一、Pandas库
1.1、概念
Pandas是一个开源的、用于数据处理和分析的Python库,特别适合处理表格类数 据。它建立在NumPy数组之上,提供了高效的数据结构和数据分析工具,使得数据操作变得更加简单、便捷和高效。
Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具
1.2、数据结构
1. Series:一维数组,可以存储任何数据类型(整数、字符串、浮点数等),每个 元素都有一个与之对应的标签(索引)。
2. DataFrame:二维表格型数据结构,可以视为多个 Series 对象的集合,每一列 都是一个 Series。每列可以有不同的数据类型,并且有行和列的标签。
1.3、数据操作
读取和保存数据:支持多种数据格式,如 CSV、Excel、SQL 数据库、JSON 等。
数据选择和过滤:提供灵活的索引和条件筛选功能,方便数据的提取和过滤。
数据清洗:提供了处理缺失数据、重复数据、异常值等数据清洗功能。
数据转换:通过 apply(), map(),replace()等方法进行数据转换。
数据合并:使用concat(), merge(), join()等方法进行数据的横向和纵向合并。
聚合和分组:使用 组和聚合。
1.4、主要特点
1. 数据结构:Pandas提供了两种主要的数据结构:Series(一维数组)和 DataFrame(二维表格)。
2. 数据操作:支持数据的增、删、改、查等操作,以及复杂的数据转换和清洗。
3. 数据分析:提供丰富的数据分析方法,如聚合、分组、透视等。
4. 文件读取与写入:支持多种文件格式(如CSV、Excel、SQL等)的读取和写入。
5. 与其他库集成良好:Pandas 与许多其他三方库(如 NumPy、Matplotlib、 Scikit-learn等)无缝集成,形成了一个强大的数据科学生态系统。
6. 强大的社区支持:Pandas 拥有庞大的开发者社区,提供丰富的资源和学习材 料。
官方文档
安装
pip install pandas
二、一维数组Series
Series:一维数组,与Numpy中的一维array类似。它是一种类似于一维数组的对象,是由一组数据(各种 NumPy 数据类型)以及一组与之相关的数据标签(即索引)组成。
仅由一组数据也可产生简单的 Series 对象,用值列表生成 Series 时,Pandas 默认自动生成整数索引 。

