文章目录
一、非规范化问题
1、非规范化 问题简介
非规范化 的 关系模式 , 存在如下问题 :
- 数据冗余 : 同一数据 在 数据库的多个位置 重复存储 , 造成 存储空间的浪费 , 数据一致性维护成本增加 ;
- 非规范化设计 : 数据表 未通过范式分解 , 导致 字段之间存在 不必要的 依赖关系 ;
- 多字段组合存储 : 例如 将学生信息 和 课程信息 混合存储 , 导致学生姓名、学院等信息在每条课程记录中重复 ;
- 更新异常 : 修改数据时 , 可能 因冗余导致部分数据未同步更新 , 引发数据不一致 , 导致 数据可信度降低 , 维护一致性 需要复杂的更新逻辑 ;
- 冗余数据未集中管理 : 同一数据分布在多个记录或表中 ;
- 依赖关系复杂 : 数据间的 逻辑依赖 未被合理约束 ;
- 插入异常 : 无法插入某些必需数据 , 除非同时插入其他不相关数据 ; 导致 无法独立插入关键业务数据 , 需要设计临时占位数据 , 破坏数据完整性 ;
- 主键依赖不合理 : 主键包含不必要字段 , 导致插入时 必须提供无效数据 ;
- 数据耦合性高 : 实体信息与关联信息未分离 ;
- 删除异常 : 删除数据时 , 意外丢失其他必要信息 ; 导致 关键数据意外丢失 , 需通过额外逻辑 保留必要数据 , 增加复杂度 ;
- 数据耦合性高 : 不同实体的数据存储在同一表中 ;
- 依赖关系未隔离 : 删除一个实体的数据 会连带删除其他实体数据 ;
2、非规范化 问题原因
非规范化 关系模式 原因总结 : 非规范化 核心问题 源于 数据依赖关系不合理 ;
- 部分函数依赖 : 非主键字段 仅依赖主键的一部分 , 违反 2NF ;
- 传递函数依赖 : 非主键字段 间接依赖主键 , 违反 3NF ;
3、非规范化 示例说明
下面的表格中 , 有 学号、姓名、系号、系名、系位置 属性 , 几乎将系统所需要的所有数据 , 放在了一个表格中进行处理 ;
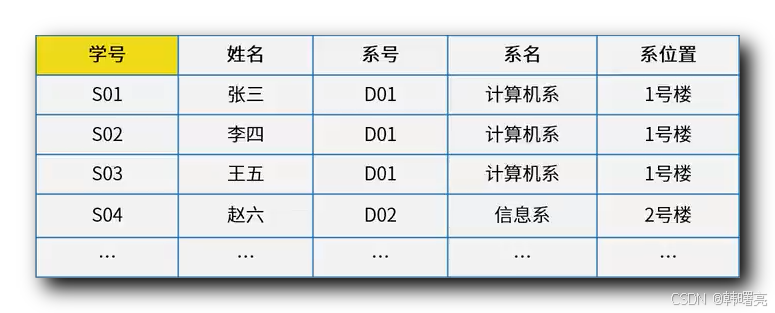
上述表格 中 , 会出现一系列的 非规范化 问题 ;
- 数据冗余 : 表格中 , 系名 和 系位置 属性 , 每个属性都是一个长字符串 , 占用了很多的存储空间 , 假如有 100 万条学生数据 相应的 数据冗余是很大的 , 浪费了大量的存储空间 ;
- 更新异常 : 如果 系位置 发生了改变 , 那么就需要将 100 万个 学生信息实体 元组行 都需要进行修改 , 操作数据量大 , 容易出错 导致 漏掉某些元组的修改 ;
- 插入异常 : 数据库表 中的 主键必须是 非空的 , 如果 新创建一个系 , 还没有招生 , 那么 新插入的系的 学号主键 就是空的 ;
- 删除异常 : 有个系 被取消 , 不再招生 , 删除 某个系 , 删除过程会同时删除学生信息 ;
4、非规范化 解决方案
解决上述问题 , 就是 规范化 上述关系 , 通过分解表结构 , 消除冗余和异常 ;
- 1NF : 确保 字段 原子性 ( 不可再分 ) ;
- 2NF : 消除 非主键字段 对主键的 部分依赖 ;
