前言
随着人工智能技术的飞速发展,图像识别技术在各个领域得到了广泛应用。数字表计识别作为图像识别的一个重要分支,在电力、水利、交通等领域具有广泛的应用前景。PaddleOCR是一个基于深度学习的开源OCR工具,它能够高效地识别图像中的文字信息。本文将详细介绍使用PaddleOCR进行数字表计识别的全套流程,包括环境配置、数据集制作、模型训练和推理等环节。通过本文的介绍,读者可以全面了解PaddleOCR在数字表计识别领域的应用,掌握从环境配置到模型训练和推理的全套流程。希望本文能够为从事数字表计识别相关工作的研究人员和工程师提供有益的参考和借鉴。
一、PaddleOCR介绍
PaddleOCR是一个基于深度学习的开源OCR(Optical Character Recognition,光学字符识别)工具,由百度公司开发并维护。它能够识别图像中的文字信息,广泛应用于各种场景,如文档扫描、车牌识别、表单处理等。PaddleOCR基于PaddlePaddle深度学习框架,提供了丰富的预训练模型和易于使用的API,使得用户可以轻松地进行文本检测、识别和端到端的OCR任务。
PaddleOCR的主要特点包括:
- 高性能:PaddleOCR利用深度学习技术,能够高效地识别各种复杂场景下的文字信息。
- 易用性:提供了详细的文档和教程,用户可以快速上手,进行模型训练和推理。
- 可定制性:用户可以根据自己的需求,对模型进行微调,以适应不同的应用场景。
- 多平台支持:PaddleOCR支持多种操作系统,包括Windows、Linux和macOS,也支持在服务器和移动设备上部署。
- 丰富的预训练模型:提供了多种预训练模型,包括通用场景、场景文字、手写文字等,用户可以根据需要选择合适的模型。
- 端到端解决方案:PaddleOCR不仅提供了文本检测和识别的独立模块,还提供了端到端的OCR解决方案,简化了开发流程。
- 社区支持:作为一个开源项目,PaddleOCR拥有活跃的社区,用户可以获取社区支持,分享经验和解决方案。
二、环境安装:
1.创建激活虚拟环境
conda create -n paddleocr python=3.9
2.安装paddlepaddle-gpu
python -m pip install paddlepaddle-gpu==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
注意cuda版本一定要与paddle对上,不然后续训练会报错,cuda版本更新点击:
3.安装 paddleocr
pip install paddleocr
三、数据集制作:
1 .PPOCRLabel安装打开:
pip install PPOCRLabel # 安装
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
2.打开文件夹:在菜单栏点击 “文件” - “打开目录” 选择待标记图片的文件夹.

3.手动标注:点击 “矩形标注”(推荐直接在英文模式下点击键盘中的 “W”),用户可对当前图片中模型未检出的部分进行手动绘制标记框。点击键盘Q,则使用四点标注模式(或点击“编辑” - “四点标注”),用户依次点击4个点后,双击左键表示标注完成。
4. 标记框绘制完成后,用户点击 “确认”,检测框会先被预分配一个 “待识别” 标签。
5. 重新识别:将图片中的所有检测画绘制/调整完成后,点击 “重新识别”,PP-OCR模型会对当前图片中的所有检测框重新识别[3]。
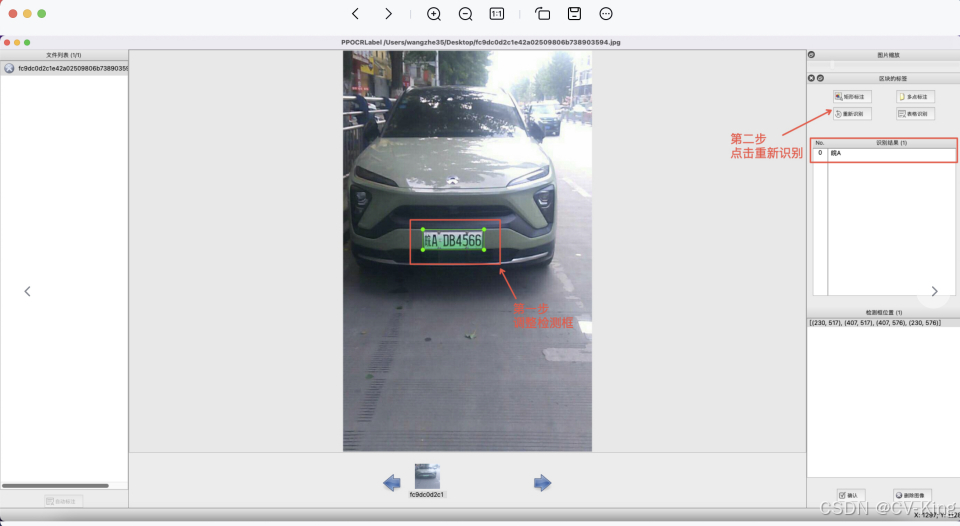
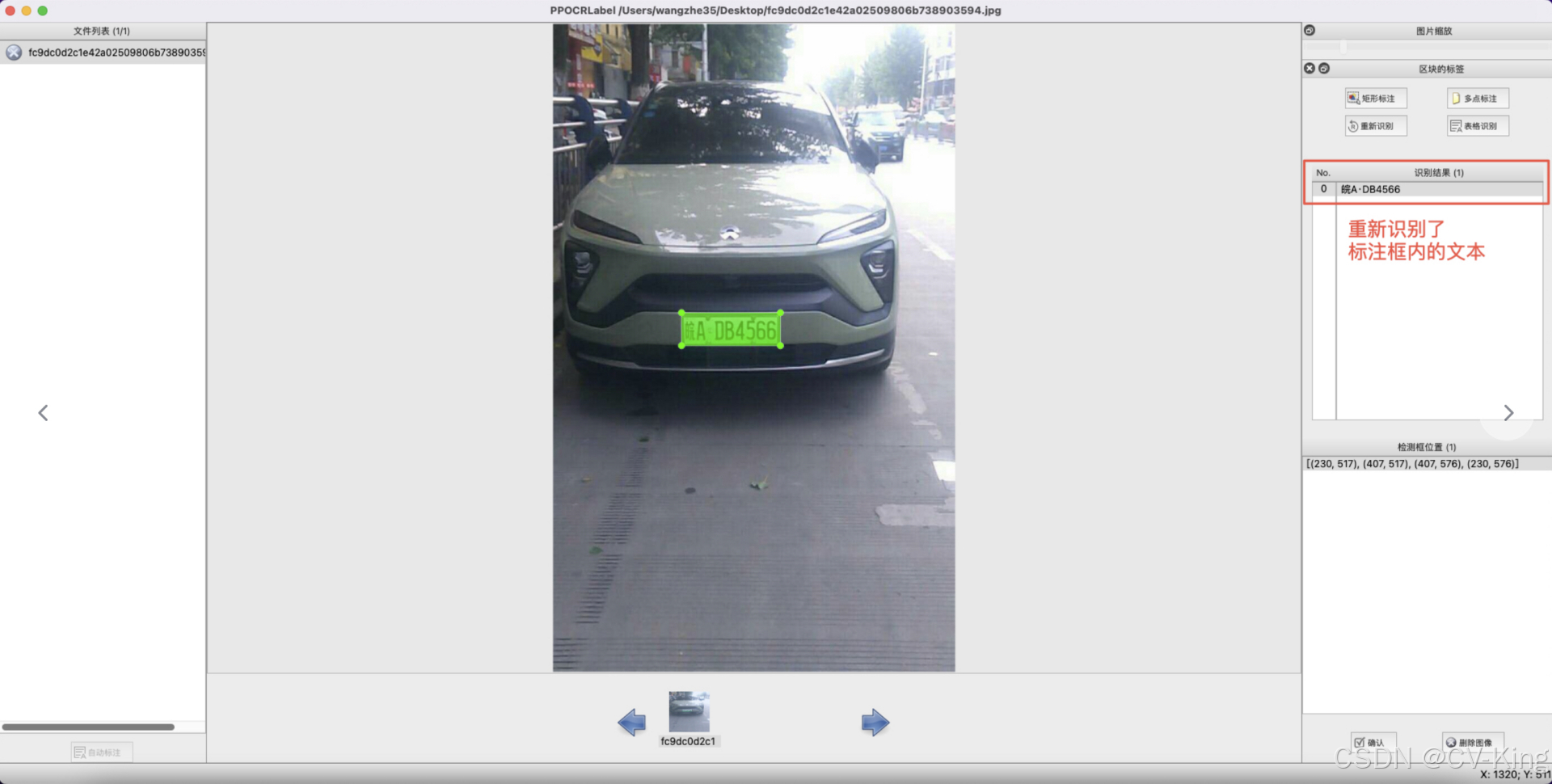 6 内容更改:单击识别结果,对不准确的识别结果进行手动更改。