2.1、Series的创建
在Pandas中,一维数组的创建离不开Pandas库中的Series类。
pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=False)| 描述 | 说明 |
|---|---|
| data | 标量值,如整数或字符串 Python列表或元组 Python字典 1d-Ndarray |
| index | 数组或列表,用于定义Series的索引。如果未提供,则默认为从0开始的 整数索引。 |
| dtype | 指定Series的数据类型。 |
| name | 给Series一个名字,用于后续的索引和操作。 |
| copy | 布尔值,默认为False。如果为True,则复制数据;如果为False,则尽可 能避免复制数据,仅影响Ndarray输入。 |
| fastpath | 布尔值,默认为False,通常不需要用户指定。它是Pandas库内部使 用的一个优化标志,当设置为 True时,允许 Series构造函数绕过一些检查和验 证步骤,加快Series的创建速度。但由于这个参数跳过了某些安全检查,因此在 正常使用中,如果在创建Series时设置了 fastpath=True,而传入的数据又不符 合预期,则可能会导致不可预测的行为或错误。 |
2.1.1、使用标量创建
import pandas as pd
data=0
series=pd.Series(data,index=['a','b','c'])
print(series)a 0
b 0
c 0
dtype: int642.1.2、使用列表或元组创建
import pandas as pd
data1=[1,2,3,4,5]
data2=(1,2,3,4,5)
series1=pd.Series(data1,index=['a','b','c','d','e'])
series2=pd.Series(data2,index=['a','b','c','d','e'])
print(series1,series2)a 1
b 2
c 3
d 4
e 5
dtype: int64 a 1
b 2
c 3
d 4
e 5
dtype: int642.1.3、使用字典
使用字典创建Series时,字典的键就是索引,字典的值就是该索引对应的值。如果使 用字典创建Series,并且指定了与字典的键不同的index参数,那么生成的Series数组 中的数据就是以index参数的值为索引,但索引所对应的值是NaN。
在Pandas中, NaN(Not a Number)是一个特殊的浮点数,用于表示缺失数据或无 效数据。NaN 是 IEEE 浮点标准的一部分,Pandas 使用 NaN 来表示数据集中缺失或 未定义的值。
import pandas as pd
data={
'a':1,
'b':2,
'c':3
}
series=pd.Series(data)
print(series)a 1
b 2
c 3
dtype: int642.1.4、使用数组
import pandas as pd
import numpy as np
data=np.array(
[1,2,3,4,5]
)
series=pd.Series(data)
print(series)0 1
1 2
2 3
3 4
4 5
dtype: int642.2、Series的属性
2.2.1、index
返回Series中的索引。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.index)
series.index=['e','f','g']
print(series.index)Index(['a', 'b', 'c'], dtype='object')
Index(['e', 'f', 'g'], dtype='object')2.2.2、values
用于返回Series中的数据,返回的数据将以Ndarray数组的形式存在。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.values)
print(type(series.values))[1 2 3]
<class 'numpy.ndarray'>2.2.3、name
用于返回Series的名称,如果创建时指定了name参数,那么该属性的返回值就是 name参数,如果没有指定则为None。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.name)
series.name='test'
print(series.name)None
test2.2.4、dtype和dtypes
对于Series来说,dtype和dtypes的作用是一样的,都是用来返回Series对象的数据 类型。 需
要注意的是:
该属性是只读属性,不可以通过直接赋值的方式去修改数据类型。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.dtype)int642.2.5、shape
用于描述Series的形状。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.shape)(3,)2.2.6、 size
用于返回Series的元素数量,该返回值是一个整数。
import pandas as pd
series=pd.Series([1,2,3],index=['a','b','c'])
print(series.size)32.2.7、empty
用来表示Series数组是否为空,返回值一个布尔值,如果数组里一个元素都没有就返 回True,否则返回False。
import pandas as pd
series=pd.Series()
print(series.empty)True2.2.8、hasnans
用于返回数组中是否包含NaN值,如果数组中存在NaN,那么返回True,否则返回 False。
import pandas as pd
import numpy as np
series=pd.Series([1,2,np.nan],index=['a','b','c'])
print(series.hasnans)True2.2.9、is_unique
用于返回数组中的元素是否为独一无二的,如果所有的元素都是独一无二的,即数组 中没有重复元素,那么就返回True,否则返回False。
import pandas as pd
import numpy as np
series=pd.Series(['a','b','c'])
print(series.is_unique)True2.2.10、nbytes
用于返回该Series对象中所有数据占用的总字节数。
import pandas as pd
series=pd.Series([1,2,3],dtype='int64')
print(series.nbytes)82.2.11、axes
用于返回series对象行轴标签的列表。
import pandas as pd
series = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'], dtype='int64')
print(series.axes)[Index(['a', 'b', 'c', 'd', 'e'], dtype='object')]2.2.12、ndim
返回Series数组的维度,对于Series数组来说,它的维度始终为1。
import pandas as pd
series = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'], dtype='int64')
print(series.ndim)12.2.13、array
用于返回Series的底层数组,包括数组的元素、数组的长度及数组元素的数据类型。
import pandas as pd
import numpy as np
data = np.array([1, 2, 3, 4, 5])
series = pd.Series(data)
print(series.array)
print(type(series.array))<NumpyExtensionArray>
[np.int64(1), np.int64(2), np.int64(3), np.int64(4), np.int64(5)]
Length: 5, dtype: int64
<class 'pandas.core.arrays.numpy_.NumpyExtensionArray'>2.2.14、attrs
返回series的自定义属性,可以用来存储额外的说明性数据。
import pandas as pd
import numpy as np
data = np.array([1, 2, 3, 4, 5])
print(series.attrs)
series.attrs = {'source': 'file1', 'time': '19:27:27'}
print(series)
print('额外属性', series.attrs){}
0 1
1 2
2 3
3 4
4 5
dtype: int64
额外属性 {'source': 'file1', 'time': '19:27:27'}2.2.15、is_monotonic_decreasing
返回一个布尔值,表示Series是否按降序排列。
import pandas as pd
series = pd.Series([5, 4, 3, 2, 1])
print(series.is_monotonic_decreasing)True2.2.16、is_monotonic_increasing
返回一个布尔值,表示Series是否按升序排列。
import pandas as pd
series = pd.Series([5, 4, 3, 2, 1])
print(series.is_monotonic_increasing)False2.3、Series中元素的索引与访问
2.3.1、位置索引
可以使用整数索引来访问Series中的元素,就像访问列表一样。
import pandas as pd
series=pd.Series([10,20,30,40,50,60])
print(series[0])
print(series[1])10
202.3.2、标签索引
除了使用位置索引之外,还可以使用标签进行索引,与访问字典中的元素类似。
import pandas as pd
series=pd.Series([10,20,30,40,50],index=['a','b','c','d','e'])
print(series['a'])
print(series['c'])10
302.3.3、切片索引
Series对象的切片方式有两种,第一种是使用位置切片,其使用方法与列表的切片类 似;第二种是使用标签切片,其语法与位置切片类似,都是 start:stop,且开始值 与终止值可以省略,但与位置切片不同的是,标签切片的范围是左右都闭合,即既包 含start,又包含stop,而位置切片是左闭右开,只包含start,不包含stop。
import pandas as pd
series=pd.Series([10,20,30,40,50],index=['a','b','c','d','e'])
print(series[:])
print(series['b':'d'])a 10
b 20
c 30
d 40
e 50
dtype: int64
b 20
c 30
d 40
dtype: int642.3.4、loc与iloc
loc与iloc也是Series对象的属性,它们的作用就是用来访问Series中的元素,loc是基 于标签的索引,iloc是基于位置的索引。
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
print(series.loc['a'])
print(series.iloc[0:2])
print(series.iloc[2])10
a 10
b 20
dtype: int64
302.3.5、at与iat
at与iat也是Series对象的属性,可以用来访问元素,at是基于标签的索引,iat是基于 位置的索引。
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
print(series.at['a'])
print(series.iat[0])
print(series.iat[2])10
10
302.3.6、head
head是Series对象的方法,用于快速查看 Series数据的开头部分内容。
series.head(n=None)| 描述 | 说明 |
|---|---|
| n | 是可选参数,用于指定要返回的行数。如果不提供该参数,默认值为5。 |
import pandas as pd
data = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
index = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
series = pd.Series(data, index=index)
print(series.head())a 10
b 20
c 30
d 40
e 50
dtype: int642.3.7、tail
tail的用法与head类似,但不同的是,它用于快速查看Series数据的末尾部分内容。
series.tail(n=None)| 描述 | 说明 |
|---|---|
| n | 是可选参数,用于指定要返回的行数。若不提供该参数,默认值为5。 |
import pandas as pd
data = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
index = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
series = pd.Series(data, index=index)
print(series.tail())f 60
g 70
h 80
i 90
j 100
dtype: int642.3.8、isin
该函数用于判断 Series中的每个元素是否在指定的一组值中,它会返回一个与原 Series长度相同的布尔型Series, 其中对应位置为True表示该位置的元素在指定 的值集合中,False则表示不在。
series.isin(values)| 描述 | 说明 |
|---|---|
| values | 是一个可迭代对象(如列表、元组、集合等),用于指定要进行判断 的一组值。 |
import pandas as pd
data = [10, 20, 30, 40, 50]
series = pd.Series(data)
values_to_check = [20, 40]
result = series.isin(values_to_check)
print(result)0 False
1 True
2 False
3 True
4 False
dtype: bool2.3.9、get
Series.get 方法用于通过标签来获取Series中的元素。
Series.get(key, default=None)| 描述 | 说明 |
|---|---|
| key | 你想要获取的元素的标签。 |
| default | 可选参数,如果 key不在标签中,返回这个默认值。如果没有指定,默认为 None。 |
import pandas as pd
s = pd.Series(['apple', 'banana', 'cherry'], index=[1, 2, 3])
print(s.get(2))
print(s.get(4, 'Not Found'))banana
Not Found2.4、数据操作
2.4.1、数据清洗--dropna()
删除包含NaN值的行。
series.dropna(axis=0, inplace=False)| 描述 | 说明 |
|---|---|
| axis | 可选参数,用于指定按哪个轴删除缺失值。对于 Series对象,因为它是 一维数据结构,只有一个轴,所以此参数默认值为0,且一般不需要修改这个参 数(在处理 DataFrame时该参数才有更多实际意义,如 除,axis = 1表示按列删除)。 |
| inplace | 可选参数,用于指定是否在原 inplace = True,则会直接在原 axis = 0表示按行删 Series对象上进行操作。如果 如果 Series上删除缺失值,原 Series会被修改; inplace = False(默认值),则会返回一个删除了缺失值的新 Series, 原Series保持不变。 |
import pandas as pd
import numpy as np
data = [1, np.nan, 3, 4, np.nan]
series = pd.Series(data)
new_series = series.dropna()
print(new_series)0 1.0
2 3.0
3 4.0
dtype: float642.4.2、数据清洗--fillna()
填充NaN值。
Series.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)| 描述 | 说明 |
|---|---|
| value | 用于填充缺失值的标量值或字典。如果传递的是字典,则字典的键应该 是要填充的标签,值是用于填充的值。 |
| method | 字符串,表示填充的方法。可选值包括: pad / ffill:用前一个非缺失值去填充缺失值。 bfill / backfill:用后一个非缺失值去填充缺失值。 |
| axis | 填充的轴,对于Series 对象来说,这个参数通常不需要指定,因为Series 是一维的。 |
| inplace | 布尔值,表示是否在原地修改数据。如果为True,则直接在原 Series 上修改,不返回新的对象。 |
| limit | 整数,表示最大填充量。如果指定,则只填充前 limit 个缺失值。 |
| downcast | 字典,用于向下转换数据类型。例如,可以将float64 转换为float32 |
import pandas as pd
import numpy as np
s = pd.Series([1, np.nan, 3, np.nan, 5])
filled_with_scalar = s.fillna(0)
print(filled_with_scalar)
filled_with_ffill = s.fillna(method='ffill')
print(filled_with_ffill)
filled_with_bfill = s.fillna(method='bfill')
print(filled_with_bfill)
filled_with_limit = s.fillna(value=0, limit=1)
print(filled_with_limit)0 1.0
1 0.0
2 3.0
3 0.0
4 5.0
dtype: float64
0 1.0
1 1.0
2 3.0
3 3.0
4 5.0
dtype: float64
0 1.0
1 3.0
2 3.0
3 5.0
4 5.0
dtype: float64
0 1.0
1 0.0
2 3.0
3 NaN
4 5.02.4.3、数据清洗--isnull()
检测Series对象中的缺失值,它会返回一个布尔型Series,其中每个元 素表示原Series对应位置的值是否为缺失值(NaN)。
Series.isnull()import pandas as pd
import numpy as np
s = pd.Series([1, 2, np.nan, 4, np.nan])
missing_values = s.isnull()
print(missing_values)0 False
1 False
2 True
3 False
4 True
dtype: bool2.4.4、数据清洗--drop_duplicates()
用于去除Series对象中的重复项。
Series.drop_duplicates(keep='first', inplace=False, ignore_index=False)| 描述 | 说明 | ||||||
|---|---|---|---|---|---|---|---|
| keep | 可选参数,决定了如何处理重复项。有三个选项:
|
||||||
| inplace | 布尔值,默认为False.。如果设置为True,则直接在原始Series上进行操作,返回值为None。如果设置为False,则返回一个新的Series,不修改原始Series。 | ||||||
| ignore_index | 布尔值,默认为 False。如果设置为 True,则结果的索引将被 重新设置,以反映删除重复项后的新顺序。如果设置为False,则保留原始索引。 |
import pandas as pd
series = pd.Series(['a', 'b', 'b', 'c', 'c', 'c', 'd'])
series_unique = series.drop_duplicates(keep='first')
print(series_unique)0 a
1 b
3 c
6 d
dtype: object2.4.5、数据转换--replace()
替换特定的值、一系列值或者使用字典映射进行替换。
Series.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')| 描述 | 说明 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| to_replace | 要替换的值,可以是以下类型:
|
||||||||
| value | 替换后的新值,可以是标量或字典。如果 to_replace 是列表,则value 也应该是相同长度的列表。 | ||||||||
| inplace | 布尔值,表示是否在原地修改数据。如果为 True,则直接在原 Series 上修改,不返回新的对象。 | ||||||||
| limit | 整数,表示最大替换量。如果指定,则只替换前limit 个匹配的值。 | ||||||||
| regex | 布尔值,表示是否将to_replace 解释为正则表达式。 | ||||||||
| method | 字符串,表示填充的方法,在 to_replace 参数是一个标量、列表或 元组,同时 value 参数设置为 None 时,可以使用method 参数来指定填充缺 失值(NaN)的方式。可选值包括:
|
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
replaced = s.replace(to_replace=2, value=20)
print(replaced)0 1
1 20
2 3
3 4
4 5
dtype: int642.4.6、数据转换--astype()
用于将 Series 的数据类型(dtype)转换或转换为另一种类型。
Series.astype(dtype, copy=True, errors='raise')| 描述 | 说明 |
|---|---|
| dtype | 你希望将 Series 转换成的数据类型。 |
| copy | 布尔值,默认为 True。如果为 False,则转换数据类型时不会复制底层 数据(如果可能的话)。 |
| errors | 默认为 ‘raise’,控制当转换失败时的行为。如果设置为 ‘raise’,则在转 换失败时会抛出异常;如果设置为 ‘ignore’,转换失败后则返回原始Series,不做任何修改。 |
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
s_str = s.astype(float)
print(s_str)0 1.0
1 2.0
2 3.0
3 4.0
4 5.0
dtype: float642.4.7、数据转换--transform()
用于对Series中的数据进行转换操作,并返回与原始Series具有相 同索引的新Series。
Series.transform(func, axis=0, *args, **kwargs)| 描述 | 说明 |
|---|---|
| func | 应用于Series的函数。这个函数可以是内置函数,或者自定义的函数。 |
| axis | 对于Series来说,这个参数不起作用,因为Series是一维的。在 DataFrame上使用时, axis=0(默认)表示按列应用函数, axis=1表示按行应 用函数。 |
| *args, **kwargs | 这些参数会被传递给func函数。 |
import pandas as pd
def square(x):
return x ** 2
s = pd.Series([1, 2, 3, 4, 5])
transformed_series = s.transform(square)
print(transformed_series)0 1
1 4
2 9
3 16
4 25
dtype: int642.4.8、数据排序--sort_values()
按照值对 Series 进行排序。
Series.sort_values(axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)| 描述 | 说明 |
|---|---|
| axis | 默认为 0。对于 Series,这个参数不起作用,因为 Series 是一维的,而 sort_values 总是在 axis=0 上操作。 |
| ascending | 布尔值,默认为True。如果是True,则按照升序排列;如果是False,则按照降序排列。 |
| inplace | 布尔值,默认为False。如果为 True,则排序将直接在原始 Series上进行,不返回新的 Series。 |
| kind | 排序算法,{‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’},默认为‘quicksort’。决定了使用的排序算法。 |
| na_position | {‘first’, ‘last’},默认为 ‘last’。这决定了 NaN 值的放置位置。 |
| ignore_index | 布尔值,默认为 False。如果为 True,则排序后的 Series 将重置索引,使其成为默认的整数索引。 |
| key | 函数,默认为 None。如果指定,则这个函数将在排序之前应用于每个值, 并且排序将基于这些函数返回的值。 |
import pandas as pd
import numpy as np
def square(x):
return x ** 2
s = pd.Series([-3, 1, 4, 1, np.nan, 9], index=['a', 'b', 'c', 'd', 'e', 'f'])
sorted_s = s.sort_values(ignore_index=True, key=square)
print(sorted_s)0 1.0
1 1.0
2 -3.0
3 4.0
4 9.0
5 NaN
dtype: float642.4.9、数据排序--sort_index()
按照索引的顺序对数据进行排序。
Series.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)| 描述 | 说明 |
|---|---|
| axis | 默认为 0。对于 Series,这个参数不起作用 |
| level | 默认为 None,如果索引是多级索引(也称为层次化索引或 MultiIndex),则可以指定要排序的级别。 |
| ascending | 默认为 True,如果为 True,则按升序排序;如果为 False,则按降 序排序。对于多级索引,可以传递一个布尔值列表,以指定每个级别的排序顺 序。 |
| inplace | 默认为 False,如果为 True,则直接在原对象上进行修改,不会返回一 个新的对象。 |
| kind | {‘quicksort’, ‘mergesort’, ‘heapsort’},默认为 ‘quicksort’,指定排序算 法。‘quicksort’ 是最快的通用排序算法,但不是稳定的;‘mergesort’ 是稳定的, 但可能比 ‘quicksort’ 慢;‘heapsort’ 是原地排序算法,但通常比其他两个选项 慢。 |
| na_position | {‘first’, ‘last’}, 默认为 ‘last’,指定 NaN 值应该排在排序结果的开头 还是结尾。 |
| sort_remaining | 默认为 True,对于多级索引,如果为 True,在该level排序 后,在排序的基础上对剩下的级别的元素还会排序。 |
| ignore_index | 默认为 False,如果为 True,则排序后的结果将不再保留原始索 引,而是使用默认的整数索引。 |
| key | 函数,默认为 None。如果指定,则这个函数将在排序之前应用于每个值, 并且排序将基于这些函数返回的值。 |
import pandas as pd
import numpy as np
arrays = [
np.array(['qux', 'qux', 'foo', 'foo','baz', 'baz', 'bar', 'bar']),
np.array(['two', 'one', 'two', 'one','two', 'one', 'two', 'one'])
]
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8], index=arrays)
print(s)
res = s.sort_index(level=1, ascending=True, sort_remaining=True, ignore_index=False)
print(res)qux two 1
one 2
foo two 3
one 4
baz two 5
one 6
bar two 7
one 8
dtype: int64
bar one 8
baz one 6
foo one 4
qux one 2
bar two 7
baz two 5
foo two 3
qux two 1
dtype: int642.4.10、数据筛选
可以使用一个布尔数组来选择满足条件的元素。
import pandas as pd
series = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
print(series[series > 30])d 40
e 50
dtype: int642.4.11、数据拼接
concat():用于将多个Pandas对象(如Series或DataFrame)沿着一个轴连接起来的 函数。
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=None)| 描述 | 说明 |
|---|---|
| objs | 参与连接的Pandas对象的列表或元组。例如,可以是多个Series或 DataFrame。 |
| axis | {0或’index’, 1或’columns’},表示连接的轴,默认为0。0表示沿着行方向 连接(索引轴),1表示沿着列方向连接(列轴)。 |
| join | {‘inner’, ‘outer’},默认为’outer’。如何处理其他轴上的索引。'outer’表示 并集,保留所有索引;'inner’表示交集,只保留所有对象共有的索引。 |
| ignore_index | 布尔值,默认为False。如果为True,则不保留原索引,而是创 建一个新索引,可以避免重复的索引。 |
| keys | 序列,默认为None。用于创建分层索引的键。如果提供了keys,则生成 的DataFrame或Series将具有分层索引。 |
| levels | 序列列表,默认为None。用于构造分层索引的特定级别,如果设置了 keys,则默认为keys。 |
| names | 列表,默认为None。生成的分层索引中的级别名称。如果提供了keys, 表示使用keys作为索引名称。 |
| verify_integrity | 布尔值,默认为False。如果为True,则检查新连接的轴是 否包含重复的索引,如果发现重复,则引发ValueError。这在确保数据没有重复 时很有用。 |
| sort | 布尔值,默认为False。在连接之前是否对非连接轴上的索引进行排序。这 在连接多个DataFrame时很有用,可以确保索引是有序的。 |
| copy | 布尔值,默认为None。如果为True,则不管是否需要,都会复制数据。 如果为False,则尽量避免复制数据,除非必要。None表示自动选择。 |
import pandas as pd
s1 = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'f'])
s3 = pd.Series([7, 8, 9], index=['e', 'f', 'g'])
result = pd.concat([s1, s2, s3])
print(result)a 1
b 2
c 3
c 4
d 5
f 6
e 7
f 8
g 9
dtype: int642.5、统计计算
2.5.1、 count
用于计算 Series中非NaN(非空)值的数量。
import pandas as pd
s = pd.Series([1, 2, None, 4, None])
count_non_na = s.count()
print(count_non_na)2.5.2、 sum
sum() 函数会计算所有值的总和。
Series.sum(axis=None, skipna=True, numeric_only=None, min_count=0)| 描述 | 说明 |
|---|---|
| axis | 对于 Series对象来说,这个参数通常不起作用,因为 Series是一维的。 它主要在 DataFrame对象中用于指定操作的轴(0表示按列求和,1表示按行求 和)。 |
| skipna | 布尔值,默认为True,如果为True,则在计算总和时会忽略NaN值 。 如果为False,则返回NaN。 |
| numeric_only | 布尔值,默认为None。如果为True,则只对数字类型的数据进行计算,只针对DataFrame。 |
| min_count | int值,默认为0。表示在计算总和之前,至少需要多少个非NaN值.如果非NaN值的数量小于min_count,则结果为 NaN。 |
import pandas as pd
s = pd.Series([1, 2, None, 4, 5])
total = s.sum(min_count=5)
print(total)2.5.3、 mean
mean() 函数会计算所有值的平均值。
Series.mean(axis=None, skipna=True, numeric_only=None)| 描述 | 说明 |
|---|---|
| axis | 对于 Series对象来说,这个参数通常不起作用,因为 Series是一维的。 它主要在 DataFrame对象中用于指定操作的轴(0表示按列计算平均值,1表示按 行计算平均值)。 |
| skipna | 布尔值,默认为True,如果为True,则在计算总和时会忽略NaN值 。 如果为False,则返回NaN。 |
| numeric_only | 布尔值,默认为None。如果为True,则只对数字类型的数据进行计算,只针对DataFrame。 |
2.5.4、 median
median()函数用于计算DataFrame或Series中的中位数。
Series.median(axis=0, skipna=True, numeric_only=False)| 描述 | 说明 |
|---|---|
| axis | 对于 Series对象来说,这个参数通常不起作用,因为 Series是一维的。 它主要在 DataFrame对象中用于指定操作的轴(0表示按列计算中位数,1表示按 行计算中位数)。 |
| skipna | 布尔值,默认为True,如果为True,则在计算总和时会忽略NaN值 。 如果为False,则返回NaN。 |
| numeric_only | 布尔值,默认为None。如果为True,则只对数字类型的数据进行计算,只针对DataFrame。 |
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
median_value = s.median()
print(median_value)2.5.5、 min和max
Series.min()函数用于计算Series对象中的最小值, Series.max()函数用于计算Series对象中的最大值。
Series.min(axis=0, skipna=True, numeric_only=False)Series.max(axis=0, skipna=True, numeric_only=False)| 描述 | 说明 |
|---|---|
| axis | 对于 Series对象来说,这个参数通常不起作用,因为 Series是一维的。 它主要在 DataFrame对象中用于指定操作的轴(0表示按列计算最大最小值,1表示按 行计算最大最小值)。 |
| skipna | 布尔值,默认为True,如果为True,则在计算总和时会忽略NaN值 。 如果为False,则返回NaN。 |
| numeric_only | 布尔值,默认为None。如果为True,则只对数字类型的数据进行计算,只针对DataFrame。 |
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
min_value = s.min()
max_value = s.max()
print('最小值是:', min_value)
print('最大值是:', max_value)2.5.6、 var
Series.var()函数用于计算Series对象的方差。
Series.var(axis=None, skipna=True, ddof=1, numeric_only=False)| 描述 | 说明 |
|---|---|
| axis | 对于 在DataFrame中, Series对象,这个参数不会产生任何效果,因为 Series是一维的。axis用于指定沿着哪个轴计算方差。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算方差之前会忽略 NaN 值。如果设置为 False,计算方差时会包括 NaN值,通常会导致结果也是 NaN。 |
| ddof | 整数,默认为1。Delta Degrees of Freedom,用于贝塞尔校正,以得到 样本方差的估计。对于无偏估计(样本方差), ddof通常设置为1。如果计算总 体方差,应该将 ddof设置为0。 |
| numeric_only | 布尔值,默认为False,如果为True ,则只对数字类型的数据进行方差计算,忽略非数字类型的数据。 |
import pandas as pd
import numpy as np
s = pd.Series([1, 2, np.nan, 4, 5])
variance = s.var()
print('方差是:', variance)2.5.7、 std
Series.std()函数用于计算Series对象的标准差。
Series.std(axis=None, skipna=True, ddof=1, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | 对于Series来说,这个参数不会产生任何效果,因为Series是一维的。它 主要用于DataFrame,以指定沿着哪个轴计算标准差。 |
| skipna | 布尔值,默认为True。如果为True,则在计算标准差之前会忽略NaN 值,如果为False,则返回NaN。 |
| ddof | 整数,默认为1。Delta Degrees of Freedom,是贝塞尔校正的参数。对 于无偏估计(样本标准差),ddof通常设置为1。 |
| numeric_only | 布尔值,默认为False。如果为True,则只对数字类型的数据进 行计算,只针对DataFrame。 |
| **kwargs | 其他关键字参数 |
import pandas as pd
import numpy as np
s = pd.Series([1, 2, np.nan, 4, 5])
std_dev = s.std()
print('标准差是:', std_dev)2.5.8、 quantile
Series.quantile() 方法用于计算Series中数值的分位数。
Series.quantile(q=0.5, interpolation='linear')| 描述 | 说明 |
|---|---|
| q | 这个参数是必需的,它表示要计算的分位数值。可以是单一的数值,也可以 是一个数值列表。例如, q=0.5 表示计算中位数(50%分位数)。 |
| interpolation | 这个参数决定了当所需的分位数位于两个数据点之间时,应该 如何插值。默认值是 'linear',表示线性插值。其他选项包括 近的值)、 'lower'(选择较小的值)、 'nearest'(最 'higher'(选择较大的 值)、 'midpoint'(两个值的中间点)。 |

