一、相关技术及框架
1.1 虚拟机
本项目所用到的所有技术框架及项目包都已部署到虚拟机中(模拟为服务器)。
所用虚拟机软件为VMware Workstation 15.5 Pro,若没有此虚拟机软件,请联系我下载。
1.1.1 内部配置
| IP地址 |
192.168.126.66 |
| 主机名 |
cloud01 |
| 内存容量 |
5G |
| 硬盘容量 |
40G |
| 用户1及密码
扫描二维码关注公众号,回复:
17424472 查看本文章

|
用户名:root 密码:000000 |
| 用户2及密码 |
用户名:es-admin 密码:1q1w1e1r (仅用于开关ElasticSearch) |
| 所有的技术框架位置 |
/opt/module/ |
| 项目部署位置 |
/opt/module/movie_recommendation_system/ |
1.2 相关技术配置
1.2.1 MySQL
| 账号 |
密码 |
端口 |
数据库 |
| root |
000000 |
3306 |
movie_recommendation |
1.2.2 Redis
| Host |
Port |
密码 |
| 192.168.126.66 |
6379 |
000000 |
1.2.3 MongoDB
| User |
密码 |
端口 |
数据库 |
| Designer |
000000 |
27017 |
recommender |
1.2.4 ElasticSearch
| Username |
密码 |
端口 |
Index |
| elastic |
000000 |
9200 |
Movie_detail |
开发工具
要完成一个完整的系统,开发中需要涉及到前端、后端及数据库,最终还要进行测试和部署,需要很多工具来完成这些工作。本系统使用的开发工具如下表所示:
表4.9 开发工具表
| 所属工作范围 |
工具名 |
版本 |
| 前端开发工具 |
WebStorm |
2020.3.2 |
| 前端查看工具 |
Chrome浏览器 |
90.0.4430.93 |
| 后端开发工具 |
IntelliJ IDEA |
2020.3.2 |
| 数据库开发工具 |
Navicat Premium |
12 |
| 接口测试工具 |
Postman |
8.5.1 |
| 并发测试工具 |
