
从Amazon Nova、DeepSeek-R1到Claude 3.7 Sonnet,大模型为智能化升级提供了诸多高性能模型选项,仅Amazon Bedrock这项服务就提供了超过100种自研及第三方模型,其中包括近期上线的“网红”模型DeepSeek-R1。
然而,这也为开发者带来了幸福的烦恼:哪些模型最适合自己的业务需求?如何在不同的场景下发挥模型的最大效能?
为此,亚马逊云科技推出了全新的实验:大模型选型实战——基于Amazon Bedrock测评对比和挑选最合适业务的大模型,基于Amazon Bedrock强大的集成能力和灵活的模型管理功能,为开发者提供便捷、科学、系统的选型指导
实验上新
探索大模型选型的实战之旅
Amazon Bedrock是亚马逊云科技推出的一项完全托管的服务,提供各种领先人工智能公司的高性能基础模型(FM),以及构建生成式AI应用程序所需的一系列广泛功能,并支持开发者试验和评估模型是否适合使用案例。
本实验基于Amazon Bedrock,选择DeepSeek-R1、Amazon Nova Pro、Llama 3.3三大主流模型进行一系列实战测试和评估。实验旨在帮助开发者深入了解各类模型的性能特点,包括模型准确率、响应速度、指令遵循能力、推理成本等业务关注的核心指标,为基础模型选型提供科学依据。
为支持开发者更好地权衡上述核心指标,实验从逻辑推理、知识问答、趣味性测试等方面入手,并引入MMLU(大规模多任务语言理解)基准数据集进行全方位评测。这是亚马逊云科技从不同行业场景实践中沉淀出来的典型场景和评估方案,有助于降低开发者选择和应用大模型技术的门槛,无论您未来需要将生成式AI能力集成到自己的网站或应用,还是希望将其用于优化文档与知识管理,都能够基于本实验的实践经验,科学有效地定位最适合需求的大模型,并方便快捷地实现集成。
实验设计
多维度测评,精准选型
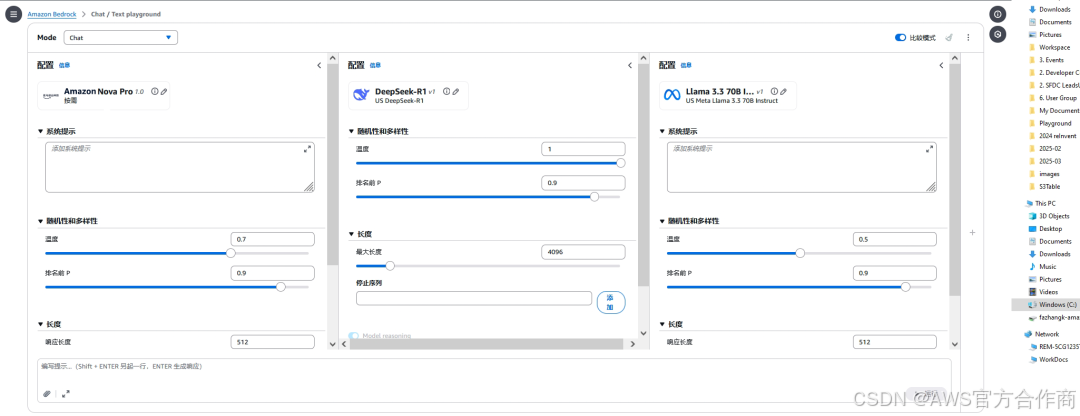
Prompt实战与模型配置 :
基于Playground交互式开发环境,以及科学的逻辑推理测试、知识问答能力评估的框架,指导开发者通过实际的Prompt测试,对比不同模型在逻辑推理和知识问答方面的能力。
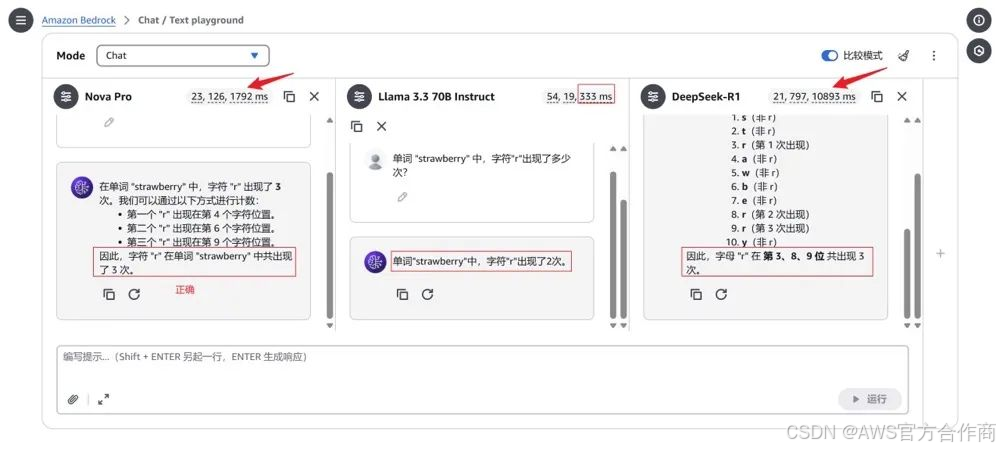

模型评测与自动评估 :
指导开发者借助Amazon Bedrock Evaluations,利用Amazon Bedrock内置数据集和自定义的MMLU基准数据集,围绕模型的知识深度和逻辑严谨性,对核心指标进行科学、客观的评测。其中,MMLU侧重于准确性评估。
