概述
SELF: A method of searching for library functions in stripped binary code [C&S 2021]
Xueqian Liua Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China
Shoufeng Cao The National Computer Network Emergency Response Technical Team Coordination Center of China, Beijing, China
Zhenzhong Cao School of Software, Qufu Normal University, Qufu, China
Qu Gao School of Software, Shandong University, Jinan, China
Lin Wan School of Software, Shandong University, Jinan, China
Fengyu Wang School of Software, Shandong University, Jinan, China
在软件开发过程中, 会使用许多第三方库, 识别软件中被使用到的库函数在一些安全场景下有重要意义, 比如检测已知开源库中的漏洞和对恶意软件的逆向分析. 一种可行的方案是通过匹配库函数和目标软件中的函数进行函数识别, 不过由于多样化的库版本, 编译器, 编译选项等等, 即便在同一个函数之间也会存在许多差异. 因此在目标软件中准确识别库函数依然是一个具有挑战性的问题.
在本文中, 作者提出一种称为 SELF(SEarch for Library Functions) 的新方案进行目标软件中的库函数识别任务. 在 SELF 中, 函数用一个共现矩阵表示且用卷积自编码器进行编码(convolutional auto-encoder, CAE). 然后两个函数之间的相似度用产生瓶颈的特征衡量. 这个方案主要集中于可区分的语义特征, 因此不仅可以区分不同函数, 还可以区分相同函数的细微差别. 实验总共收集451个软件项目, 包括大约3百万个函数, 来训练和评估 SELF. 结果显示 SELF 在Recall@1和Recall@5指标上表现良好, 特别是在库版本差异比较大时, SELF 的性能显著超过 BINDIFF. 另外 SELF 的计算效率也比较高.
一句话: 基于语义特征, 用共现矩阵和自编码器衡量函数相似度进行目标软件中的库函数识别
导论
Motivations
在过去的十年中,开源代码已经成为软件开发的基础和创新的动力。一种常见的开发实践是对必要但通用的组件使用开源库,而从逆向分析者的角度来看, 如果能识别出开源库的函数, 那么分析负担会大幅下降. 又由于不同软件版本, 编译器, 编译选项等因素, 使得二进制文件多样化, 在 stripped binary code 中进行函数识别十分具有挑战性同时也是一个待解决的难题.
Contributions
(1) 提出 SELF 解决方案对目标软件进行库函数识别
(2) 因为代码多样性, 单纯用语义特征是不够的, 作者因此使用操作码组合(opcode bigrams),并将其进一步转换为共现矩阵(co-occurrence matrix),抽象地表示函数语义
(3) 受CNN在图像领域应用效果的启发, 作者提出卷积自编码器 (convolutional autoencoder, CAE), 来提取共现矩阵中的瓶颈特征.
Problem definition
(1) Main research target: 识别一个软件中使用的库函数,并且该软件的调试信息已被剥离
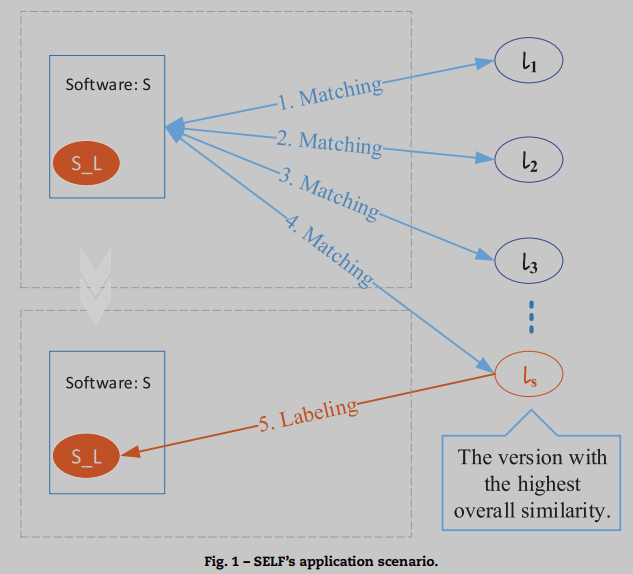
(2) SELF’s application scenarios: 当逆向分析人员面对剥离的二进制代码时,他们可能会面临以下两种情况之一: 不知道软件中使用了哪些函数库,或者已经知道函数库但不知道确切的版本。假设对于函数库 L L L, 收集一组不同版本的函数库集 l = { l 1 , l 2 , . . . } l = \{l_1, l_2, ...\} l={
l1,l2,...}, 设没收集的版本函数库集为 l ′ = { l 1 ′ , l 2 ′ , . . . } l' = \{l_1', l_2', ...\} l′={
l1′,l2′,...}. 对于一个目标软件 S S S, 函数库 L L L 以静态连接方式连接进软件中, 但是库版本未知. 假设待检测目标库版本为 S L S_L SL, 进行识别函数库识别任务分为三个步骤, 1.使用所有已收集的库版本对S进行相似度匹配, 得到每个函数之间的相似度, 2.选择相似度最高的库版本 l S l_S lS, 3.根据 l S l_S lS中的函数名对 S L S_L SL 各个函数进行标记.
