最近看了这篇论文, 写了些心得体会,仅代表个人看法,如有不对还请多多指教!
本文提出了一种新的设计方案,在基于注意的编解码框架下,探讨图像描述对象之间的联系。具体来说,我们提出了图形卷积网络和长期短期内存(称为gcn-lstm)架构,这种新颖的方法将语义和空间对象关系整合到图像编码器中。从技术上讲,我们根据图像中检测到的对象的空间和语义联系来构建关系图形。然后,通过GCN利用图形结构,对每个区域的表示进行细化,得到区域级关系感知特征,然后将其注入到attention lstm中生成句子。
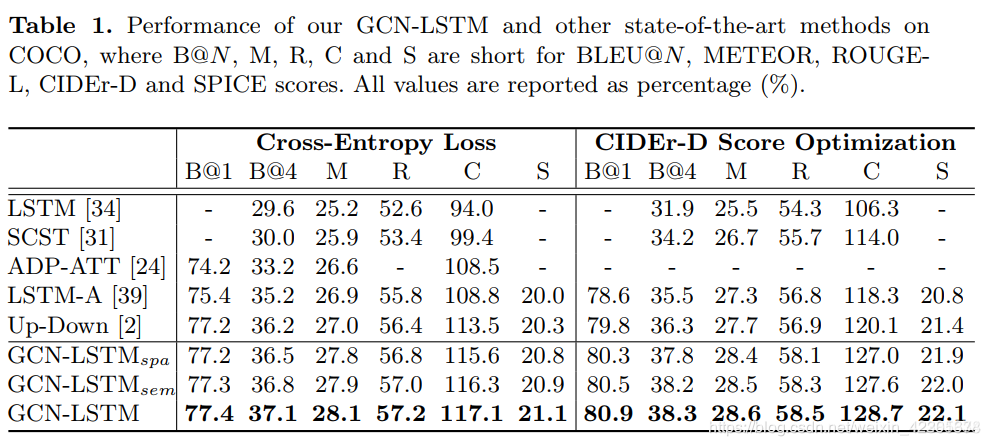
在COCO图像描述数据集上进行了广泛的实验,当与最先进的方法相比时,报告了更好的结果. 更值得注意的是,GCN-LS TM在COCO测试集上将CIDER-D性能从120.1%提高到128.7%
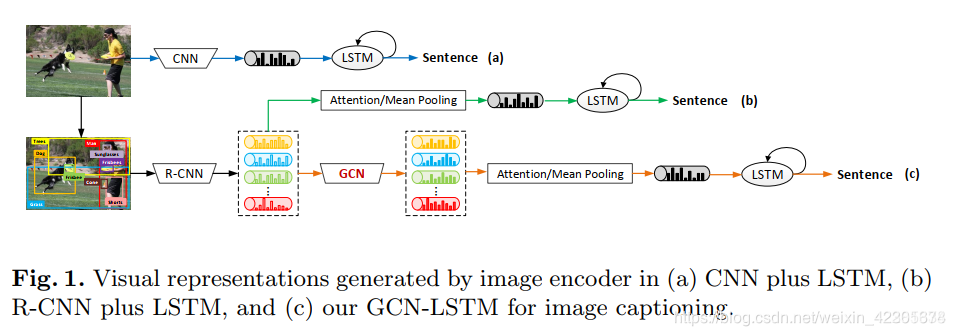 如图(A)和(B)是典型的图片描述的卷积神经网络模型,一个尚未充分研究的共同问题是如何利用视觉关系进行图片描述,因为对象之间的相互关联或相互作用是描述图像的自然基础。
如图(A)和(B)是典型的图片描述的卷积神经网络模型,一个尚未充分研究的共同问题是如何利用视觉关系进行图片描述,因为对象之间的相互关联或相互作用是描述图像的自然基础。
所以就有了图(c)我们的GCN+LSTM模型进行图片描述。
什么是视觉关系
视觉关系描述了图像中检测到的对象之间的交互或相对位置。视觉关系的检测不仅涉及到对象的定位和识别,还涉及对每对对象之间的交互(谓词)进行分类。这种关系可以表示为主语-谓词-目标,例如(man-eating-sandwich)or(dog-inside-car)
这篇论文提出了一种新的模型,是GCN+LSTM的结构,整合了语义信息和空间位置信息到图像编码器
论文的重点在于语义关系和位置关系的提取
模型的整体结构
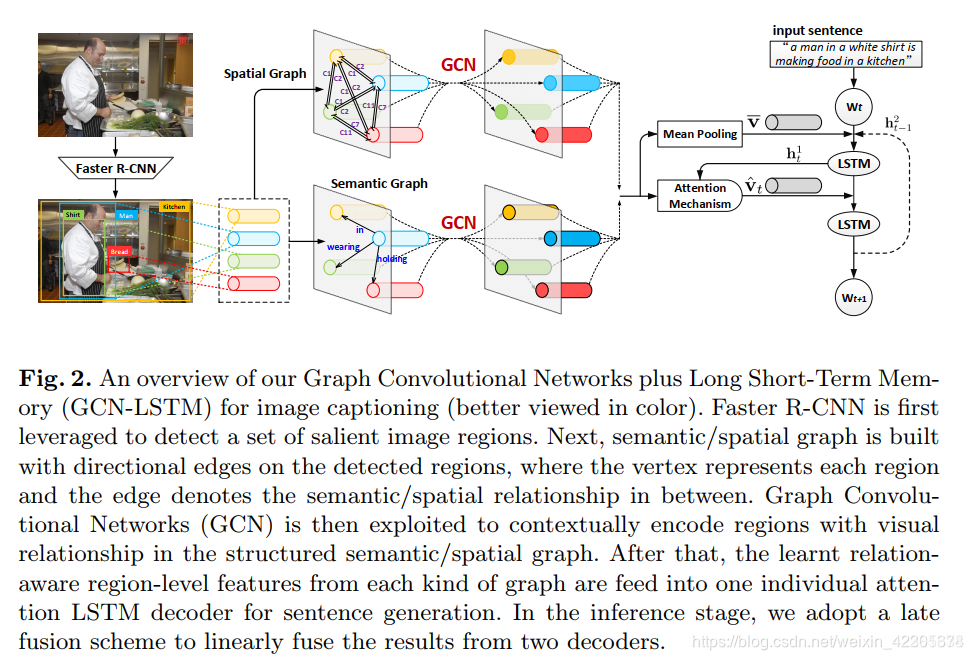 首先是用Faster R-CNN来提取一系列图像中突出的图像区域。然后利用提取出来的图像区域进行构建空间图和语义图。顶点表示区域,边表示区域之间的语义关系或是空间关系。然后用GCN 在结构化的语义和空间图上的视觉关系进行上下文编码。然后得到这些学习后区域级别的关系感知的特征,然后分别送入一个独立的attention LSTM解码器用于句子生成。在推理阶段,是采用后期融合方案来线性融合两个解码器的结果。