6 内容更改:单击识别结果,对不准确的识别结果进行手动更改。
7. 确认标记:点击 “确认”,图片状态切换为 “√”,跳转至下一张。
8. 导出结果:用户可以通过菜单中“文件-导出标记结果”手动导出,同时也可以点击“文件 - 自动导出标记结果”开启自动导出。手动确认过的标记将会被存放在所打开图片文件夹下的Label.txt中。在菜单栏点击 “文件” - "导出识别结果"后,会将此类图片的识别训练数据保存在crop_img文件夹下,识别标签保存在rec_gt.txt中。
注意事项:
PPOCRLabel以文件夹为基本标记单位,打开待标记的图片文件夹后,不会在窗口栏中显示图片,而是在点击 “选择文件夹” 之后直接将文件夹下的图片导入到程序中。
图片状态表示本张图片用户是否手动保存过,未手动保存过即为 “X”,手动保存过为 “√”。点击 “自动标注”按钮后,PPOCRLabel不会对状态为 “√” 的图片重新标注。
点击“重新识别”后,模型会对图片中的识别结果进行覆盖。因此如果在此之前手动更改过识别结果,有可能在重新识别后产生变动。
PPOCRLabel产生的文件放置于标记图片文件夹下,包括以下几种,请勿手动更改其中内容,否则会引起程序出现异常。

数据标注好之后,执行下面代码进行数据集划分:
# coding:utf8
import os
import shutil
import random
import argparse
# 删除划分的训练集、验证集、测试集文件夹,重新创建一个空的文件夹
def isCreateOrDeleteFolder(path, flag):
flagPath = os.path.join(path, flag)
if os.path.exists(flagPath):
shutil.rmtree(flagPath)
os.makedirs(flagPath)
flagAbsPath = os.path.abspath(flagPath)
return flagAbsPath
def splitTrainVal(root, absTrainRootPath, absValRootPath, absTestRootPath, trainTxt, valTxt, testTxt, flag):
# 按照指定的比例划分训练集、验证集、测试集
dataAbsPath = os.path.abspath(root)
if flag == "det":
labelFilePath = os.path.join(dataAbsPath, args.detLabelFileName)
elif flag == "rec":
labelFilePath = os.path.join(dataAbsPath, args.recLabelFileName)
labelFileRead = open(labelFilePath, "r", encoding="UTF-8")
labelFileContent = labelFileRead.readlines()
random.shuffle(labelFileContent)
labelRecordLen = len(labelFileContent)
for index, labelRecordInfo in enumerate(labelFileContent):
imageRelativePath = labelRecordInfo.split('\t')[0]
imageLabel = labelRecordInfo.split('\t')[1]