(3) Accuracy verification: 构建数据集保留调试符号信息, 在实验中,目标软件和函数库都保留了有意义的函数名,可以用来确认匹配结果,而在实践中,只有函数库才有有意义的函数名,可以用来标记目标软件中配对的函数。
方法
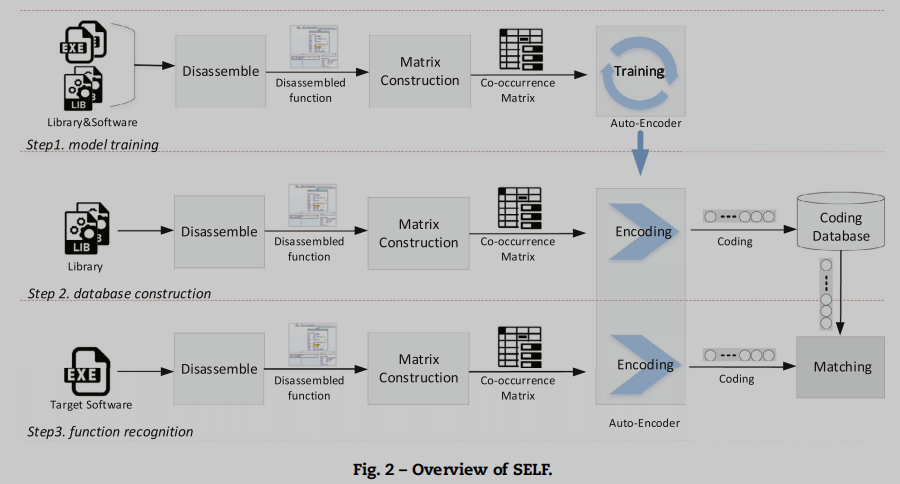
Workflow
首先通过统计两个相邻操作码序列, 为每个库函数构建共现矩阵. 再以大量共现矩阵作为输入训练CAE模型.
接着CAE将所有收集的库中的每个函数表示为瓶颈特征, 然后存储于数据库里
最后对目标软件中的每个函数与数据库中的函数做相似度分析, 得到匹配的结果
Co-occurrence matrix
二进制函数由一个指令序列组成,每条指令可以分为操作码和操作数。如果一个函数被两个软件程序使用,它的指令操作数通常是不同的,例如内存地址引用。与操作数相比,操作码序列代表函数的动作,即使在不同版本中,其统计属性也相对稳定。因此操作码是函数的内在属性, 可以用于描述函数差异性. 并且任何指令集中的操作码数量都是有限的,这可以有效地压缩统计模型的维度空间。所以作者采取丢弃操作数保留操作码的策略.


通过将操作码序列转换为n-gram的集合,一个函数可以嵌入到向量空间中。假设操作码种类数为m, 则可以得到 m n m^n mn维度的空间. n 越大可以表示的上下文信息越多, 但空间成本也会变大. 所以为了效率 SELF 选择 bigram 来表示函数. 形式化表示
设函数操作码序列为 x = ( x 1 , x 2 , . . . , x d ) x = (x_1, x_2, . . ., x_d ) x=(x1,x2,...,xd), 则表示为n-gram得到 g = ( g 1 n , g 2 1 + n , . . . , g d − n + 1 d ) g = (g^n_1, g^{1+n}_ 2 , . . ., g^d_{d−n+1}) g=(g1n,g21+n,...,gd−n+1d), 其中 g i i + n − 1 = ( x i , x i + 1 , . . . , x i + n − 1 ) g_i^{i+n−1} = (x_i, x_{i+1}, . . ., x_{i+n−1}) gii+n−1=(xi,xi+1,...,xi+n−1), d d d 是函数长度.