首先是用Faster R-CNN来提取一系列图像中突出的图像区域。然后利用提取出来的图像区域进行构建空间图和语义图。顶点表示区域,边表示区域之间的语义关系或是空间关系。然后用GCN 在结构化的语义和空间图上的视觉关系进行上下文编码。然后得到这些学习后区域级别的关系感知的特征,然后分别送入一个独立的attention LSTM解码器用于句子生成。在推理阶段,是采用后期融合方案来线性融合两个解码器的结果。
Semantic Object Relationship
语义关系可以用 subject-predicate-object 表示
语义关系是有方向性的,通过谓词将主体和客体相关联,谓词可是对象间的交互或动作
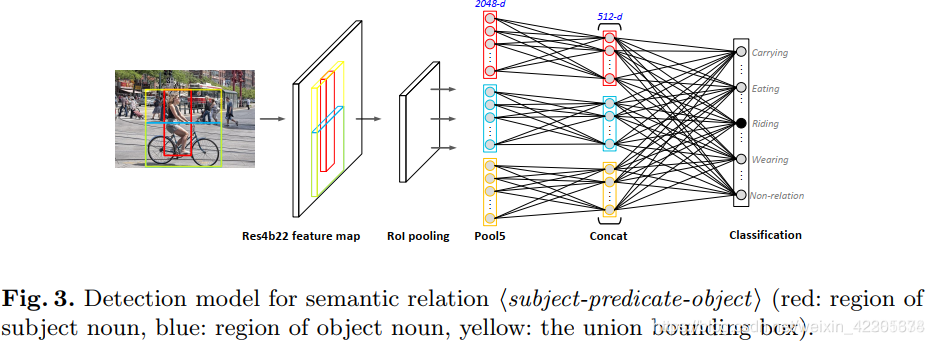 其实这个就是视觉关系分类器
其实这个就是视觉关系分类器
红框(vi)表示主体人 ,蓝框(vj)表示客体车,黄框表示二者的联合边界框他们被检测出来之后,分别各自做卷积操作,相当与区域内部做特征提取,然后经过ROI pooling 化为同一尺寸,从pool5层提取特征,将这三个得到的特征向量拼接起来,再经过非线性映射,最后通过softmax做分类,预测N+1个概率值。(N:N种语义关系 1:没有语义关系) 这个全过程是在另外一个数据集VG上训练得到的。
这边用ROI pooling 是将输入化为同一尺寸是为了后面的GCN。
在训练这个分类器之后,可以使用它来构建语义图
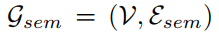
v表示顶点区域, Esem表示顶点区域间的边的集合
假设图片检测出有K个显著区域,分组成K *(K -1)个对象对,用上面的视觉关系分类器计算每个对象对在N+1个语义类别上的概率分布,如果没有语义关系的那一项的概率值<0.5,就建立从主体区域顶点到客体区域顶点的有向边,选择剩下N个概率中最大的那个最为边语义关系。
Spatial Object Relationship
语义图只展现了物体之间固有的动作/相互作用,而没有利用图像区域之间的空间关系。 因此,我们构造另一个图,即空间图,以充分探索一个图像内每两个区域之间的相对空间关系。
 通常将空间关系表示为objecti-objectj,它表示对象j相对于对象i的几何位置。
通常将空间关系表示为objecti-objectj,它表示对象j相对于对象i的几何位置。
红色区域用vi表示,蓝色区域用vj表示 这二个区域的位置可以表示为(xi,yi)和(xj,yj)