- 3NF : 消除 非主键字段间 的 传递依赖 ;
- BCNF : 进一步 消除 主键字段间 的依赖 ;
上述示例 规范化后的表 :
学生表 ( 学号, 姓名, 系号 )
系表 ( 系号, 系名, 系位置 )
二、规范化理论 - 函数依赖
1、函数依赖 概念说明
函数依赖 概念 : R ( U , F ) 是 二元关系 , R 是实体 , U 是 属性集合 , F 是 依赖集合 ,
X 、 Y 是 属性集合 U 的 子集 ,
r 是 任意一个 关系 ,
如果 r 中 任意两个 元组 u 、 v , 只要有 u[X] = v[X] 就有 u[Y] = v[Y] ,
X 函数决定 Y , Y 函数依赖于 X , 可以记做 X -> Y ;
- 决定因素 : " -> " 符号 左侧 的 X 是 决定因素 ;
- 被决定因素 : " -> " 符号 右侧 的 Y 是 被决定因素 ;
2、函数依赖 示例说明
给定一个二元关系 :
学生 ( U , F )
U = {
学号 , 姓名 , 年龄 , 班级编号}
F = {
学号 -> 姓名 , 学号 -> 年龄 , 学号 -> 班级编号}
如 : X 是 {学号} , Y 是 {姓名} , 学号 -> 姓名 , 学号 函数决定 姓名 , 姓名 函数依赖于 学号 ;
X 属性存在 , 对应的 Y 属性自然而然的存在 , 如 : 给定一个学生的学号 , 肯定有一个对应的 学生的姓名 , 学生的年龄 , 学号 就可以 函数决定 姓名 和 年龄 , 姓名 和 年龄 函数依赖于 学号 ;
反过来说 Y 不能决定 X , 根据 年龄 是不能找到学生的学号的 , 一年级的学生 年龄 都是 6 岁 , 姓名 和 年龄 是无法唯一确定一个 学生 实体的 ;
3、部分函数依赖
在关系模式中 , 若 某个 非主属性(Non-Prime Attribute) 依赖于 候选键(Candidate Key)的 部分属性 , 而非 整个候选键 , 则称为 " 部分函数依赖 " ;
非主属性 仅依赖 候选键的部分属性 , 常见于 复合主键 ;
部分函数依赖 示例 : 下面的关系模式 R1 中 , 属性 AB 函数决定 属性 D , 属性 D 函数依赖 于 属性 AB ;
属性 A 和 B 不能 单独 决定 D , 必须组合在一起 才能 函数决定 D ;
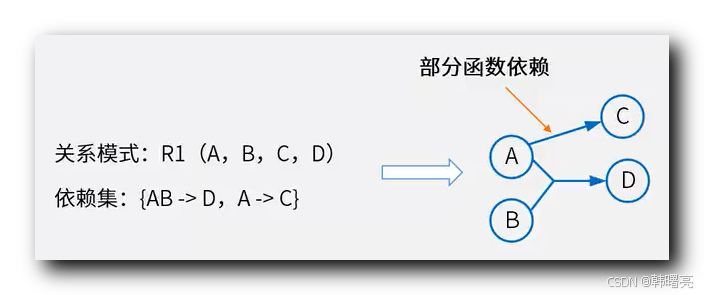
在 查找 关系 R1 的 候选键 时 , 如果 想要 在 有向图 中遍历到 D , 必须将 A 和 B 属性一起放入到 集合 L 中 ;
属性 C 依赖于 候选键 { A , B } 中的 一部分属性 { A } , 不是依赖于 所有的 候选键 { A , B } , 这种依赖 称为 " 部分函数依赖 " ;
4、传递函数依赖
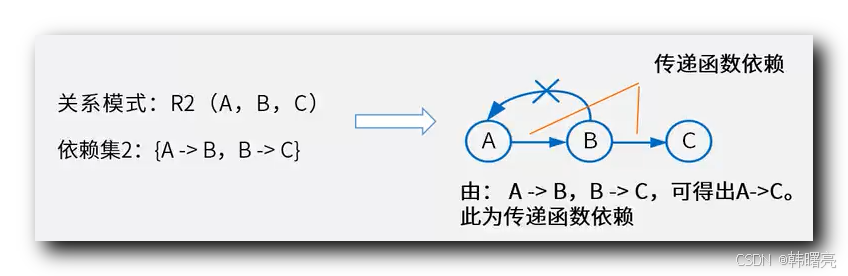
若 存在 属性集合 A -> B 且 B -> C,但 B 不决定 A , 则称 C 通过 B 传递依赖于 A ;
非主属性 通过 中间属性 间接依赖候选键 , 形成依赖链 ;
