文章目录

一、3D 模型建模
1、传统 3D 模型 建模
传统 3D 模型 建模 : 通过 三维建模软件 或 扫描技术 创建的 高精度、高复杂度 的三维模型 , 广泛应用于游戏、影视、工业设计等领域 ;
- 手动建模 : 使用 Maya 、 3D Max 、 Blender 等 3D 建模软件 , 通过 多边形建模 、 NURBS 曲面等技术人工构建模型 , 这种建模方式 耗时长、对专业要求高 , 难以生成复杂细节 ;
- 参数化建模 : 使用 数学公式 进行 建模 , 在 工业设计 中 的 标准化零件 生成 领域 使用这种建模方式 ;
2、3D 模型表示方式
3D 生成大模型 也在 发展中 , 3D 模型 的 表示方式 有很多种 , 目前表示方式还不统一 , 因此 3D 生成大模型 还在发展中 ;
3D 模型的表示方法 :
- 多边形网格 : 由 顶点 、 边 和 面 ( 多为 三角形 或 四边形 ) 构成 , 是 游戏 / 影视 行业主流格式 ;
- 参数化曲面 : 通过 参数方程 定义的 连续光滑曲面 ,典型代表为NURBS ( 非均匀有理B样条 ) , 主要用于 工业设计 ( 如汽车车身 、 飞机机翼 ) ;
- 点云 : 由 无序 三维点 组成的集合 , 直接来源于 激光雷达 ( LiDAR ) 或 深度相机扫描 , 用于 自动驾驶环境感知 ( 华为智驾中的激光雷达扫描数据处理 ) 、 文物数字化 ( 扫描 故宫 、 敦煌壁画 等 ) ;
- 神经辐射场 : NeRF ( NEURAL RADIANCE FIELDS ) , 通过 神经网络 建模 空间中每个点的 密度 和 颜色 , 实现隐式 3D 表示 , 应用于 高保真场景重建、虚拟现实中的动态光照模拟 ;
- 高斯溅射 : 将 3D 场景 表示为 可微分的 高斯分布集合 , 每个高斯描述局部几何与外观 , 用于 实时动态场景渲染 、 移动端 AR / VR 应用 ;
- 体素 : 三维空间的立方体单元 , 类比二维像素,可视为均匀网格中的最小体积单位 , 可以理解为 我的世界 中堆的积木 ;
3、3D 模型表示方式对比
| 表示方式 | 数据结构 | 存储效率 | 编辑性 | 渲染效率 | 适用场景 | 典型应用 | 主要优缺点 |
|---|---|---|---|---|---|---|---|
| 多边形网格 | 顶点、边、面 ( 三角/四边形 ) | 中等 | 高 | 高 | 精细表面建模、实时交互 | 游戏建模 ( 如《原神》角色 ) 、影视特效 ( 如《阿凡达》场景 ) | 优 : 结构紧凑 , 渲染高效 ; 缺 : 复杂模型需大量面片 , 内存消耗大 |
| 参数化曲面 | 数学参数方程 ( 如 NURBS ) | 高 | 极高 | 中 ( 需细分 ) | 高精度工业设计 | 汽车曲面设计 ( 特斯拉车身 ) 、飞机机翼 ( 波音787 ) | 优 : 数学精确 , 平滑连续 ; 缺 : 需转换为网格才能渲染 |
| 点云 | 无序三维点集合 | 高 | 低 | 低 | 原始扫描数据、快速环境感知 | 自动驾驶 ( 华为ADS激光雷达 ) 、文物扫描 ( 敦煌壁画三维化 ) | 优 : 采集直接 , 存储轻量 ; 缺 : 无拓扑关系 , 需后处理 |