空间图
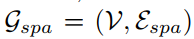
v表示顶点区域, Espa表示顶点区域间的边的集合
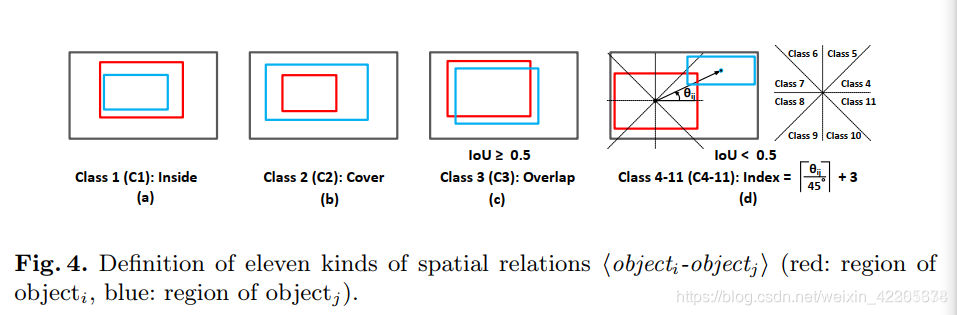
空间图中每两个对象顶点的边和相应的类标签由它们的IOU、相对距离和角度决定,共有11类位置关系和一类无关系(空间关系的详细定义如图4所示)
首先是两种特殊关系,一种是inside:vi包含vj, 另一种是cover:vi完全由vj覆盖,
除了这二种特殊关系外:
如果IOU>0.5,我们将vi和vj二者相连,变得标签标为overlap
如果IOU<0.5,比率<0.5,依据相对角度进行边的分类,并将类索引设置为
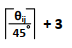
当比率>0.5 和IoU <0.5时,则二者不建立边
相对距离可以表示为
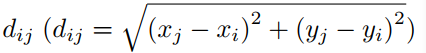
用视觉关系来进行图像描述
接下来,我们讨论了如何通过我们设计的GCN-LSTM将学习到的视觉关系集成到序列学习中,并使用基于区域的注意力机制进行图像描述。
GCN-based Image Encoder
通过捕获语义/空间图上的语义/空间关系来丰富区域级特征
传统的GCN主要是在无向图上操作,对每一个节点vi的所有邻域进行信息编码
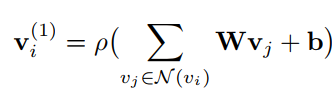
它没有包含方向性或边缘标签的信息用于编码图像区域
所以对GCN进行更新
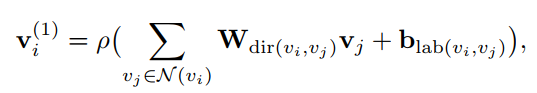
针对不同的方向和标签采用不同的转换矩阵目的就是为了让GCN对方向性和标签敏感
但不是从所有连接的顶点均匀的积累信息,所以在GCN中加了一个门控单元对不同对象之间的关系强弱进行度量,自动的聚焦于那些可能比较重要的边
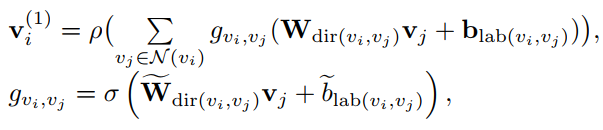
ρ :表示激活函数relu
b :表示偏置
W :表示变换矩阵
N(vi):表vi的邻居集合,也包含自身vi
dir(vi,vj): 根据边的方向给出不同的W (w1表示vi到vj,w2表示vj到vi,w3表示vi到vi)
lab(vi,vj): 表示每条边的标签
gvi,vj: 表门控单元的尺度因子
σ : logistic sigmoid函数