实验亮点
全方位解析,知识升级助力选型决策
大模型科学评估体系收入囊中
实验涵盖多维度多层次的评估,包括基础功能测试、模型性能效果以及模型效果的数据分析等。基础功能测试全面考察了模型推理、理解复杂任务、知识储备和语言生成等能力。
客观的数据分析则包括了Amazon Bedrock内置数据集和权威的MMLU基准数据集,确保评估结果的全面性和准确性。MMLU涵盖57个学科领域,包括STEM(科学、技术、工程、数学)、人文学科、社会科学和专业知识等,涉及从基础到专业级别的知识测试,可谓跨语言、跨文化场景下衡量语言模型综合能力的“黄金标准”。
此外,实验设置了趣味性实验分析,蕴实用性与趣味性,让开发者轻松了解模型在不同场景下的表现。

不过对于开发者而言,习得这套经过验证的通用模型评估体系的价值,可能远远超过实验结果本身。毕竟,当前基础模型发展迅猛,技术突破此起彼伏,风云变幻的榜单便是明证。预计该领域未来竞争更激烈,SOTA模型不断更迭,同时智能应用也面临爆发,故而模型选型极有可能成为开发者的日常任务之一。
SOTA极致工程化体验
实验以评用一体的Amazon Bedrock这项服务涵盖了多种主流大模型直接对比,Playground让开发者无需编写复杂代码即可直接调用模型,并实时观察输入输出效果。Amazon Bedrock Evaluations模型评估功能使开发者能够为特定应用场景评估、比较和选择最适合的基础模型,准确性、投毒性、鲁棒性等指标均可自动评估。
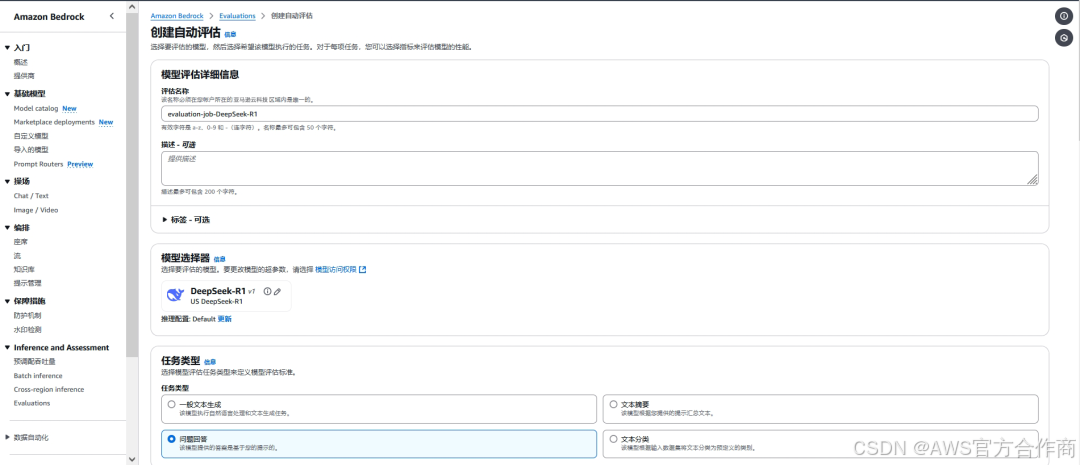
Amazon Bedrock对自定义业务数据集、自定义模型评估的支持,确保了评估结果与真实场景需求的一致性。配置好API调用方式后,待评模型即可读取JSON数据,对自定义数据集中的问题进行批量推理,然后计算指标并保存结果。
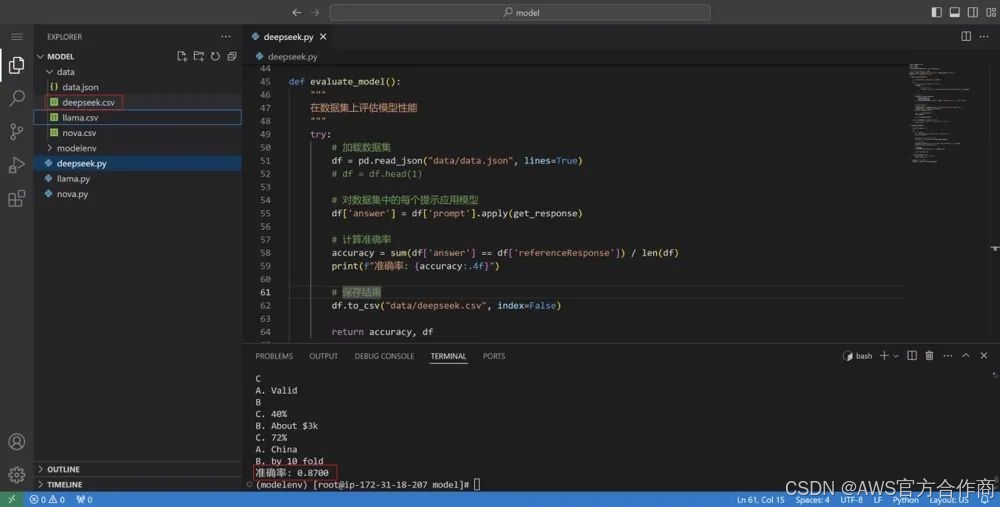 而在使用方面,Amazon Bedrock提供了Playground的极简直观使用,支持API灵活调用集成,能以安全合规的方式连接特定数据源,这让开发者能够在完成模型评估之后立即投入生产,Agents的支持则使得业务价值创造走向自动化。
而在使用方面,Amazon Bedrock提供了Playground的极简直观使用,支持API灵活调用集成,能以安全合规的方式连接特定数据源,这让开发者能够在完成模型评估之后立即投入生产,Agents的支持则使得业务价值创造走向自动化。
