生成式AI的快速发展使得DeepSeek-R1等强大的公开大语言模型成为创新前沿。目前,DeepSeek-R模型已通过Amazon Bedrock Marketplace和Amazon SageMaker JumpStart在亚马逊云科技开放访问,其轻量化版本也可通过Amazon Bedrock Custom Model Import获取。据深度求索公司介绍,这些模型在推理、编码和自然语言理解方面表现优异。但与其他所有模型一样,在生产环境中部署时仍需谨慎考虑数据隐私要求、合理管理输出偏差,并建立可靠的监控与管控机制。
通过本文,你将掌握在保持严格安全控制、促进AI伦理实践的同时,充分发挥DeepSeek模型高级能力的方法。无论是开发面向客户的生成式AI应用还是内部工具,这些实施方案都能帮助你满足安全、负责任的AI要求。遵循这一循序渐进的方法,企业可按照AI安全最佳实践部署DeepSeek-R1等开放权重大语言模型。
DeepSeek模型及在Amazon Bedrock上的部署
深度求索作为专注开放权重基础AI模型的公司,近期推出了DeepSeek-R1系列模型。根据其技术论文显示,该系列模型在行业基准测试中展现出卓越的推理能力和性能表现。第三方评估数据表明,这些模型在质量指数、科学推理与知识、定量推理及编程等多项指标上持续保持前三的排名优势。
Amazon Bedrock提供全面的安全功能,既能保障开源和开放权重模型的托管与运行安全,又能确保数据隐私和合规性。主要特性包括静态和传输中的数据加密、细粒度访问控制、安全连接选项以及多项合规认证。此外,Amazon Bedrock 还提供内容过滤和敏感信息保护等防护措施,以支持负责任的AI使用。亚马逊云科技通过覆盖全平台的安全与合规措施进一步强化这些能力:
• 通过Amazon密钥管理服务(KMS)实现静态及传输中数据加密
• 采用Amazon身份与访问管理(IAM)进行权限管控
• 依托Amazon虚拟私有云(VPC)部署、VPC终端节点及支持TLS检测与严格策略规则的Amazon网络防火墙保障网络安全
• 通过服务控制策略(SCP)实现Amazon账户级治理
• 运用安全组与网络访问控制列表(NACL)实施访问限制
• 持有HIPAA、SOC、ISO及GDPR等合规认证
• Amazon Bedrock在Amazon GovCloud(美西)区域获得FedRAMP High授权
• 通过Amazon CloudWatch与Amazon CloudTrail实现监控审计
企业在生产环境部署时,应根据具体合规与安全需求定制这些安全配置。Amazon对所有模型容器执行漏洞扫描作为安全流程环节,并仅接受Safetensors格式的模型文件以防范不安全代码执行。
Amazon Bedrock Guardrails
Amazon Bedrock Guardrails提供可配置的防护措施,帮助安全地构建大规模生成式AI应用。该防护栏功能可与Amazon Bedrock的其他工具集成,从而构建更安全、更可靠且符合负责任AI政策的生成式AI应用。
核心功能
Amazon Bedrock Guardrails可通过两种方式使用。首先,它可以直接集成到 InvokeModel 和 Converse API 调用中,在推理过程中对输入提示词和模型输出同时应用防护措施。此方法适用于通过 Amazon Bedrock Marketplace和Amazon Bedrock Custom Model Import托管的模型。其次,ApplyGuardrail API提供了更灵活的方式,可独立评估内容而无需调用模型。第二种方法适用于在应用程序不同阶段评估输入或输出内容,并能与 Amazon Bedrock之外的自定义或第三方模型配合使用。这两种方式都能让开发者根据具体用例实施定制化防护措施,确保生成式 AI 应用中的交互既安全合规,又符合负责任AI 政策要求。
Amazon Bedrock Guardrails 核心防护策略
Amazon Bedrock Guardrails提供以下可配置的防护策略,助力安全构建大规模生成式 AI应用:
1. 内容过滤:可调节有害内容过滤强度;可预定义分类,如仇恨言论、侮辱性内容、色情内容、暴力内容、不当行为及提示词攻击;支持多模态内容过滤。
2. 主题过滤:支持限制特定主题;防止查询及响应中出现未授权主题。
3. 关键词过滤:拦截特定词汇、短语及不当用语;支持自定义过滤器。
- 敏感信息过滤:阻止或脱敏个人身份信息;支持自定义正则表达式匹配规则;基于概率检测标准格式。
- 上下文关联性检查:通过来源追溯检测幻觉内容;验证查询相关性。
- 自动推理检查:预防模型幻觉生成。
其他功能
模型无关实现方案:
• 兼容所有Amazon Bedrock基础模型
• 支持微调后的定制模型
• 通过ApplyGuardrail API可扩展至外部自定义及第三方模型
该综合框架帮助客户践行负责任AI原则,确保各类生成式AI应用中的内容安全与用户隐私保护。