imageName = os.path.basename(imageRelativePath)
if flag == "det":
imagePath = os.path.join(dataAbsPath, imageName)
elif flag == "rec":
imagePath = os.path.join(dataAbsPath, "{}\\{}".format(args.recImageDirName, imageName))
# 按预设的比例划分训练集、验证集、测试集
trainValTestRatio = args.trainValTestRatio.split(":")
trainRatio = eval(trainValTestRatio[0]) / 10
valRatio = trainRatio + eval(trainValTestRatio[1]) / 10
curRatio = index / labelRecordLen
if curRatio < trainRatio:
imageCopyPath = os.path.join(absTrainRootPath, imageName)
shutil.copy(imagePath, imageCopyPath)
trainTxt.write("{}\t{}".format(imageCopyPath, imageLabel))
elif curRatio >= trainRatio and curRatio < valRatio:
imageCopyPath = os.path.join(absValRootPath, imageName)
shutil.copy(imagePath, imageCopyPath)
valTxt.write("{}\t{}".format(imageCopyPath, imageLabel))
else:
imageCopyPath = os.path.join(absTestRootPath, imageName)
shutil.copy(imagePath, imageCopyPath)
testTxt.write("{}\t{}".format(imageCopyPath, imageLabel))
# 删掉存在的文件
def removeFile(path):
if os.path.exists(path):
os.remove(path)
def genDetRecTrainVal(args):
detAbsTrainRootPath = isCreateOrDeleteFolder(args.detRootPath, "train")
detAbsValRootPath = isCreateOrDeleteFolder(args.detRootPath, "val")
detAbsTestRootPath = isCreateOrDeleteFolder(args.detRootPath, "test")
recAbsTrainRootPath = isCreateOrDeleteFolder(args.recRootPath, "train")
recAbsValRootPath = isCreateOrDeleteFolder(args.recRootPath, "val")
recAbsTestRootPath = isCreateOrDeleteFolder(args.recRootPath, "test")
removeFile(os.path.join(args.detRootPath, "train.txt"))
removeFile(os.path.join(args.detRootPath, "val.txt"))
