全文总结
本文提出了一种使用统计机器翻译(SMT)框架从源代码自动生成伪代码的方法。
研究背景
- 背景介绍: 这篇文章的研究背景是伪代码可以用自然语言描述程序语句的行为,帮助不熟悉编程语言的人理解源代码。然而,大多数源代码没有对应的伪代码,因为伪代码冗长且耗时。如果能够自动生成伪代码,可以在不需要人工干预的情况下按需生成伪代码。
- 研究内容: 该问题的研究内容包括使用统计机器翻译(SMT)框架自动生成伪代码,特别是短语机器翻译(PBMT)和树到串机器翻译(T2SMT)两种方法。
- 文献综述: 该问题的相关工作有:传统的自动注释生成方法主要基于减少代码阅读量的思想,分为基于规则的方法和基于数据的方法。基于规则的方法使用手动定义的启发式规则,适用于处理复杂的语言结构,但扩展性差。基于数据的方法通过增加训练数据来提高准确性,但存在数据稀疏性问题。SMT结合了两者的优点,能够从数据中学习翻译规则。
研究方法
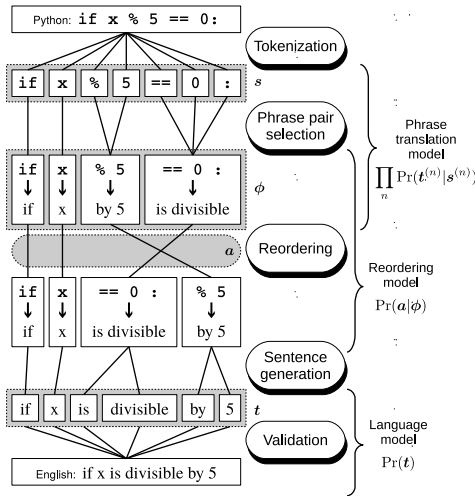
这篇论文提出了使用统计机器翻译(SMT)框架自动生成伪代码。具体来说:
-
统计机器翻译(SMT): SMT通过定义条件概率分布来生成目标句子,公式如下:
-
t^≡argmaxtPr(t∣s).(1)t^≡argtmaxPr(t∣s).(1)
其中,Pr(t∣s)Pr(t∣s) 是给定源句子 ss 的条件下目标句子 tt 的概率,通过平行语料库计算得到。
-
短语机器翻译(PBMT): PBMT直接使用源语言和目标语言之间的短语对关系。通过短语表提取短语对,并进行重排序以生成目标句子。公式如下:
-
t^≡argmaxt,ϕ,aPr(t,ϕ,a∣s),(6)
- t^≡argt,ϕ,amaxPr(t,ϕ,a∣s),(6)
其中,f(t,ϕ,a,s)f(t,ϕ,a,s) 表示翻译过程中计算的特征函数,ww 表示特征权重向量。
-
树到串机器翻译(T2SMT): T2SMT使用源句子的解析树 TsTs 来避免PBMT无法处理通配符和层次结构的问题。公式如下:
-
t^≃argmaxtPr(t∣Ts),(9)t^≃argtmaxPr(t∣Ts),(9)
其中,TsTs 是源句子的解析树,定义了编程语言的语法结构。
扫描二维码关注公众号,回复: 17508571 查看本文章
-
规则提取: 使用词对齐从平行语料库中提取翻译规则。PBMT使用满足特定条件的短语对,T2SMT使用GHKM算法提取树到串的翻译规则。
-
语言模型: 使用n-gram模型评估目标句子的流畅性,公式如下:
-
Pr(ti∣ti−n+1i−1)≃Pr(ti∣ti−n+1i−1),(12)
- Pr(ti∣ti−n+1i−1)≃Pr(ti∣ti−n+1i−1),(12)
其中,n-gram表示连续的n个词。
实验设计
- 数据收集: 创建了Python到英语和Python到日语的平行语料库。Python到英语语料库包含18,805对Python语句和对应的英语伪代码。Python到日语语料库包含722个Python语句及其对应的日语伪代码。
- 数据划分: Python到英语语料库分为训练集(16,000条)、开发集(1,000条)和测试集(1,805条)。Python到日语语料库使用10折交叉验证。
- 工具使用: 使用开源工具如MeCab、pialign、KenLM、Moses和Travatar来构建和训练SMT系统。
结果与分析
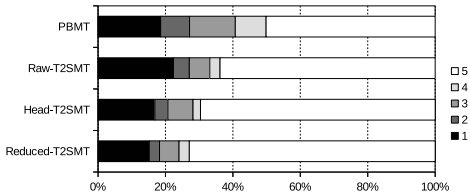
