使用 Dropout 前后模型的可视化效果对比,可以看到:使用 Dropout的模型具有更好的内容重建、伪影移除以及降噪效果。
 Dropout 概率 p 的对比实验
Dropout 概率 p 的对比实验
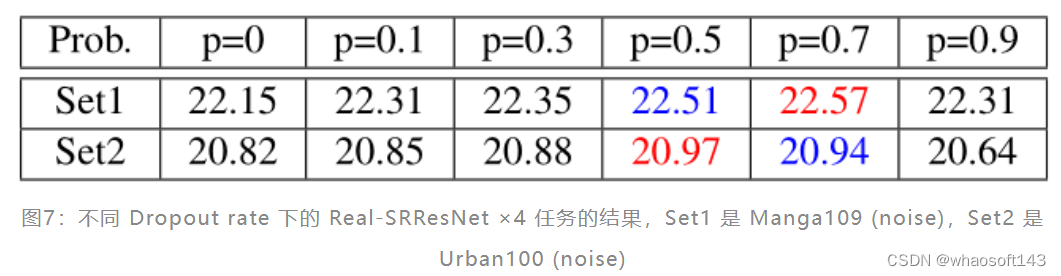
在单退化作用实验中,p 的最佳点是10%。但是在多退化作用实验中,p 的最佳点会更大。如下图7所示是不同 Dropout rate 下的 Real-SRResNet ×4 任务的结果,Set1 是 Manga109 (noise),Set2 是 Urban100 (noise)。
通过 Channel Saliency Map 解释 Dropout 实验现象
下面2个小节作者想探究 Dropout 是如何提升 SR 网络的泛化能力的。作者通过 Channel Saliency Map 从归因图的角度以及通过 Deep Degradation Representation 从泛化性能的角度解释了 Dropout 的实验现象。
 Attribution map 代表的含义是显著图,即:Attribution map 里面较亮的像素表明对 SR 结果的影响较大。从下图8可知,当我们对某些特征进行 Mask 之后,我们可以得到不同的 PSNR 值,更低的 PSNR 值对应了更明亮的显著性图,更亮显著性图意味着对超分结果的更大影响。很明显:不同特征对于最终的结果影响程度是不一样的。有些特征 Mask 掉以后 PSNR 下降严重,这些特征的 Attribution map 也更亮。
Attribution map 代表的含义是显著图,即:Attribution map 里面较亮的像素表明对 SR 结果的影响较大。从下图8可知,当我们对某些特征进行 Mask 之后,我们可以得到不同的 PSNR 值,更低的 PSNR 值对应了更明亮的显著性图,更亮显著性图意味着对超分结果的更大影响。很明显:不同特征对于最终的结果影响程度是不一样的。有些特征 Mask 掉以后 PSNR 下降严重,这些特征的 Attribution map 也更亮。
 图10说明 Real-SRResNet without dropout 模型在更多的 channel 被置0时性能急剧下降,但是 Real-SRResNet with dropout 模型在更多的 channel 被置0时性能保持不变。这说明对于一个有 Dropout 的模型,PSNR 不再取决于几个特定的 channel 了。即使是只有网络的1/3的通道也足以维持模型性能。这说明 Dropout 能够帮助模型防止 co-adapting,带来更好的性能。
图10说明 Real-SRResNet without dropout 模型在更多的 channel 被置0时性能急剧下降,但是 Real-SRResNet with dropout 模型在更多的 channel 被置0时性能保持不变。这说明对于一个有 Dropout 的模型,PSNR 不再取决于几个特定的 channel 了。即使是只有网络的1/3的通道也足以维持模型性能。这说明 Dropout 能够帮助模型防止 co-adapting,带来更好的性能。
 通过 Deep Degradation Representation 解释 Dropout 实验现象
通过 Deep Degradation Representation 解释 Dropout 实验现象
Deep Degradation Representation 代表 "超分模型的语义信息",解读见下文。
底层任务超详细解读 (七):探索超分模型中的 "语义" 信息代表什么
图11中的 (a)(b)(c) 代表一个128×128的输入样本,通过5种不同的退化作用时形成的500个点 (每种退化是100个点)。Deep Degradation Representation 说明了超分模型可以根据语义信息的不同把不同退化类型的输入图像聚到不同的类别中。例如,图11(a) 中,不同颜色的点表示输入图片具有不同的退化作用。
也就是说,具有相似退化作用的输入图片会被聚类在一起。如果不同的聚类结果之间边界清晰,那么网络倾向于仅处理特定的退化聚类,而忽略其他聚类,从而导致较差的泛化性能。反之,如果不同的聚类结果混杂在一起,这说明网络能够很好地处理所有输入。
从图11(a)和(b) 可以得出结论,原始的 SRResNet 的聚类结果好于 Real-SRResNet,这说明训练数据包含各种退化作用网络的泛化性能更强。 whaosoft aiot http://143ai.com
从图11(b)和(c) 可以得出结论,加了 Dropout 之后,Real-SRResNet 的聚类结果好于不加的 Real-SRResNet,这说明模型的泛化性能更强了。
Calinski-Harabaz Index (CHI) 指标是用来衡量语义的区分度:不同特征聚类之间的区分度越强,同一类内部的紧密度越高,CHI 分数更高。也就是说,当聚类被很好地分开时,CHI 分数更高,这表明语义区分能力更强。
我们也可以发现,当 Dropout rate p 逐渐增大时,CHI 逐渐降低,证明聚类效果逐渐变差,也就是模型的泛化性能也在逐渐变强。
另一个有趣的发现是,含噪声的样本聚类的分布 (图11绿点) 总是最不同的。这也是为什么在有噪声的数据上获得的性能也远不如在干净的数据上获得的性能。

总结
Dropout 操作最初设计是为了缓解 High-level 视觉任务中的过拟合问题,似乎与 SR 这种 Low-level 任务的本质是冲突的。本文作者从传统 SR 任务开始研究 Dropout 的作用,结论是通过适当地使用 Dropout 操作,SR 模型的性能可以得到显著提高,引入 Dropout 可以大幅提升模型的泛化性能,甚至可以将 SRResNet 的提升到优于 RRDB 的程度,而后者参数量是前者的10倍多!重要的是,添加 Dropout 仅需一行代码。对于单退化任务,Dropout 的最优使用方式是 last-conv + channel-wise 的方式,最优的 Dropout rate 为 10%。对于多退化任务,Dropout 依然采用 last-conv + channel-wise 的方式,最优的 Dropout rate 更大。最后,作者通过 Channel Saliency Map 从归因图的角度以及通过 Deep Degradation Representation 从泛化性能的角度解释了 Dropout 的实验现象。