| 神经辐射场(NeRF) | 神经网络隐式场 ( 密度+颜色 ) | 低 | 极低 | 极低 | 高保真静态场景重建 | 虚拟博物馆 ( 故宫数字展厅 ) 、电影级光照模拟 ( 《曼达洛人》虚拟拍摄 ) | 优 : 逼真视角合成 ; 缺 : 训练耗时 , 无法动态交互 |
| 高斯溅射 | 可微分高斯分布集合 | 中 | 中 | 极高 | 实时动态渲染、移动端轻量化 | AR导航 ( 苹果Vision Pro ) 、VR直播 ( Meta Quest 3 ) | 优 : 实时60FPS+渲染 ; 缺 : 高频细节可能丢失 |
| 体素 | 三维栅格 ( 立方体单元 ) | 低 | 中 | 中 | 体积分析、规则结构处理 | 医学影像 ( CT肿瘤分割 ) 、体素游戏 ( 《我的世界》地形生成 ) | 优 : 支持布尔运算 ; 缺 : 分辨率固定 , 高精度需求时内存爆炸 |
二、3D 生成大模型
1、现有的 成熟的 生成大模型
大模型 生成 文本 、 图像 、 声音 、 视频 等内容 , 这些内容的 表示方式 都是 统一的 , 如 :
- 文本 直接是 UTF-8 编码 ;
- 图像 使用 ARGB 或 YUV 方式编码 ;
- 声音 直接生成 PCM 采样数据 ;
- 视频 使用 H.264 进行压缩编码 ;
由于 表示方式统一 , 针对上述四种内容 的 生成大模型 已经出现很多种 , 有些已经很成熟 ;
2、3D 生成大模型 局限性
3D 模型的 表示方式不统一 是当前 3D 生成大模型 发展的核心瓶颈之一 ;
由于 不同表示方法 存在 数据结构、计算特性 和 信息密度 的本质差异 , 导致模型难以实现跨模态统一建模 ;
3D 模型 表示方式 多样性 的 局限 对 3D 生成大模型 的影响 :
- 训练数据碎片化 : 现有数据集如 ShapeNet 、Objaverse 包含混合格式 , 需分别 预处理数据 ;
- 生成质量瓶颈 : 体素 生成 受分辨率影响 , 导致细节模糊 ; 点云 生成 易产生孔洞 ;
- 跨模态转换损耗 : 不同表示间转换 引入误差 , 如 : 网格 转 体素 时曲面阶梯化 ;
- 统一架构设计困难 : 传统 Transformer 难以直接处理 非规则数据 , 如 : 点云、网格 数据 ;
3、多模态输入、输出
大模型 多模态 输入 / 输出 是指超大规模 AI 模型 同时接收并处理 多种类型数据 , 如 : 文本、图像、音频、视频等 的能力 ;
其核心是 通过统一架构实现跨模态信息融合 , 使 模型 能像 人类 一样综合理解复杂世界 ;
多模态输入 / 输出 有如下特点 :
- 多源感知 : 同时解析 语言 ( 文本序列 ) 、视觉 ( 像素矩阵 ) 、声音 ( 频谱图 ) 等数据 ;
- 跨模态对齐 : 建立 不同模态 间的语义关联 , 如 : 将 " 猫 " 的文本描述与喵叫声、猫的图像映射到同 一语义 ;
- 空间联合推理 : 综合 多模态 信息进行决策 , 如医疗诊断时结合CT影像 ( 图像 ) 和病历描述 ( 文本 )
接收 多模态输入 是 3D 生成大模型 的 基础 ;