- BLEU评分: PBMT在Python到英语数据集上的BLEU评分为25.71,T2SMT系统显著高于PBMT,其中Reduced-T2SMT最高,达到54.08。Python到日语数据集上,PBMT的BLEU评分为51.67,T2SMT系统也显著高于PBMT,其中Reduced-T2SMT最高,达到62.88。
- 人工评估: 日语专家对Python到日语伪代码的可接受性评分显示,Reduced-T2SMT的平均可接受性得分最高,为4.155。
- 代码理解: 通过Web界面进行的代码理解实验表明,提供伪代码可以显著提高编程新手对源代码的理解效率。
结论
这篇论文提出了一种基于统计机器翻译框架自动生成伪代码的方法,特别是使用了短语机器翻译(PBMT)和树到串机器翻译(T2SMT)。实验结果表明,自动生成的伪代码在语法正确性和代码理解方面表现良好,能够显著提高编程新手对源代码的理解效率。未来的工作包括处理多语句的伪代码生成以及在大型软件项目环境中使用自动伪代码生成。
这篇论文通过实验证明了自动生成伪代码的有效性,具有重要的理论和实际意义。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何从源代码自动生成伪代码,以帮助程序员更好地理解不熟悉编程语言的源代码。
- 研究难点:该问题的研究难点包括:伪代码的创建冗长且耗时;现有的伪代码生成方法要么基于规则,难以扩展;要么基于数据,但存在数据稀疏性问题。
- 相关工作:该问题的研究相关工作有:基于规则的方法,如Sridhara等人提出的Java方法摘要生成方法;基于数据的方法,如Wong等人提出的从编程问答社区提取注释的方法。这些方法各有优缺点,但都无法完全解决自动生成准确伪代码的问题。
研究方法
这篇论文提出了一种基于统计机器翻译(SMT)框架的伪代码生成方法。具体来说,
-
统计机器翻译(SMT):SMT是一种将一种自然语言自动翻译成另一种自然语言的技术。近年来,SMT算法主要基于两个思想:提取输入和输出语言之间的小片段关系,并使用统计模型决定最佳翻译结果。
-
短语机器翻译(PBMT):PBMT直接使用源语言和目标语言对之间的短语对关系。PBMT模型通过定义源句子和目标短语的对应关系来生成目标句子。公式如下:
t^≡argmaxtPr(t∣s)t^≡argtmaxPr(t∣s)其中,Pr(t∣s)Pr(t∣s) 表示给定源句子 ss 的目标句子 tt 的条件概率分布。
-
树到字符串的翻译(T2SMT):T2SMT使用源句子的解析树而不是源标记来避免短语翻译中的问题。T2SMT模型通过替换源子树与目标短语中的通配符来生成目标句子。公式如下:
t^≃argmaxtPr(t∣Ts)t^≃argtmaxPr(t∣Ts)其中,TsTs 是源句子的解析树。
-
规则提取:从平行语料库中提取翻译规则,用于训练PBMT和T2SMT模型。使用词对齐方法确定源语言和目标语言之间的单词级关系。
-
语言模型:语言模型评估目标语言句子的流畅性。通常使用n-gram模型来计算条件概率:
Pr(ti∣t1i−1)≃Pr(ti∣ti−n+1i−1)Pr(ti∣t1i−1)≃Pr(ti∣ti−n+1i−1)其中,n-gram表示连续的n个单词。
实验设计
- 数据收集:通过雇佣程序员为现有代码添加伪代码,创建了Python到英语和Python到日语的平行语料库。Python到英语语料库包含18,805对Python语句和对应的英语伪代码;Python到日语语料库包含722个Python语句和对应的日语伪代码。