解决方案概览
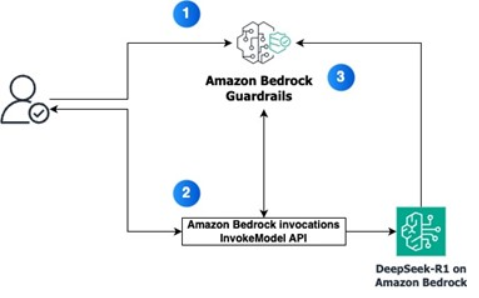
- 防护栏配置
- 创建针对你特定用例量身定制的防护栏策略并进行配置。与InvokeModel API集成
- 2. 在请求中携带防护栏标识符调用Amazon Bedrock InvokeModel API。
- 进行API调用时,Amazon Bedrock会将指定的防护栏同时应用于输入和输出。
-
- 3. 防护栏评估流程
-
- 进行API调用时,Amazon Bedrock会将指定的防护栏同时应用于输入和输出。
a. 输入评估:在将提示发送给模型之前,防护栏会根据配置的策略评估用户输入。
b. 并行策略检查:为降低延迟,系统会并行执行所有配置策略的输入评估。
c. 输入干预:如果输入违反任何防护栏策略,将返回预配置的拦截消息,并放弃模型推理。
d. 模型推理:如果输入通过防护栏检查,提示将被发送至指定模型进行推理。
e. 输出评估:模型生成响应后,防护栏会根据配置的策略评估输出内容。
f. 输出干预:如果模型响应违反任何防护栏策略,将根据策略类型返回预配置拦截消息或对敏
感信息进行脱敏处理。
g. 响应交付:如果输出通过所有防护栏检查,响应将不作修改直接返回给应用程序。
准备工作
在使用Amazon Bedrock自定义模型导入功能为模型设置防护栏之前,请确保满足以下先决条件:
- 拥有可访问Amazon Bedrock的Amazon账户,以及具备必要权限的IAM角色。为实现集中式访问管理,我们建议你使用Amazon IAM Identity Center。
- 确保已通过Amazon Bedrock自定义模型导入服务导入自定义模型。为便于说明,我们将使用可通过Amazon Bedrock自定义模型导入的DeepSeek-R1-Distill-Llama-8B模型。你有以下两种部署该模型的选项:
- 按照《部署DeepSeek-R1蒸馏Llama模型》中的说明部署DeepSeek的蒸馏Llama模型
- 使用aws-samples提供的notebook进行部署
你可以通过Amazon管理控制台创建防护栏,关键步骤如下:
- 安装必要的依赖项
- 使用boto3 API创建防护栏并配置过滤器,以满足前文所述的使用场景需求
- 为导入的模型配置tokenizer
- 使用不同测试prompt验证Amazon Bedrock防护栏的各项过滤功能
该方法将防护栏集成到用户输入和模型输出两端,确保在交互的两个阶段都能拦截潜在有害或不适当内容。对于通过Amazon Bedrock自定义模型导入、Amazon Bedrock Marketplace和Amazon SageMaker JumpStart导入的开放权重蒸馏模型,需要实施的关键过滤功能包括:提示词攻击防护、内容审核、主题限制以及敏感信息保护。
通过亚马逊云科技服务实施纵深防御策略
虽然Amazon Bedrock Guardrails提供了基本的内容安全和提示词防护控制,但在部署任何基础模型时,实施全面的纵深防御策略至关重要。如需了解符合OWASP LLM十大安全风险的纵深防御方法详细指导,请参阅我们之前关于构建安全生成式AI应用的博客文章。
关键要点包括:
- 通过安全优先的设计理念构建组织韧性
- 基于亚马逊云科技服务打造安全的云基础架构
- 在多个信任边界实施分层防御策略
- 应对LLM应用的OWASP十大安全风险
- 在整个AI/ML生命周期贯彻安全最佳实践
- 将亚马逊云科技安全服务与AI/机器学习专用功能结合使用
- 综合考虑多方观点,使安全措施与业务目标保持一致
- 防范提示词注入和数据投毒等风险
模型级控制措施与纵深防御策略的结合,可构建强大的安全防护体系,有效抵御:
- 数据外泄企图
- 对精调模型或训练数据的未授权访问
- 模型实现中的潜在漏洞
- AI代理和集成功能的恶意利用
亚马逊云科技还提供众多免费云产品,感兴趣的话可以访问:亚马逊云科技。
总结
为DeepSeek-R1等大语言模型实施安全防护措施,对维护安全、合规的AI环境至关重要。通过结合使用Amazon Bedrock Guardrails与InvokeModel API及ApplyGuardrails API,你能够在充分发挥先进语言模型强大能力的同时,有效降低相关风险。但需注意的是,模型层面的防护措施仅是整体安全战略的一个组成部分。
本文所述的策略解决了通过Amazon Bedrock Custom Model Import、Amazon Bedrock Marketplace和Amazon SageMaker JumpStart托管的各类开放权重模型普遍存在的关键安全问题。这些问题包括:提示词注入攻击的潜在漏洞、有害内容生成风险,以及最新评估中发现的其他安全隐患。通过实施这些防护栏措施,并结合纵深防御策略,企业能够大幅降低模型滥用风险,使其AI应用更好地符合伦理标准和监管要求。