4、3D 生成大模型 生成方式
3D 生成大模型 生成方式 :
- 显式生成 : 直接输出 点云 ( Point Cloud ) 、网格 ( Mesh ) 或体素 ( Voxel ) ;
- 隐式表示 : 通过 神经辐射场 ( NeRF ) 、符号距离函数 ( SDF ) 等 隐式方法 建模 3D 结构 ;
5、3D 生成大模型 举例说明
3D 大模型 举例 :
- Shap-E ( OpenAI ) : 从 文本 或 图像 生成 3D 模型,支持导出为网格或点云 ;
- Point-E : 基于扩散模型,快速生成点云形式的 3D 对象 ;
- NeRF ( Neural Radiance Fields ) : 通过 多视角 2D 图像 重建 高质量 3D 场景 ;
- DreamFusion : 利用 2D 扩散模型 ( 如 Stable Diffusion ) 优化 3D 模型生成 ( 无需 3D 训练数据 ) ;
三、3D 生成大模型 代码示例
1、从 Hugging Face 中查找 3D 生成大模型
到 Hugging Face 的 模型广场 https://huggingface.co/models 中 查找 3D 生成大模型 ;
- 选中 左侧的 " Text-to-3D " 标签 , 可以过滤出 根据 文本输入 生成 3D 模型的 大模型 ;
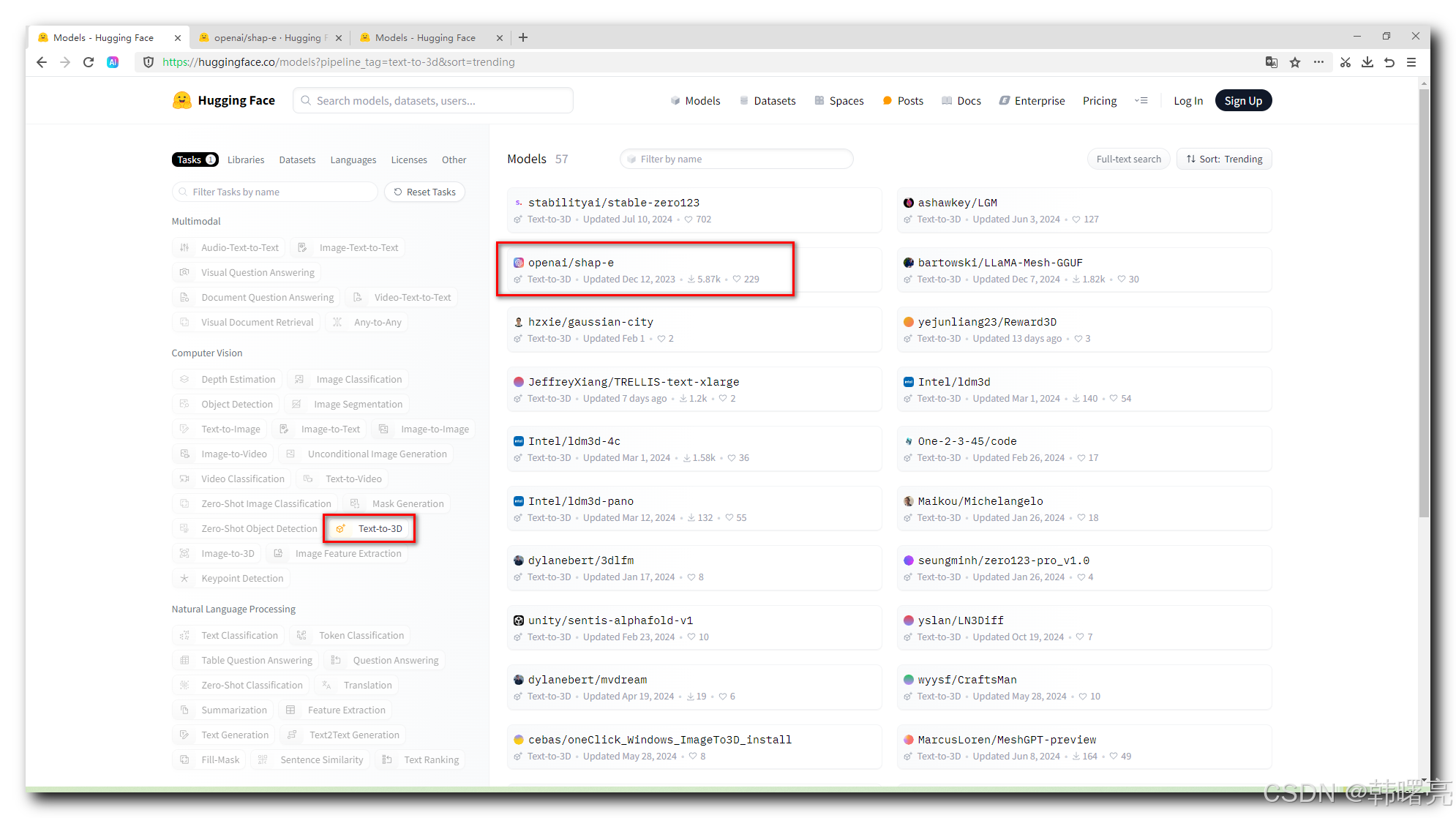
- 选中 左侧的 " Image-to-3D " 标签 , 可以过滤出 根据 二维图像输入 生成 3D 模型的 大模型 ;
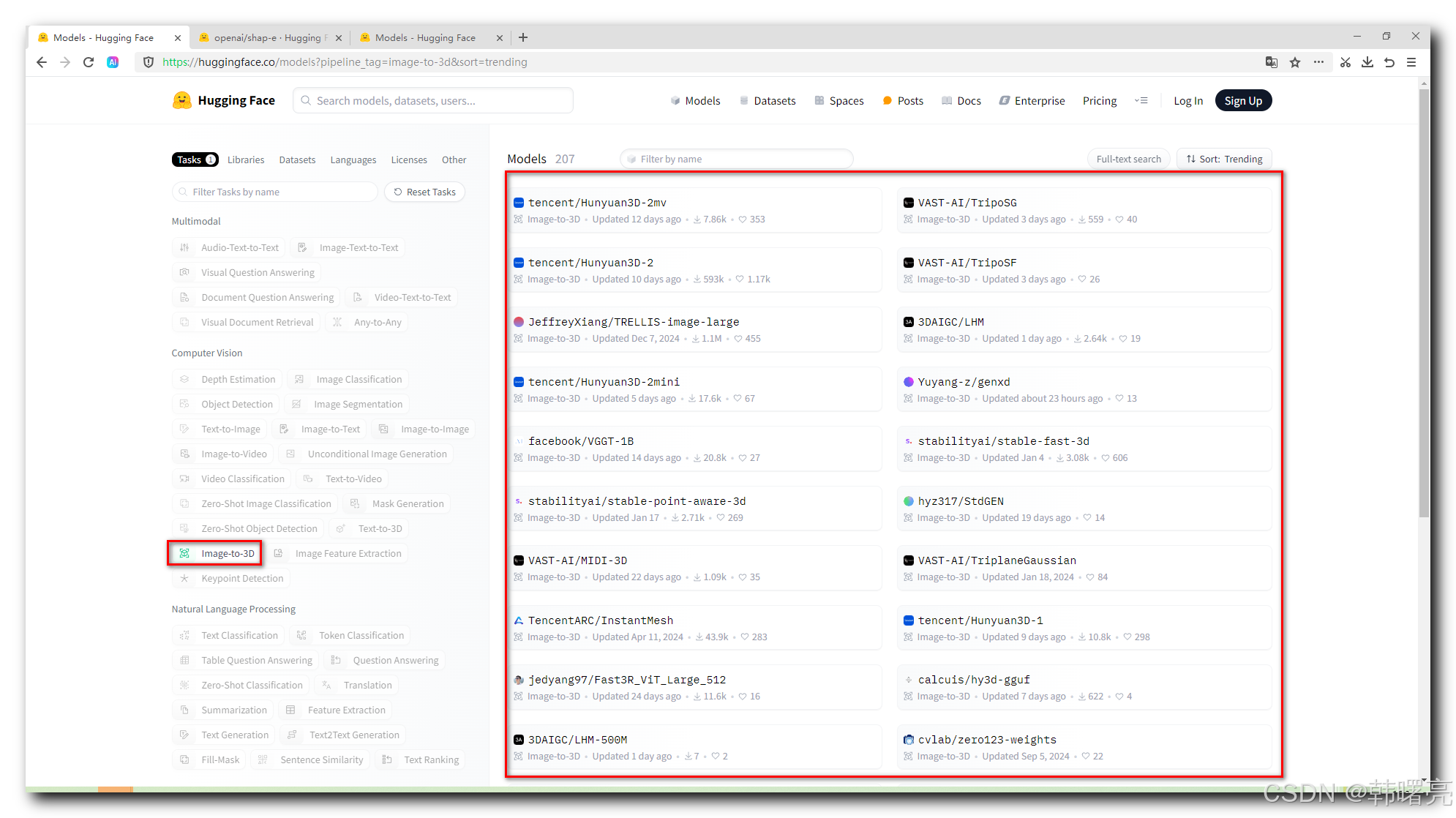
这里我们选择使用 openai/shap-e 大模型 生成 3D 模型 ;
2、openai/shap-e 大模型简介
进入到 Hugging Face 中的 openai/shap-e 大模型 的 页面 https://huggingface.co/openai/shap-e , 其中有完整的 模型使用介绍 ;
Shap-E 是由 OpenAI 开源 的 条件式 3D 生成模型 , 能够 直接从 文本描述 生成 高质量的 3D 物体 或 3D 场景 ;
与 传统 显式生成 方法不同 , Shap-E 通过 建模 隐式函数参数 , 支持生成 多模态 的 3D 表示 , 如 : 纹理网格 和 神经辐射场 , 在生成效率与质量上实现突破 ;
Shap-E 模型 核心技术 :
- 两阶段训练框架 :
- 阶段一 : 训练编码器将 3D 网格或点云 数据 , 编码为 隐式函数 ( 如 : 符号距离函数 SDF 或 神经辐射场 NeRF ) 的 参数 ;
- 阶段二 : 基于编码器输出的隐式参数 , 训练条件扩散模型 , 学习从文本到 3D 隐式表示的映射关系 ;
- 多表示输出 : 生成的 隐式函数 可 灵活渲染为纹理网格 ( Mesh ) 或 神经辐射场 ( NeRF ) , 兼顾工业应用需求 ( 如 3D 打印 ) 与高保真渲染效果 ;
OpenAI 公开了 模型权重 、 推理代码 及示例 , 开发者可通过 GitHub 仓库 ( https://github.com/openai/shap-e ) 快速体验文本到 3D 的生成流程 ;
