论文链接:Self-critical Sequence Training for Image Captioning
引言
现在image caption主要存在的问题有:
exposure bias:模型训练的时候用的是叫“Teacher-Forcing”的方式:输入RNN的上一时刻的单词是来自训练集的ground-truth单词。而在测试的时候依赖的是自己生成的单词,一旦生成得不好就会导致误差的积累,导致后面的单词也生成得不好。
模型训练的时候用的是cross entropy loss,而evaluate的时候却用的是BLEU、ROUGE、METEOR、CIDEr等metrics,存在不对应的问题。
由于生成单词的操作是不可微的,无法通过反向传播来直接优化这些metrics,因此很多工作开始使用强化学习来解决这些问题。
但强化学习在计算期望梯度时的方差会很大,通常来说是不稳定的。又有些研究通过引入一个baseline来进行bias correction。还有一些方法比如Actor-Critic,训练了一个critic网络来估算生成单词的value。
而本文的方法则没有直接去估算reward,而是使用了自己在测试时生成的句子作为baseline。sample时,那些比baseline好的句子就会获得正的权重,差的句子就会被抑制。具体做法会在后面展开。
Caption Models
本文分别使用了两个caption model作为基础,分别是
- FC model [3, 4]。就是以cross entropy loss训练的image caption模型,公式基本跟show and tell里的公式一样。
- Attention Model(Att2in)。本文对原模型的结构进行了一些修改,只把attention feature输入到LSTM的cell node,并且发现使用ADAM方法优化的时候,这种结构的表现优于其他结构。
FC models
公式就不打了,只需要知道LSTM最后输出的是每个单词的分数 ,再通过softmax得到下一个单词的概率分布为 。
训练目标是最小化cross entropy loss(XE):
是模型的参数, 是训练集中的语句, 、 在后面Reinforcement Learning部分会被用到。
Attention Model(Att2in)
公式基本跟FC Model的一样,只不过在cell node的公式里加了个attention项,其他部分以及loss function也跟上面一样的。
Reinforcement Learning
把序列问题看作是一个RL的问题:
- Agent: LSTM
- Environment: words and image features
- Action: prediction of the next word(模型的参数 定义了一个policy ,也就是上面的 ,从而导致了这个action)
- State: cells and hidden states of the LSTM, attenion weights etc
- Reward: CIDEr score r
训练目标是最小化负的期望
是生成的句子。
实际上, 可以依据 的概率来进行single sample(而不是选择概率最大的那一个), 可以近似为:
L关于 的梯度为:
推导过程:
