1、网络爬虫
网络爬虫
自动提取网页的程序
网络爬虫运行原理
网络爬虫分类
通用网络爬虫
聚集网络爬虫
增量式网络爬虫
深层网络爬虫
新型网络爬虫
人工智能发展
可视化网络爬虫
反爬
机器人协议:哪此页面可以爬取,哪些页面不可以
因为影响网站的访问速度,严重时导致不可访问
非法网络爬虫
不遵守协议
获取敏感数据
2、网页基础知识
HTML
Hyper Text Markup Language
超文本标记语言
页面的构成
HTML + CSS + JavaScript
http
Hyper Text Trasfer Protocal
超文本传输协议
万维网协会World Wide Web Consortium
Internet工作小组IETF
服务器端
httpd
nginx
tomcat
weblogic
……
客户端
浏览器
IE不再推荐使用,微信已经不再维护
国内银行,国税/地税……
firefox
chrome
safari
opera
3、urllib模块
urllib模块
python自带的模块

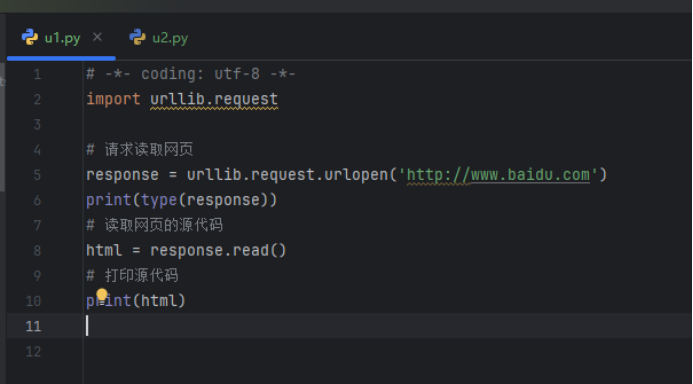
get请求示例
post请求示例
运行结果
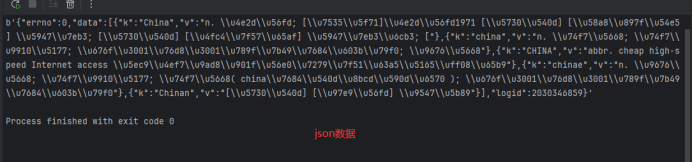
使用工具查看JSON数据
https://www.sojson.com/

4、urllib3模块
urllib3模块
功能强大
提供python标准库里没有的重要特性
线程安全
连接池
客户端SSL/TLS验证
文件上传
代理
压缩编码


GET请求示例
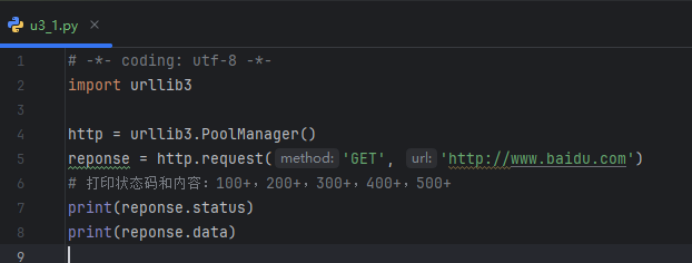
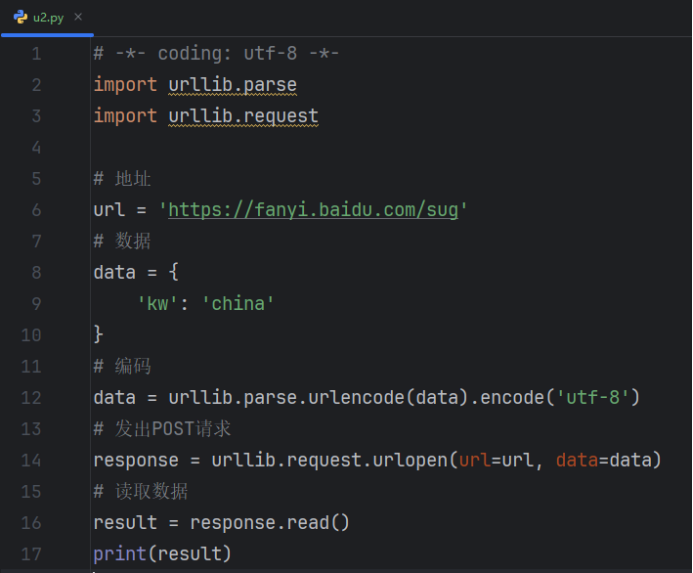
POST请求
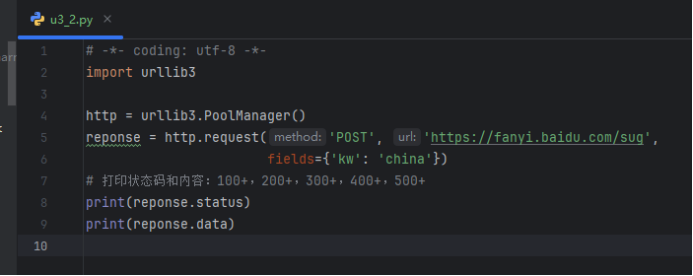
运行结果

5、requests模块
requests模块
HTTP请求库
网络请求和网络爬虫
优势:相比urllib和urlib3功能更强大,封装的功能比较多
安装模块
pip install requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=1000 requests
查看模块


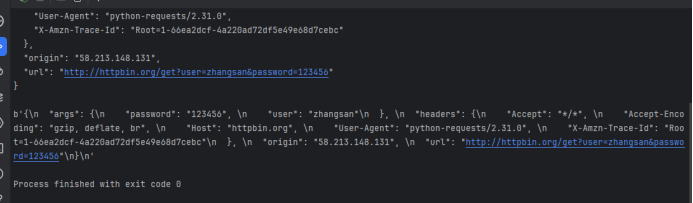
GET请求示例
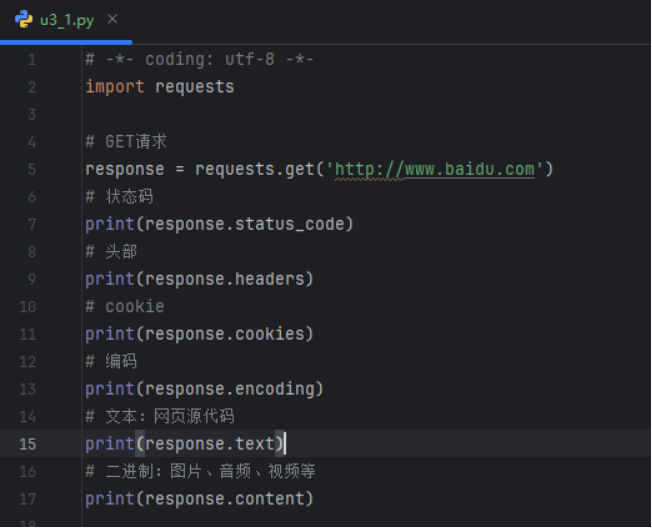
运行结果
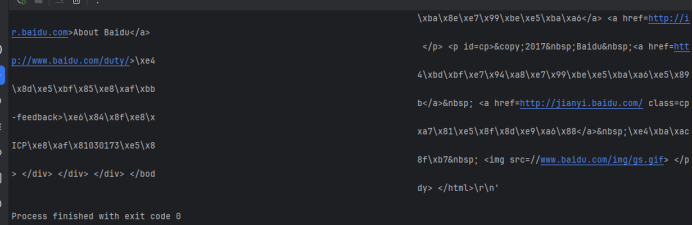
POST请求示例
运行结果(注意:关闭本地代理)