- 数据分割:将Python到英语语料库分为训练集(16,000条语句)、开发集(1,000条语句)和测试集(1,805条语句)。Python到日语语料库进行10折交叉验证,使用90%的数据作为训练集,10%的数据作为测试集。
- 工具使用:使用MeCab进行日语分词,pialign训练词对齐,KenLM训练Kneser-Ney平滑语言模型,Moses和Travatar分别训练和生成PBMT和T2SMT模型的目标句子。
结果与分析
-
自动评估(BLEU分数):在Python到英语和Python到日语数据集上,所有提出的方法的BLEU分数都相对较高(除了PBMT在Python到英语数据集上的得分较低),表明生成的伪代码相对准确。Python到日语数据集的BLEU分数高于Python到英语数据集,可能是因为日语数据集的输入代码风格较为一致。
-
人工评估(可接受性):在Python到日语数据集上,所有T2SMT系统的平均可接受性得分均高于PBMT系统,特别是Reduced-T2SMT系统的平均可接受性得分超过4,表明其生成的伪代码中有大量被评判为语法正确的句子。
-
代码理解:在代码理解实验中,参考设置(人类生成的伪代码)的可理解性和阅读时间最佳,自动化设置(自动生成的伪代码)次之。这表明正确的伪代码确实提高了代码的阅读效率和理解度。
总体结论
这篇论文提出了一种基于统计机器翻译(SMT)的伪代码生成方法,能够自动从源代码生成准确的伪代码,减少了人工编写和维护伪代码的工作量。实验结果表明,该方法生成的伪代码在语法正确性和代码理解度方面表现良好,特别是在处理具有相似编程风格的代码时效果更佳。未来的工作包括开发多语句伪代码生成器,并在大型软件项目环境中应用自动伪代码生成。
论文评价
优点与创新
- 首次提出自动生成伪代码的方法:论文提出的基于统计机器翻译(SMT)的伪代码生成方法,能够完全描述对应的源代码,这在之前的研究中是前所未有的。
- 使用SMT框架:利用SMT技术,特别是短语机器翻译(PBMT)和树到字符串机器翻译(T2SMT),可以自动学习源代码和伪代码之间的关系,减少了人工创建和维护伪代码生成器的工作量。
- 实验验证:实验结果表明,所提出的方法在Python到英语和Python到日语的伪代码生成任务中表现出色,生成的伪代码具有较高的准确性,并有助于代码理解。
- 多种评估方法:采用了自动评估(BLEU评分)、人工评估(可接受性评分)和代码理解度评估等多种方法,全面验证了生成伪代码的质量和实用性。
- 工具链支持:使用了多个开源工具来辅助构建伪代码生成系统,如MeCab、pialign、KenLM、Moses和Travatar,这些工具使得系统的实现更加高效和可靠。
不足与反思
- 数据稀疏性问题:现有的自动评论生成方法主要基于检索已有的评论,存在数据稀疏性问题。如果训练数据中没有描述现有代码的评论,就无法生成准确的评论。
- 规则维护负担:尽管SMT框架可以减少人工创建和维护伪代码生成器的工作量,但在需要更新生成器以覆盖新情况时,仍然需要手动添加或修改规则,这可能会带来一定的负担。
- 多语句处理:未来的工作将致力于开发能够处理多语句的伪代码生成器,这是一个比逐行生成评论更不规律的问题,具有挑战性。
- 实际应用环境:计划研究在大规模软件项目环境中自动生成伪代码的应用,例如,程序员可以使用自动生成的伪代码来确认他们编写的代码是否按预期工作,或者帮助确认现有单行注释是否需要更新。
关键问题及回答
问题1:论文中提到的两种统计机器翻译(SMT)框架——短语机器翻译(PBMT)和树到字符串机器翻译(T2SMT)——在伪代码生成中的具体实现方式有何不同?
