
01
背景
02
Venus日志平台介绍
Venus是由爱奇艺自研的日志服务平台,提供日志的采集、处理、存储、分析等功能,主要用于公司内部的日志排障、大数据分析、监控报警等场景,整体架构如图1所示。
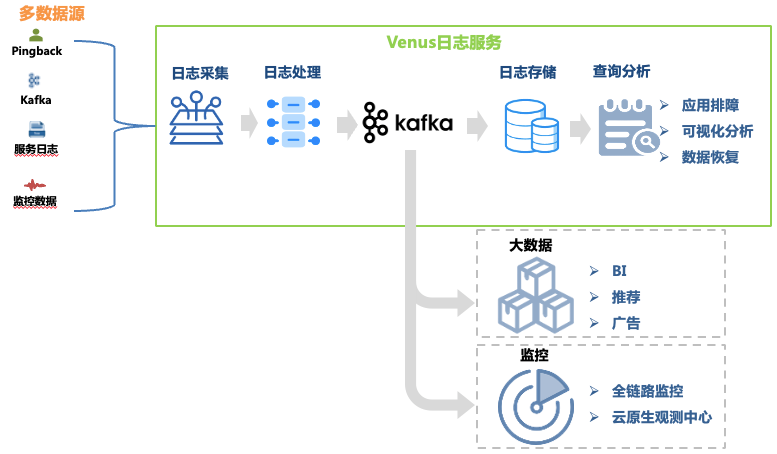 图1 Venus链路
图1 Venus链路
本文重点讨论日志排障链路的架构演变,其数据环节包括:
日志采集:通过在机器、容器宿主机上部署采集Agent,收集各业务线前端、后端、监控等多种来源的日志,也支持业务自行投递符合格式要求的日志。部署了超过3万个 Agent,支持Kafka、MySQL、K8s、网关等10种数据源。
日志处理:日志收集后经过正则抽取、内置解析器抽取等标准化处理后以JSON格式统一写入Kafka,再由转存程序写入到存储系统中。
日志存储:Venus存储了近万个业务日志流,写入峰值超过1千万QPS,日新增日志超过500TB。随着存储规模的变化,存储系统的选型经历了从ElasticSearch到数据湖的多次变化。
查询分析:Venus提供可视化查询分析、上下文查询、日志大盘、模式识别、日志下载等功能。
为了满足海量日志数据的存储与快速分析,Venus日志平台经历了三次大的架构升级,从经典的ELK架构逐步演变到基于数据湖的自研体系,本文将介绍Venus架构转型过程中遇到的问题及解决方案。
03
Venus 1.0:基于ELK架构
Venus 1.0 始于2015年,基于当时流行的ElasticSearch+Kibana搭建,如图2所示。ElasticSearch承担日志的存储与分析功能,Kibana提供可视化查询分析能力,只需要消费Kafka将日志写入ElasticSearch即可提供日志服务。
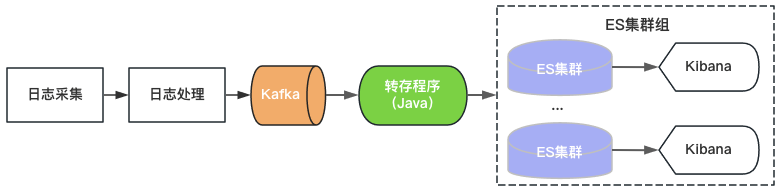 图2 Venus 1.0架构
图2 Venus 1.0架构
由于单ElasticSearch集群吞吐、存储容量、索引分片数存在上限,Venus通过不断增加新的ElasticSearch集群应对不断增长的日志需求。为了控制成本,每个ElasticSearch的负载都在高位,索引配置的都是0副本,经常遇到突增流量写入、大数据量的查询、或者机器故障导致集群不可用等问题。同时由于集群上索引多、数据量大,恢复时间也很长导致日志长时间不可用,Venus的使用体验变得越来越糟糕。
04
Venus 2.0:基于ElasticSearch + Hive
集群分级:将ElasticSearch集群分为高优和低优两类。重点业务使用高优集群,集群的负载控制在低位,索引开启1副本配置,容忍单节点故障;非重点业务使用低优集群,负载控制在高位,索引依然采用0副本配置。
存储分级:对于保存时间长的日志双写ElasticSearch和Hive。ElasticSearch保存最近7天的日志,Hive保存更长时间的日志,降低ElasticSearch的存储压力,也可降低大数据量查询将ElasticSearch打挂的风险。但是由于Hive无法做交互式查询,需要通过离线计算平台查询Hive中的日志,查询体验较差。