计算0.5分位数
import pandas as pd s = pd.Series([1, 2, 3, 4, 5]) median_value = s.quantile(q=0.5, interpolation='linear') print(median_value)
2.5.9、 cummax
该方法用于计算Series中元素的累积最大值,返回一个相同长度的Series,其中每个 位置上的值表示从Series开始到当前位置(包括当前位置)的最大值。
Series.cummax(axis=None, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | 对于Series来说,这个参数不起作用,因为Series是一维的。在 DataFrame上使用时, axis=0(默认)表示按列计算, axis=1表示按行计算。 |
| skipna | 布尔值,默认为True。如果为True,则在计算累积最大值时会忽略NaN 值;如果为False,则任何NaN值都会导致结果在该位置及之后的值都为NaN。 |
| *args, **kwargs | 这些参数用于兼容性,通常不需要使用。 |
import pandas as pd
s = pd.Series([1, 2, None, 4, 5])
cumsum_series = s.cummax()
print(cumsum_series)2.5.10、 cummin
该方法用于计算Series中元素的累积最小值,返回一个相同长度的Series,其中每个 位置上的值表示从Series开始到当前位置(包括当前位置)的最小值。
Series.cummin(axis=None, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | 对于Series来说,这个参数不起作用,因为Series是一维的。在 DataFrame上使用时, axis=0(默认)表示按列计算, axis=1表示按行计算。 |
| skipna | 布尔值,默认为True。如果为True,则在计算累积最小值时会忽略NaN 值;如果为False,则任何NaN值都会导致结果在该位置及之后的值都为NaN。 |
| *args, **kwargs | 这些参数用于兼容性,通常不需要使用。 |
import pandas as pd
s = pd.Series([1, 2, None, 4, 5])
cumsum_series = s.cummin()
print(cumsum_series)2.5.11、 cumsum
用于计算Series中元素的累积和。该方法返回一个相同长度的Series,其中每个位置 上的值表示从Series开始到当前位置(包括当前位置)的所有元素的累加和。
Series.cumsum(axis=None, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | 对于Series来说,这个参数不起作用,因为Series是一维的。在 DataFrame上使用时, axis=0(默认)表示按列计算, axis=1表示按行计算。 |
| skipna | 布尔值,默认为True。如果为True,则在计算累积和时会忽略NaN 值;如果为False,则任何NaN值都会导致结果在该位置及之后的值都为NaN。 |
| *args, **kwargs | 这些参数用于兼容性,通常不需要使用。 |
import pandas as pd
s = pd.Series([1, 2, None, 4, 5])
cumsum_series = s.cumsum()
print(cumsum_series)2.5.12、 cumprod
用于计算Series中元素的累积乘积。该方法返回一个相同长度的Series,其中每个位 置上的值表示从Series开始到当前位置(包括当前位置)的所有元素的累积乘积。
Series.cumprod(axis=None, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | 对于Series来说,这个参数不起作用,因为Series是一维的。在 DataFrame上使用时, axis=0(默认)表示按列计算, axis=1表示按行计算。 |
| skipna | 布尔值,默认为True。如果为True,则在计算累积乘积时会忽略NaN 值;如果为False,则任何NaN值都会导致结果在该位置及之后的值都为NaN。 |
| *args, **kwargs | 这些参数用于兼容性,通常不需要使用。 |
import pandas as pd
s = pd.Series([1, 2, None, 4, 5])
cumprod_series = s.cumprod()
print(cumprod_series)2.6、分组和聚合
2.6.1、groupby
用于将Series中的数据分组,并允许你对这些分组进行操作,比如计算每个组的总 和、平均值、最大值、最小值等。
Series.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)| 描述 | 说明 |
|---|---|
| by | 确定分组依据,如果 by 是一个函数,它会在对象索引的每个值上调用。如 果传递了字典或Series,将使用这些对象的值来确定组。如果传递了长度等于所 选轴的列表或 ndarray,则直接使用这些值来确定组。 |
| axis | 用于分组的轴。对于Series,这个参数通常设置为0(默认值),因为 Series是一维数据结构。 |
| level | 如果索引是多级索引(MultiIndex),则此参数用于指定分组所依据的 级别,by和level同时只能存在一个,且必须存在一个。 |
| as_index | 是否将分组键作为结果的索引,默认值为True。仅与DataFrame 输入相关。 |
| sort | 是否对结果进行排序。默认值为 True。 |
| group_keys | 是否在结果中包含分组键。默认值为 True。 |
| observed | 是否仅包含实际观察到的分类值。默认值为 False。 |
| dropna | 是否从结果中排除包含 NaN 的组。默认值为 True。 |
import pandas as pd
data = [10, 20, 10, 30, 20, 10]
series = pd.Series(data)
grouped = series.groupby(series).count()
print(grouped)2.6.2、agg
Series.agg() 方法用于对Series中的数据进行聚合操作。
Series.agg(func=None, axis=0, *args, **kwargs)| 描述 | 说明 |
|---|---|
| func | 聚合函数或函数列表/字典。可以是一个函数名称(字符串),也可以是实 际的函数对象,或者是这些的列表或字典。如果是字典,则键将是输出列的名 称,值应该是应用于Series的函数。 |
| axis | 整数或字符串,默认为0。由于Series是一维数据结构,这个参数实际上在 Series的上下文中不起作用。在DataFrame的上下文中,axis=0 表示按列进行 聚合, axis=1 表示按行进行聚合。 |
| *args | 位置参数,可以传递给 func。 |
| **kwargs | 关键字参数,可以传递给func。 |
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
result = s.agg('mean')
print(result)
result = s.agg(['max', 'min'])
print(result)
result = s.agg({'Maximum': 'max', 'Minimum': 'min'})
print(result)
def custom_agg(x, power):
return (x ** power).sum()
result = s.agg(custom_agg, power=2)
print(result)2.7、数据可视化
2.7.1、plot
Series.plot 方法是用来绘制Series数据的可视化图表的,该方法提供了灵活的接 口,允许用户通过不同的参数来定制图表的类型、样式、布局等,其用法与 Matplotlib中的plot相同。
Series.plot(*args, **kwargs)| 描述 | 说明 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kind | 图表类型,可以是以下之一:
|
||||||||||||||||||||
| ax | Matplotlib 轴对象,用于在指定的轴上绘制图表。如果不提供,则创建新的 轴对象。 | ||||||||||||||||||||
| figsize | 图表的尺寸,格式为 (width, height),单位为英寸。 | ||||||||||||||||||||
| use_index | 是否使用 Series 的索引作为 x 轴标签。默认为 True。 | ||||||||||||||||||||
| title | 图表的标题。 | ||||||||||||||||||||
| grid | 是否显示网格线。默认为 False。 | ||||||||||||||||||||
| legend | 是否显示图例。默认为 False。 | ||||||||||||||||||||
| xticks | x 轴的刻度位置。 | ||||||||||||||||||||
| yticks | y 轴的刻度位置。 | ||||||||||||||||||||
| xlim | x 轴的范围,格式为 (min, max)。 | ||||||||||||||||||||
| ylim | y 轴的范围,格式为 (min, max)。 | ||||||||||||||||||||
| color | 绘制颜色,可以是单个颜色或颜色列表。 | ||||||||||||||||||||
| label | 图例标签 |
2.7.2、hist
用于绘制Series数据直方图的方法。这个方法提供了多种参数来定制直方图的外观和 样式。
Series.hist(by=None, ax=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, figsize=None, bins=10, backend=None, legend=False, **kwargs)| 描述 | 说明 |
|---|---|
| by | 如果不是None,则将数据分组并分别绘制每个组的直方图。 |
| ax | matplotlib的Axes对象,如果指定了,则直方图将绘制在该Axes上。 |
| grid | 布尔值,默认为True,表示是否在直方图上显示网格线。 |
| xlabelsize | int或str,用于设置x轴标签的字体大小。 |
| xrot | int或float,用于设置x轴标签的旋转角度。 |
| ylabelsize | int或str,用于设置y轴标签的字体大小。 |
| yrot | int或float,用于设置y轴标签的旋转角度。 |
| figsize | 元组,用于设置直方图的大小,格式为 (width, height)。 |
| bins | int或序列,用于设置直方图的柱子数量或具体的边界。 |
| backend | 用于指定绘图后端,通常Pandas会使用matplotlib。 |
| legend | 布尔值,默认为False,表示是否在直方图上显示图例。 |
| **kwargs | 其他关键字参数,将被传递给matplotlib的 hist函数。 |
2.7.3、绘图集合
2.7.3.1、准备工作
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
s = pd.Series([1, 3, 2, 4, 5], index=['a', 'b', 'c', 'd', 'e']) 2.7.3.2、绘制折线图
plt.figure(figsize=(8, 4))
plt.plot(s.index, s.values, marker='o', color='r', linestyle='--', linewidth=2)
plt.title('折线图', fontsize=14)
plt.xlabel('索引', fontsize=12)
plt.ylabel('值', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show() 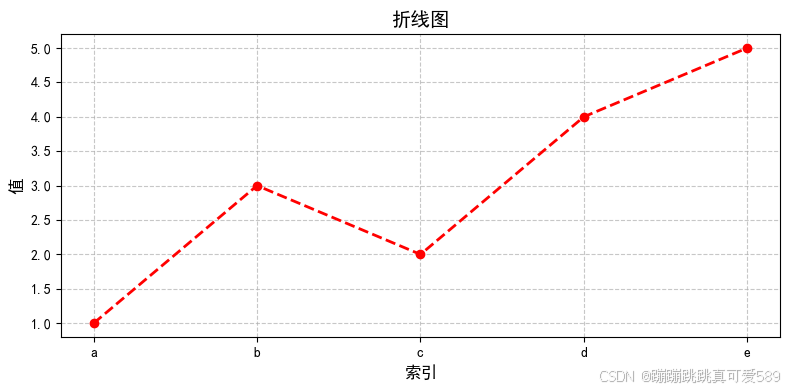
2.7.3.3、绘制柱状图
plt.figure(figsize=(8, 4))
plt.bar(s.index, s.values, color='b', alpha=0.7)
plt.title('柱状图', fontsize=14)
plt.xlabel('索引', fontsize=12)
plt.ylabel('值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show() 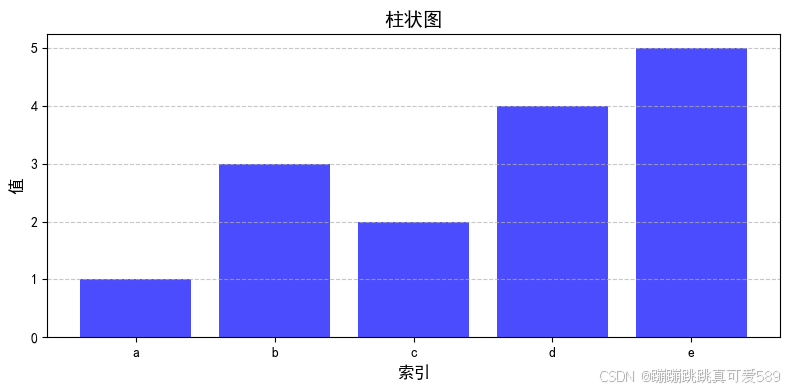
2.7.3.4、绘制散点图
plt.figure(figsize=(8, 4))
plt.scatter(s.index, s.values, color='g', s=100) # s为点的大小
plt.title('散点图', fontsize=14)
plt.xlabel('索引', fontsize=12)
plt.ylabel('值', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show() 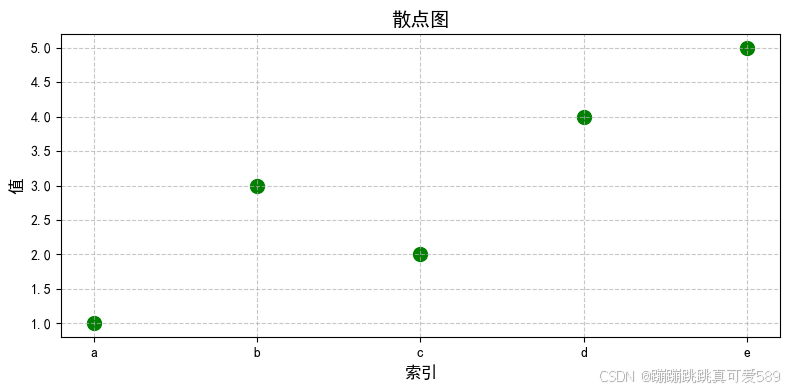
2.7.3.5、绘制直方图
plt.figure(figsize=(8, 4))
plt.hist(s.values, bins=3, alpha=0.7, color='purple', edgecolor='black')
plt.title('直方图', fontsize=14)
plt.xlabel('值', fontsize=12)
plt.ylabel('频率', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show() 
2.7.3.6、绘制箱线图
plt.figure(figsize=(8, 4))
plt.boxplot(s, patch_artist=True, boxprops=dict(facecolor='orange'), medianprops=dict(color='black'))
plt.title('箱线图', fontsize=14)
plt.ylabel('值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()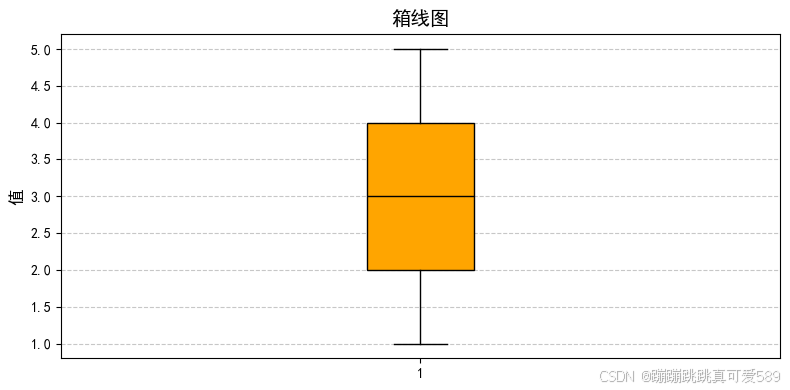
2.8、其他常用方法
2.8.1、 unique
该函数用于返回 Series 中的唯一值。这个方法返回一个数组,其中包含了 Series 中 所有唯一的值。数组中的值是按照它们在原始 Series 中首次出现的顺序排列的。
Series.unique()import pandas as pd
# 创建一个 Series
s = pd.Series(['apple', 'banana', 'apple', 'orange', 'banana', 'banana'])
# 获取唯一值
unique_values = s.unique()
# 输出唯一值
print(unique_values)
print(type(unique_values))
print(len(unique_values))
num = s.nunique()
print(num)2.8.2、 nunique
该函数用于计算 Series 中唯一值的数量。这个方法返回一个整数,表示 Series 中唯 一值的数量。
Series.nunique(dropna=True)| 描述 | 说明 |
|---|---|
| dropna | 布尔值,默认为 True。如果为 True,则在计算唯一值数量之前,会 先从 Series 中排除 NaN 值。 |
import pandas as pd
# 创建一个 Series
s = pd.Series(['apple', 'banana', 'apple', 'orange', 'banana', 'banana'])
# 计算唯一值的数量(排除 NaN)
unique_count = s.nunique(dropna=True)
# 输出唯一值的数量
print(unique_count)2.8.3、 value_counts
该方法用于计算 Series 中每个值的出现次数。这个方法返回一个包含每个唯一值及 其对应出现次数的 Series。
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)| 描述 | 说明 |
|---|---|
| normalize | 布尔值或 ‘all’,默认为 False。如果为 True,返回每个值的相对频 率;如果为 ‘all’,则返回所有值的相对频率之和为 1。 |
| sort | 布尔值,默认为 True。如果为 True,结果将按计数值降序排序。 |
| ascending | 布尔值,默认为 False。如果为 True,结果将按计数值升序排 序。 |
| bins | 用于离散化连续数据,可以是整数或分位数数组。如果指定了 果将是每个 bin 的计数。 |
| dropna | 布尔值,默认为 True。如果为True,则排除 NaN 值。 |
import pandas as pd
# 创建一个 Series
s = pd.Series(['apple', 'banana', 'apple', 'orange', 'banana', 'banana'])
# 计算每个值的出现次数
value_counts = s.value_counts(ascending=True)
# 输出每个值的出现次数
print(value_counts)2.8.4、 describe
该方法用于生成描述性统计信息。这个方法返回一个包含计数、均值、标准差、最小 值、25% 分位数、中位数、75% 分位数和最大值的 Series。
Series.describe(percentiles=None, include=None, exclude=None)| 描述 | 说明 |
|---|---|
| percentiles | 数值列表或数值元组,默认为 [.25, .5, .75],表示要包含在输 出中的分位数。 |
| include | 字符串或类型列表,用于指定要包括在结果中的数据类型。默认为 None,即包括所有数字类型。 |
| exclude | 字符串或类型列表,用于指定要从结果中排除的数据类型。默认为 None。 |
import pandas as pd
# 创建一个 Series
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 生成描述性统计信息
description = s.describe()
# 输出描述性统计信息
print(description)
2.8.5、 copy
该函数用于创建 Series 对象的一个副本。
Series.copy(deep=True)| 描述 | 说明 |
|---|---|
| deep | 布尔值,默认为 True。当 deep=True 时,会进行深拷贝,即复制数据和 索引的副本,而不是仅仅复制引用。当 deep=False 时,会进行浅拷贝,即只复 制数据或索引的引用。 |
import pandas as pd
# 创建一个 Series
original_series = pd.Series([1, 2, 3, 4, 5])
# 创建一个深拷贝
deep_copied_series = original_series.copy()
# 创建一个浅拷贝
shallow_copied_series = original_series.copy(deep=False)
# 修改深拷贝中的数据
deep_copied_series[0] = 999
# # 输出原始 Series 和深拷贝后的 Series
# print("Original Series:\n", original_series)
# print("Deep Copied Series:\n", deep_copied_series)
# 修改浅拷贝中的数据
shallow_copied_series[1] = 888
# 输出原始 Series 和浅拷贝后的 Series
print("Original Series after shallow copy modification:\n", original_series)
print("Shallow Copied Series:\n", shallow_copied_series)2.8.6、 reset index
该函数用于重置 Series 的索引,将原来的索引转换为一个列,并将一个新的默认整 数索引赋给 Series。
Series.reset_index(level=None, *, drop=False, name=no_default, inplace=False, allow_duplicates=False)| 描述 | 说明 |
|---|---|
| level | int 或 level 名,可选。如果 Series 是多级索引(MultiIndex),则只移除 指定的级别。默认为 None,移除所有级别。 |
| drop | 布尔值,默认为 False。如果为 True,则不将旧索引添加为新列,直接丢 弃。 |
| name | 字符串,可选。用于新列的名称,默认为 no_default。如果未指定,并且 索引有名字,则使用索引的名字。 |
| inplace | 布尔值,默认为 False。如果为 True,则在原地修改 Series,不返回新 的对象。 |
| allow_duplicates | 布尔值,默认为 False。如果为 True,则允许在重置索引后 出现重复的索引值。默认情况下,如果出现重复的索引值,Pandas 会抛出错 误,对Series无用。 |
import pandas as pd
import numpy as np
# 创建一个简单的Series对象
data = pd.Series(np.random.randint(1, 100, 5), index=['c', 'a', 'e', 'b', 'd'])
# 对Series进行排序
sorted_series = data.sort_values()
# 重置索引
reset_indexed_series = sorted_series.reset_index(drop=False)
print("排序后的Series:")
print(sorted_series)
print("重置索引后的Series:")
print(reset_indexed_series)2.8.7、 info
用于显示Series的概要信息的方法。这个方法提供了关于Series的元数据,包括数据 类型、非空值的数量、内存使用情况等。
Series.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=True)| 描述 | 说明 |
|---|---|
| verbose | 布尔值或None,默认为None。如果为True,则输出更详细的信息。 |
| buf | 一个文件-like对象,如果提供,则将输出写入这个对象而不是标准输出。 |
| max_cols | int,用于显示的最大列数。如果列数超过这个值,则显示“…”。 |
| memory_usage | 布尔值或str,默认为None。如果为True,则显示内存使用情 况。如果设置为’deep’,则会计算列的内存使用情况,这可能非常慢。 |
| show_counts | 布尔值,默认为True。如果为True,则显示非空值的数量。 |
import numpy as np
import pandas as pd
# 创建一个示例Series
s = pd.Series([1, 2, np.nan, 4, 5], name='example_series', index=['a', 'b', 'c', 'd', 'e'])
# 显示Series的概要信息
print(s.info())2.8.8、 apply
对 Series 中的每个元素应用一个函数,并返回一个结果 Series。
Series.apply(func, convert_dtype=True, args=(), **kwargs)| 描述 | 说明 |
|---|---|
| func | 一个函数,它将被应用到 Series 的每一个元素上。这个函数可以是 Python 的内置函数,也可以是用户自定义的函数。 |
| convert_dtype | 布尔值,默认为True。如果为True,则在可能的情况下, Pandas 会尝试将结果转换为适合的数据类型。 |
| args | 一个元组,包含传递给 func 的位置参数。 |
| **kwargs | 一个字典,包含传递给 True,则在可能的情况下, func的关键字参数。 |
import pandas as pd
# 创建一个Series
series = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
# 使用 apply 方法结合 lambda 函数,对 series 中的每个元素执行平方操作
res = series.apply(lambda x: x ** 2)
# 打印结果,输出每个元素的平方值
print(res)
2.8.9、 map
对 Series 中的每个元素应用Series 的每个一个映射,它允许你将一个函数应用到 元素上,或者将一个字典或 Series 映射到 Series.map(arg, na_action=None) Series 的值上。
Series.map(arg, na_action=None)| 描述 | 说明 | ||||||
|---|---|---|---|---|---|---|---|
| arg | 这可以是以下几种类型:
|
||||||
| na_action | 默认为 None。如果设置为 ‘ignore’,并且 arg 是一个函数,那么 将忽略 NaN 值,并保留它们不变。 |
import pandas as pd
# 创建一个 Series
s = pd.Series([1, 2, 3, 4, 5])
# 定义一个函数,用于将值翻倍
def double(x):
return x * 2
# 使用 map 方法应用这个函数
s_doubled = s.map(double)
print(s_doubled)
import pandas as pd
# 创建一个映射字典
grade_mapping = {
90: 'A',
80: 'B',
70: 'C',
60: 'D',
0: 'F'
}
# 创建一个成绩的 Series
grades = pd.Series([80, 92, 77, 80, 100])
# 使用 map 方法应用这个字典
grades_mapped = grades.map(grade_mapping)
print(grades_mapped)import pandas as pd
# 创建一个名为series1的Series对象
series1 = pd.Series([50, 60, 70, 80, 90], index=['a', 'b', 80, 'd', 'e'])
# 创建一个名为grades的Series对象,代表成绩数据
grades = pd.Series([80, 92, 77, 59, 100], index=[0, 1, 2, 3, 4])
print(series1)
print(grades)
# 使用grades的map方法,将grades中的每个值作为键,去series1中查找对应的键值并返回
res = grades.map(series1)
# 打印输出新生成的Series对象res
print(res)三、 二维数组DataFrame
DataFrame 是 Pandas 中的一个表格型的数据结构,包含有多列的数据,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由 Series 组成的字典。