removeFile(os.path.join(args.detRootPath, "test.txt"))
removeFile(os.path.join(args.recRootPath, "train.txt"))
removeFile(os.path.join(args.recRootPath, "val.txt"))
removeFile(os.path.join(args.recRootPath, "test.txt"))
detTrainTxt = open(os.path.join(args.detRootPath, "train.txt"), "a", encoding="UTF-8")
detValTxt = open(os.path.join(args.detRootPath, "val.txt"), "a", encoding="UTF-8")
detTestTxt = open(os.path.join(args.detRootPath, "test.txt"), "a", encoding="UTF-8")
recTrainTxt = open(os.path.join(args.recRootPath, "train.txt"), "a", encoding="UTF-8")
recValTxt = open(os.path.join(args.recRootPath, "val.txt"), "a", encoding="UTF-8")
recTestTxt = open(os.path.join(args.recRootPath, "test.txt"), "a", encoding="UTF-8")
splitTrainVal(args.datasetRootPath, detAbsTrainRootPath, detAbsValRootPath, detAbsTestRootPath, detTrainTxt, detValTxt,
detTestTxt, "det")
for root, dirs, files in os.walk(args.datasetRootPath):
for dir in dirs:
if dir == 'crop_img':
splitTrainVal(root, recAbsTrainRootPath, recAbsValRootPath, recAbsTestRootPath, recTrainTxt, recValTxt,
recTestTxt, "rec")
else:
continue
break
if __name__ == "__main__":
# 功能描述:分别划分检测和识别的训练集、验证集、测试集
# 说明:可以根据自己的路径和需求调整参数,图像数据往往多人合作分批标注,每一批图像数据放在一个文件夹内用PPOCRLabel进行标注,
# 如此会有多个标注好的图像文件夹汇总并划分训练集、验证集、测试集的需求
parser = argparse.ArgumentParser()
parser.add_argument(
"--trainValTestRatio",
type=str,
default="6:2:2",
help="ratio of trainset:valset:testset")
parser.add_argument(
"--datasetRootPath",
type=str,
default="../train_data/",
help="path to the dataset marked by ppocrlabel, E.g, dataset folder named 1,2,3..."