JMeter |
|
| 远程连接工具 |
FinalShell |
3.8.3 |
4.6 技术选型
本系统所涉及的所有开发技术及其选型如下所示:
表4.10 技术选型清单
| 所属范围 |
类型 |
技术名 |
版本 |
| 前端 |
开发语言 |
HTML |
5 |
| CSS |
3 |
||
| Javascript |
ES6 |
||
| 开发框架 |
Vue |
2.6.11 |
|
| 网络通信库 |
Axios |
0.21.1 |
|
| 图表库 |
ECharts |
5.0.2 |
|
| 组件库 |
vuetify |
2.4.0 |
|
| element-ui |
2.15.1 |
||
| 后端 |
开发语言 |
Java |
1.8 |
| Scala |
2.12.12 |
||
| 开发框架 |
SpringBoot |
2.4.1 |
|
| 数据库 |
MySQL |
5.7.32 |
|
| MongoDB |
4.0.22 |
||
| 缓存 |
Redis |
6.0.9 |
|
| 搜索引擎 |
ElasticSearch |
7.9.3 |
|
| 持久层框架 |
Mybatis |
2.1.4 |
|
| 安全框架 |
Shiro |
1.7.0 |
|
| 计算框架 |
Spark |
3.0.0 |
|
| 消息队列 |
Kafka |
2.6.0 |
|
| 短信服务 |
aliyun-core |
4.5.9 |
|
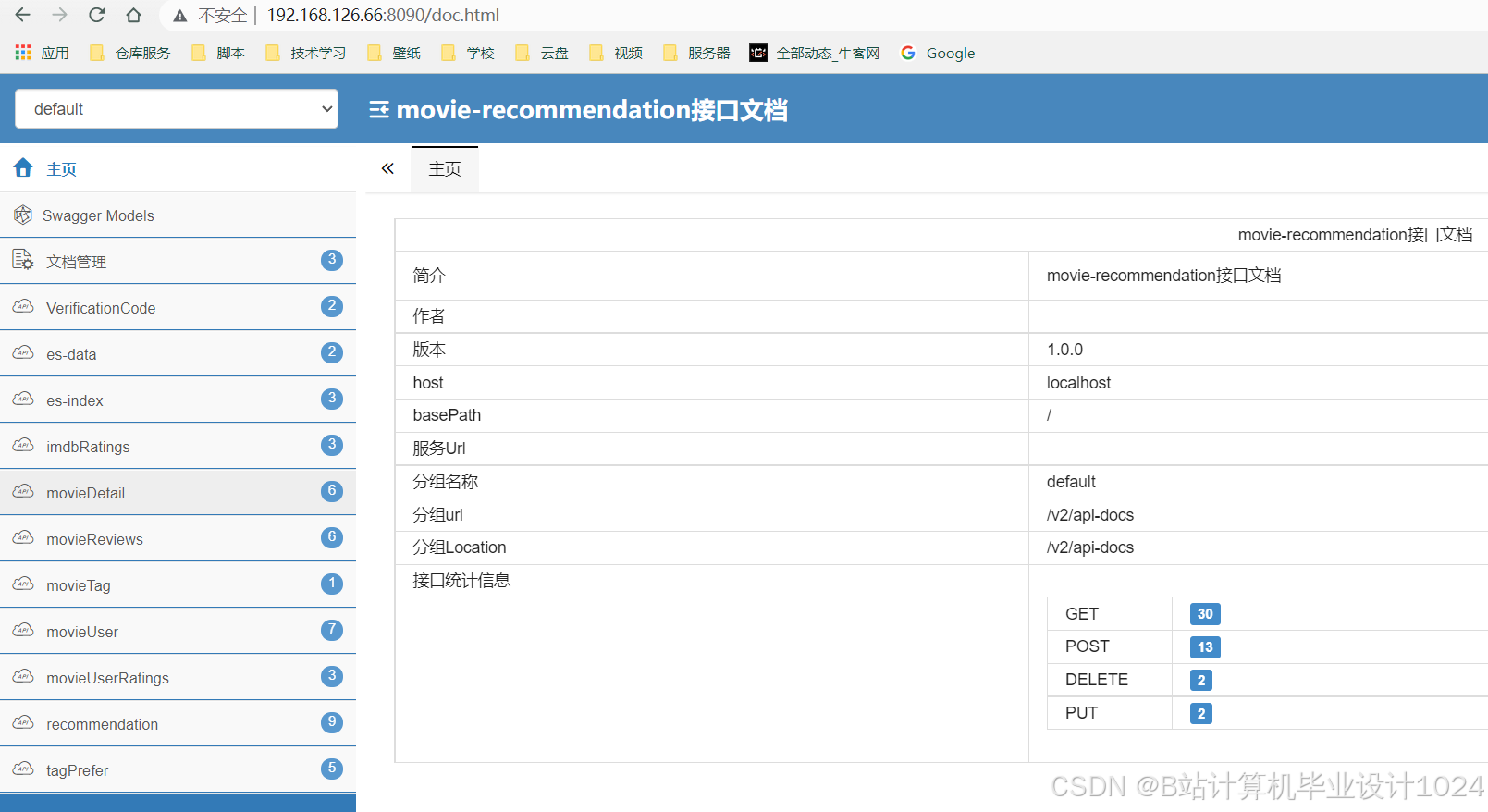
| 接口文档 |
Swagger |
2.9.2 |
|
| 日志 |
Logback |
1.2.3 |
|
| 静态资源访问 |
Nginx |
1.18.0 |
6 总结与展望
6.1 总结
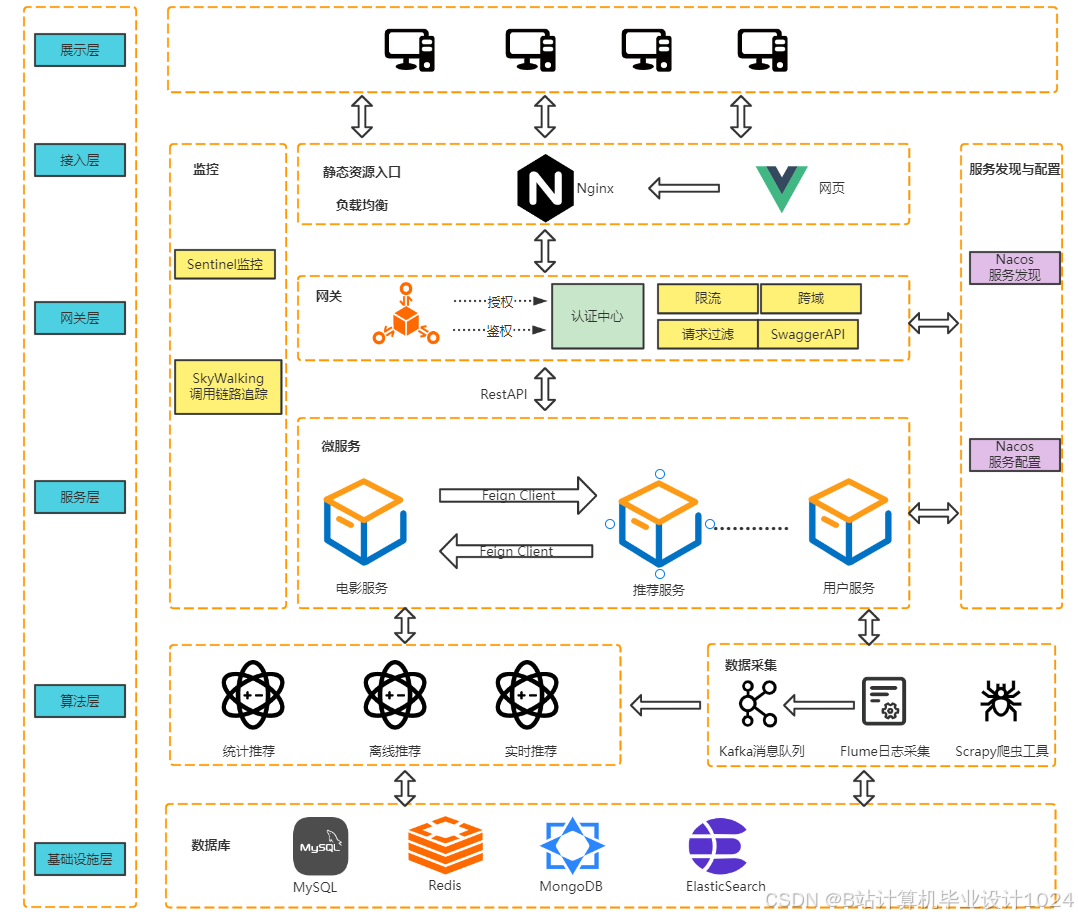
本文从实际生活的应用出发,综合运用各类技术,设计并实现了基于Spark的电影推荐系统。在本次课题研究中,所做的工作总结有以下几点:
- 学习了许多推荐算法的原理;
- 学习了许多之前的未接触过的技术,如Spark计算框架、ElasticSearch搜索引擎、MongoDB数据库和Vue前端框架等;
- 详细分析了本系统的功能性需求和非功能性需求;
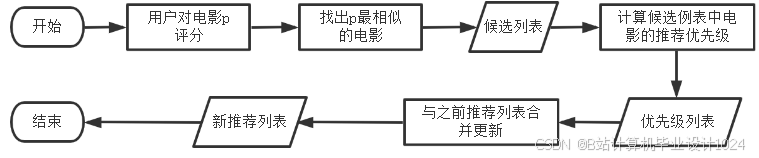
