《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
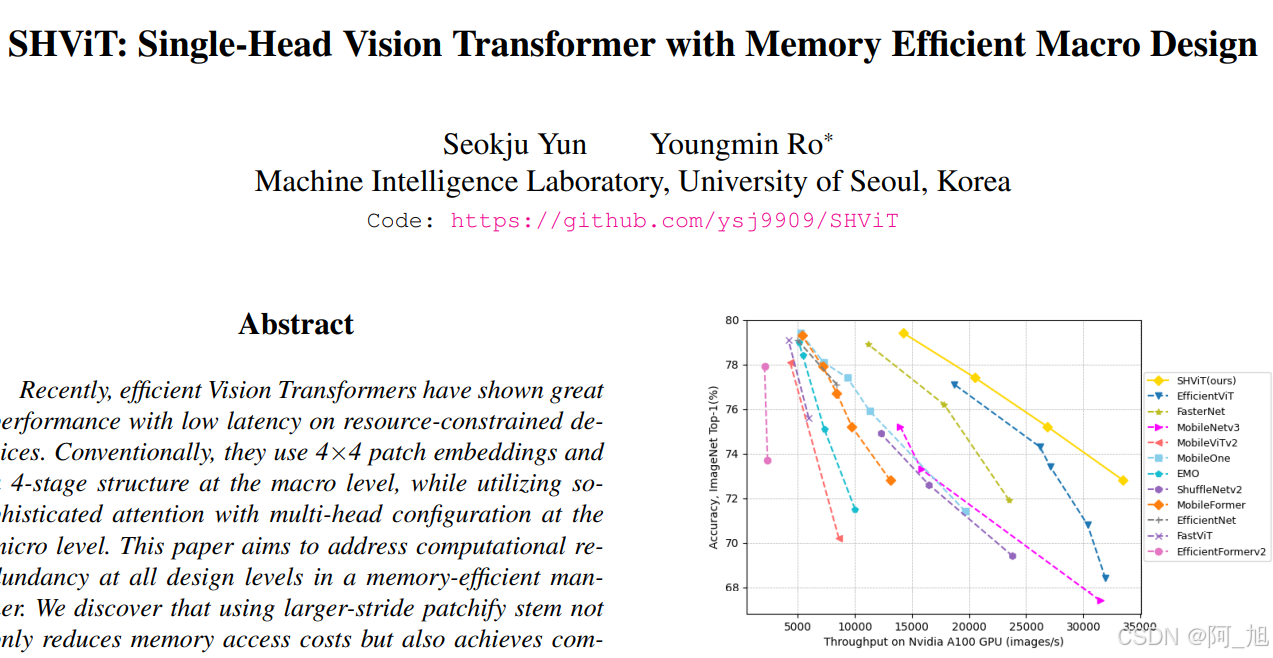
论文地址:https://arxiv.org/pdf/2401.16456
代码地址:https://github.com/ysj9909/SHViT
创新点
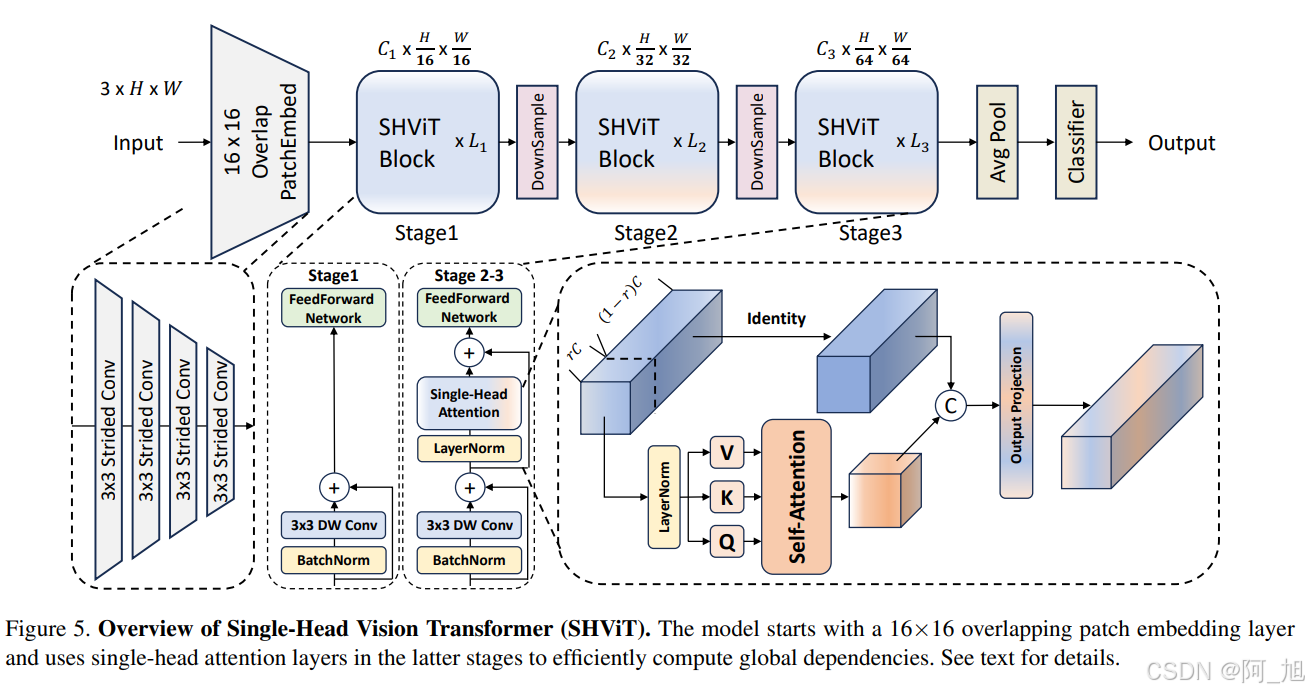
- 内存高效的宏观设计:文章提出了一种新的宏观设计,使用更大的步幅(16x16)进行patch embedding,并采用3阶段结构,减少了早期阶段的空间冗余,从而降低了内存访问成本。
- 单头注意力机制(SHSA):提出了一种单头自注意力模块,避免了多头注意力机制中的冗余,同时通过并行结合全局和局部信息来提升准确性。
- 综合性能优化:通过结合上述设计,提出了SHViT(单头视觉Transformer),在多种设备上实现了速度和准确性的最佳平衡。
方法
- 宏观设计分析:通过实验分析了传统4x4 patch embedding和4阶段结构的冗余,发现使用16x16 patch embedding和3阶段设计可以在减少计算成本的同时保持性能。
- 微观设计分析:深入研究了多头自注意力机制(MHSA)中的冗余,发现多头机制在后期的冗余尤为明显,提出了单头自注意力模块(SHSA)来替代。
- SHViT架构:基于上述分析,提出了SHViT架构,包括四个3x3步幅卷积层、三个阶段的SHViT块(包含深度卷积、SHSA和FFN模块),以及高效的降采样层。
SHSA模块的作用
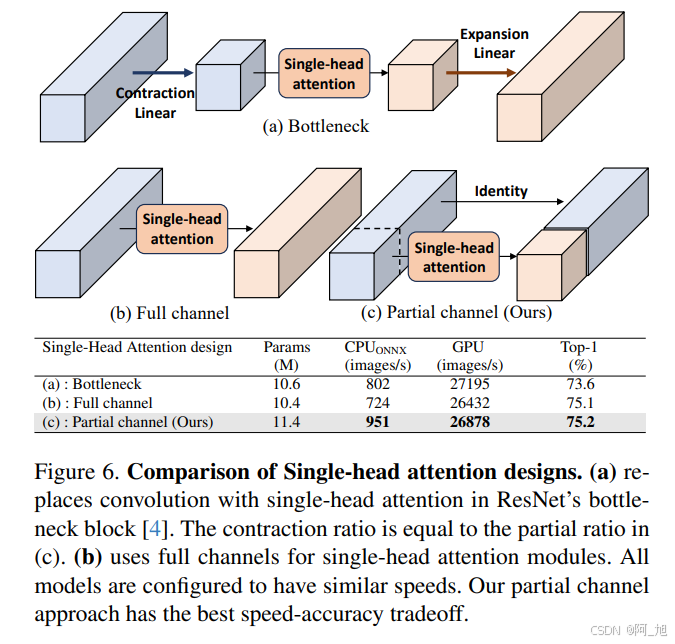
- 减少计算冗余:SHSA模块仅对输入通道的一部分应用单头自注意力,避免了多头机制中的计算冗余。
- 降低内存访问成本:通过处理部分通道,减少了内存访问成本,使得模型在GPU和CPU上能够更高效地运行。
- 提升性能:SHSA模块通过并行结合全局和局部信息,提升了模型的准确性,同时允许在相同的计算预算下堆叠更多的块,进一步提升了性能。
源码与注释
import torch
class GroupNorm(torch.nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1):
super().__init__()
# 添加卷积层
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
# 添加批量归一化层
self.add_module('bn', torch.nn.BatchNorm2d(b))
# 初始化批量归一化层的权重和偏置
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
# 融合卷积层和批量归一化层
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups,
device=c.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class SHSA(torch.nn.Module):