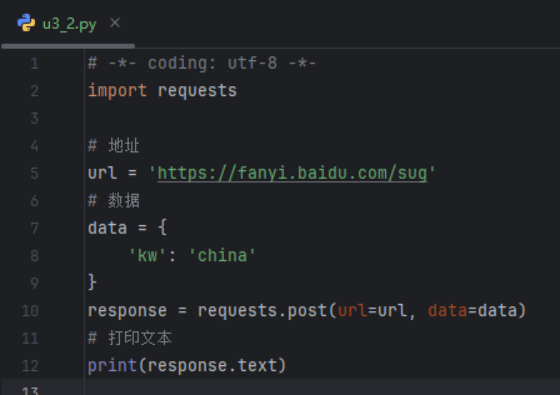
定制requests—传递参数
get/post参数
运行结果
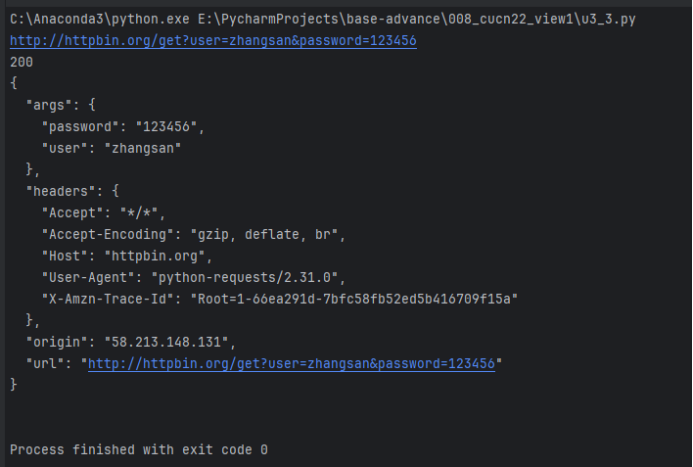
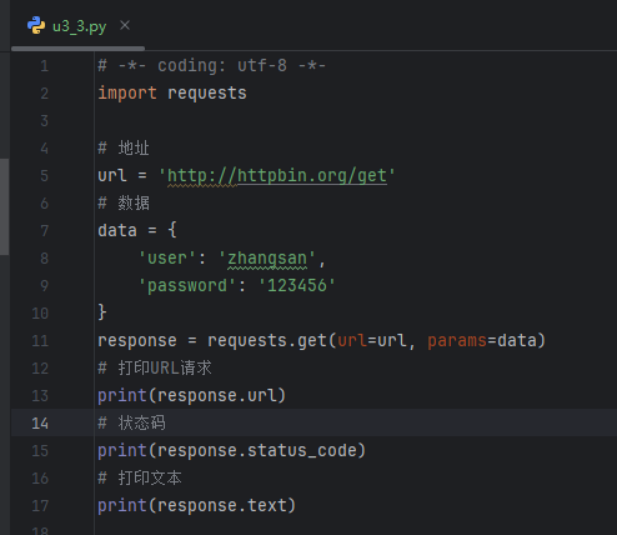
定制requests—请求头
部分网站对浏览器版本或客户端设备有一定的要求
甚至于禁止爬取数据
解决上述问题:伪装请求头
用浏览器,自己去访问,访问成功后,F12拷贝头部信息

运行结果
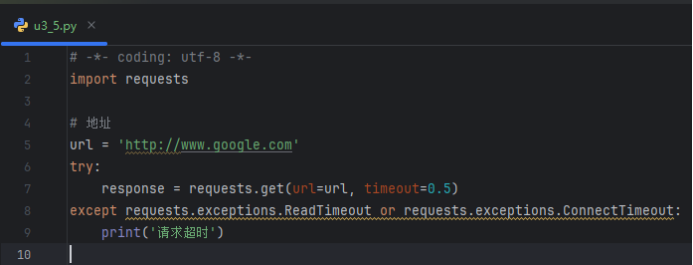
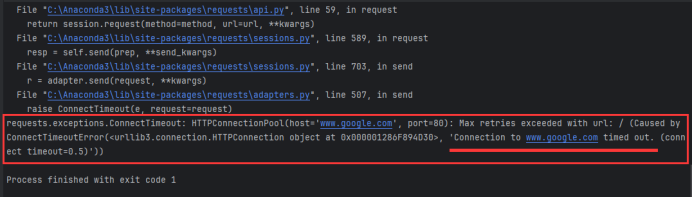
定制requests—网络超时
网络等待时间,时间比较短,可以设置更长等待时间
部分场景如网络卡顿
运行结果
6、BeautifulSoup介绍
urllib/ulrlib3/requests模块
返回文本/流
基于文本的处理,比较繁琐
BeautifulSoup
爬取网页内容
网页内容即可以是文本,也可以是对象
处理方法比较多
封装:导航、搜索、修改分析树等
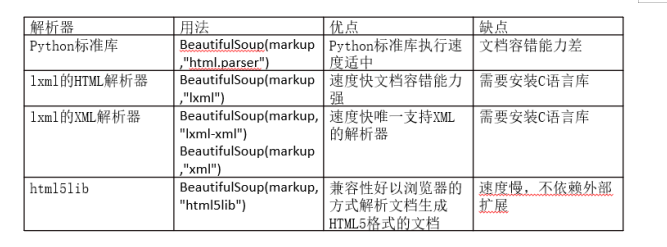
工具箱
解析页面
CSS选择器
HTML解析器
LXML:XML解析器,HTML解析器
HTML5lib解析器
安装模块
pip install beautifulsoup4==4.12.2
pip install lxml==5.0.0
查看模块