3.1、DataFrame的创建
在Pandas中,使用DataFrame来创建二维数组DataFrame
class pandas.DataFrame(data=None, index=None, columns=None,
dtype=None, copy=None)| 描述 | 说明 |
|---|---|
| data | 列表,其中每个元素是一行数据。 字典,其中键是列名,值是列值(列表或数组)。 2d-Ndarray。 Series对象,每个 Series成为一列 |
| index | 行标签,如果没有指定,默认是整数索引[0, ..., n-1],其中 n 是数据中的行数。 |
| columns | 列标签,如果没有指定,则列标签从数据源中推断。 |
| dtype | 指定某列的数据类型。如果指定,则所有列都将转换为指定的数据类型。 |
| copy | 布尔值,默认为False。如果为True,则复制数据;如果为False,则尽可 能避免复制数据 |
3.1.1、使用列表创建
import pandas as pd
# 创建一个包含学生信息的嵌套列表,每个子列表代表一个学生的姓名、年龄和成绩
data_list = [
['小明', 20, 85],
['小红', 18, 90],
['小刚', 22, 88]
]
# 定义列名,分别对应姓名、年龄和成绩
columns = ['姓名', '年龄', '成绩']
# 使用pandas库创建一个DataFrame,将数据列表和列名作为参数传入
df = pd.DataFrame(data_list, columns=columns)
# 打印DataFrame以查看数据
print(df) 
3.1.2、使用字典创建
可以使用一个字典来创建DataFrame,其中字典的键将作为列名,字典的值可以是列 表、数组等可迭代对象,它们的长度要一致,代表每一列的数据。
import pandas as pd
# 定义一个字典,其中包含两组数据:姓名和年龄
data = {
'Name': ['Tom', 'Nick', 'John'], # 'Name' 键对应一个包含姓名的列
'Age': [20, 21, 22] # 'Age' 键对应一个包含年龄的列
}
# 使用pd.DataFrame()函数将字典转换为DataFrame对象
# 这里,data字典中的键自动成为DataFrame的列名,值成为列的数据
df = pd.DataFrame(data)
# 打印DataFrame对象,查看其内容
print(df)
3.1.3、使用Ndarray数组创建
import pandas as pd
# 创建三个pandas Series对象
s1 = pd.Series(['小明', '小红', '小刚'], name='姓名')
s2 = pd.Series([20, 18, 22], name='年龄')
s3 = pd.Series([85, 90, 88], name='成绩')
# 将Series对象组合成一个字典,键是Series的名称,值是Series本身
# 然后将这个字典传递给DataFrame构造函数来创建一个DataFrame
df = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3})
# 打印DataFrame对象,查看其内容
print(df)

import pandas as pd
import numpy as np
# 定义一个二维Ndarray数组,其中包含两组数据:姓名和年龄
data_array = np.array([
['Tom', 20],
['Nick', 21],
['John', 19]
])
# 使用pd.DataFrame()函数将二维数组转换为DataFrame对象
df = pd.DataFrame(data_array, columns=['Name', 'Age'])
# 打印
print(df)3.1.4、使用Series创建
如果有多个Series对象,也可以将它们组合成一个DataFrame。
import pandas as pd
# 创建三个pandas Series对象
s1 = pd.Series(['小明', '小红', '小刚'], name='姓名')
s2 = pd.Series([20, 18, 22, 0], name='年龄')
s3 = pd.Series([85, 90, 88], name='成绩')
s4 = pd.Series(name='test')
# 使用concat拼接,并指定轴为1
df = pd.concat([s1, s2, s3, s4], axis=1)
# 打印DataFrame对象,查看其内容
print(df)
3.2、DataFrame的属性
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=[3, 4, 5])
print(df)
3.2.1、 index
返回DataFrame的行索引。
print(df.index)
#Index([3, 4, 5], dtype='int64')3.2.2、 columns
返回DataFrame的列名。
print(df.columns)
#Index(['姓名', '年龄', '成绩'], dtype='object')3.2.3、 values
返回DataFrame中数据的Ndarray表示
print(df.values)
# [['小明' 20 85]
# ['小红' 18 90]
# ['小刚' 22 88]]3.2.4、 dtypes
返回每列的数据类型。
print(df.dtypes)
# 姓名 object
# 年龄 int64
# 成绩 int64
# dtype: object3.2.5 、shape
返回DataFrame的形状(行数,列数)。
print(df.shape)
#(3, 3)3.2.6、 size
返回DataFrame中的元素数量。
print(df.size)
#93.2.7、 empty
返回DataFrame是否为空。
import pandas as pd
import numpy as np
data = [None]
df = pd.DataFrame(data, index=['a'])
print(df)
print(df.empty)
3.2.8 、T
返回DataFrame的转置。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
res = df.T
print(res)
3.2.9、 axes
返回行轴和列轴的列表。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
print(df.axes)
3.2.10、 ndim
返回DataFrame的维度数。对于标准的二维DataFrame,这个值通常是2。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
print(df.ndim)
3.2.11 、attrs
允许用户存储DataFrame的元数据,它是一个字典,可以用来存储任意与 DataFrame相关的额外信息。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
df.attrs['creator'] = '哈哈哈哈哈哈哈哈哈哈哈'
df.attrs['created_at'] = '2025-3-8'
print(df.attrs)
3.3、DataFrame中元素的索引与访问
3.3.1、 使用列名访问
对于DataFrame来说,可以直接使用列名来访问某一列的数据,返回的是一个Series 对象。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
print(df['姓名'])
print(df[['姓名', '年龄']])
print(df['成绩']['b']) 


3.3.2、 loc和iloc
可以使用loc与 iloc属性访问单个或多个数据,其语法为:
df.loc[row_label, column_label]
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
print(df.loc['a', '姓名'])
print(df.iloc[1, 0])
print(df.loc['a':'b', '姓名':'成绩'])
print(df.iloc[0, 0])
print(df.iloc[0:1, 0:1]) 