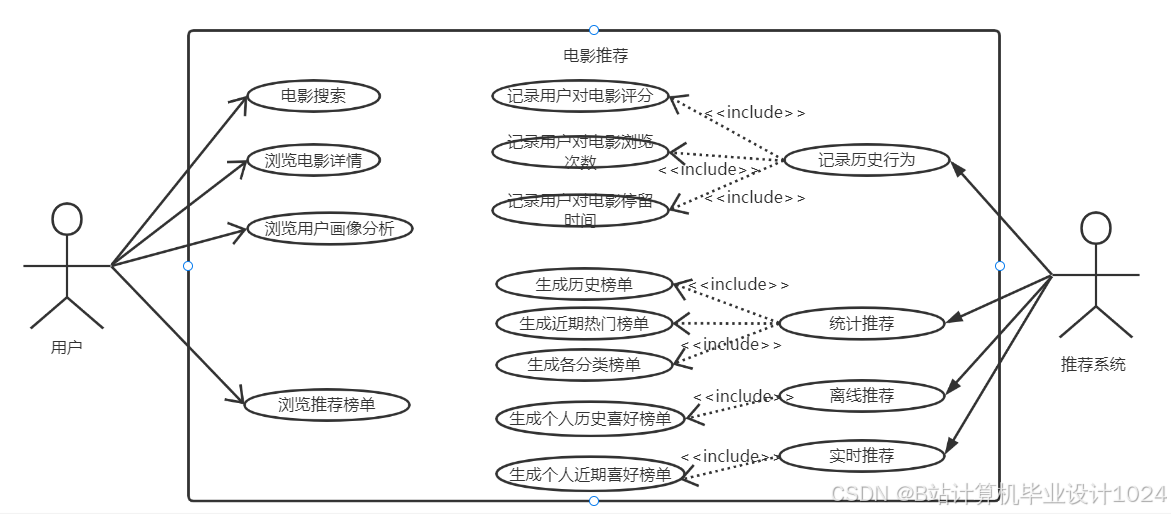
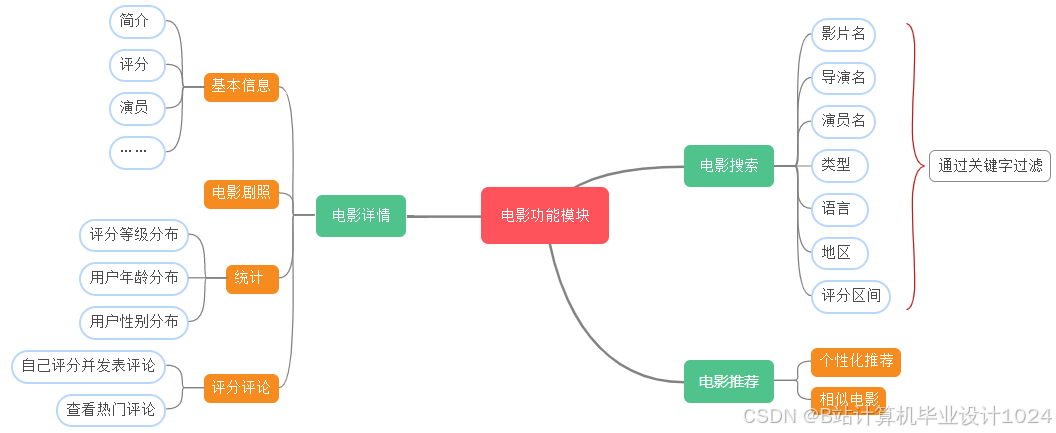
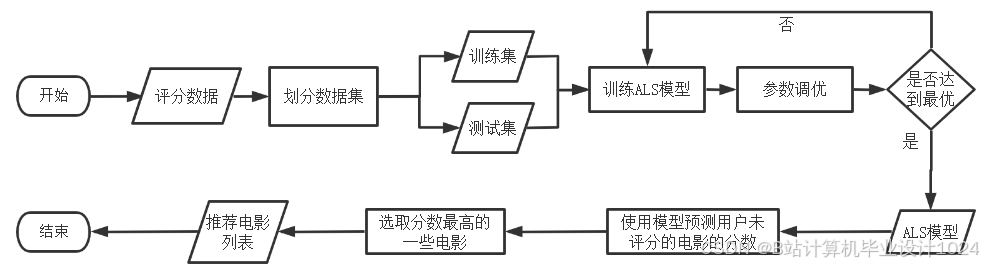
- 详细设计了本系统的架构与各个功能模块,详细设计了系统所需的几种推荐算法,如统计推荐、离线推荐和实时推荐算法,详细设计了数据库并给出了优化策略;
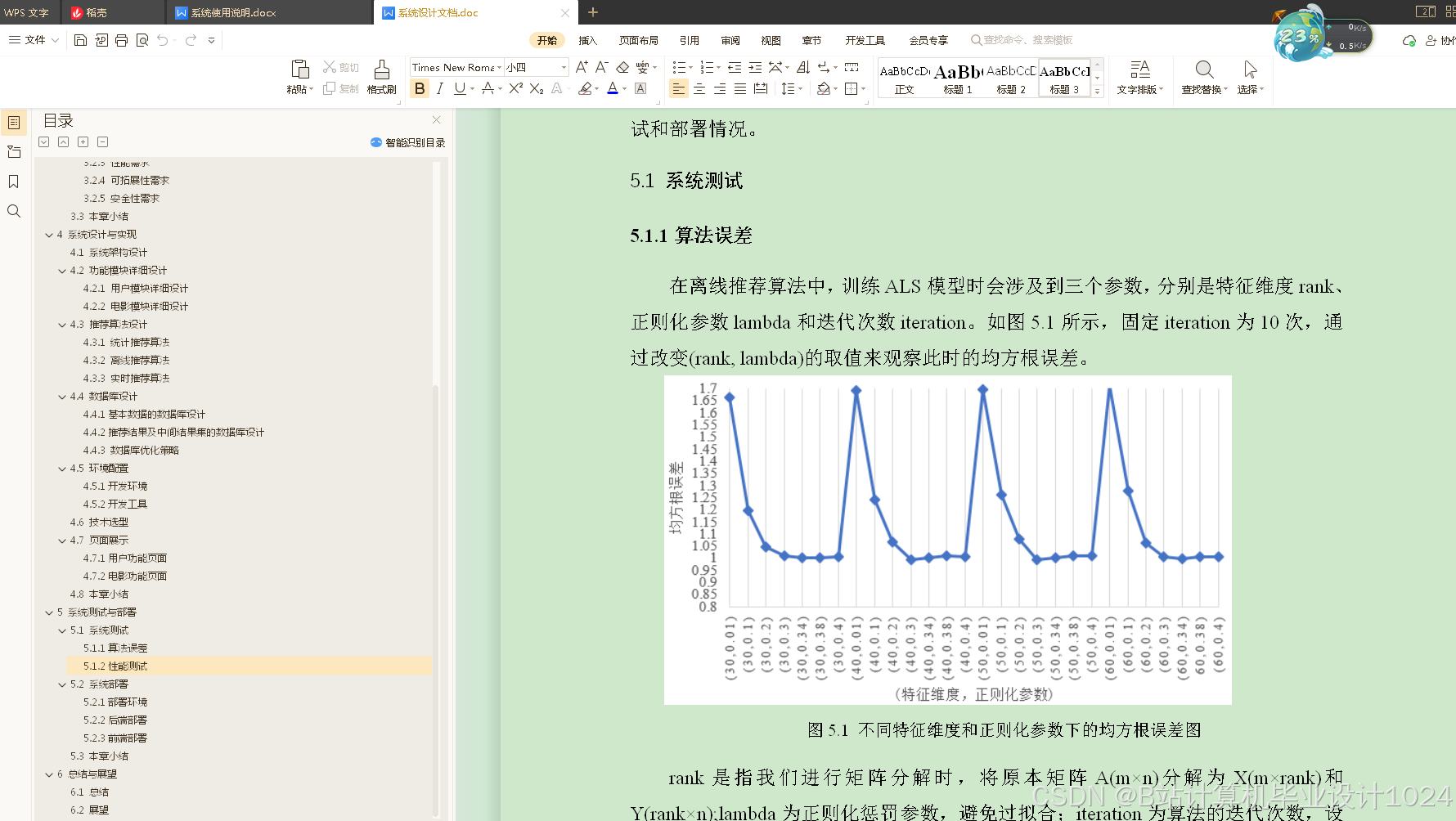
- 测试了推荐算法的误差,以及对系统进行了高并发的性能测试。
6.2 展望
虽然本文最终实现了基于Spark的电影推荐系统,但是仍还有进一步完善、优化和提升的空间。笔者提出以下两点优化意见:
- 搭建Spark集群
目前本系统还是单机模式,但是面对日益庞大的数据量,单机的计算能力就有点捉襟见肘了。当搭建了Spark集群,每台机器的计算和内存压力会减轻不少,大大提高了计算效率。
- 探索其它推荐算法
由于本系统中用户评分矩阵十分稀疏,会对推荐算法的准确性有一定的影响。在以后的学习中,还可以探索其他推荐算法,使本系统具有更高的准确性。