7、BeautifulSoup—简单示例
推荐使用本地页面
因为网络页面,过段时间后,无法访问
编写代码
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
# 声明页面
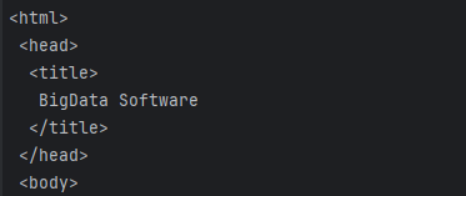
html_doc = """
<html>
<head>
<title>
BigData Software
</title>
</head>
<body>
<p class="title">
<b>
BigData Software
</b>
</p>
<p class="bigdata">
There are three famous bigdata softwares; and their names are
<a class="software" href="http://example.com/hadoop" id="link1">
Hadoop
</a>
,
<a class="software" href="http://example.com/spark" id="link2">
Spark
</a>
and
<a class="software" href="http://example.com/flink" id="link3">
Flink
</a>
;
and they are widely used in real applications.
</p>
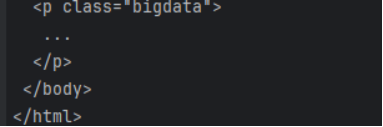
<p class="bigdata">
...
</p>
</body>
</html>
"""
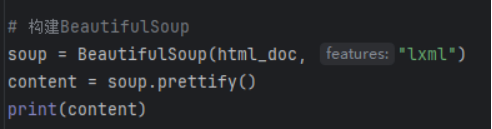
# soup = BeautifulSoup(html_doc, 'html.parser')
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.prettify())
8、BeautifulSoup—四大对象
官网链接
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
中文链接
# 定义页面
html_doc = """<html>
<head>
<title>
BigData Software
</title>
</head>
<body>
<h1>BigData Software</h1>
<p class="title">
<b>
BigData Software
</b>
</p>
<h2><!-- 注释 --></h2>
<p class="bigdata">
There are three famous bigdata softwares; and their names are
<a class="software" href="http://example.com/hadoop" id="link1">
Hadoop
</a>
,
<a class="software" href="http://example.com/spark" id="link2">
Spark
</a>
and
<a class="software" href="http://example.com/flink" id="link3">
Flink
</a>
;
and they are widely used in real applications.
</p>
<p class="bigdata">
...
</p>
</body>
</html>
"""
BeautifulSoup对象
文档的全部内容
是一个特殊的Tag对象
示例
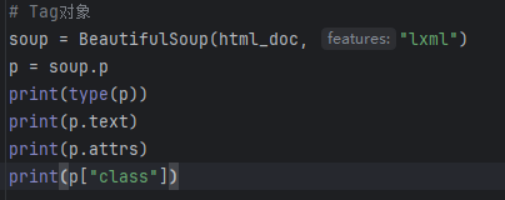
就是HTML中一个一个的标签
使用标签名称获取标签内容,也就对Tag对象
示例
Tag对象
就是HTML中一个一个的标签
使用标签名称获取标签内容,也就对Tag对象
示例
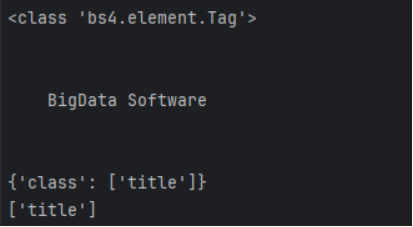
NavigableString对象
操纵字符串
Tag对象通过.string方法,返回NavigableString对象
示例


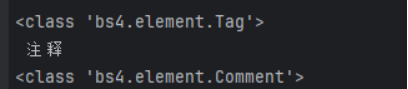
Comment对象
特殊类型的NavigableString对象
输出内容不包括注释内容
9、BeautifulSoup—遍历文档树
遍历文档树
从根节点寻找特定的标签元素
直到找到目标元素结束
直接子节点/所有子孙节点
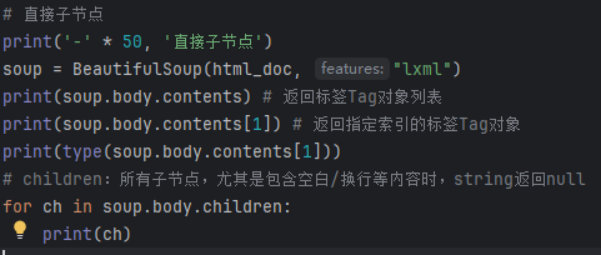

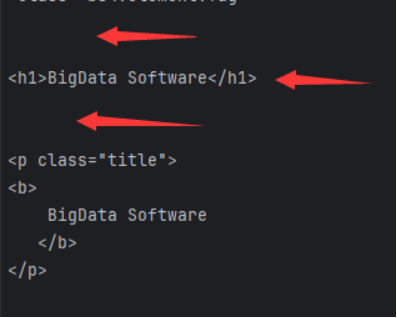
节点内容
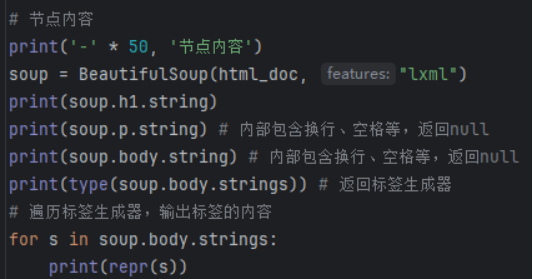

直接父节点/祖先节点
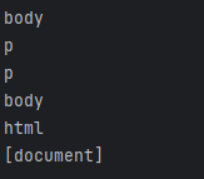
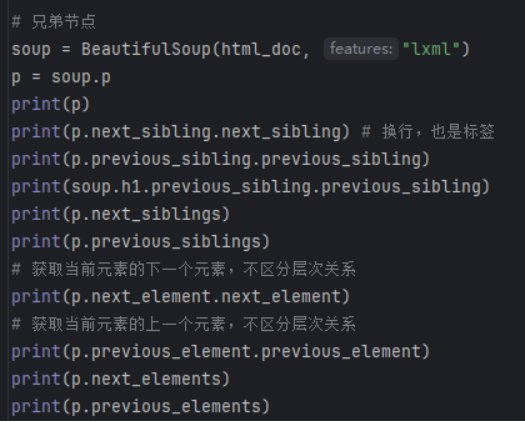
兄弟节点/全部兄弟节点/前后节点/所有前后节点
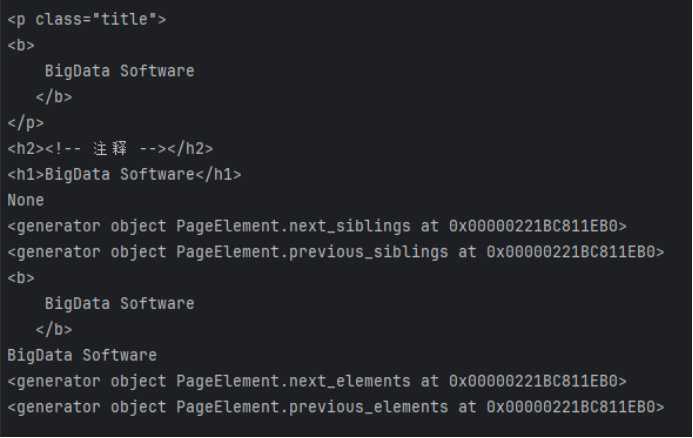
10、BeautifulSoup—搜索文档树
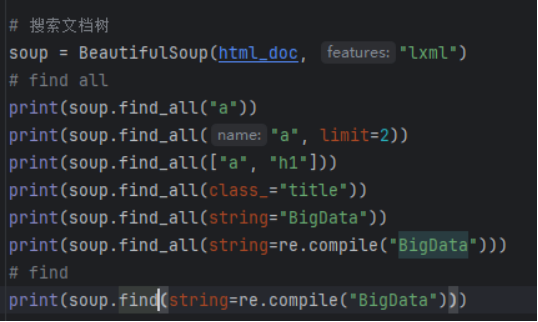
find_all()
根据标签名称搜索
find_all(‘标签名称’)
find_all(re.compile(‘标签名称’))
find_all([‘标签名称1’, ‘标签名称2’])
根据标签的属性搜索
find_all(ID=True)
find_all(id=’txtID’)
find_all(class_=’title’)
根据标签的内容搜索
find_all(text=‘标签内容文本’)
限制返回的标签数量
find_all(‘标签名称’ , limit=2)
仅搜索直接子节点,默认情况下搜索所有后代节点
find_all(‘标签名称’ , recursive=False)
find()
与上相同
仅返回第1个匹配的标签元素
示例
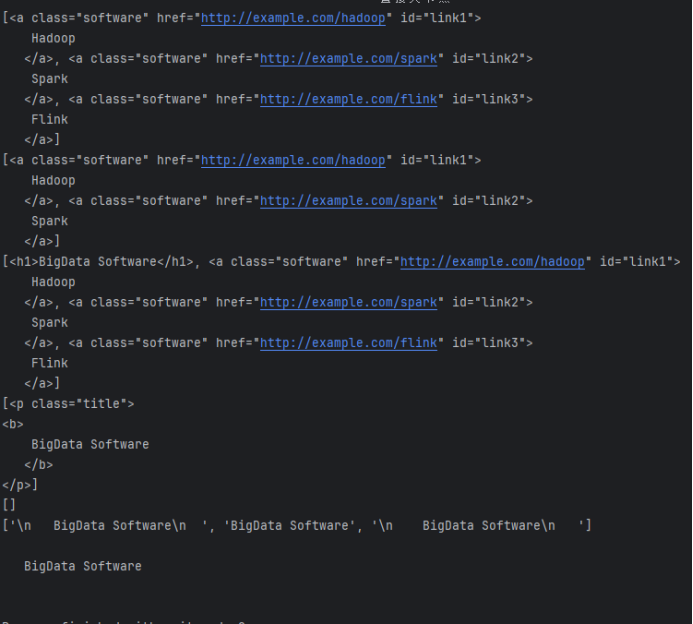
11、BeautifulSoup—CSS选择器
确定并查找标签的方法
遍历节点方法
搜索文档树
CSS选择器:内容与样式是分离的
1)打开浏览器页面,按F12
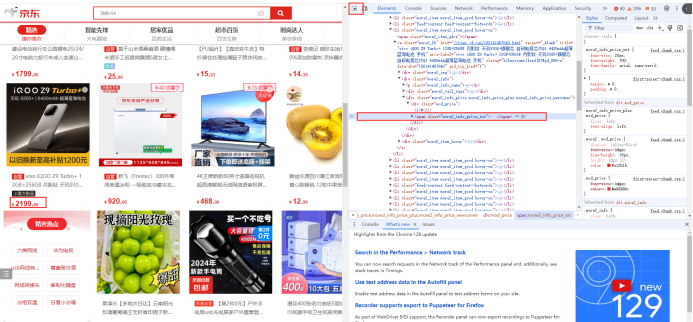
2)分析源代码
确定CSS选择器
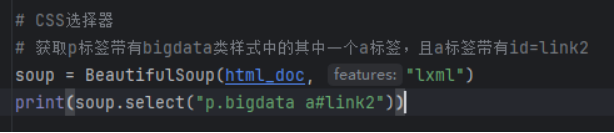
3)编写代码
获取标签内容
CSS选择器类型
标签选择器
类选择器
ID选择器
组合选择器
属性选择器
……
示例