3.3.3、 at和iat
使用at和 iat属性来访问单个数据。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data)
print(df)
print(df.at[0, '姓名':'年龄'])
print(df.iat[0, 0])
3.3.4、 head
该方法用于获取DataFrame的前 n 行。默认情况下,如果不指定 n 的值,它会返回 前5行。
DataFrame.head(n=None)| 描述 | 说明 |
|---|---|
| n | 是可选参数,用于指定要返回的行数。如果不提供该参数,默认值为5。 |
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'B': [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
# 使用head方法获取前5行
print(df.head(3)) 
3.3.5、 tail
该方法用于获取DataFrame的最后n行。与 DataFrame.head 方法类似,如果不指
定 n 的值,它会默认返回最后5行。
DataFrame.tail(n=5)| 描述 | 说明 |
|---|---|
| n | 是可选参数,用于指定要返回的行数。如果不提供该参数,默认值为5。 |
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'B': [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
# 使用tail方法获取最后5行
print(df.tail())
3.3.6、 isin
DataFrame.isin(values) 方法用于检查DataFrame中的元素是否包含在指定的集 合 values 中。这个方法会返回一个布尔型DataFrame,其中的每个元素都表示原 始DataFrame中对应元素是否在 values 中。
DataFrame.isin(values)| 描述 | 说明 |
|---|---|
| values | 可以是单个值、列表、元组、集合或另一个DataFrame/Series。如果 values 是一个字典,键是列名,值是列表或元组,表示该列中要检查的值。 |
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': ['a', 'b', 'c', 'd', 'e']
}
df = pd.DataFrame(data)
print(df)
# 检查DataFrame中的元素是否包含在指定的值集合中
values_to_check = [2, 4, 'c']
print(df.isin(values_to_check))
print(df['C']) 
3.3.7、 get
用于从DataFrame中获取列,它类似于直接使用 df[key] 来访问列,但是当列不存 在时,get 方法提供了一个更安全的方式来处理这种情况,你可以指定一个默认值, 而不是引发一个错误。
DataFrame.get(key, default=None)| 描述 | 说明 |
|---|---|
| key | 想获取的列的名称。 |
| default | 如果列不存在时返回的默认值。None |
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data)
# 获取'成绩'列
scores = df.get('成绩')
print(scores)
# 尝试获取不存在的列,返回指定值
non_existent_column = df.get('体重', default='Not Found')
print(non_existent_column)
3.4、数据操作
3.4.1、 数据清洗
3.4.1.1、 isnull()
用于检测 DataFrame 中的缺失值,它会返回一个相同形状的布尔型 DataFrame,其中每个元素表示原始 DataFrame 中相应位置的元素是否是缺失 值。
import pandas as pd
import numpy as np
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [4, np.nan, 6],
'C': [7, 8, 9]
})
# 打印原始DataFrame
print(df)
# 使用 isnull() 方法检测缺失值
missing_values = df.isnull()
print(missing_values)3.4.1.2、dropna()
用于删除 DataFrame 中的缺失值。
DataFrame.dropna(axis=0, how=any, thresh=_NoDefault.no_default, subset=None, inplace=False, ignore_index=False)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’},默认为 0。0表示按行删除,1表示按列删 除 |
| how | {‘any’, ‘all’},默认为 ‘any’。 ‘any’:如果行或列中的任意一个值是 NaN,就删除该行或列。 ‘all’:如果行或列中的所有值都是 NaN,才删除该行或列。 |
| thresh | 指定每行或每列至少需要有多少个非缺失值才能保留。如果设置此参 数,how 参数将被忽略。 |
| subset | 指定在哪些列中搜索缺失值。如果未指定,则在所有列中搜索。 |
| inplace | 是否修改 DataFrame 而不是创建新的 DataFrame。 |
| ignore_index | 布尔值,默认为 False。如果为 True,则不保留原始 DataFrame 的索引 |
import pandas as pd
import numpy as np
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
'A': [1, np.nan, np.nan],
'B': [4, np.nan, 6],
'C': [7, 8, 9]
})
# 打印原始DataFrame
print(df)
# 删除任何含有 NaN 值的行
df_cleaned = df.dropna(subset=['B'])
print(df_cleaned)3.4.1.3、fillna()
用于填充 DataFrame 中的缺失值。
DataFrame.fillna(value=None, *, method=None, axis=0, inplace=False, limit=None)| 描述 | 说明 |
|---|---|
| value | 填充值,可以是单个值,也可以是字典(对不同的列填充不同的值),或 者一个 Series。 |
| method | {‘bfill’, ‘ffill’},默认为无默认值。 ‘bfill’ 或 ‘backfill’:使用下一个有效观测值填充。 {0 或 ‘index’, 1 或 ‘columns’},默认为0。 |
| axis | {0 或 ‘index’, 1 或 ‘columns’},默认为0。 |
| inplace | 布尔值,默认为 False。如果为 True,则在原地修改 DataFrame 而不 返回新的 DataFrame。 |
| limit | int,默认为无默认值。如果指定了method,则该参数限制连续填充的 数量。 |
import pandas as pd
import numpy as np
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [np.nan, np.nan, 6],
'C': [7, np.nan, 9]
})
# 打印原始DataFrame
print(df)
# 使用固定值填充缺失值
df_filled_value = df.fillna(value=0, limit=1, axis=1)
print(df_filled_value)
# 使用字典填充
data = {
'A': 'a',
'B': 'b',
'C': 'c'
}
df_filled_dict = df.fillna(value=data)
print(df_filled_dict)
# 使用Series填充
data_series = pd.Series(['a', 'b', 'c'], ['A', 'B', 'C'])
df_filled_series = df.fillna(value=data_series)
print(df_filled_series)
# 使用前一个有效观测值填充缺失值
df_filled_ffill = df.fillna(method='ffill')
print(df_filled_ffill)
# 使用后一个有效观测值填充缺失值
df_filled_bfill = df.fillna(method='bfill', axis=1)
print(df_filled_bfill)3.4.1.4、drop_duplicates()
用于删除 DataFrame 中的重复行。
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)| 描述 | 说明 |
|---|---|
| subset | 指定要检查重复的列名或列名列表,默认值为 None,表示检查所有 列。 |
| keep | {‘first’, ‘last’, False},默认为 ‘first’。 ‘first’:保留第一次出现的重复项。 ‘last’:保留最后一次出现的重复项。 False:删除所有重复项。 |
| inplace | 是否修改 DataFrame 而不是创建新的 DataFrame。 |
| ignore_index | 是否重置索引值。 |
import pandas as pd
# 创建一个包含重复行的 DataFrame
df = pd.DataFrame({
'A': [1, 1, 2, 2, 3, 3],
'B': [1, 1, 2, 3, 3, 3],
'C': [1, 1, 2, 2, 3, 3]
})
# 打印原始DataFrame
print(df)
# 删除重复行,保留第一次出现的重复项
df_dedup_first = df.drop_duplicates(keep=False)
print(df_dedup_first)
# 根据指定列删除重复行
df_dedup_column = df.drop_duplicates(subset=['A'])
print(df_dedup_column)
# 删除重复行,保留最后一次出现的重复项
df_dedup_last = df.drop_duplicates(keep='last')
print(df_dedup_last)
# 删除所有重复行
df_dedup_all = df.drop_duplicates(keep=False)
print(df_dedup_all)3.4.2、 数据转换
3.4.2.1、replace()
用于替换 DataFrame 中的值。
DataFrame.replace(to_replace=None, value=_NoDefault.no_default, inplace=False, limit=None, regex=False, method=_NoDefault.no_default)| 描述 | 说明 |
|---|---|
| to_replace | 被替换的内容,可以是 scalar, list, dict, regex。如果是字典,则键 是要替换的值,值是相应的替换值。 |
| value | 替换后的值。可以是单个值、列表或数组,与 to_replace 长度相同。 |
| inplace | 是否在原地修改 DataFrame。 |
| limit | 限制替换的数量。可以是整数,表示最多替换多少个值。 |
| regex | 是否使用正则表达式进行匹配。 |
| method | 'pad' 或 'ffill':使用前面的数据向后填充。 'backfill' 或 'bfill':使用后面的数据向前填充。 |
import pandas as pd
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, 1, 4, 5],
'B': ['a', 'b', 'a', 'b', 'a']
})
data = {
1: 20
}
# 用数字 100 替换所有的 1
df_replaced = df.replace(to_replace=data)
# 用字符串 'z' 替换所有的 'a'
df_replaced = df.replace(to_replace='a', value='z')
# 使用字典替换多个值
df_replaced = df.replace({
2: 200,
'b': 'y'
})
# 使用正则表达式替换
df_replaced = df.replace(to_replace=r'^a$', value='z', regex=True)3.4.2.2、pivot()
用于改变表格形状格式。
DataFrame.pivot(columns, index=typing.Literal[<no_default>], values=typing.Literal[<no_default>])| 描述 | 说明 |
|---|---|
| columns | 作为新 DataFrame 的行索引的列名。可以是单个列名或列名列表。 |
| index | 作为新 DataFrame 的列标签的列名。可以是单个列名或列名列表。 |
| values | 作为新 DataFrame 的值的列名。可以是单个列名或列名列表。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']
})
# 打印原始DataFrame
print(df)
# 使用pivot方法对DataFrame进行重塑,其中foo作为行索引,bar作为列索引,baz作为值
res1 = df.pivot(index='foo', columns='bar', values='baz')
# # 打印重塑后的DataFrame
print(res1)
# 使用pivot方法对DataFrame进行重塑,其中foo作为行索引,bar作为列索引,baz、zoo作为值
res2 = df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])
# 打印重塑后的DataFrame
print(res2)

3.4.2.3、melt()
用于改变表格形状格式。
DataFrame.melt(id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)| 描述 | 说明 |
|---|---|
| id_vars | 保持不变的列名或列名列表。 |
| value_vars | 字符串或字符串列表,可选。要重塑的列名或列名列表。这些列的 值将被展平到新的行中。 |
| var_name | 新的列名,用于存储原来列的名称。默认值为 None,表示使用默认名称 |
| value_name | 字符串。新的列名,用于存储原来列的值。默认值为 'value'。 |
| col_level | 整数或列标签,可选。如果 DataFrame 的列是多级索引,指定要使用的级别。默认值为 None,表示使用所有级别。 |
| ignore_index | 是否忽略原来的索引,重新生成一个新的默认整数索引。默认值 为 True。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}
})
# 打印原始DataFrame
print(df)
# 使用melt方法对DataFrame进行重塑
res1 = df.melt(id_vars=['A'], value_vars=['B'],)
# 打印重塑后的DataFrame
print(res1)
3.4.2.4、pivot_table()
用于生成一个指定格式的数据透视表。
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)| 描述 | 说明 |
|---|---|
| values | 要聚合的列名或列名列表。如果未指定,则使用所有数值列。 |
| index | 作为新 DataFrame 的行索引的列名或列名列表。 |
| columns | 作为新 DataFrame 的列标签的列名或列名列表。 |
| aggfunc | 聚合函数,可以是: 单个函数(如 'mean'、 'sum'、 'count' 等)。 函数列表(如 ['mean', 'sum'])。 字典,键是列名,值是聚合函数。 |
| fill_value | 用于填充缺失值的值。默认值为 None。 |
| margins | 是否添加总计行和总计列。默认值为 False。 |
| dropna | 是否从结果中删除包含缺失值的行。默认值为 True。 |
| margins_name | 总计行和总计列的名称。默认值为 'All'。 |
| observed | 是否仅显示已观察到的类别。默认值为 False。 |
| sort | 是否对结果进行排序。默认值为 True。 |
import numpy as np
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]
})
# 打印原始DataFrame
print(df)
# 使用pivot_table方法创建一个数据透视表
table = df.pivot_table(values=['D', 'E'], index=['A',], columns=['C'], aggfunc=np.sum, fill_value='a', margins=True, margins_name='test')
# 打印数据透视表
print(table) 

3.4.2.5、 astype()
用于转换 DataFrame 中指定列的数据类型。
DataFrame.astype(dtype, copy=None, errors='raise')| 描述 | 说明 |
|---|---|
| dtype | 新的数据类型,可以是字典或数据类型。如果是字典,则键是列名,值是 要转换为的数据类型。如果指定为单一数据类型,则所有列都将转换为该类型。 |
| copy | 布尔值,默认为 本。如果为 None。如果为 True,则在转换数据之前创建数据的副 False,则尽可能地避免复制,但这可能会影响到输入数据的原始 DataFrame。如果为 None(默认值),则仅在需要时复制数据。 |
| errors | {‘raise’, ‘ignore’},默认为 ‘raise’。控制当转换失败时的行为。如果为 ‘raise’,则在无法转换数据时抛出异常;如果为 ‘ignore’,则在无法转换数据时保 持原始数据类型不变。 |
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4.5, 5.5, 6.5],
'C': ['7', '8', '9']
})
# 打印原始DataFrame
print(df)
# 将列 'A' 转换为浮点数类型
df['A'] = df['A'].astype(float)
# 使用字典将多列转换为不同的数据类型
# 将列 'B' 转换为整数类型,列 'C' 也转换为整数类型
df = df.astype({
'B': int,
'C': int
})
# 打印转换后的DataFrame
print(df)
# 打印DataFrame中各列的数据类型
print(df.dtypes)


3.4.3 、数据排序
3.4.3.1、 sort_values()
用于根据一个或多个列的值对 DataFrame 进行排序。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)| 描述 | 说明 |
|---|---|
| by | 用于排序的列名或列名列表。 |
| axis | {0 or ‘index’, 1 or ‘columns’},默认为 0。沿着哪个轴进行排序。 |
| ascending | 排序的方向,True表示升序,False表示降序, 默认为True。 |
| inplace | 是否在原地修改 DataFrame。 |
| kind | {‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’},默认为 ‘quicksort’。排序 算法。 |
| na_position | {‘first’, ‘last’},默认为 ‘last’。缺失值的放置位置。 |
| ignore_index | 布尔值,默认为 False。是否忽略原来的索引,重新生成一个 新的默认整数索引。 |
| key | 函数,默认为None。应用于 by 中每个列的函数,排序将基于函数的返回 值。 |
import numpy as np
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({
'col1': ['A', 'A', 'B', np.nan, 'D', 'C'],
'col2': [2, 1, 9, 8, 7, 4],
'col3': [3, 1, 9, 4, 2, 3],
'col4': ['a', 'B', 'c', 'D', 'e', 'F']
})
# 打印原始DataFrame
print(df)
# 根据 'col1' 列对DataFrame进行排序
res1 = df.sort_values(by=['col1'])
# 打印排序后的DataFrame
print(res1)
# 根据 'col1' 和 'col2' 列对DataFrame进行排序
res2 = df.sort_values(by=['col1', 'col3'])
# 打印排序后的DataFrame
print(res2)


3.4.3.2、sort_index()
用于根据索引对 DataFrame 进行排序。
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)| 描述 | 说明 |
|---|---|
| axis | {0 or ‘index’, 1 or ‘columns’},默认为 0。表示沿着哪个轴进行排序。0按 照行标签排序,1按照列标签排序。 |
| level | 如果索引是多级索引,指定要排序的级别。可以是整数或整数列表。 |
| ascending | 默认为 True。表示排序是升序还是降序。 |
| inplace | 是否在原地修改 DataFrame。 |
| kind | {‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’},默认为 ‘quicksort’。排序 算法。 |
| na_position | {‘first’, ‘last’},默认为 ‘last’。缺失值的放置位置。 |
| sort_remaining | 是否对剩余的级别进行排序。仅在多级索引时有效。默认值为True。 |
| ignore_index | 是否忽略原来的索引,重新生成一个新的默认整数索引。默认值 为 False。 |
| key | 函数,默认为 None。应用于索引的函数,排序将基于函数的返回值。 |
import pandas as pd
import numpy as np
# 创建一个多级索引的DataFrame
arrays = [np.array(['qux', 'qux', 'foo', 'foo']),
np.array(['two', 'one', 'two', 'one'])]
df = pd.DataFrame({'C': [1, 2, 3, 4], 'B': [4, 3, 2, 1]}, index=arrays)
print(df)
# # 按第一层索引升序排序
df_sorted_by_first_level = df.sort_index(level=0)
print(df_sorted_by_first_level)
# # 按第二层索引降序排序
df_sorted_by_second_level_desc = df.sort_index(level=1, ascending=False)
print(df_sorted_by_second_level_desc)
# 按整个索引升序排序
df_sorted_by_full_index = df.sort_index()
print(df_sorted_by_full_index) 