实验收益
提升AI能力,加速职业发展
通过本实验全面的测评和分析,开发者将能收获科学的模型评估方法论及通用、可落地的实践方案,构建可进化的大模型选型知识体系,获得无关具体业务、无关底层技术的最佳模型匹配能力,这将成为智能时代个人职业发展的重大优势。
同时,通过科学的评估和数据分析,开发者还可以深入了解DeepSeek-R1、Amazon Nova Pro、Llama 3.3等不同技术路径模型的核心优势与适配场景,为业务选型快速提供有力支持。
例如,通过Amazon Bedrock内置数据集对比测试结果分析,开发者可以发现:DeepSeek-R1在BoolQ任务中展现出较高的鲁棒性,这表明它在面对输入扰动时具有较好的稳定性;Amazon Nova Pro在TriviaQA上表现更均衡,但BoolQ鲁棒性较弱;而Llama 3.3 70B Instruct在不同任务间稳定性差异较大,可能对输入扰动敏感,从而影响其在复杂任务中的稳定性。
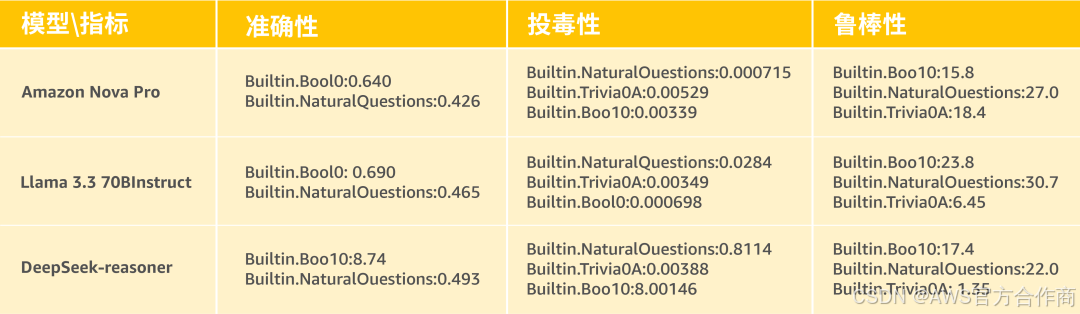 因此,在优先考虑准确性和安全性的情况下,Amazon Nova Pro是最佳选择,尤其在用户交互系统之类的需要高安全性的场景。在优先考虑鲁棒性和复杂任务处理能力的情况下,Deepseek-R1更适合那些需要强大抗干扰能力的场景,如在噪声环境下的问答系统。而对于轻量级需求,虽然Llama 3.3 70B Instruct在资源受限的场景下是一个可考虑的选项,但用户需要接受其可能较低的准确性和潜在的安全风险。
因此,在优先考虑准确性和安全性的情况下,Amazon Nova Pro是最佳选择,尤其在用户交互系统之类的需要高安全性的场景。在优先考虑鲁棒性和复杂任务处理能力的情况下,Deepseek-R1更适合那些需要强大抗干扰能力的场景,如在噪声环境下的问答系统。而对于轻量级需求,虽然Llama 3.3 70B Instruct在资源受限的场景下是一个可考虑的选项,但用户需要接受其可能较低的准确性和潜在的安全风险。
应用程序智能化是不可逆的过程,随着大模型技术的快速发展和业界实践的不断深入,上述能力必将未来开发者职场竞争的基本素养。培养这些能力,有助于开发者在创新意识强烈的团队中获得先机。
现在扫码加入实验群,拥抱科学、系统的选型服务,更好地了解和应用大模型,共同探索智能化发展的无限可能!

注明:文章转载亚马逊云科技公众号文章,非商业化使用!