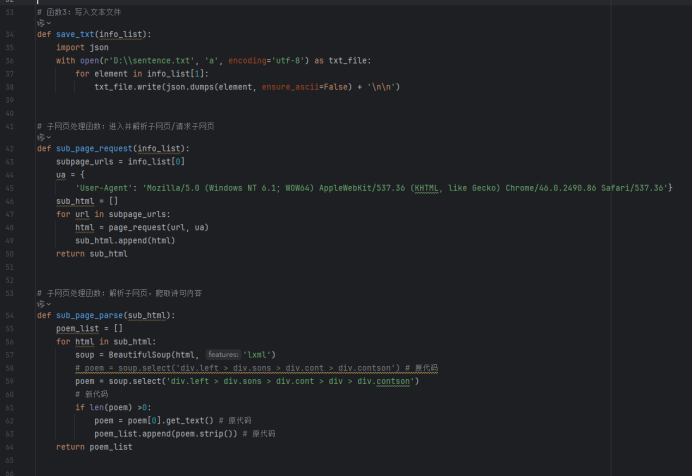
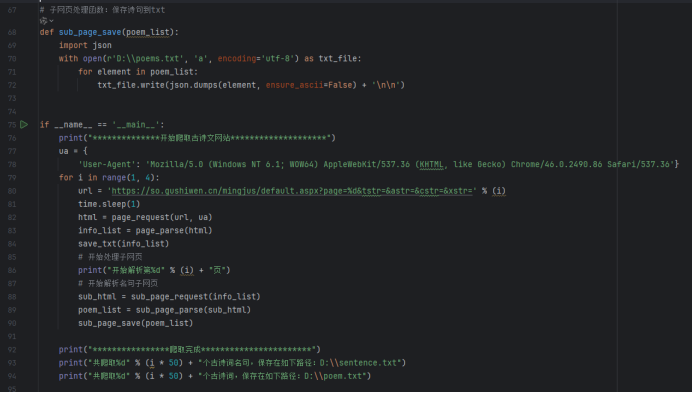
12、项目——采集网页数据保存到文本文件
目标页面:https://www.gushiwen.cn/mingjus/

https://www.gushiwen.cn/mingju/juv_14169affadb9.aspx
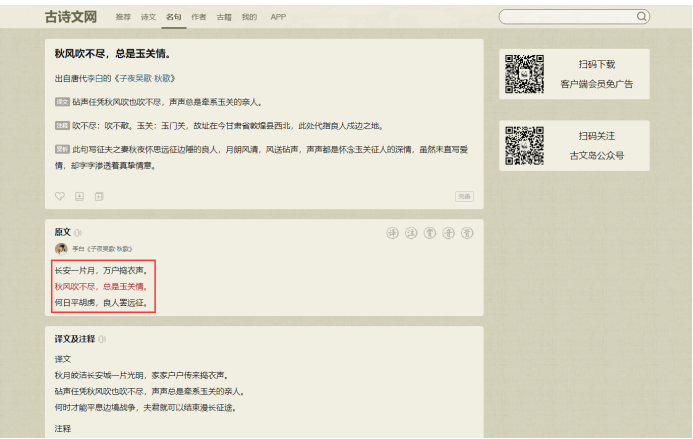
需求:
保存名句
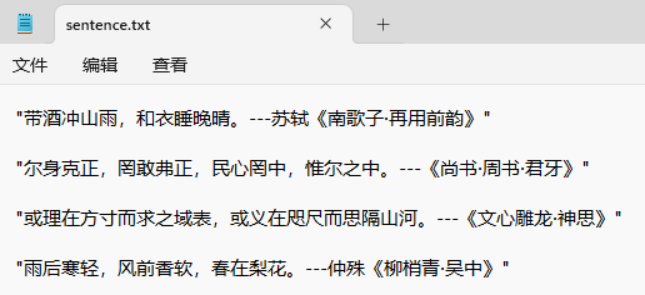
保存原文

确定名称共几个页面
https://www.gushiwen.cn/mingjus/
https://www.gushiwen.cn/mingjus/default.aspx?page=2&tstr=&astr=&cstr=&xstr=
https://www.gushiwen.cn/mingjus/default.aspx?page=3&tstr=&astr=&cstr=&xstr=
https://www.gushiwen.cn/mingjus/default.aspx?page=4&tstr=&astr=&cstr=&xstr=
分析规律
https://www.gushiwen.cn/mingjus/default.aspx?page=1&tstr=&astr=&cstr=&xstr=
分析名句的源代码