"""Single-Head Self-Attention"""
def __init__(self, dim, qk_dim=16, pdim=32):
super().__init__()
# 计算缩放因子
self.scale = qk_dim ** -0.5
self.qk_dim = qk_dim
self.dim = dim
self.pdim = pdim
# 添加预归一化层
self.pre_norm = GroupNorm(pdim)
# 添加卷积层用于生成查询、键和值
self.qkv = Conv2d_BN(pdim, qk_dim * 2 + pdim)
# 添加投影层
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
dim, dim, bn_weight_init=0))
def forward(self, x):
B, C, H, W = x.shape
# 将输入张量按通道维度拆分为两部分
x1, x2 = torch.split(x, [self.pdim, self.dim - self.pdim], dim=1)
# 对第一部分应用预归一化
x1 = self.pre_norm(x1)
# 生成查询、键和值
qkv = self.qkv(x1)
q, k, v = qkv.split([self.qk_dim, self.qk_dim, self.pdim], dim=1)
q, k, v = q.flatten(2), k.flatten(2), v.flatten(2)
# 计算注意力分数
attn = (q.transpose(-2, -1) @ k) * self.scale
# 应用softmax函数
attn = attn.softmax(dim=-1)
# 计算加权和
x1 = (v @ attn.transpose(-2, -1)).reshape(B, self.pdim, H, W)
# 将加权和与未处理的部分拼接并应用投影层
x = self.proj(torch.cat([x1, x2], dim=1))
return x
if __name__ == '__main__':
# 创建SHSA模块实例
block = SHSA(64) # 输入通道数C
# 创建随机输入张量
input = torch.randn(1, 64, 32, 32) # 输入形状为[B, C, H, W]
# 打印输入张量的形状
print(input.size())
# 通过SHSA模块进行前向传播
output = block(input)
# 打印输出张量的形状
print(output.size())
总结
文章通过系统分析现有设计中的冗余,提出了内存高效的宏观设计和单头自注意力模块,构建了SHViT模型,在多种设备上实现了速度和准确性的最佳平衡。SHSA模块通过减少计算冗余和内存访问成本,提升了模型的性能和效率。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!