3、openai/shap-e 大模型代码示例
安装下面一系列的 环境 工具 :
pip install torch torchvision torchaudio
pip install diffusers transformers
pip install trimesh # 用于可视化或导出 3D 网格
- torch : PyTorch 核心库 , 提供 动态计算图 、 GPU 加速 的张量计算和深度学习模型构建工具 ;
- torchvision : 配套的计算机视觉库 , 包含:
- 预训练模型 ( 如 ResNet、YOLO )
- 常用数据集 ( 如 MNIST、CIFAR-10 )
- 图像变换工具 ( 如裁剪、归一化 )
- torchaudio : 音频处理库 , 支持语音识别、音频信号处理等任务 , 用于 构建 和 训练 深度学习模型 ( 尤其是视觉和语音任务 ) ;
- diffusers : 专注于 扩散模型 ( Diffusion Models ) 的库 , 如 : Stable Diffusion , 支持图像、音频、3D 等多模态生成任务 , 提供预训练扩散模型和训练/推理接口 ;
- transformers ( Hugging Face ) : 预训练 自然语言处理模型 ( 如 BERT、GPT、T5 ) , 支持文本生成、翻译、分类等任务 , 也包含多模态模型 ( 如 : CLIP 、 Whisper ) ;
- trimesh : 轻量级 3D 网格 ( Mesh ) 和点云处理工具 , 支持 OBJ、STL、PLY 等格式 , 可实现 网格简化、法线计算、布尔运算、可视化 等功能 ;
完整代码示例 :
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
# 导入PyTorch深度学习框架(用于张量计算和GPU加速)
import torch
# 从Diffusers库导入Shap-E模型管道(专用于3D生成的预训练模型)
from diffusers import ShapEPipeline
# 导入用于导出3D模型到PLY格式的工具函数
from diffusers.utils import export_to_ply
# 检查GPU可用性并分配设备(优先使用CUDA加速)
# torch.cuda.is_available() 会检测系统是否支持NVIDIA GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
##############################################################################
# 加载OpenAI开源的Shap-E预训练模型(约2.3GB,首次运行需下载)
# - from_pretrained() 会自动下载模型权重和配置文件
# - to(device) 将模型加载到GPU/CPU显存中
# 注意:模型加载可能需要1-3分钟,取决于网络速度和硬件性能
##############################################################################