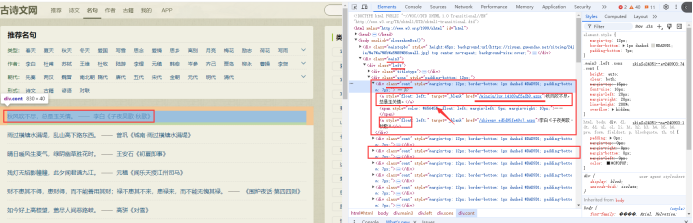
分析原文的源代码
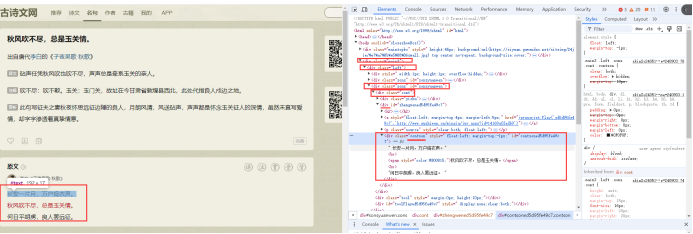
代码实现
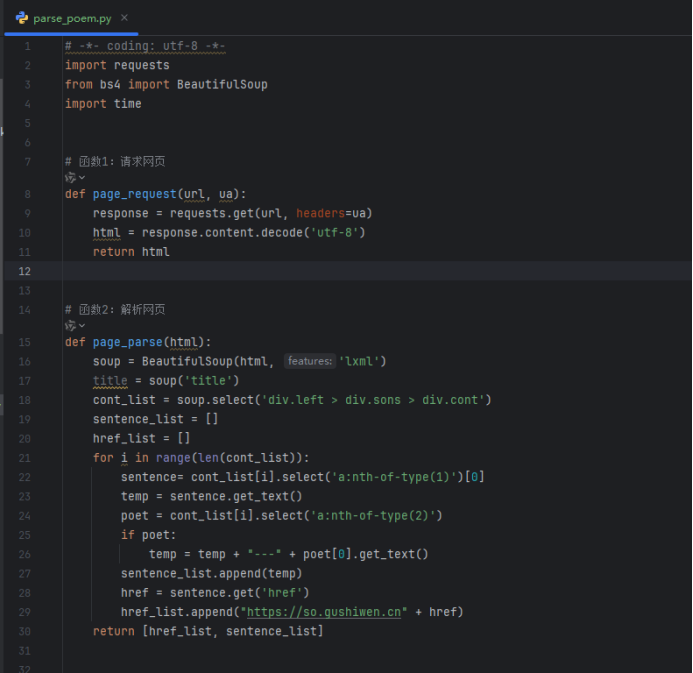
运行结果

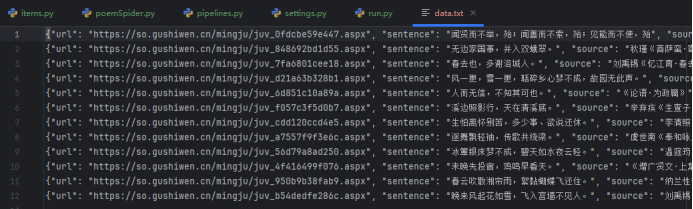
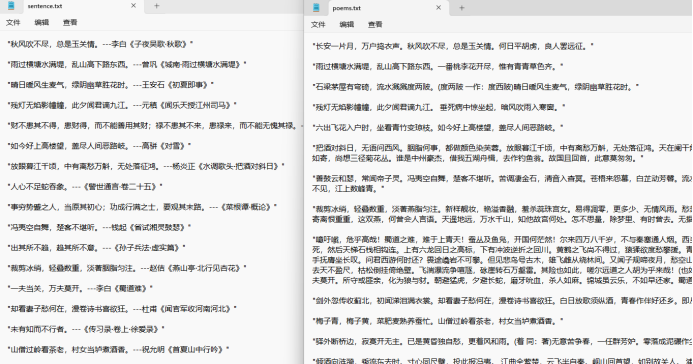
查看数据
13、项目——采集网页数据保存到MySQL
本地页面(好处:代码规则永不变化,稳定)
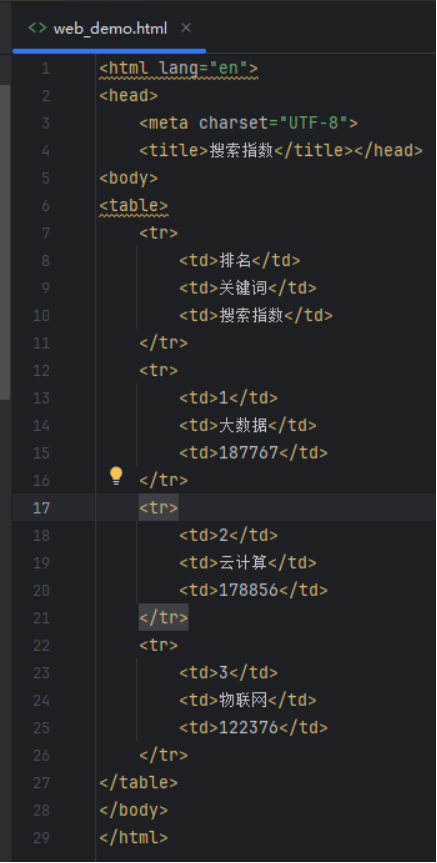
需求
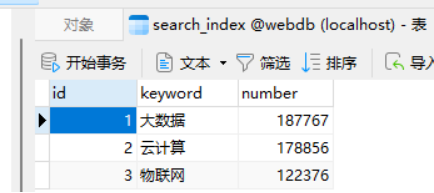
将关键词和搜索次数,写入MySQL数据库
实现过程
1)创建数据库与表
建库
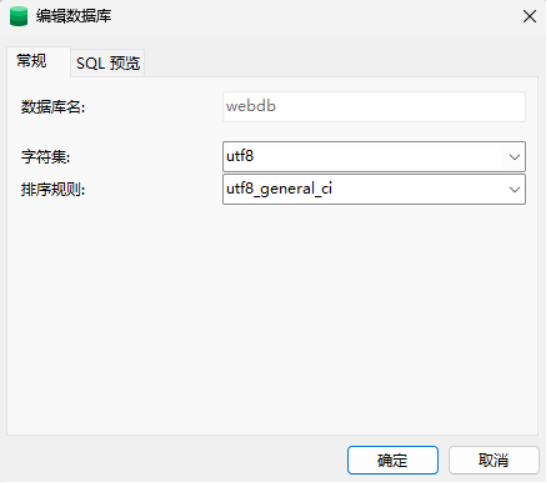
建表