- 短语机器翻译(PBMT):
- 实现方式:PBMT直接使用源语言和目标语言对之间的短语对关系。它通过一个“短语表”来生成目标句子,并通过重排序来确保语法正确性。
- 关键步骤:
- 将源句子分解为短语对。
- 使用短语表和重排序模型来生成目标句子。
- 公式:
t^≡argmaxtPr(t∣s)t^≡argtmaxPr(t∣s)
- 优点:简单直观,适用于短语级别的翻译。
- 缺点:缺乏处理复杂语言结构和嵌套关系的表达能力。
- 树到字符串机器翻译(T2SMT):
- 实现方式:T2SMT使用源句子的解析树来避免短语的局限性。它通过替换子树与目标短语之间的关系来生成目标句子。
- 关键步骤:
- 将源代码解析为抽象语法树(AST)。
- 使用解析树来生成目标句子,替换子树与目标短语之间的关系。
- 公式:

t^≃argmaxtPr(t∣Ts)t^≃argtmaxPr(t∣Ts)
- 优点:能够处理复杂的语言结构和嵌套关系,生成更准确的伪代码。
- 缺点:计算复杂度较高,需要对解析树进行操作。
问题2:论文中如何评估生成的伪代码的准确性和有用性?
- 自动评估(BLEU):
- 使用BLEU(Bilingual Evaluation Understudy)分数来自动测量生成的伪代码的准确性。BLEU通过计算生成翻译与人工参考翻译之间的相似度来评估准确性。
- 公式:

BLEU=precisionn×brevity penalty
BLEU=precisionn×brevity penalty
- 优点:快速且自动化,适用于大规模评估。
- 缺点:无法完全保证语义正确性,可能会产生生成过于简短或不准确的翻译。
- 人工评估(可接受性):
- 为了更准确地评估翻译质量,进行了人工可接受性评估。请5位日本专家Python程序员对每条生成的日语伪代码进行评分,评分标准包括语法正确性和流畅性。
- 表格:展示了不同方法的平均可接受性得分。
- 代码理解:
- 通过Web界面进行代码理解实验,评估初学者程序员对自动生成伪代码的理解程度。实验包括展示函数定义和对应的伪代码,要求程序员评分其理解度和阅读时间。
- 表格:展示了不同设置下的平均理解印象和平均阅读时间。
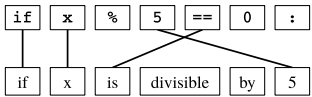
问题3:论文中提到的“头插入”和“剪枝与简化”过程是如何应用于抽象语法树(AST)的?
- 头插入:
- 目的:在AST中插入一个新的边,称为“HEAD”,使其包含内部节点的标签作为叶子节点。这样做的目的是使原本在AST中消失的关键词(如“if”)重新成为词对齐的候选词。
- 示例:对于源代码“if x % 5 == 0:”,插入HEAD后变为“if HEAD x % 5 == 0:”。
- 剪枝与简化:
- 目的:减少插入HEAD后AST的复杂度,去除与目标语言表面形式不相关的节点,以避免自动词对齐中的噪声。
- 示例:插入HEAD后的树可能变得非常庞大,通过剪枝和简化规则(如移除没有信息表达的节点)来简化树结构。
这些过程使得生成的AST更适合用于SMT训练,提高了伪代码生成的准确性和流畅性。