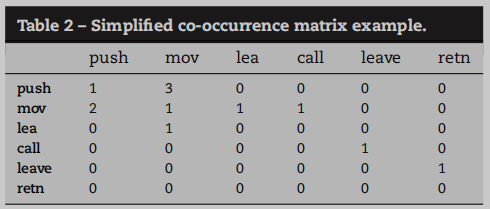
比如 Table I 的操作码序列可以表示为其下的形式, 然后对于重复出现的操作码対, 可以统计其频率得到
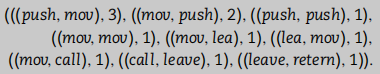
至此可以构建共现矩阵, 矩阵中显示的计数是bigram频率,它只显示当前操作码的下一个操作码。使用这种表示,函数的一些信息将会丢失。另外基本块之间的相邻操作码被忽略掉, 因为物理相邻的基本块在逻辑上未必相关.
CAE
如果直接使用这些大小为N × N的共现矩阵进行函数相似度分析,高维数据会严重影响效率,冗余数据会降低精度。因此,在压缩数据的同时,我们还需要弱化冗余数据的影响。为了满足这一要求,我们使用了卷积自动编码器(CAE) 从共现矩阵中提取瓶颈特征。
自动编码器(AE)是一种旨在将输入复制到输出的神经网络。它们的工作原理是将输入压缩到潜在空间表示中,然后从该表示中重构输出。
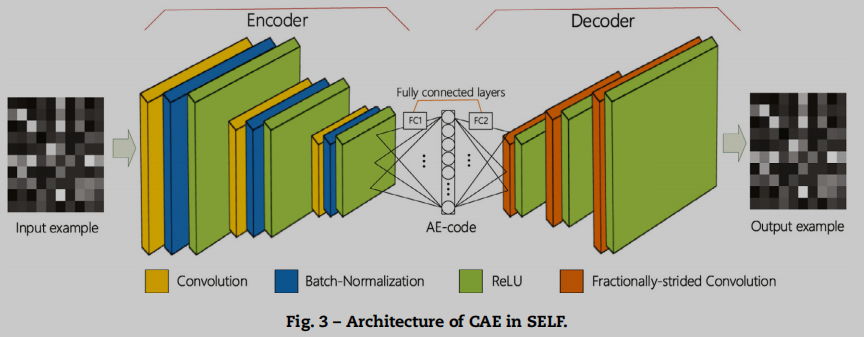
Functions Matching
用CAE模型对函数进行编码后,可以对函数进行相似度分析。在这里使用Pearson相关系数作为相似度的度量
ρ X , Y = cov ( X , Y ) σ X σ Y = E [ ( X − μ X ) ( Y − μ Y ) ] σ X σ Y \rho_{X, Y}=\frac{\operatorname{cov}(\mathrm{X}, \mathrm{Y})}{\sigma_{\mathrm{X}} \sigma_{\mathrm{Y}}}=\frac{E\left[\left(\mathrm{X}-\mu_{\mathrm{X}}\right)\left(\mathrm{Y}-\mu_{\mathrm{Y}}\right)\right]}{\sigma_{\mathrm{X}} \sigma_{\mathrm{Y}}} ρX,Y=σXσYcov(X,Y)=σXσYE[(X−μX)(Y−μY)]
设目标软件的函数代码集为 A = a 1 , a 2 , … , a n A = {a_1, a_2,…, a_n} A=a1,a2,…,an,函数库的函数代码集为 B = b 1 , b 2 , … , b m B = {b_1, b_2,…, b_m} B=b1,b2,…,bm。我们的目标是在A和B之间进行函数匹配。对于A中的 a i a_i ai,我们依次计算它与B中的每个函数的相似系数,相似系数最高的库函数就是最终的匹配。如果有相同相似度的情况则需特殊处理来决定最终匹配结果

实验
数据集
作者使用 IDA Pro 提供的脚本语言 idpython 编写插件来提取函数特征。从3669个二进制文件(包括软件和库)中收集了一组 3,079,563 个函数样本。第一个来源是GitHub(2021),从那里收集了46个开源项目的源代码。然后使用GCC-7.4和默认优化选项编译每个版本。第二个来源是Softpedia(2021)。从其中的405个项目中收集了3076个二进制文件. 并且忽略掉指令数小于5条的函数(信息太少难以匹配); 之后将数据集分为三个不相交的子集(训练集、验证集和测试集)进行评估.