传递函数依赖 示例 : 下面的关系模式 R2 中 , 属性 A 函数决定 属性 B , 属性 B 函数决定 属性 C ;
属性 A 到 属性 C 就是 间接的 传递函数依赖 ;
三、候选键
1、候选键 概念简介
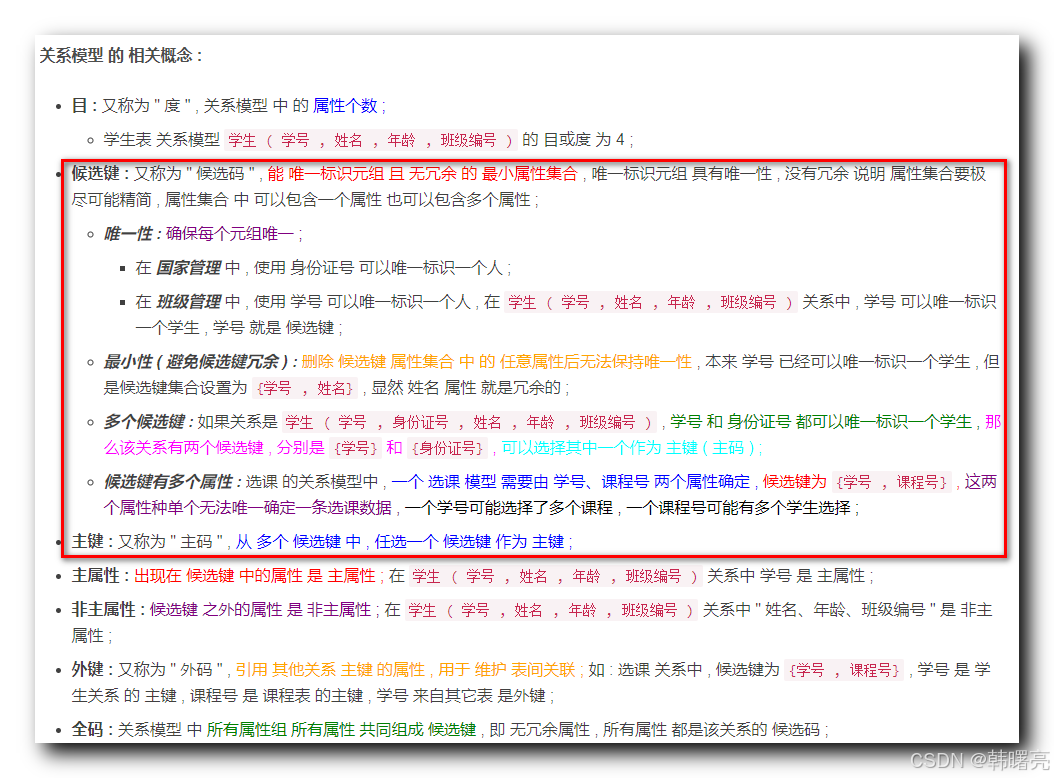
候选键 是 多属性集合 , 唯一可以标识 元组行 , 且没有任何 冗余 ;
一个关系 可以有 多个 候选键 ;
任意选择一个 候选键 可以作为 关系的 主键 ;
主属性 与 非主属性 : 出现在 候选键 中的属性 称为 " 主属性 " , 其它属性 称为 " 非主属性 " ;
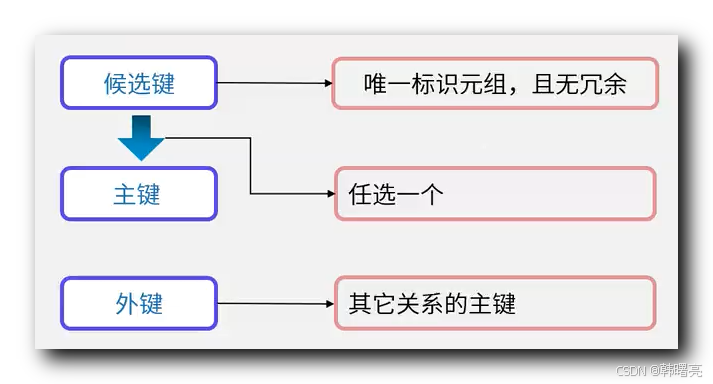
在 【系统架构设计师】数据库系统 ④ ( 关系模型 | 数据模型 三要素 | 数据模型 种类 | 关系模型 的 表示形式 | 关系模型相关概念 | 完整性约束 | 触发器 ) 博客中 对 候选码 、 主键 、 主属性 、 非主属性 、 外键 进行了简要说明 :
2、求取 关系 的 候选键
使用 " 图示法 " 查找 关系的 候选键 , 使用 " 有向图 " 的方式 分析 关系模式 的 函数依赖关系 ;
R ( U , F ) 是 关系模式 的表示方式 , U 是 属性集合 , F 是 依赖集合 ;
- 属性集合 U 作为 有向图 的 节点 ;
- 依赖集合 F 作为 有向图 的 有向边 ;
有向图 节点 的 入度 和 出度 : 箭头流出 是 出度 , 箭头流入 是 入度 ;
- X、Y 是两个属性 , X 函数决定 Y , Y 函数依赖于 X , 记做 X -> Y ;
- X 属性节点 的 出度为 1 , 入度为 0 ;
- Y 属性节点 的 出度为 0 , 入度为 1 ;
- 上述 依赖 的 有向边 方向是 X -> Y ;
候选键遍历 : 在 上述 " 有向图 " 中 , 找到 " 入度 为 0 " 的 属性节点 , 放在 " 遍历属性集合 " 中 , 以 该属性集合 中的属性节点 为起点 , 遍历 有向图 ,
- 遍历多次 : 不需要一次遍历完 , 可遍历多次 ;
- 间接遍历 : 不需要 完全 直接遍历 , 可以通过 多个节点传导遍历 , 间接遍历也可 ;
分析遍历结果 :
- 如果 能 正常遍历 有向图 中的所有节点 , 则 该 " 遍历属性集合 " 就是 关系模式的 候选键 ;
- 如果 不能 正常遍历 有向图 中的所有节点 , 则 该 " 遍历属性集合 " 就不是 关系模式的 候选键 ;
- 此时 需要 尝试 将 " 既有入度 又有出度 " 的 " 中间结点 " 并入 到 " 遍历属性集合 " 中 , 继续 以 集合中的属性节点 为起点 , 遍历有向图 , 直到 能够 正常遍历 有向图 中的所有节点 ;
四、软考考点
1、求取候选码 1
给定关系 R ( A1 , A2 , A3 , A4 ) , 该关系上的 函数依赖为 F = { A1 -> A2 , A3 -> A2 , A2 -> A3 , A2 -> A4 } ,