3.4.4、 数据筛选
可以使用布尔数组进行索引,选择满足条件的数据。
import pandas as pd
data = {
'姓名': ['小明', '小红', '小刚'],
'年龄': [20, 18, 22],
'成绩': [85, 90, 88]
}
df = pd.DataFrame(data)
print(df)
print(df['成绩'] >= 90)
# 使用布尔索引选择成绩大于或等于90的学生
high_scores = df[df['成绩'] >= 90]
print(high_scores)
3.4.5 、数据拼接
3.4.5.1、 concat()
用于沿一个轴将多个 pandas 对象连接在一起。
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)| 描述 | 说明 |
|---|---|
| objs | 要连接的对象列表。 |
| axis | {0, 1, ‘index’, ‘columns’},默认为 0。 |
| join | 连接方式。可以是: 'outer':取所有索引的并集。 'inner':取所有索引的交集。 |
| ignore_index | 是否忽略原来的索引,重新生成一个新的默认整数索引。默认值 为 False。 |
| keys | 用于生成多级索引的键列表。每个键对应一个对象。 |
| levels | 用于多级索引的级别列表。通常与 华清远见|元宇宙实验中心 yyzlab.com.cn keys 一起使用。 |
| names | 用于多级索引的名称列表。通常与 keys 一起使用。 |
| verify_integrity | 是否验证最终的 DataFrame 是否有重复的索引。默认值为False |
| sort | 是否对结果按照列名进行升序排序。默认值为 False。 |
| copy | 是否复制数据。 |
import pandas as pd
# 创建两个 DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'F': ['F4', 'F5', 'F6', 'F7']},
index=[4, 5, 6, 7])
print(df1)
print(df2)
# 沿着竖直方向拼接两个DataFrame
result = pd.concat([df1, df2], axis=1, join='outer')
print(result)
3.4.5.2、 merge()
用于根据一个或多个键将两个 DataFrame 对象连接起来。
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=None, indicator=False, validate=None)| 描述 | 说明 |
|---|---|
| right | 另一个 DataFrame 对象。 |
| how | {‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认为 ‘inner’。确定连接的类型: ‘left’: 使用左侧(调用 merge的 DataFrame)的索引进行左连接。 ‘right’: 使用右侧(参数 right 中的 DataFrame)的索引进行右连接。 ‘outer’: 使用两个DataFrame的并集连接。 ‘inner’: 使用两个DataFrame的交集连接。 |
| on | 用于合并的列名。如果 left_on 和 right_on 都没有指定,则使用on |
| left_on | 左侧 DataFrame 中用于合并的列名。不与on同时使用。 |
| right_on | 右侧 DataFrame 中用于合并的列名。不与on同时使用。 |
| left_index | 是否使用左侧 DataFrame 的索引作为合并键。默认值为 False。不与on同时使用。 |
| right_index | 是否使用右侧 DataFrame 的索引作为合并键。默认值为 False。不与on同时使用。 |
| sort | 是否对结果进行排序。默认值为 False。 |
| suffixes | 用于重命名重复列的后缀。默认值为 ('_x', '_y')。 |
| copy | 是否复制数据。默认值为 None,表示根据需要自动决定是否复制。 |
| indicator | 是否添加一个指示器列,显示每行来自哪个DataFrame。默认值为 False。 |
| validate | 检查合并键。可以是: 'one_to_one':检查合并键在两者中是否唯一。 'one_to_many':检查合并键在左侧是否唯一。 'many_to_one':检查合并键在右侧是否唯一。 'many_to_many':不检查。 |
import pandas as pd
# 创建两个 DataFrame
df1 = pd.DataFrame({'key1': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]}, index=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame({'key2': ['B', 'D', 'D', 'E'],
'value': [5, 6, 7, 8]}, index=['a', 'c', 'e', 'f'])
print(df1)
print(df2)
# 使用内连接(inner join)合并两个 DataFrame
result = df1.merge(df2, left_on='key1', right_on='key2', how='right', suffixes=('_left', '_right'), indicator=True,)
print(result)
3.4.5.3、 join()
用于将两个对象的列连接起来。
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False, validate=None)| 描述 | 说明 |
|---|---|
| other | 另一个 DataFrame 对象。 |
| on | 用于连接的列名。 |
| how | {‘left’, ‘right’, ‘outer’, ‘inner’}, 默认为 ‘left’。确定连接的类型: ‘left’: 使用左侧(调用 join 的 DataFrame)的索引进行左连接。 ‘right’: 使用右侧(参数 other 中的 DataFrame)的索引进行右连接。 ‘outer’: 使用两个 DataFrame 的索引的并集进行全外连接。 ‘inner’: 使用两个 DataFrame 的索引的交集进行内连接。 |
| lsuffix | 用于重命名重复列的左后缀。默认值为空字符串 ''。 |
| rsuffix | 用于重命名重复列的右后缀。默认值为空字符串 ''。 |
| sort | 是否对结果进行排序。默认值为 False。 |
| validate | 检查合并键。可以是: 'one_to_one':检查合并键在两者中是否唯一。 'one_to_many':检查合并键在左侧是否唯一。 'many_to_one':检查合并键在右侧是否唯一。 'many_to_many':不检查。 |
import pandas as pd
# 创建两个 DataFrame
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]},
index=['k0', 'k1', 'k2', 'k3'])
df2 = pd.DataFrame({'value': [5, 6, 7, 8]},
index=['k1', 'k2', 'k3', 'k4'])
print(df1)
print(df2)
# 使用左连接(left join)根据索引合并两个 DataFrame
result = df1.join(df2, how='left', rsuffix='_right', lsuffix='_left')
print(result) 


3.5、统计计算
3.5.1、 count
用于计算 DataFrame 中非 NaN 值的数量。
DataFrame.count(axis=0, numeric_only=False)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’},决定统计的方向。 如果 axis=0 或 axis='index',则对每列进行计数,返回一个 Series,其 索引为列名,值为每列非 NaN 值的数量。 如果 axis=1 或 axis='columns',则对每行进行计数,返回一个 Series, 其索引为行索引,值为每行非 NaN 值的数量。 |
| numeric_only | 是否只计算数值列中的非 NaN 值的数量,忽略非数值列,默认 为 False。 |
import pandas as pd
import numpy as np
# 创建一个包含 NaN 值的 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': ['foo', 'bar', 'baz', np.nan]
})
print(df)
# 计算每列非 NaN 值的数量
count_per_column = df.count()
print("Count per column:")
print(count_per_column)
# 计算每行非 NaN 值的数量
count_per_row = df.count(axis=1)
print("\nCount per row:")
print(count_per_row)
# 只计算数值列的非 NaN 值的数量
count_numeric_only = df.count(numeric_only=True)
print("\nCount numeric only:")
print(count_numeric_only) A B C
0 1.0 5.0 foo
1 2.0 NaN bar
2 NaN NaN baz
3 4.0 8.0 NaN
Count per column:
A 3
B 2
C 3
dtype: int64
Count per row:
0 3
1 2
2 1
3 2
dtype: int64
Count numeric only:
A 3
B 2
dtype: int643.5.2、 sum
用于计算 DataFrame 中数值的总和。
DataFrame.sum(axis=0, skipna=True, numeric_only=False, min_count=0, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了求和是在 哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行求和,返回一个 Series,其 索引为列名,值为每列的总和。 如果 axis=1 或 axis='columns',则对每行进行求和,返回一个 Series, 其索引为行索引,值为每行的总和。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算总和时会忽略 NaN 值。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行求和, 忽略非数值列。 |
| min_count | 默认为 0。这个参数指定了在计算总和之前,至少需要非 NaN 值的最小数量。如果某个分组中的非 NaN 值的数量小于 min_count,则结果为 NaN。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
# 创建一个包含 NaN 值的 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': ['foo', 'bar', 'baz', 'qux']
})
print(df)
# 计算每列的总和
sum_per_column = df.sum()
print("Sum per column:")
print(sum_per_column)
# 只计算数值列的总和
sum_numeric_only = df.sum(numeric_only=True)
print("\nSum numeric only:")
print(sum_numeric_only)
# 使用 min_count 参数
sum_with_min_count = df.sum(min_count=3)
print("\nSum with min_count=2:")
print(sum_with_min_count) A B C
0 1.0 5.0 foo
1 2.0 NaN bar
2 NaN NaN baz
3 4.0 8.0 qux
Sum per column:
A 7.0
B 13.0
C foobarbazqux
dtype: object
Sum numeric only:
A 7.0
B 13.0
dtype: float64
Sum with min_count=2:
A 7.0
B NaN
C foobarbazqux
dtype: object3.5.3、 mean
用于计算 DataFrame 中数值的平均值。
DataFrame.mean(axis=0, skipna=True, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算平均 值是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的平均值。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的平均值。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算平均值时会忽略 NaN 值。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.mean()
print("mean per column:")
print(sum_per_column)mean per column:
A 2.5
B 6.5
dtype: float643.5.4、 median
用于计算 DataFrame 中数值的中位数。
DataFrame.median(axis=0, skipna=True, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算中位数是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的中位数。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的中位数。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算中位数时会忽略 NaN 值。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.median()
print("median per column:")
print(sum_per_column)mean per column:
A 2.5
B 6.5
dtype: float643.5.5、 min
用于计算 DataFrame 中数值的最小值。
DataFrame.min(axis=0, skipna=True, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算最小值是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的最小值。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的最小值。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算最小值时会忽略 NaN 值。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.min()
print("min per column:")
print(sum_per_column)min per column:
A 1
B 5
dtype: int643.5.6、 max
用于计算 DataFrame 中数值的最大值。
DataFrame.max(axis=0, skipna=True, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算最大值是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的最大值。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的最大值。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算最大值时会忽略 NaN 值。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.max()
print("max per column:")
print(sum_per_column)max per column:
A 4
B 8
dtype: int643.5.7 、var
用于计算 DataFrame 中数值的方差。
DataFrame.var(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算方差是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的方差。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的方差。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算方差时会忽略 NaN 值。 |
| ddof | 整数,默认为 1。Delta Degrees of Freedom,计算样本方差时使用的无 偏估计的自由度修正。对于整个群体的方差, ddof 应该设置为 0。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.var()
print("var per column:")
print(sum_per_column)var per column:
A 1.666667
B 1.666667
dtype: float643.5.8 、std
用于计算 DataFrame 中数值的标准差。
DataFrame.std(axis=0, skipna=True, ddof=1, numeric_only=False, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算标准差是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的标准差。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的标准差。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算标准差时会忽略 NaN 值。 |
| ddof | 整数,默认为 1。Delta Degrees of Freedom,计算样本标准差时使用的无 偏估计的自由度修正。对于整个群体的标准差, ddof 应该设置为 0。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.std()
print("std per column:")
print(sum_per_column)std per column:
A 1.290994
B 1.290994
dtype: float643.5.9 、quantile
用于计算 DataFrame 中数值的分位数。
DataFrame.quantile(q=0.5, axis=0, numeric_only=False, interpolation='linear', method='single')| 描述 | 说明 |
|---|---|
| q | 可以是单个浮点数或浮点数列表,默认为 0.5。要计算的的分位数,应该在 0 到 1 之间。例如,q=0.5 表示中位数。 |
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算分位数是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的分位数。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的分位数。 |
| numeric_only | 布尔值,默认为 False。如果为 True,则只对数值列进行计算, 忽略非数值列。 |
| interpolation | {‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}, 默认为 ‘linear’。这个参数决定了分位数在数据不包含精确分位数值时的插值方法: ‘linear’: 线性插值。 ‘lower’: 选择小于分位数的最大值。 ‘higher’: 选择大于分位数的最小值。 ‘midpoint’: 选择两个相邻数据的中间值。 ‘nearest’: 选择最接近分位数的值。 |
| method | {‘single’, ‘table’}, 默认为 ‘single’。这个参数决定了计算分位数的方法: ‘single’: 对每列或每行单独计算分位数。 ‘table’: 使用整个表的分位数。选择table时,插值方法只能是higher、 lower、nearest之一。 |
import pandas as pd
import numpy as np
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
})
sum_per_column = df.quantile()
print("quantile per column:")
print(sum_per_column)quantile per column:
A 2.5
B 6.5
Name: 0.5, dtype: float643.5.10、 cummax
用于计算 DataFrame 中数值的累积最大值。
DataFrame.cummax(axis=0, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算累积最大值是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的累积最大值。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的累积最大值。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算累积最大值时会忽略 NaN 值。 |
| *args 和 **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, 3, 2, 1],
})
print(df)
# 计算每列的累积最大值
cummax_per_column = df.cummax(axis=0)
print("Cumulative max per column:")
print(cummax_per_column)
# 计算每行的累积最大值
cummax_per_row = df.cummax(axis=1)
print("\nCumulative max per row:")
print(cummax_per_row) A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 2.0
4 5.0 1.0
Cumulative max per column:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 5.0
3 4.0 5.0
4 5.0 5.0
Cumulative max per row:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 4.0
4 5.0 5.03.5.11、 cummin
用于计算 DataFrame 中数值的累积最小值。
DataFrame.cummin(axis=0, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算累积最小值是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的累积最小值。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的累积最小值。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算累积最小值时会忽略 NaN 值。 |
| *args 和 **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, 3, 2, 1],
})
print(df)
# 计算每列的累积最小值
cummin_per_column = df.cummin(axis=0)
print("Cumulative min per column:")
print(cummax_per_column)
# 计算每行的累积最小值
cummin_per_row = df.cummin(axis=1)
print("\nCumulative min per row:")
print(cummax_per_row) A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 2.0
4 5.0 1.0
Cumulative min per column:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 5.0
3 4.0 5.0
4 5.0 5.0
Cumulative min per row:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 4.0
4 5.0 5.03.5.12、 cumsum
用于计算 DataFrame 中数值的累积 和。
DataFrame.cumsum(axis=0, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算累积 和是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的累积 和。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的累积 和。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算累积 和时会忽略 NaN 值。 |
| *args 和 **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, 3, 2, 1],
})
print(df)
# 计算每列的累积和
cumsum_per_column = df.cumsum(axis=0)
print("Cumulative sum per column:")
print(cummax_per_column)
# 计算每行的累积和
cumsum_per_row = df.cumsum(axis=1)
print("\nCumulative sum per row:")
print(cummax_per_row) A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 2.0
4 5.0 1.0
Cumulative sum per column:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 5.0
3 4.0 5.0
4 5.0 5.0
Cumulative sum per row:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 4.0
4 5.0 5.03.5.13、 cumprod
用于计算 DataFrame 中数值的累积乘积。
DataFrame.cumprod(axis=0, skipna=True, *args, **kwargs)| 描述 | 说明 |
|---|---|
| axis | {0 或 ‘index’, 1 或 ‘columns’, None}, 默认为 0。这个参数决定了计算累积乘积是在哪个轴上进行: 如果 axis=0 或 axis='index',则对每列进行计算,返回一个 Series,其 索引为列名,值为每列的累积乘积。 如果 axis=1 或 axis='columns',则对每行进行计算,返回一个 Series, 其索引为行索引,值为每行的累积乘积。 |
| skipna | 布尔值,默认为 True。如果为 True,则在计算累积乘积时会忽略 NaN 值。 |
| *args 和 **kwargs | 其他关键字参数。这些参数通常用于兼容性或特殊用途,通常不需 要。 |
import pandas as pd
import numpy as np
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4, 5],
'B': [5, np.nan, 3, 2, 1],
})
print(df)
# 计算每列的累积乘积
cumprod_per_column = df.cumprod(axis=0)
print("Cumulative sum per column:")
print(cummax_per_column)
# 计算每行的累积乘积
cumprod_per_row = df.cumprod(axis=1)
print("\nCumulative sum per row:")
print(cummax_per_row) A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 2.0
4 5.0 1.0
Cumulative sum per column:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 5.0
3 4.0 5.0
4 5.0 5.0
Cumulative sum per row:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 3.0
3 4.0 4.0
4 5.0 5.03.6、分组和聚合
3.6.1、 groupby
用于将 DataFrame 分割成多个组,以便可以对这些组应用聚合函数或执行其他操 作。
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)| 描述 | 说明 |
|---|---|
| by | 用于确定分组依据。 |
| axis | {0 或 ‘index’, 1 或 ‘columns’},默认为 0。这个参数决定了分组是在哪个轴 上进行。 |
| level | 如果轴是多索引,则按指定的索引级别分组。 |
| as_index | 布尔值,默认为 True。当为 True 时,分组名称将作为结果的索引; 如果为 False,则结果会保持原有的 DataFrame 结构,分组名称会作为一个普通 列出现。 |
| sort | 布尔值,默认为 True。如果为 True,则对分组键进行排序;如果为 False,则不排序,保持原有的分组顺序。 |
| group_keys | 布尔值,默认为 True。如果为 True,则将组键添加到聚合后的结 果中;如果为 False,则不添加。 |
| observed | 布尔值,默认为 False。仅当分组依据是多索引且包含分类数据时适 用,如果为 True,则仅显示分类数据中的观察值。 |
| dropna | 布尔值,默认为 True。如果为 True,并且by 是一个列表,则排除任何含有 NaN 的组。 |
import pandas as pd
import numpy as np
# 创建两个列表,它们将用作多级索引的级别
arrays = [['Falcon', 'Falcon', 'Parrot', 'Parrot'], # 第一级索引的值
['Captive', 'Wild', 'Captive', 'Wild']] # 第二级索引的值
# 使用arrays列表创建一个DataFrame,'Max Speed'列包含对应于多级索引的数据
df = pd.DataFrame({'Max Speed': [390., 350., 30., 20.]}, # 数据
index=arrays) # 使用arrays列表作为多级索引
# 打印原始DataFrame,以查看其结构和数据
print(df)
# 使用groupby方法按第一级索引(即'arrays'列表的第一个元素)分组
# level=0表示按照多级索引的第一级进行分组
res = df.groupby(level=1).mean() # 计算每个组(即每个不同的第一级索引值)的平均速度
# 打印分组后的平均值,显示每个动物的Max Speed的平均值
print(res) Max Speed
Falcon Captive 390.0
Wild 350.0
Parrot Captive 30.0
Wild 20.0
Max Speed
Captive 210.0
Wild 185.03.6.2、 transform
对 DataFrame 或其中一个列应用一个函数,并返回一个与原始 DataFrame 具有相 同索引的对象。此方法不会更改原始 DataFrame,而是返回一个新的 DataFrame, 其中包含应用函数后的结果。
DataFrame.transform(func, axis=0, *args, **kwargs)| 描述 | 说明 |
|---|---|
| func | 函数,应用于每个组或列。这个函数可以是一个内置函数,比如 numpy.mean,也可以是一个自定义函数。 |
| axis | {0 或 ‘index’, 1 或 ‘columns’},默认为 0。这个参数决定了函数是在哪个轴 上应用: 如果 axis=0 或 axis='index',则函数按列应用。 如果 axis=1 或 axis='columns',则函数按行应用。 |
| *args | 位置参数,将传递给 func。 |
| **kwargs | 关键字参数,将传递给func |
import pandas as pd
import numpy as np
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50],
'C': [100, 200, 300, 400, 500]
})
print(df)
def square(x):
return x ** 2
# 调用transform函数,并将自定义函数带入
transformed_df = df.transform(lambda x: x + x.sum(), axis=1)
print(transformed_df) A B C
0 1 10 100
1 2 20 200
2 3 30 300
3 4 40 400
4 5 50 500
A B C
0 112 121 211
1 224 242 422
2 336 363 633
3 448 484 844
4 560 605 10553.6.3 、agg
它允许你应用一个或多个聚合函数到 DataFrame 的列或行上,并返回聚合后的结 果。
DataFrame.agg(func=None, axis=0, *args, **kwargs)| 描述 | 说明 |
|---|---|
| func | 函数或函数列表/字典,应用于 DataFrame 的列或行。如果传递一个函 数,它将应用于所有列。如果传递一个函数列表或字典,则可以分别对不同的列 应用不同的函数。可以使用的函数包括 NumPy 的统计函数、Python 的内置函 数、Pandas 的自定义聚合函数,或者自定义的 lambda 函数。 |
| axis | {0 或 ‘index’, 1 或 ‘columns’},默认为 0。这个参数决定了函数是在哪个轴 上应用: 如果 axis=0 或 axis='index',则函数按列应用。 如果 axis=1 或 axis='columns',则函数按行应用。 |
| *args | 位置参数,将传递给 func。 |
| **kwargs | 关键字参数,将传递给func |
import numpy as np
import pandas as pd
# 创建一个 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]
})
print(df)
# 应用单个聚合函数,计算每列的平均值
result = df.agg('mean')
print(result)
# 对列 'A' 应用 'sum' 函数,对列 'B' 应用 'mean' 函数
result = df.agg({'A': 'sum', 'B': 'mean'})
print(result)
# 对所有列应用多个聚合函数
result = df.agg(['min', 'max', 'sum'])
print(result)
# 定义一个自定义函数
def custom_agg(x):
return (x.max() - x.min()) / x.std()
# 使用自定义函数进行聚合
result = df.agg(custom_agg)
print(result) A B
0 1 10
1 2 20
2 3 30
3 4 40
4 5 50
A 3.0
B 30.0
dtype: float64
A 15.0
B 30.0
dtype: float64
A B
min 1 10
max 5 50
sum 15 150
A 2.529822
B 2.529822
dtype: float643.7、数据可视化
3.7.1、plot
用于绘制 DataFrame 数据图形,它允许用户直接从 DataFrame 创建各种类型的图 表,而不需要使用其他绘图库(底层实际上使用了 Matplotlib)。
DataFrame.plot(*args, **kwargs)| 描述 | 说明 |
|---|---|
| kind | {‘line’, ‘bar’, ‘barh’, ‘hist’, ‘box’, ‘kde’, ‘density’, ‘area’, ‘pie’, ‘scatter’, ‘hexbin’},默认为 ‘line’。这个参数决定了要绘制哪种类型的图表。 |
| ax | Matplotlib axes 对象,可选。如果提供,则绘图将在指定的 axes 对象上进 行。 |
| subplots | 布尔值,默认为 False。如果为 True,则每个数值列将绘制在其自己 的子图中。 |
| sharex | 布尔值,默认为 False。如果为 True,并且 subplots 为 True,则所 有子图共享相同的 x 轴。 |
| sharey | 布尔值,默认为 False。如果为 True,并且 subplots 为 True,则所有子图共享相同的 y 轴。 |
| layout | 元组(行数,列数),可选。用于安排子图的布局。 |
| figsize | 元组(宽度,高度),可选。用于设置图表的大小。 |
| use_index | 布尔值,默认为 True。如果为 True,则将 DataFrame 的索引用作 x 轴。 |
| title | 字符串,可选。图表的标题。 |
| grid | 布尔值,默认为 None。如果为 True,则在图表上显示网格线。 |
3.7.2、hist
用于绘制 DataFrame 中数据的直方图。
DataFrame.hist(column=None, by=None, grid=True, xlabelsize=None, xrot=None, ylabelsize=None, yrot=None, ax=None, sharex=False, sharey=False, figsize=None, layout=None, bins=10, backend=None, legend=False, **kwargs)| 描述 | 说明 |
|---|---|
| column | 字符串或字符串列表,可选。用于指定要绘制直方图的列。如果未指 定,则默认绘制所有数值列的直方图。 |
| by | 字符串或字符串列表,可选。用于指定分组变量,以便为每个组绘制直方 图。 |
| grid | 布尔值,默认为 True。是否在直方图上显示网格线。 |
| xlabelsize | 整数,可选。用于设置 x 轴标签的大小。 |
| xrot | 浮点数,可选。用于设置 x 轴标签的旋转角度。 |
| ylabelsize | 整数,可选。用于设置 y 轴标签的大小。 |
| yrot | 浮点数,可选。用于设置 y 轴标签的旋转角度。 |
| ax | Matplotlib axes 对象或数组,可选。如果提供,则在指定的 axes 对象上绘 制直方图。 |
| sharex | 布尔值,默认为 False。如果为 True,并且绘制多个直方图,则所有直 方图共享相同的 x 轴。 |
| sharey | 布尔值,默认为 False。如果为 True,并且绘制多个直方图,则所有直 方图共享相同的 y 轴。 |
| figsize | 元组(宽度,高度),可选。用于设置整个图形的大小。 |
| layout | 元组(行数,列数),可选。用于指定直方图的布局。 |
| bins | 整数或序列,默认为 10。用于设置直方图的柱子数量或边界。 |
| backend | 字符串,可选。用于指定绘图的后端。默认情况下,Pandas 使用 Matplotlib。 |
| legend | 布尔值,默认为 False。如果为 True,并且指定了 by 参数,则在直方图上显示图例。 |
| **kwargs | 关键字参数,这些参数会被传递给 Matplotlib 的 hist 函数,用于进 一步自定义直方图。 |
3.7.3、 其他绘图
3.7.3.1、折线图与区域图
作用
- 显示趋势和变化:折线图适用于显示数据随时间、序列或其他连续变量的变化趋势。通过连接数据点形成线条,可以直观地观察数据的变化趋势,包括增长、下降、周期性等。
- 比较多个数据集:折线图可以同时显示多个数据集的趋势,以便进行比较和对比。通过将多个折线绘制在同一图表上,可以直观地比较不同数据集之间的差异和相似性。
- 发现异常值和波动:折线图可以帮助识别数据中的异常值和波动。通过观察折线图上的离群点、突变或震荡,可以发现数据中的异常情况,从而引发进一步的数据调查和分析。
- 预测和趋势分析:折线图可以用于预测和趋势分析。基于过去的数据,可以使用折线图来推断未来的趋势和模式,以支持决策制定和预测目标。
- 表达关联关系:折线图还可以显示不同数据集之间的关联关系。通过将相关的数据集绘制在同一图表上,并在折线之间进行比较,可以揭示变量之间的相关性和相互影响。
单条折线图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'年份': [2030, 2031, 2032, 2033, 2034], '销售额': [100, 150, 200, 180, 250]} df = pd.DataFrame(data) df.plot(x='年份', y='销售额', kind='line', title='年度销售额')
多条折线图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'年份': [2030, 2031, 2032, 2033, 2034], '销售额A': [100, 150, 200, 180, 250], '销售额B': [120, 160, 190, 210, 230]} df = pd.DataFrame(data) df.plot(x='年份', y=['销售额A', '销售额B'], kind='line', title='年度销售额')
区域图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'年份': [2030, 2031, 2032, 2033, 2034], '销售额': [100, 150, 200, 180, 250]} df = pd.DataFrame(data) df.plot(x='年份', y='销售额', kind='area', title='年度销售额')
堆叠区域图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'年份': [2030, 2031, 2032, 2033, 2034], '销售额A': [100, 150, 200, 180, 250], '销售额B': [120, 160, 190, 210, 230]} df = pd.DataFrame(data) df.plot(x='年份', y=['销售额A', '销售额B'], kind='area', stacked=True, title='年度销售额')