统一查询入口:提供类似Kibana的统一可视化查询分析入口,屏蔽底层ElasticSearch集群。在集群故障时将新写入日志调度到其他集群,不影响新日志的查询分析。在集群负载不均衡时,在集群之间透明调度流量。
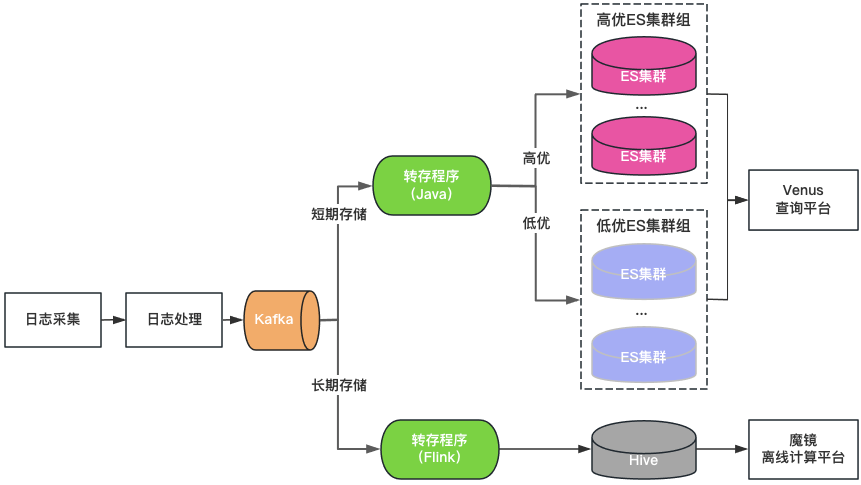
图3 Venus 2.0架构
Venus 2.0是一种保障重点业务、降低故障风险与影响的妥协方案,依然有成本高、稳定性差的问题:
ElasticSearch 存储时间短:由于日志量大,ElasticSearch只能存储 7 天,无法满足日常业务需求
入口很多,数据割裂:20 多个 ElasticSearch集群 + 1 个 Hive 集群,查询入口很多,非常不便于查询和管理
成本高:ElasticSearch虽然只存7天日志,依旧消耗了 500多台机器
读写一体:ElasticSearch服务器同时负责读写,相互影响
故障多:ElasticSearch故障占 Venus总故障 80%,故障后读写阻塞,容易丢日志,且处理困难
05
Venus 3.0:基于数据湖的新架构
引入数据湖的思考
深入分析Venus的日志场景,我们总结其有如下特点:
数据量大:近万个业务日志流峰值千万QPS的写入,PB级的数据存储。
写多查少:通常业务在有排障需求时才去查询日志,大部分日志一天内都没有查询需求,整体看查询QPS也极低。
交互式查询:日志主要用于排障这种紧急、需要多次连续查询的场景,需要秒级的交互式查询体验。
针对使用ElasticSearch存储分析日志遇到的问题,我们认为其与Venus的日志场景并不十分匹配,原因如下:
单集群写入QPS和存储规模有限,需要多集群分担流量。需考虑集群规模、写入流量、存储空间、索引数量等复杂调度策略问题,增加了管理难度。由于业务日志流量差异大、不可预测,为解决突发流量对集群稳定性的影响,往往需预留较多空闲资源,导致集群资源极大浪费。
写入时做全文索引消耗了大量CPU,导致数据膨胀,造成计算存储成本大幅上升。在很多场景下存储分析日志所需的资源比后台服务资源还多。对于日志这种写入多、查询少的场景,做全文索引的预计算比较奢侈。
存储数据与计算在相同的机器上,大数据量查询或者聚合分析容易影响写入,造成写入延迟甚至集群故障。
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
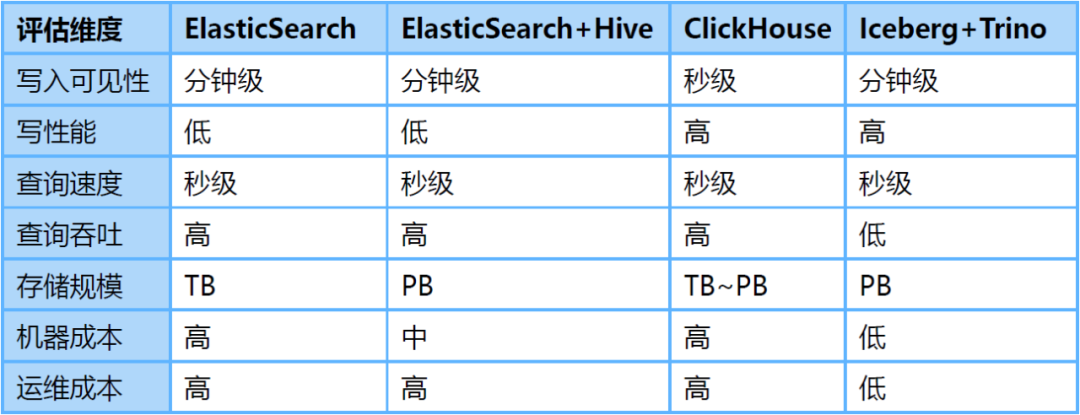
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
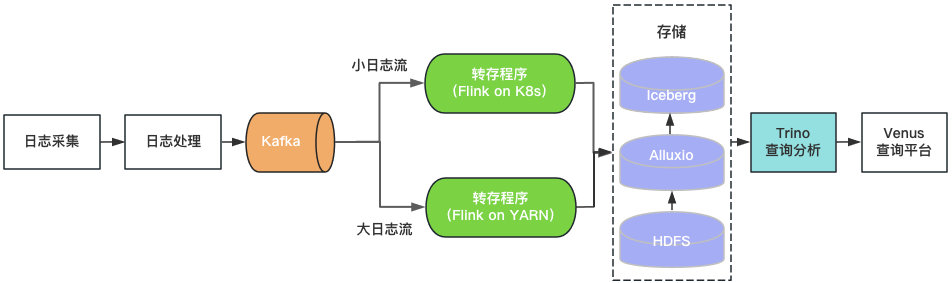 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
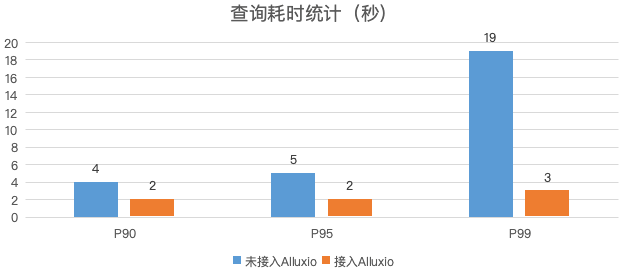
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。