将 属性 " A1 , A2 , A3 , A4 " 和 函数依赖 F , 绘制成 " 有向图 " , 可以得到下面的 有向图 ;
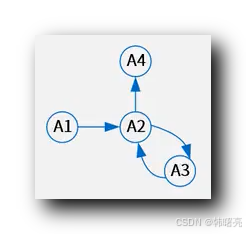
入度为 0 的 属性节点是 A1 , 将 A1 属性放入 " 遍历属性集合 " L 中 , L = { A1 } ;
以 A1 为起点 , 遍历 有向图 , 可以直接遍历到 A2 , 间接遍历到 A3 和 A4 , 可以完全遍历 整个 有向图 , 则 " 遍历属性集合 " L = { A1 } , 就是 该关系 R 的 " 候选键 " ;
{ A1 } 属性集合 是 R 的 候选键 ;
A1 属性 是 R 关系的 主属性 , A2 、A3 、A4 是 R 关系的 非主属性 ;
2、求取候选码 2
给定 关系模式 R ( U , F ) , 其中
- 属性集合 U = { A , B , C , D , E , F , G , H , I , J } ;
- 依赖集合 F = { ABD -> E , AB -> G , B -> F , C -> J , CJ -> I , G -> H } ;
求 上述 关系 R 的 候选键 ;
将 上述 属性集合 U 中的元素作为 有向图 的 节点 , 依赖集合 F 作为 有向图 的 有向边 , 绘制成的 有向图 如下图所示 :
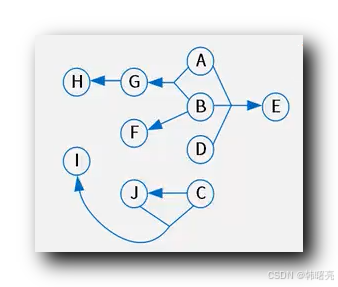
找到 入度 为 0 的 属性节点 , 将其放入 集合 L 中 , L = { A , B , D , C } ;
以 L 集合 属性为起点 , 可以 遍历 所有 的 属性节点 ;
L = { A , B , D , C } 集合 , 可以作为 关系 R 的候选键 ;
3、求取候选码 3
给定 关系模式 R ( U , F ) , 其中
- 属性集合 U = { A , B , C } ;
- 依赖集合 F = { B -> C , B -> A , A -> BC } ;
求 上述 关系 R 的 候选键 ;
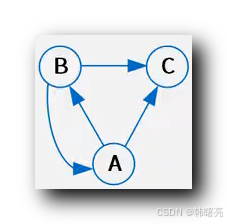
尝试 找到 入度 为 0 的 属性节点 , 将该属性节点放入集合 L , 发现没有 入度为 0 的 属性节点 ;
此时 L = { Φ } ;
查找入度为 1 的节点 , 放入 集合 L 中 ;
- 将 A 节点放入集合 L 中 , L = { A } , 此时 以 L 集合 属性为起点 , 可以 遍历 所有 的 属性节点 ;
- 将 B 节点放入集合 L 中 , L = { B } , 此时 以 L 集合 属性为起点 , 可以 遍历 所有 的 属性节点 ;
- C 的 入度为 2 , 并且没有出度 , C 不能作为候选键 ;
上述关系 R 的候选键为 { A } 或者 { B } , 任意一个都可以作为 候选键 ;
注意 : { A , B } 不能作为候选键 , 因为 单独的 A 属性 或者 单独的 B 属性 都可以作为候选键 , 两个属性一起就出现了 冗余 ;