3.7.3.2、条形图与柱状图
作用
比较不同类别或组之间的大小或数量:柱状图是一种常用的工具,用于比较不同类别或组之间的大小、数量或频率。通过柱形的高度或长度,可以直观地看出各类别或组之间的差异,帮助我们进行比较和分析。
展示数据的分布情况:柱状图可以展示数据的分布情况,特别是离散型数据。每个柱形代表一个类别或组,其高度或长度表示该类别或组中的数据频率或数量,可以用于观察数据的分布模式。
强调特定数据点或子集:通过染色、添加标签或其他视觉效果,柱状图可以强调特定的数据点或数据子集,使其在整体数据中更加突出。
揭示趋势和模式:通过观察柱状图中不同类别或组的趋势和模式,可以发现数据中的某些趋势、关联或模式。例如,柱状图可以显示时间序列数据的趋势或季节性变化。
支持决策和传达见解:柱状图通常易于理解和解释,可以用于支持决策、传达见解和构建可视化故事。通过合理的布局、标签和注释,柱状图可以提供清晰的信息和观
垂直柱状图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'城市': ['北京', '上海', '广州', '深圳'], '人口': [2153, 2423, 1404, 1303]} df = pd.DataFrame(data) df.plot(x='城市', y='人口', kind='bar', title='城市人口')
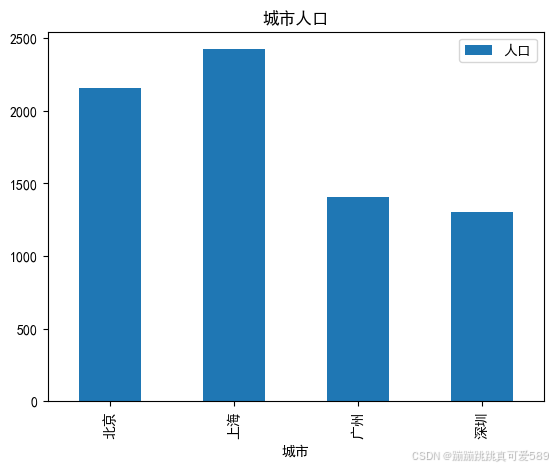
堆叠柱状图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'城市': ['北京', '上海', '广州', '深圳'], '男性人口': [1050, 1190, 693, 646], '女性人口': [1103, 1233, 711, 657]} df = pd.DataFrame(data) df.plot(x='城市', kind='bar', stacked=True, title='城市人口性别分布')