实验指标
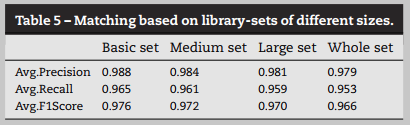
根据真实配对函数是否在包括的前K个匹配候选中,即 Recall@K,来评估SELF。对于每个测试的函数,如果从前K个匹配中检索到真正配对的函数,则得分为1,否则为0。对于一个测试集,计算所有函数的平均分为 average Recall@K。此外使用经典指标,包括正确率、召回率和F1得分,来评价方案的有效性。
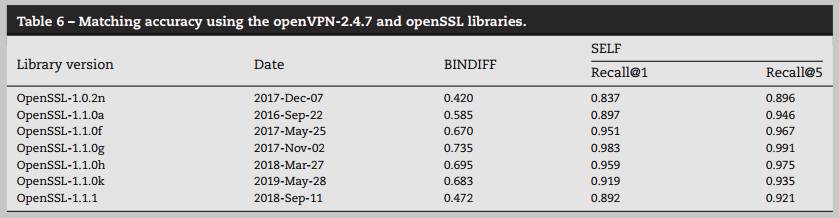
跨库匹配
对于跨库匹配函数的任务目标, 以OpenSSL的不同版本作为实验测试对象, 具有80%+的准确率, 而且超过BINDIFF许多
通用性实验
对更多函数库和软件进行了匹配
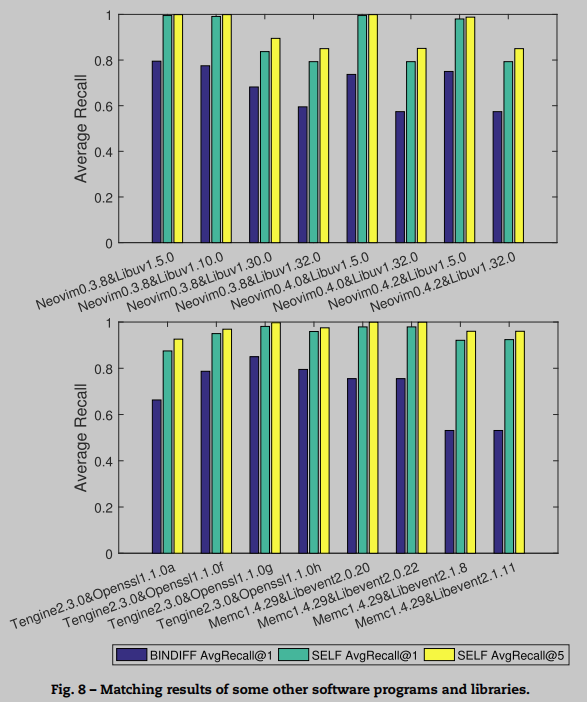
横向对比
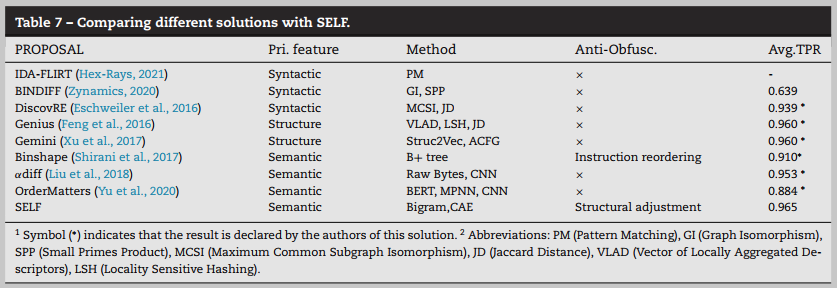
总结
Related Works
库函数识别本质上是相似度检测问题(binary code similarity detection, BCSD)
传统的和广泛使用的IDA Pro Hex-Rays(2021)使用 FLIRT (快速库识别和识别技术)来匹配库函数,其中类似于bytelevel正则表达式的模式来自现有库。但从库函数派生的模式只能用于查找字节数几乎相同的库代码,而不能用于处理不同库版本之间的细微差异.
Insights
(1) 使用操作码序列来描述函数差异性
(2) 基本块之间的相邻操作码被忽略, 如果采取某种方式引入逻辑相关的基本块n-gram, 也许能进一步提高模型精度
(3) 把AI领域的优秀成果搬砖到二进制领域的一篇教学论文(