最终根据上述的公式对所有的区域特征(节点)进行转换,得到区域级关系感知特征赋予了对象间固有的视觉关系
Attention LSTM sentence decoder
LSTM的一种变体attention LSTM ,增加了一个和输入同尺度的注意力权重at
将上面经过GCN更新的特征注入具有注意力机制的双层LSTM
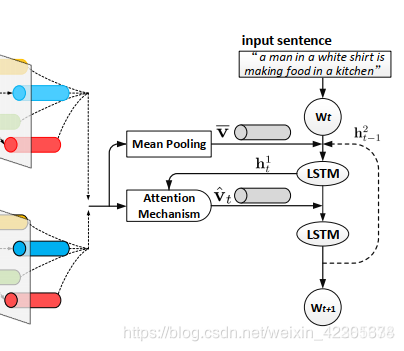
首先解码器通过连接输入单词wt和第二层LSTM单元的上一个输出h2t−1以及平均池化的图像特征
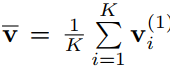
这三者来收集最大上下文信息,然后将其作为第一层LSTM单元的输入
因此,第一层LSTM单元的输出为:
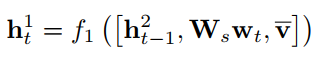
然后在输出h1t的基础上,所有关系感知的区域级特征生成规范化注意分布:
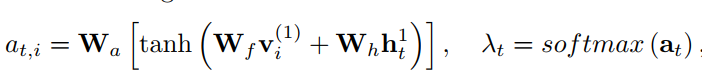
将所有区域级特征与注意力加权,计算出所关注的图像特征
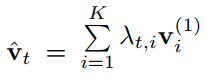
at :注意力权重
λt :注意分布, λt,i表示第i个结点 (也可以说是区域)的注意概率
最后将图像特征vˆt与第一层LSTM的输出h1t连接起来,并将它们输入到第二层LSTM单元中,输出:
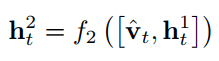
然后通过softmax预测出下一个单词wt+1 循环往复,最终得到预测的句子
Ws∈RD1s*Ds是输入单词的传输矩阵
f1是第一层lstm单元的更新函数
Wa∈R1*Da,Wf∈RDa*Dv,Wh∈RDa*Dv是传输矩阵
f2是第二层LSTM单元的更新函数
注意我们生成的语义图和空间图是分别送入一个单独的attention LSTM中进行训练,然后采用后期融合的方法把二个输出的预测值进行融合
(不知道你们在看这个模型整体框架时有没有对 二个图经过GCN输出后是怎么结合进入attention LSTM 这部分产生疑惑,反正我当时是有点晕的,可以看看下面训练和推理这部分或许对同样有疑惑的你有帮助)
训练和推理
训练阶段,将之前建立的空间图和语义图分别用于训练一个单独的GCN编码器和一个attentionLSTM的解码器。
LSTM解码器可以通过常用的交叉熵损失函数或预期的句子级奖励损失函数来优化
在GCN-LSTM中融合语义和空间图通常有两个方向:
