
ARIMA模型(自回归积分滑动平均模型)是时间序列分析中的一种广泛应用的模型,这个模型在各个领域发挥着巨大的作用,如股票市场的价格预测、经济中GDP增长率预测、供应链中销售量和库存需求预测、气象中气温和降水量的预测等等。为了深入理解ARIMA模型,我们需要先深入理解构成它的三个基本构建模块:
-
AR(自回归)部分:使用时间序列自身的过去值来预测当前值。
-
I(积分)部分:通过对数据进行差分处理,使非平稳时间序列变为平稳序列。
-
MA(移动平均)部分:使用过去的预测误差来修正预测。
前面已经详细介绍 AR 模型和 MA 模型,如果还没阅读过这两篇文章的同学,强烈建议先提前阅读它们,因为那是学好本篇文章的基础。
本文的目标将是进入到时间序列模型系列的终极目标,上手深度学习掌握 ARIMA 模型。本人将从 ARIMA 模型基本概念、差分过程、ARIMA 模型应用 三个章节来详细讲述 ARIMA 模型。希望你通过阅读此文,能够获得对 ARIMA 模型的深入理解,并能够在实际问题中正确使用这些模型。
1、ARIMA 模型基本概念
ARIMA 模型全称为自回归差分移动平均模型(Autoregressive Integrated Moving Average Model),它主要由三部分构成,分别为自回归模型(AR)、差分过程(I)和移动平均模型(MA)。
从前面两篇文章的学习,我们知道 AR 模型和 MA 模型的主要作用为:
AR 模型,即自回归模型,它的基本思想是一个给定时间点的数据值受到其过去的数据值的显著影响,其优势是对于具有较长历史趋势的数据,AR模型可以捕获这些趋势,并据此进行预测。但是AR模型不能很好地处理某些类型的时间序列数据,例如那些有临时、突发的变化或者噪声较大的数据。
MA 模型,即移动平均模型,它的基本思想是大部分时候时间序列应当是相对稳定的,在稳定的基础上,每个时间点上的标签值受过去一段时间内、不可预料的各种偶然事件影响而波动。但是对于具有较长历史趋势的数据,MA模型可能无法像AR模型那样捕捉到这些趋势。
ARIMA 模型综合 AR 模型和 MA 模型,基本思想是:一个时间点上的数据值既受过去一段时间内的数据值影响,也受过去一段时间内的偶然事件的影响,这就是说,ARIMA模型假设:数据值是围绕着时间的大趋势而波动的,其中趋势是受历史标签影响构成的,波动是受一段时间内的偶然事件影响构成的,且大趋势本身不一定是稳定的。这个融合思想也在其名称 ARIMA 中看出来,那名称中(I)又表示什么意思呢?
I 表示差分,用于使非平稳时间序列达到平稳,通过一阶或者二阶等差分处理,消除了时间序列中的趋势和季节性因素,这个我们留着独立的章节来讲解。

另外,这个公式的基础是假设我们正在处理的时间序列是平稳的,这样我们可以直接应用 AR 和 MA 模型。如果时间序列是非平稳的,那么我们就需要考虑 ARIMA 模型中的 I 部分,也就是进行差分处理。
2、差分过程
差分的基本思想是计算时间序列相邻观测值之间的差。通过差分,可以消除时间序列中的趋势和季节性,从而实现平稳化。
2.1、什么是差分

差分的阶数:前面,我们介绍了一阶差分。然而,实际上,差分的阶数可以是任何正整数。差分的阶数就是我们需要进行多少次差分操作才能得到一个平稳序列。具体地说就是:二阶差分就是对一阶差分后的序列再次进行差分,三阶差分就是对二阶差分后的序列再次进行差分。需要注意的是:差分的阶数不会很大,在平时工作中使用 ARIMA 模型时,差分的阶数一般为 0、1、2,几乎不会是更大的了。
2.2、什么是滞后