2)分析页面
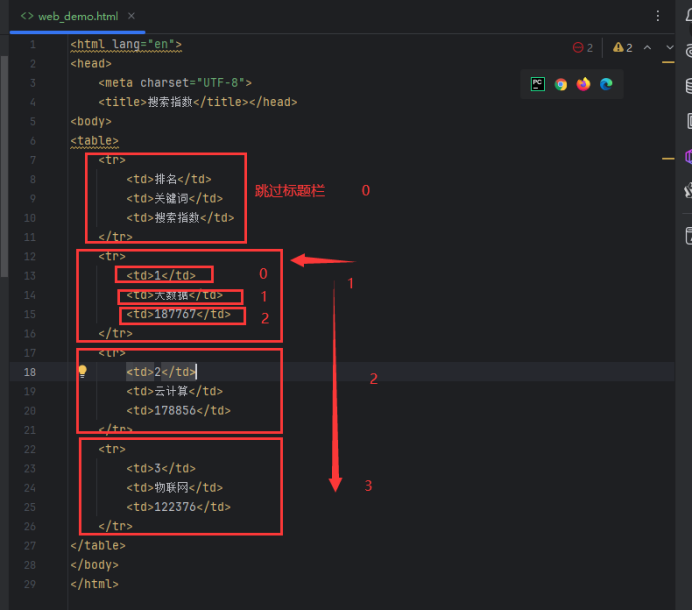
3)编写代码
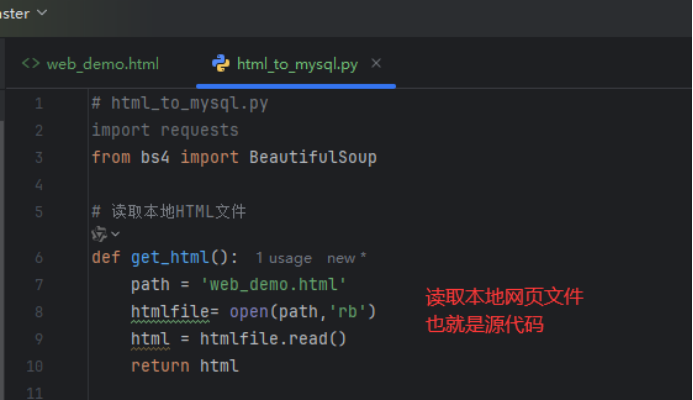
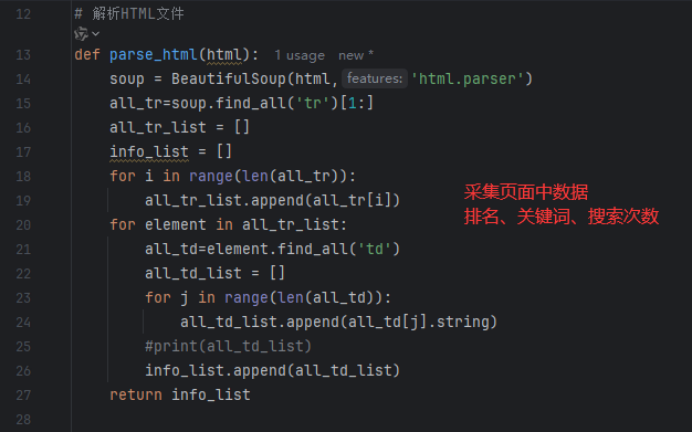
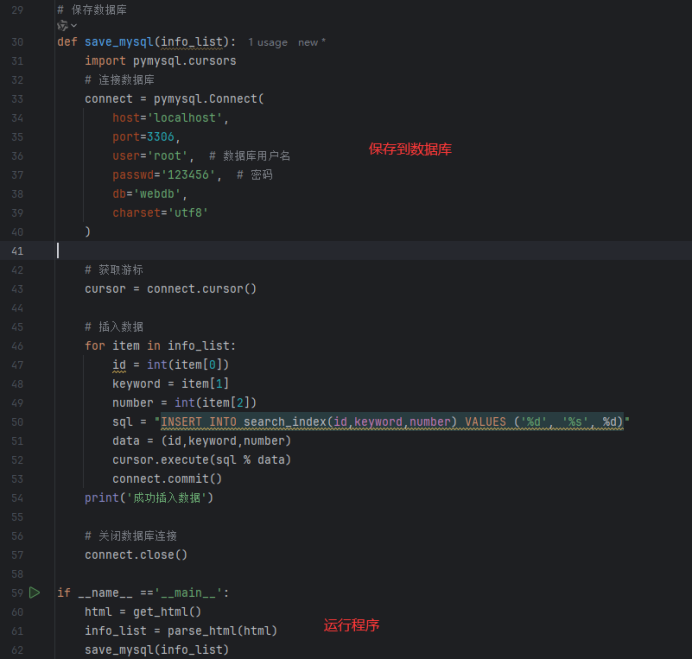
4)运行程序
5)查看数据
14、Scrapy爬虫概述
安装模块,确保版本一致
安装1(默认国外源,通常会出现超时)
pip install scrapy2.11.0
pip install lxml5.0.0
pip install pyopenssl==23.3.0
安装2(使用国内清华源,速度快)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=1000 scrapy2.11.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=1000 lxml5.0.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout=1000 pyopenssl==23.3.0
安装3(部署模式使用)
1)创建requirements.txt
文件中内容
scrapy2.11.0
lxml5.0.0
pyOpenSSL==23.3.0
2)安装
pip install -r requirements.txt
Scrapy爬虫概述
基于Twisted异步处理框架
纯Python实现的爬虫框架
定制几个模块
抓取内容包括文字、图片、媒体等
跨平台运行
运行模式:本地、云端