一种是将注意模块之前的图数据中的每一对区域特征和注意模块之后的图数据中的注意特征连接起来,进行早期的融合方案。
另一种是我们采用的后期融合方案下图的(c),对两个解码器的预测词分布进行线性融合
融合方案:
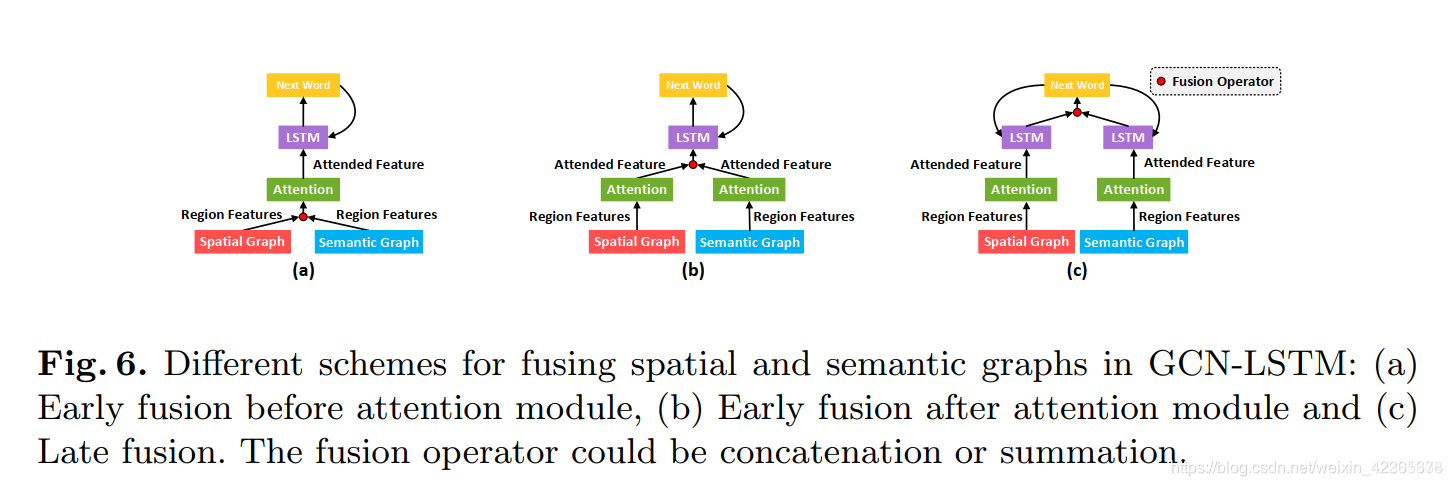 在推理时,我们采用后期融合方案来连接我们设计的GCN-LSTM架构中的两个视觉图。具体而言,我们在每个时间步骤线性融合来自两个解码器的预测单词分布,取出具有最大概率的单词作为两个解码器在下一个时间步中的输入单词。每个单词wi的融合概率计算如下:
在推理时,我们采用后期融合方案来连接我们设计的GCN-LSTM架构中的两个视觉图。具体而言,我们在每个时间步骤线性融合来自两个解码器的预测单词分布,取出具有最大概率的单词作为两个解码器在下一个时间步中的输入单词。每个单词wi的融合概率计算如下:
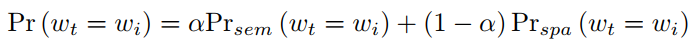
α是一个权衡参数,设为0.7 通过相关实验测得再0.7时性能最好
Prsem(wt=wi)和Prspa(wt=wi)分别表示用语义图和空间图训练解码器对每个词wi 的预测概率
问题制定
这部分其实是在论文的3.1节讲述的,我把它拿到了最后进行讲述
假设我们有一个由文本句子S描述的图像I,其中S = {w1, w2, …, wNs } 由Ns 字组成。设wt∈ RDs表示句子S中第t个单词
用faster-rcnn对图像提取特征区域,构建语义图和空间图
对于句子生成问题,通过最小化以下损失函数来制定
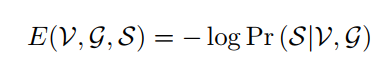
它是给定检测到的对象V的图像区域和构造的关系图g(这里的g表示语义图gsem或空间图gspa)的正确文本语句的负对数概率。
这里负对数概率通常用交叉熵损失来测量,这不可避免地导致训练和推理之间的评估差异。因此,为了通过修正这种差异来进一步推进我们的描述模型,我们可以直接使用预期的句子级奖励损失来优化LSTM。
这里说的不可避免地导致训练和推理之间的评估差异是指:
1、暴露偏差:我们的图像描述模型在训练时输入的都是来自真实的caption利用反向传播来最大程度增加下一个真实值的可能性;在测试时,生成的单词都是基于之前生成的单词,一旦有一个单词生成的不好,后面可能会跑偏
2、序列模型通常用交叉熵损失函数进行训练,在测试时用的是metric如BLUE、METEOR、CIDER度量评估
实验结果