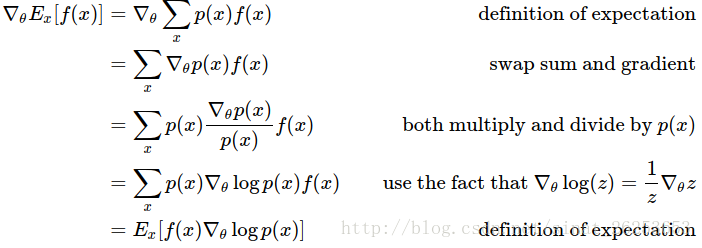
再引入一个baseline来减少方差:
baseline可以是任意函数,只要它不依赖action
,引入它并不会改变梯度的值,证明如下:
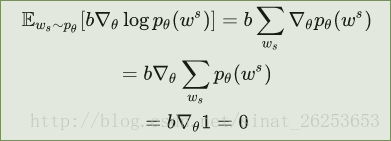
实际上
可以被近似为:
应用链式法则,梯度可以表示为:
根据Reinforcement learning neural turing machines: //我在原文并没有找到为什么可以这样近似,但在SEQUENCE LEVEL TRAINING WITH RECURRENT NEURAL NETWORKS里面有解释
是词的one-hot向量表示。
Self-Critical sequence training(SCST)
SCST阶段的训练过程如图所示:
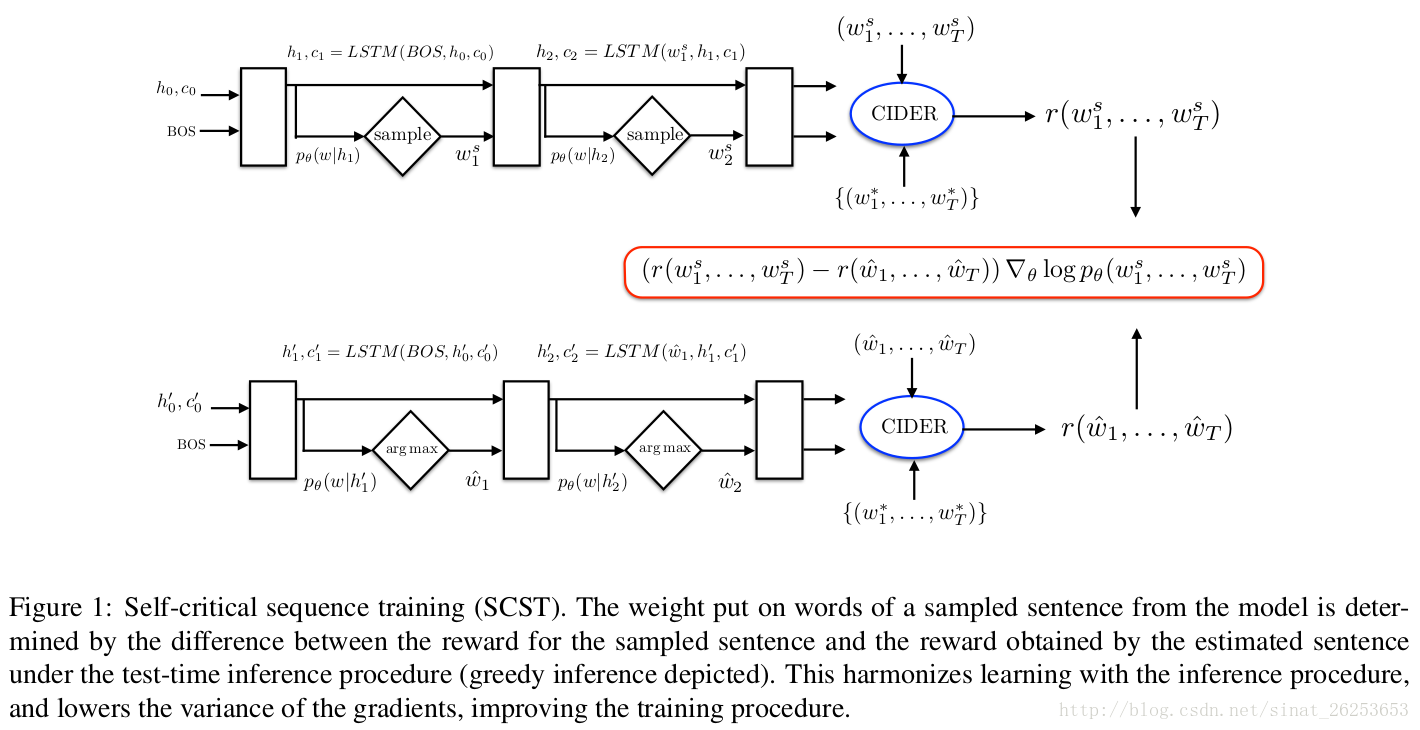
SCST的思想就是用当前模型在测试阶段生成的词的reward作为baseline,梯度就变成了:
其中 ,就是在测试阶段使用greedy decoding取概率最大的词来生成句子;
而 是通过根据概率来随机sample词,如果当前概率最大的词的概率为60%,那就有60%的概率选到它,而不是像greedy decoding一样100%选概率最大的。
公式的意思就是:对于如果当前sample到的词比测试阶段生成的词好,那么在这次词的维度上,整个式子的值就是负的(因为后面那一项一定为负),这样梯度就会上升,从而提高这个词的分数 ;而对于其他词,后面那一项为正,梯度就会下降,从而降低其他词的分数。
Experiments
训练阶段,作者使用了curriculum learning的方法:先对最后一个词使用CIDEr的目标进行训练,前面的词则使用XE进行训练,然后逐步开始提高比例,对最后两个词、三个词用CIDEr进行训练。但最后发现在MSCOCO数据集上,这种训练方法没有提高模型的performance。
作者也对其他的metrics进行优化,但是发现只有优化CIDEr才能提高其他metrics的得分。
有意思的是,文章还对一些objects ut-of-context(OOOC)的图片进行实验,发现使用了SCST优化的Att2in模型能准确地描述图片。

但至于为什么模型有这样的能力,文章没有进行探讨。
Supplementary Material
几个有意思的点:
- 跟SEQUENCE LEVEL TRAINING WITH RECURRENT NEURAL NETWORKS的发现一样,作者发现使用RL加beam search训练的模型只比RL加greedy decoding训练的模型有少量的提升。
- 在优化CIDEr的时候要把EOS tag当成单词,不然的话生成的句子会含有大量的”with a”
“and a”这样没有意义但是能在CIDEr标准里面拿高分的单词。在CIDEr-D里面引入了截断和基于长度的惩罚,实际上就是本文所优化的(为什么不直接优化CIDEr-D呢?)
本文链接:http://blog.csdn.net/sinat_26253653/article/details/78458894
参考:用Reinforcement Learning来做image captioning