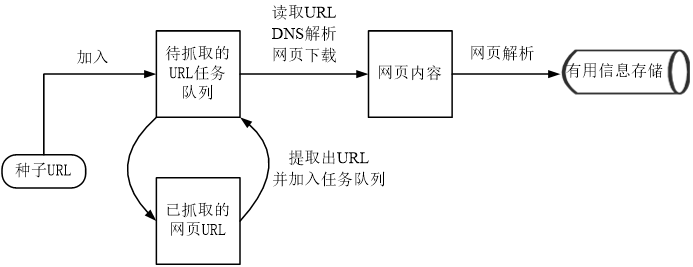
scrapy体系架构
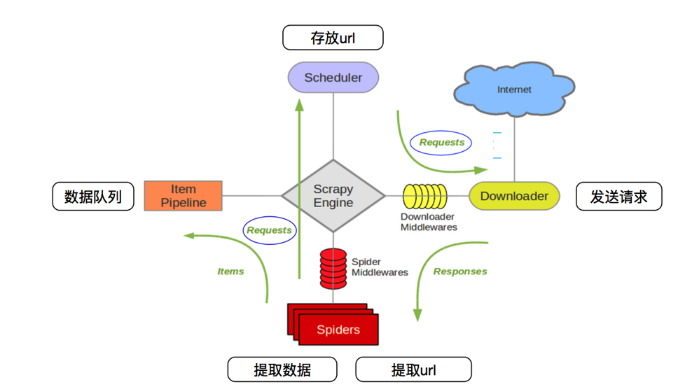
①Scrapy引擎从调度器中取出一个链接(URL)用于接下来的抓取;
②Scrapy引擎把URL封装成一个请求并传给下载器;
③下载器把资源下载下来,并封装成应答包;
④爬虫解析应答包;
⑤如果解析出的是项目,则交给项目管道进行进一步的处理;
⑥如果解析出的是链接(URL),则把URL交给调度器等待抓取。
15、XPath语言
XPath
XML Path Language
在XML和html文档中查找信息的语言
内置上百个函数
节点类型
元素
属性
文本
命名空间
处理指令
注释
文档
节点关系
父节点
子节点
兄弟节点
祖先节点
后代节点
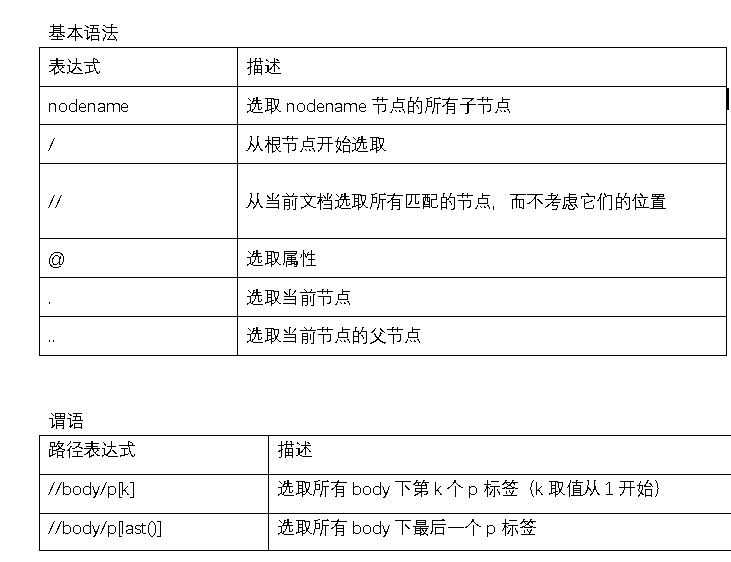
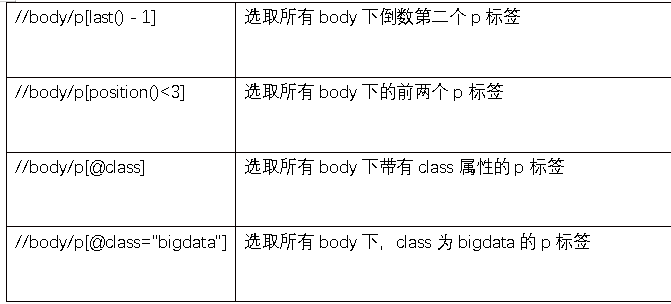
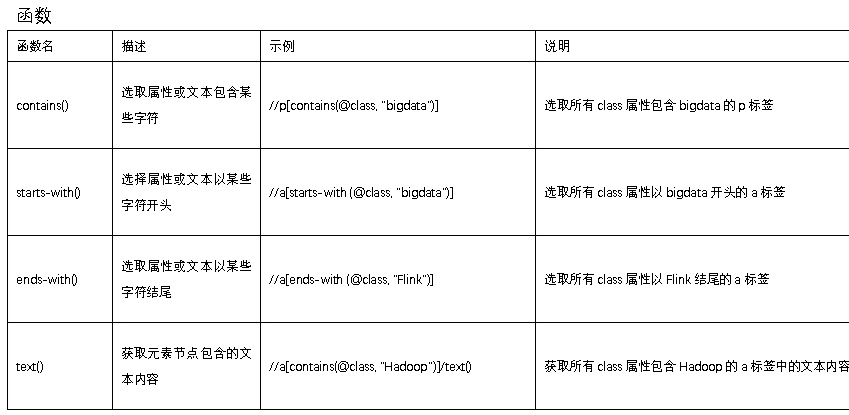
基本语法
16、项目——scrapy爬虫
目标页面:https://www.gushiwen.cn/mingjus/
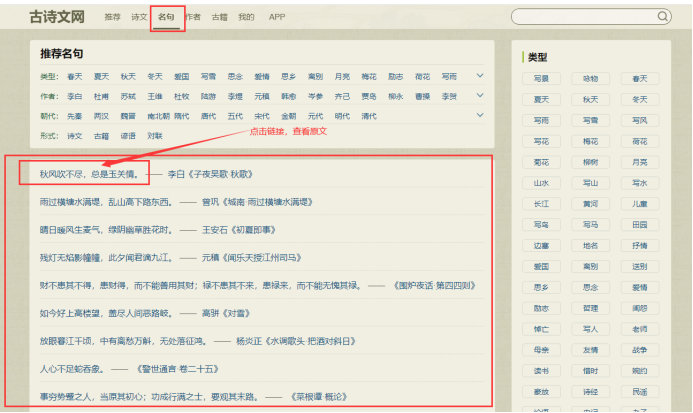
https://www.gushiwen.cn/mingju/juv_14169affadb9.aspx
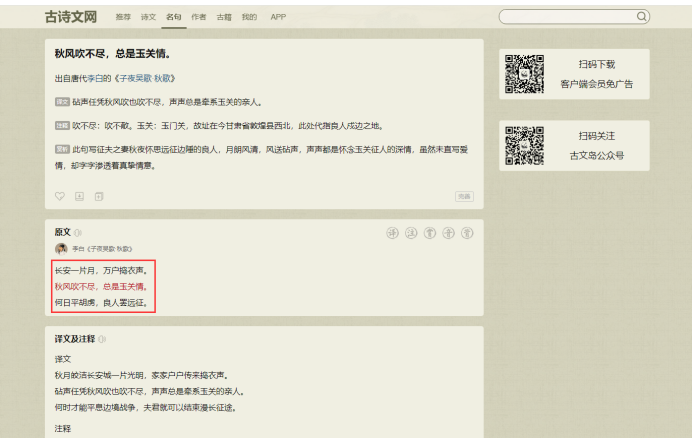
需求:
保存名句
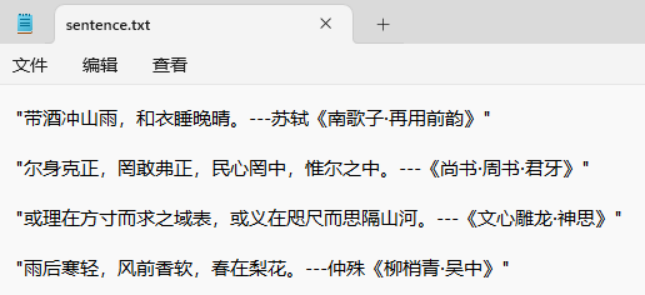
保存原文