3、ARIMA 模型应用
在 ARIMA(p, d, q) 模型中存在三个参数 p、d、q ,根据前面我们所介绍的,它们分别具有以下作用:
-
p:表示 AR 自回归模型的阶数,即 AR 自回归模型考虑的过去多久的数据的线性组合;
-
d:表示差分的阶数,即这个数据使用几阶差分进行处理成平稳数据;
-
q:表示 MA 移动平均模型的阶数,即 MA 移动平均模型考虑过去多久的白噪声影响;
值得注意的是,差分滞后设置在社区提供的模型中没有提供参数配置,如果要实现滞后大于1以上的差分处理,需要对数据提前进行手动预处理。
在实际实践中,我们不需要从零开始自己编写 ARIMA 模型,在社区中有很多比较成熟的封装包了,我们可以拿来开箱即用。在 Python 中,我们可以使用 statsmodels 库中的 ARIMA 模型来使用。以下为一个简单的示例,如下所示,每行都有对应的注释说明,再结合上面的基础原理,相信大家一看就懂,所以就不再重复赘述了。
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 示例数据:月度销售数据
data = {
'Month': ['2020-01', '2020-02', '2020-03', '2020-04', '2020-05',
'2020-06', '2020-07', '2020-08', '2020-09', '2020-10',
'2020-11', '2020-12'],
'Sales': [200, 220, 250, 230, 300, 280, 310, 320, 330, 360, 400, 450]
}
# 创建 DataFrame
df = pd.DataFrame(data)
df['Month'] = pd.to_datetime(df['Month'])
df.set_index('Month', inplace=True)
# 构建和拟合 ARIMA 模型 (p=12, d=1, q=12)
model = ARIMA(df['Sales'], order=(12, 1, 12))
model_fit = model.fit()
# 进行预测
forecast = model_fit.forecast(steps=6) # 预测未来 6 个月
print('Forecasted values:', forecast)
# 绘制预测结果
plt.figure(figsize=(10, 4))
plt.plot(df['Sales'], label='原始销量', marker='o')
plt.plot(pd.date_range(start='2020-12-31', periods=6, freq='M'), forecast, label='预测', color='red', marker='o')
plt.title('ARIMA 预测')
plt.xlabel('月份')
plt.ylabel('销量')
plt.legend()
plt.grid()
plt.show()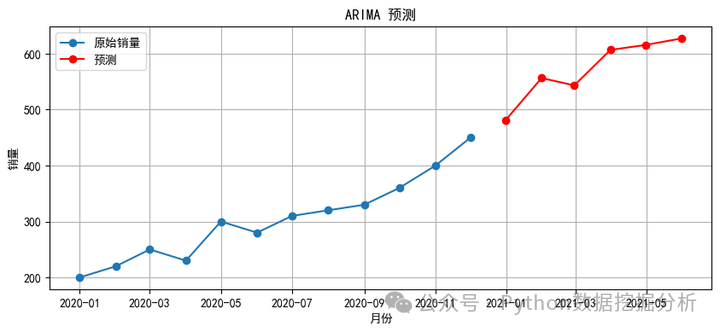
4、总结
本文从 ARIMA 模型基本概念、差分过程、ARIMA 模型应用 三个章节来详细讲述 ARIMA 模型,帮助大家从零开始学习掌握 ARIMA 模型。至此,时间序列预测模型的文章(AR、MA、ARIMA)三姊妹篇都已完成输出,希望这系列文章能对你有切实有用的帮助,也不枉费我花了国庆两天时间整理沉淀!
如果你喜欢本文,欢迎点赞,并且关注我们的微信公众号:Python技术极客,我们会持续更新分享 Python 开发编程、数据分析、数据挖掘、AI 人工智能、网络爬虫等技术文章!让大家在Python 技术领域持续精进提升,成为更好的自己!
添加作者微信(coder_0101),拉你进入行业技术交流群,进行技术交流~