pipe = ShapEPipeline.from_pretrained("openai/shap-e").to(device)
# 定义文本提示词(描述想要生成的3D对象)
# Shap-E是基于文本到3D的生成模型,支持自然语言描述
prompt = "a chair that looks like an avocado" # "一个看起来像牛油果的椅子"
# 设置生成参数
guidance_scale = 15.0 # 指导系数:值越大越遵循文本描述,但可能降低多样性(建议范围7-15)
num_inference_steps = 64 # 扩散模型去噪步数:步数越多细节越好,但耗时增加(默认64)
##############################################################################
# 执行3D模型生成(核心步骤)
# 原理:Shap-E使用扩散模型逐步将随机噪声转化为符合文本描述的3D表示
# - output_type="mesh" 表示直接输出网格模型(包含顶点和面信息)
# - 也可选"latent"获取隐式表示,需后续解码
# 返回值images包含生成的3D数据(此处为网格列表)
##############################################################################
images = pipe(
prompt, # 输入的文本描述
guidance_scale=guidance_scale, # 控制文本引导强度
num_inference_steps=num_inference_steps, # 生成迭代次数
output_type="mesh", # 输出类型:网格模型(或latent隐变量)
).images # 提取生成的3D对象列表
# 获取第一个生成的3D网格(如果批量生成会有多个结果)
mesh = images[0]
##############################################################################
# 导出为PLY文件(标准3D模型格式,支持Blender/Maya等软件)
# - 第一个参数:网格数据(包含vertices顶点和faces三角面信息)
# - 第二个参数:输出文件路径
# 文件内容包含:
# - 顶点坐标(x,y,z)
# - 三角面片索引(定义如何连接顶点构成表面)
##############################################################################
export_to_ply(mesh, "avocado_chair.ply")
# 打印完成提示(建议检查文件大小,正常应大于100KB)
print("3D 模型已保存为 avocado_chair.ply!")