确定名称共几个页面
https://www.gushiwen.cn/mingjus/
https://www.gushiwen.cn/mingjus/default.aspx?page=2&tstr=&astr=&cstr=&xstr=
https://www.gushiwen.cn/mingjus/default.aspx?page=3&tstr=&astr=&cstr=&xstr=
https://www.gushiwen.cn/mingjus/default.aspx?page=4&tstr=&astr=&cstr=&xstr=
分析规律
https://www.gushiwen.cn/mingjus/default.aspx?page=1&tstr=&astr=&cstr=&xstr=
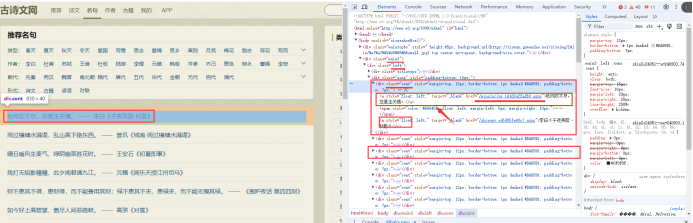
分析名句的源代码

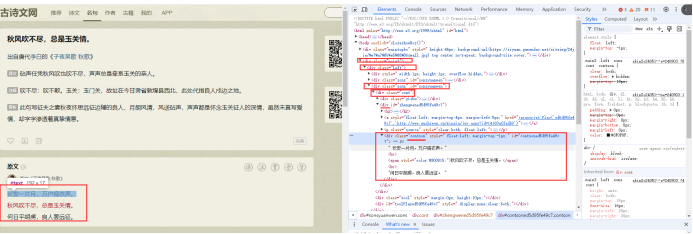
分析原文的源代码
实现过程
1)创建项目
2)创建scrapy子项目
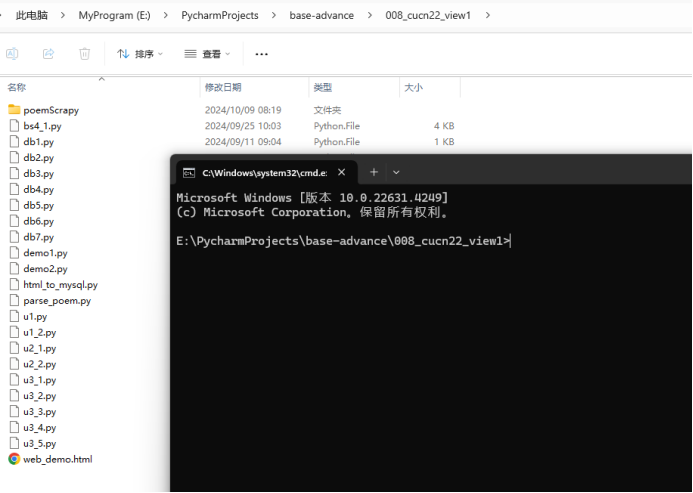
scrapy startproject 子项目名称
如
scrapy startproject poemScrapy
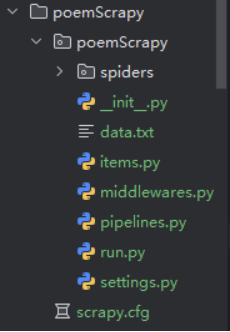
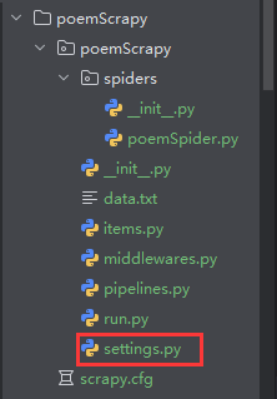
目录介绍
l Spiders目录:该目录下包含爬虫文件,需编码实现爬虫过程;
l init.py:为Python模块初始化目录,可以什么都不写,但是必须要有;
l items.py:模型文件,存放了需要爬取的字段;
l middlewares.py:中间件(爬虫中间件、下载中间件),本案例中不用此文件;
l pipelines.py:管道文件,用于配置数据持久化,例如写入数据库;
l settings.py:爬虫配置文件;
scrapy.cfg:项目基础设置文件,设置爬虫启用功能等。在本案例中不用此文件。
3)定制items
保存采集的数据
import scrapy
class PoemscrapyItem(scrapy.Item):
# 名句
sentence = scrapy.Field()
# 出处
source = scrapy.Field()
# 全文链接
url = scrapy.Field()
# 名句详细信息
content = scrapy.Field()
4)定制Spider
采集页面并处理(链接、页面内容)
创建爬虫
scrapy genspider poemSpider so.gushiwen.cn

编写代码
import scrapy
from scrapy.http import Request,Response
from ..items import PoemscrapyItem
class PoemspiderSpider(scrapy.Spider):
name = 'poemSpider' # 用于区别不同的爬虫
allowed_domains = ['gushiwen.cn'] # 允许访问的域
start_urls = ['https://so.gushiwen.cn/mingjus/'] # 爬取的地址
def parse(self, response:Response):
# 先获每句名句的div
for box in response.xpath('//*[@id="html"]/body/div[2]/div[1]/div[2]/div'):
# 获取每句名句的链接
url = 'https://so.gushiwen.cn' + box.xpath('.//@href').get()
# 获取每句名句内容
sentence = box.xpath('.//a[1]/text()').get()
# 获取每句名句出处
source = box.xpath('.//a[2]/text()').get()
# 实例化容器
item = PoemscrapyItem()
# # 将收集到的信息封装起来
item['url'] = url
item['sentence'] = sentence
item['source'] = source
# 处理子页
yield scrapy.Request(url=url, meta={
'item': item}, callback=self.parse_detail)
# 翻页
next = response.xpath('//a[@class="amore"]/@href').get()
if next is not None:
next_url = 'https://so.gushiwen.cn' + next
# 处理下一页内容
yield Request(next_url)
def parse_detail(self, response):
# 获取名句的详细信息
item = response.meta['item']
content_list = response.xpath('//div[@class="contson"]//text()').getall()
content = "".join(content_list).strip().replace('\n', '').replace('\u3000', '')
item['content'] = content
yield item
5)定制pipelines
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class PoemscrapyPipeline:
def __init__(self):
# 打开文件
self.file = open('data.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 读取item中的数据
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
# 写入文件
self.file.write(line)
return item
6)定制settings
# Scrapy settings for poemScrapy project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "poemScrapy"
SPIDER_MODULES = ["poemScrapy.spiders"]
NEWSPIDER_MODULE = "poemScrapy.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "poemScrapy.middlewares.PoemscrapySpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "poemScrapy.middlewares.PoemscrapyDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"poemScrapy.pipelines.PoemscrapyPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
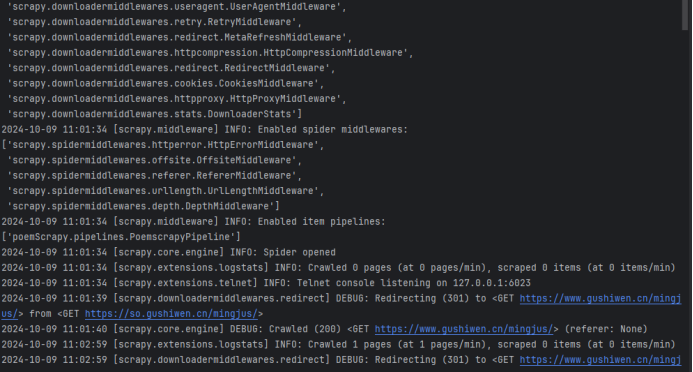
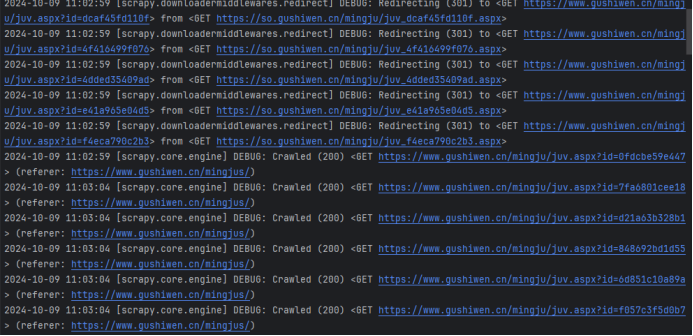
7)运行爬虫
运行1:控制台命令
scrapy crawl poemSpider
运行2:编写代码

8)查看保存的数据
部分运行截图
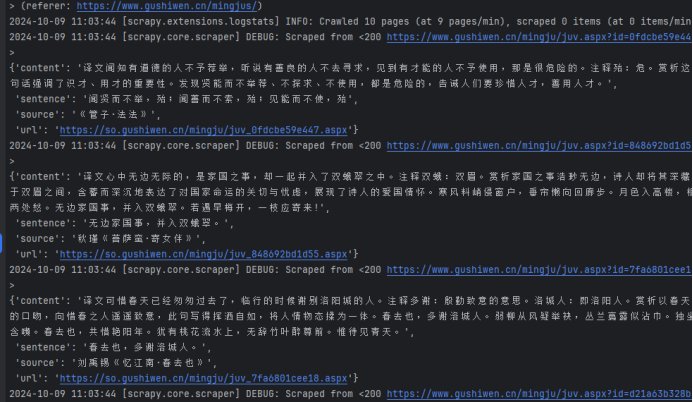
查看数据