)
parser.add_argument(
"--detRootPath",
type=str,
default="../train_data/det",
help="the path where the divided detection dataset is placed")
parser.add_argument(
"--recRootPath",
type=str,
default="../train_data/rec",
help="the path where the divided recognition dataset is placed"
)
parser.add_argument(
"--detLabelFileName",
type=str,
default="Label.txt",
help="the name of the detection annotation file")
parser.add_argument(
"--recLabelFileName",
type=str,
default="rec_gt.txt",
help="the name of the recognition annotation file"
)
parser.add_argument(
"--recImageDirName",
type=str,
default="crop_img",
help="the name of the folder where the cropped recognition dataset is located"
)
args = parser.parse_args()
genDetRecTrainVal(args)
注意:代码使用的时候需要在路径下创建det,和rec两个文件下用来分别保存检测与识别的结果。
四、字符检测训练:
修改yml文件的路径batchsize,学习率以及预训练模型路径::
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 20
save_model_dir: ./output/ch_PP-OCRv4
save_epoch_step: 50
eval_batch_step:
- 0
- 1000
cal_metric_during_train: false
checkpoints: null
pretrained_model: null
save_inference_dir: null
use_visualdl: false
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./checkpoints/det_db/predicts_db.txt
distributed: true
Architecture:
name: DistillationModel
algorithm: Distillation
model_type: det
Models:
Student:
model_type: det
algorithm: DB
Transform: null
Backbone:
name: PPLCNetV3
scale: 0.75
pretrained: false
det: true
Neck:
name: RSEFPN
out_channels: 96
shortcut: true
Head:
name: DBHead
k: 50
Student2:
pretrained: null
model_type: det
algorithm: DB
Transform: null
Backbone:
name: PPLCNetV3
scale: 0.75
pretrained: true
det: true
Neck:
name: RSEFPN
out_channels: 96
shortcut: true
Head:
name: DBHead
k: 50
Teacher:
pretrained: /home/build/下载/ch_PP-OCRv4_det_train/best_accuracy.pdparams
freeze_params: true
return_all_feats: false
model_type: det
algorithm: DB
Backbone:
name: ResNet_vd
in_channels: 3
layers: 50
Neck:
name: LKPAN
out_channels: 256
Head:
name: DBHead
kernel_list:
- 7
- 2
- 2
k: 50
Loss:
name: CombinedLoss
loss_config_list:
- DistillationDilaDBLoss:
weight: 1.0
model_name_pairs:
- - Student
- Teacher
- - Student2
- Teacher
key: maps
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
- DistillationDMLLoss:
model_name_pairs:
- Student
- Student2
maps_name: thrink_maps
weight: 1.0
key: maps
- DistillationDBLoss:
weight: 1.0
model_name_list:
- Student
- Student2
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 2
regularizer:
name: L2
factor: 5.0e-05
PostProcess:
name: DistillationDBPostProcess
model_name:
- Student
key: head_out
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DistillationMetric
base_metric_name: DetMetric
main_indicator: hmean
key: Student
Train:
dataset:
name: SimpleDataSet
data_dir: /home/build/test/det/
label_file_list:
- /home/build/test/det/train.txt
ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- IaaAugment:
augmenter_args:
- type: Fliplr
args:
p: 0.5
- type: Affine
args:
rotate:
- -10
- 10
- type: Resize
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 640
- 640
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
total_epoch: 500
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
total_epoch: 500
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 2
num_workers: 1
Eval:
dataset:
name: SimpleDataSet
data_dir: /home/build/test/det/
label_file_list:
- /home/build/test/det/test.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- DetResizeForTest:
limit_side_len: 960
limit_type: max
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- shape
- polys
- ignore_tags
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2
profiler_options: null
修改好yml文件后执行下面代码开始训练:
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
五、字符识别训练:
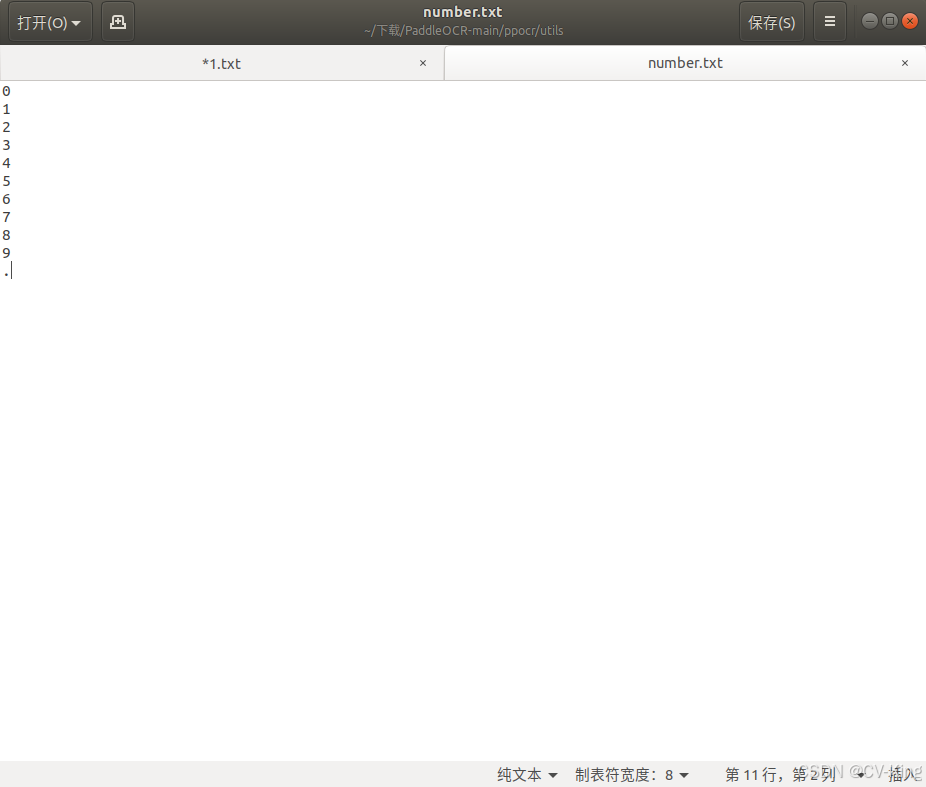
与检测不同的事是,字符识别最后需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。因此字典需要包含所有希望被正确识别的字符,本次项目为数显表读数识别,故内容为
修改yaml文件的路径batchsize,学习率以及预训练模型路径:
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/rec_ppocr_v4
save_epoch_step: 10
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: /home/build/下载/ch_PP-OCRv4_rec_train/student
checkpoints:
save_inference_dir:
use_visualdl: false
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/number.txt
max_text_length: &max_text_length 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR_LCNet
Transform:
Backbone:
name: PPLCNetV3
scale: 0.95
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 120
depth: 2
hidden_dims: 120
kernel_size: [1, 3]
use_guide: True
Head:
fc_decay: 0.00001
- NRTRHead:
nrtr_dim: 384
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- NRTRLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: MultiScaleDataSet
ds_width: false
data_dir: /home/build/test/rec/train/
ext_op_transform_idx: 1
label_file_list:
- /home/build/test/rec/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales: [[320, 32], [320, 48], [320, 64]]
first_bs: &bs 16
fix_bs: false
divided_factor: [8, 16] # w, h
is_training: True
loader:
shuffle: true
batch_size_per_card: *bs
drop_last: true
num_workers: 1
Eval:
dataset:
name: SimpleDataSet
data_dir: /home/build/test/rec/test/
label_file_list:
- /home/build/test/rec/test.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 64
num_workers: 1
运行下面代码开始训练:
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
如果有两块及以上显卡执行下面内容:
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
六、模型推理:
在训练好模型之后执行下面代码进行模型推理,识别执行infer_rec.py,检测执行infer_det.py,修改相应的yml路径以及刚才训练好的模型地址。
python3 tools/infer_rec.py -c /home/build/下载/PaddleOCR-main/configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=/home/build/下载/PaddleOCR-main/output/rec_ppocr_v4/latest Global.infer_img=/home/build/test/rec/val/1.jpg