代码解析 :
- 模型加载 : 使用 ShapEPipeline 加载 OpenAI 开源的 Shap-E 模型 , 支持从文本生成 3D 网格(Mesh)或点云 ; 需要较高显存(建议使用 GPU) , 若显存不足可调整 batch_size=1 ;
- 生成参数 :
- guidance_scale 参数 : 控制生成结果的多样性与质量(值越高,越贴近文本描述,但可能过拟合)。
- num_inference_steps 参数 : 扩散模型的生成步数,影响细节和速度。
- 输出格式 :
- 选择 output_type=“mesh” 可直接导出网格模型,output_type=“latent” 则输出隐式表示 ( 需进一步解码 ) ;
- 使用 export_to_ply 将生成的网格保存为 .ply 文件,可用 Blender、MeshLab 等工具打开 ;
执行结果 : 下载时间太长了 , 这里就不等了 ;
从 Hugging Face 中下载的 Shap-E 大模型 在 C:\Users\octop.cache\huggingface\hub\models–openai–shap-e 目录中存放 ;
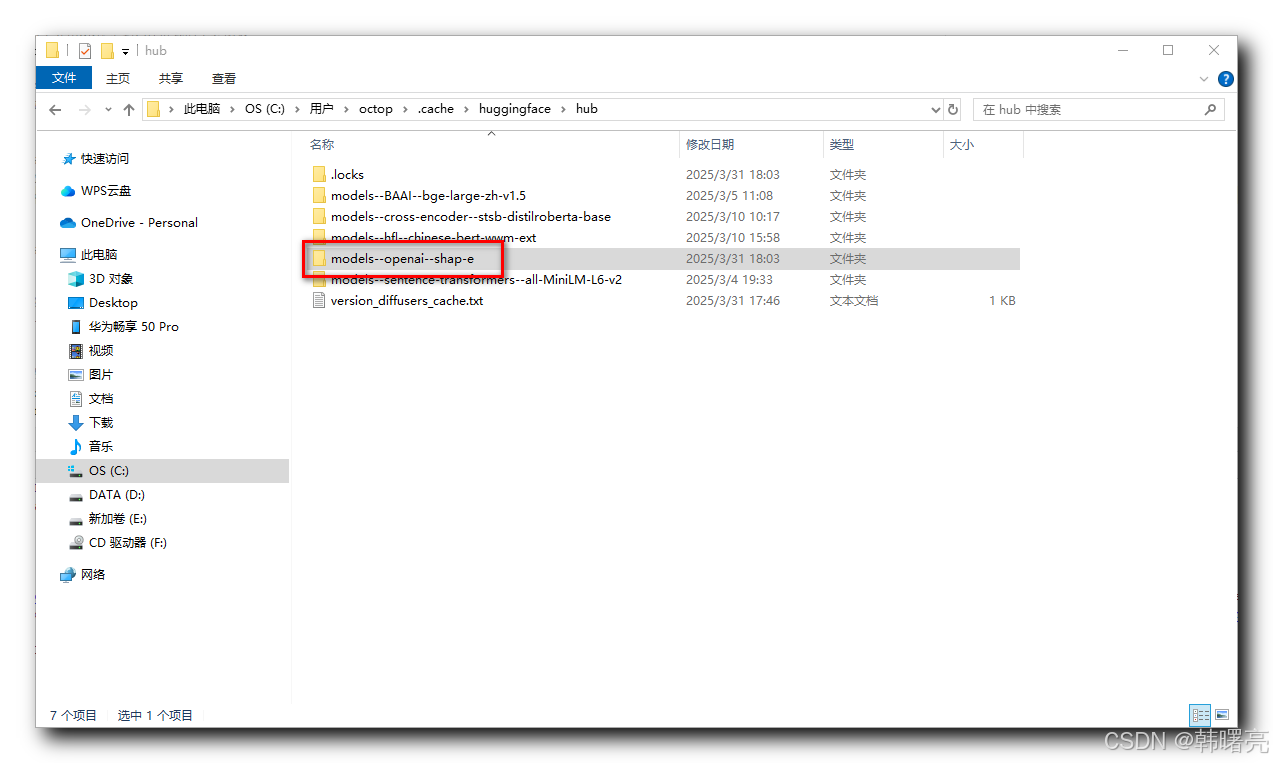
该模型大小为 2.2 GB ;