分组柱状图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'城市': ['北京', '上海', '广州', '深圳'], '男性人口': [1050, 1190, 693, 646], '女性人口': [1103, 1233, 711, 657]} df = pd.DataFrame(data) df.plot(x='城市', kind='bar', position=0.5, title='城市人口性别分布')
水平柱状图
from matplotlib import pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False data = {'城市': ['北京', '上海', '广州', '深圳'], '人口': [2153, 2423, 1404, 1303]} df = pd.DataFrame(data) df.plot(x='城市', y='人口', kind='barh', title='城市人口')
3.7.3.3、直方图
作用
数据分布的可视化:直方图可用于显示数据的分布情况。通过将数据划分为若干个等宽的区间(称为箱体),直方图展示了每个区间内的数据数量或频率,从而可以观察数据的分布模式,包括集中趋势、离散程度、偏斜度等。
数据间的比较:直方图可用于比较不同类别或组之间的数据。通过在同一图表中绘制多个直方图,可以直观地对比不同类别或组之间的数据分布情况,帮助观察差异、相似性和趋势。
发现异常值和异常模式:直方图可以帮助识别数据中的异常值和异常模式。通过观察直方图中的离群箱体或异常模式,可以发现数据中的异常情况,进而引发进一步的数据调查和分析。
数据预处理和特征工程:直方图在数据预处理和特征工程中起到重要的作用。通过观察数据的直方图,可以判断数据的分布是否符合要求,是否需要进行数据变换(如对数变换、归一化等)以满足建模的假设条件。
应用场景
数据分布的可视化和理解
比较不同类别或组之间的数据差异
发现数据中的异常值或异常模式
数据预处理和特征工程的探索性分析
垂直柱状图
import pandas as pd data = {'A': [1, 2, 2, 3, 3], 'B': [2, 3, 3, 4, 4]} df = pd.DataFrame(data) df.plot(kind='hist', stacked=True, title='堆叠直方图')
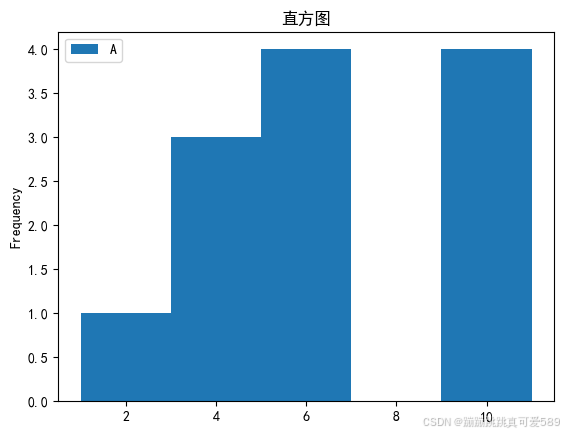
堆叠直方图
import pandas as pd data = {'A': [1, 2, 2, 3, 3], 'B': [2, 3, 3, 4, 4]} df = pd.DataFrame(data) df.plot(kind='hist', stacked=True, title='堆叠直方图')
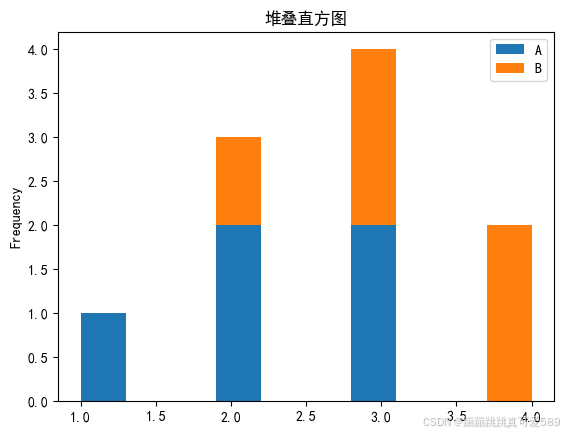
分组直方图
import pandas as pd data = {'Category': ['A', 'A', 'B', 'B', 'B'], 'Value': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) df.plot(kind='hist', by='Category', title='分组直方图')
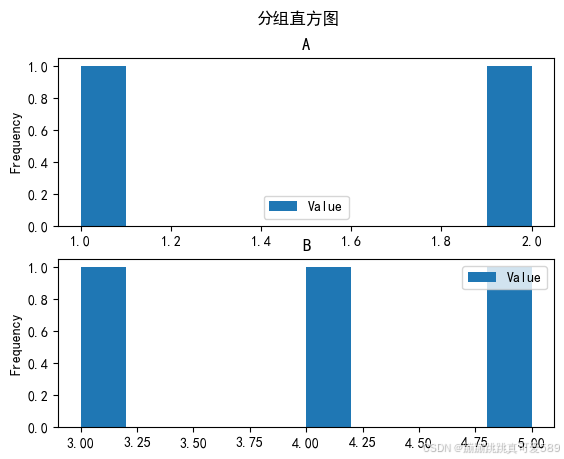
3.7.3.4、饼图
作用
显示各类别占比:饼图可以用于显示不同类别在整体中的占比情况,通过扇区的面积或角度大小来表示不同类别的比例关系。
比较不同类别的大小:饼图可以用于比较不同类别的数据大小,通过比较扇区的大小来观察各类别之间的相对大小关系。
强调特定类别:通过突出显示特定扇区,饼图可以帮助强调或突出显示某个类别在整体中的重要性或特殊性。
数据分布的可视化:饼图可以展示数据的分布情况,特别适用于展示离散的分类数据
注意
饼图在某些情况下可能存在局限性,特别是在扇区过多或数据差异较小时,可能导致饼图难以解读。因此,在使用饼图时应谨慎选择数据和适当的展示方式,确保准确传达数据的含义
饼图常用的参数如下:
kind:指定绘图类型,设置为'pie'表示绘制饼图。
title:设置图形的标题。
labels:指定饼图每个扇区的标签。
autopct:设置扇区上的百分比格式,可以显示每个扇区的百分比值。
'%.1f%%':显示一位小数的百分比值,例如 25.0%。
'%.2f%%':显示两位小数的百分比值,例如 25.00%。
'%.0f%%':显示整数的百分比值,例如 25%。
'%d':不显示百分比值,仅显示整数值。
None:不显示任何值。
colors:设置饼图扇区的颜色。
explode:设置是否将某些扇区分离出来,突出显示。
shadow:设置是否显示阴影效果。
startangle:设置饼图的起始角度,以度数表示。
饼图
import pandas as pd data = {'类别': ['A', 'B', 'C', 'D'], '数值': [30, 20, 15, 35]} df = pd.DataFrame(data) df.plot(kind='pie', y='数值', labels=df['类别'], autopct='%.1f%%', title='饼图')
突出特定类别的饼图
import pandas as pd data = {'类别': ['A', 'B', 'C', 'D'], '数值': [30, 20, 15, 35]} df = pd.DataFrame(data) explode = [0.1, 0, 0, 0] # 突出显示第一个类别 df.plot(kind='pie', y='数值', labels=df['类别'], autopct='%.1f%%', explode=explode, title='突出特定类别的饼图')
不同颜色的饼图
import pandas as pd data = {'类别': ['A', 'B', 'C', 'D'], '数值': [30, 20, 15, 35]} df = pd.DataFrame(data) explode = [0.1, 0, 0, 0] # 突出显示第一个类别 df.plot(kind='pie', y='数值', labels=df['类别'], autopct='%.1f%%', explode=explode, title='突出特定类别的饼图')
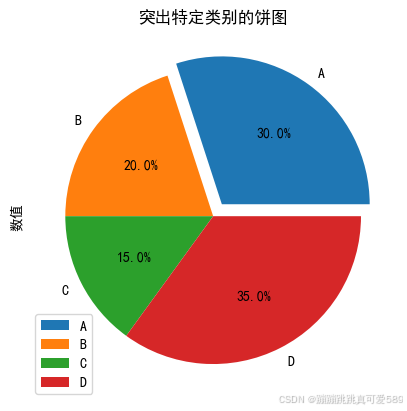
3.7.3.5、箱图
作用
数据分布的可视化:箱图可以用于显示数据的分布情况,包括数据的集中趋势、离散程度和离群值情况。
离群值的检测:箱图可以帮助检测数据中的离群值,通过显示离群值的位置,帮助识别异常数据。
组间比较:可以通过绘制多个箱图,将不同组的数据进行比较,观察各组之间的差异和离群值情况。
注意
箱图适用于数值型数据,特别是在比较不同组之间的数据分布和离群值情况时非常有用。
然而,当数据集较大或数据分布高度倾斜时,可能需要结合其他图表或数据分析方法来更全面地理解数据。
在选择是否使用箱图时,应根据具体的数据和分析目标进行评估。
箱图常用的参数如下:
kind:指定绘图类型,设置为'box'表示绘制箱图。
title:设置图形的标题。
vert:设置箱图的方向,设置为True表示垂直箱图,设置为False表示水平箱图。
whis:设置箱线图须与内限的位置,默认为 1.5。
showfliers:设置是否显示离群值,默认为True。
patch_artist:设置是否使用补丁对象填充箱体,默认为False。
meanline:设置是否显示均值线,默认为False。
meanprops:设置均值线的属性,如颜色、线型等。
widths:设置箱图的宽度,可以是数值或数组。
单个数据集的箱图
import pandas as pd data = {'数值': [10, 20, 30, 40, 50]} df = pd.DataFrame(data) df.plot(kind='box', title='Box Plot')
不同组之间的箱图比较
import pandas as pd data = {'组别': ['A', 'A', 'B', 'B', 'C', 'C'], '数值': [10, 15, 20, 25, 30, 35]} df = pd.DataFrame(data) df.boxplot(column='数值', by='组别')
水平箱图
import pandas as pd data = {'数值': [10, 20, 30, 40, 50]} df = pd.DataFrame(data) df.plot(kind='box', title='Horizontal Box Plot', vert=False)
显示离群值的箱图
import pandas as pd data = {'数值': [10, 20, 30, 40, 500]} df = pd.DataFrame(data) df.plot(kind='box', title='Box Plot with Outliers')

3.7.3.6、散点图
作用
变量关系的探索:散点图可以用于观察两个变量之间的关系,包括线性关系、非线性关系、正相关、负相关等。
数据分布的可视化:散点图可以显示数据点在二维平面上的分布情况,有助于理解数据的分布密度、离散程度和异常点。
趋势和模式的发现:通过绘制散点图,可以观察数据点的分布趋势、聚集模式和离群点,帮助发现数据中的规律和特征。
相关性分析:散点图可以用于评估两个变量之间的相关性,通过观察散点的分布,可以初步判断两个变量之间的相关关系
散点图常用的参数如下:
kind:指定绘图类型,设置为'scatter'表示绘制散点图。
x:指定散点图的横轴数据列。
y:指定散点图的纵轴数据列。
title:设置图形的标题。
s:设置数据点的大小。
c:设置数据点的颜色。
单个颜色值:可以使用常见的颜色名称(如
'red'、'blue')或颜色的十六进制表示(如'#FF0000'、'#0000FF')来指定所有数据点的颜色。序列类型数据:可以传递一个与数据点数量相同的序列类型数据,用于为每个数据点指定单独的颜色。这可以是数字序列、字符串序列或颜色名称序列
marker:设置数据点的标记形状。
'.':点标记。
'o':圆圈标记。
'x':叉标记。
'+':加号标记。
'*':星号标记。
'^':三角形标记。
's':正方形标记
单个数据集的散点图
import pandas as pd data = {'x': [1, 2, 3, 4, 5], 'y': [10, 20, 30, 40, 50]} df = pd.DataFrame(data) df.plot(kind='scatter', x='x', y='y', title='Scatter Plot')
根据数值设定散点大小和颜色
import pandas as pd data = {'x': [1, 2, 3, 4, 5], 'y': [10, 20, 30, 40, 50], 'size': [100, 200, 300, 400, 500], 'color': ['red', 'blue', 'green', 'yellow', 'orange']} df = pd.DataFrame(data) df.plot(kind='scatter', x='x', y='y', s=df['size'], c=df['color'], title='Scatter Plot with Size and Color')
3.8、其他常用方法
3.8.1 nunique
用于计算DataFrame中唯一值的数量。
DataFrame.nunique(axis=0, dropna=True)| 描述 | 说明 |
|---|---|
| axis=0 | 默认值,表示按列进行操作。如果设置为 axis=1,则表示按行进行操作 |
| dropna=True | 默认值,表示在计算唯一值之前先排除掉缺失值(NaN)。如果 设置为 False,则缺失值也会被计算在内。 |
import pandas as pd
import numpy as np
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 2, 3, 3, 3],
'B': ['a', 'b', 'b', 'c', 'c', 'c'],
'C': [np.nan, np.nan, 1, 2, 2, 2]
})
print(df)
# 使用nunique()方法计算每列的唯一值数量
unique_counts = df.nunique(axis=1, dropna=False)
print(unique_counts) A B C
0 1 a NaN
1 2 b NaN
2 2 b 1.0
3 3 c 2.0
4 3 c 2.0
5 3 c 2.0
0 3
1 3
2 3
3 3
4 3
5 3
dtype: int643.8.2 value_counts
用于计算DataFrame中各个值出现的频率的一个方法。
DataFrame.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)| 描述 | 说明 |
|---|---|
| subset=None | 可选参数,用于指定要进行计算操作的列名列表。如果未指定, 则对整个DataFrame的所有列进行操作。 |
| normalize=False | 布尔值,默认为False。如果设置为True,则返回每个值的 相对频率,而不是计数。 |
| sort=True | 布尔值,默认为True。如果设置为True,则结果将按计数值降序排 序。 |
| ascending=False | 布尔值,默认为False。当 sort=True时,此参数指定排序顺序。如果设置为True,则结果将按计数值升序排序。 |
| dropna=True | 布尔值,默认为True。如果设置为True,则在计数之前排除缺失 值。 |
import pandas as pd
import numpy as np
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 2, 3, 3, 3],
'B': ['a', 'b', 'b', 'c', 'c', 'c'],
'C': [np.nan, np.nan, 1, 2, 2, 2]
})
print(df)
# 使用value_counts()方法计算值的频率
value_counts = df.value_counts(subset=['C'], normalize=True, sort=True, ascending=True, dropna=False)
print(value_counts) A B C
0 1 a NaN
1 2 b NaN
2 2 b 1.0
3 3 c 2.0
4 3 c 2.0
5 3 c 2.0
C
1.0 0.166667
NaN 0.333333
2.0 0.500000
Name: proportion, dtype: float643.8.3 describe
用于生成DataFrame中数值列的统计摘要,会返回一个DataFrame,其中包含以下 统计信息:
count:非NA值的数量
mean:平均值
std:标准差
min:最小值
分位数:可指定
max:最大值
DataFrame.describe(percentiles=None, include=None, exclude=None)| 描述 | 说明 |
|---|---|
| percentiles=None | 一个列表形式的数值,用于指定要计算的分位数。默认情 况下,会计算25%,50%,和75%这三个分位数。如果你想要不同的分位数,可 以在这里指定。 |
| include=None | 一个列表形式的字符串或字符串序列,用于指定要包含在描述 统计中的数据类型。默认情况下,只包括数值类型的数据。 |
| exclude=None | 一个列表形式的字符串或字符串序列,用于指定要从描述统计 中排除的数据类型。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 2, 3, 3, 3],
'B': [10, 20, 20.0, 30, 30, 30],
'C': ['foo', 'bar', 'bar', 'baz', 'baz', 'baz']
})
print(df)
# 使用describe()方法生成统计摘要
description = df.describe(percentiles=[0.5, 0.75, 0.9], include=['number'])
print(description) A B C
0 1 10.0 foo
1 2 20.0 bar
2 2 20.0 bar
3 3 30.0 baz
4 3 30.0 baz
5 3 30.0 baz
A B
count 6.000000 6.000000
mean 2.333333 23.333333
std 0.816497 8.164966
min 1.000000 10.000000
50% 2.500000 25.000000
75% 3.000000 30.000000
90% 3.000000 30.000000
max 3.000000 30.0000003.8.4 copy
用于创建DataFrame的一个副本。
DataFrame.copy(deep=True)| 描述 | 说明 |
|---|---|
| deep=True | 默认为True,表示创建一个深拷贝。在深拷贝中,DataFrame中的 所有数据都会被复制到新的DataFrame中,因此原始DataFrame中的数据与副本 DataFrame中的数据是完全独立的。如果你对副本进行修改,原始DataFrame不 会受到影响,反之亦然。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 创建深拷贝
df_deep_copy = df.copy()
# 创建浅拷贝
df_shallow_copy = df.copy(deep=False)
# 修改深拷贝中的数据
df_deep_copy['A'][0] = 999
# 修改浅拷贝中的数据
df_shallow_copy['B'][0] = 888
# 打印原始DataFrame和副本
print("Original DataFrame:")
print(df)
print("\nDeep Copy:")
print(df_deep_copy)
print("\nShallow Copy:")
print(df_shallow_copy)Original DataFrame:
A B
0 1 888
1 2 5
2 3 6
Deep Copy:
A B
0 999 4
1 2 5
2 3 6
Shallow Copy:
A B
0 1 888
1 2 5
2 3 63.8.5 reset index
用于重置DataFrame的索引。
DataFrame.reset_index(level=None, *, drop=False, inplace=False, col_level=0, col_fill='', allow_duplicates=_NoDefault.no_default, names=None)| 描述 | 说明 |
|---|---|
| level=None | 整数或索引名称,用于指定要重置的索引级别。对于多级索引的 DataFrame,可以指定一个级别或级别列表。如果为None,则重置所有级别。 |
| drop=False | 布尔值,默认为False。如果为True,则重置索引后,原始索引将 不会作为列添加到DataFrame中。如果为False,则原始索引将作为新列添加到 DataFrame中。 |
| inplace=False | 布尔值,默认为False。如果为True,则直接在原始 DataFrame上进行操作,不返回新的DataFrame。 |
| col_level=0 | 如果原始索引是多级索引,则指定新列的索引级别。 |
| col_fill='' | 如果原始索引是多级索引,并且 多,则使用此值填充缺失的级别。 |
| allow_duplicates=_NoDefault.no_default | 允许索引列中出现重复值。如 果设置为False,则在尝试插入重复列时会引发ValueError。 |
| names=None | 列表或元组,用于为新列指定名称。默认情况下,如果drop为Flase,则使用原始索引的名称。 |
import pandas as pd
# 创建两个列表,它们将用作多级索引的级别
arrays = [['Falcon', 'Falcon', 'Parrot', 'Parrot'], # 第一级索引的值
['Captive', 'Wild', 'Captive', 'Wild']] # 第二级索引的值
# 使用arrays列表创建一个DataFrame,'Max Speed'列包含对应于多级索引的数据
df = pd.DataFrame({'Max Speed': [390., 350., 30., 20.]}, # 数据
index=arrays) # 使用arrays列表作为多级索引
print(df)
# 重置所有索引级别,并将它们作为列添加到DataFrame中
df_reset = df.reset_index()
print(df_reset)
# 只重置第二级索引,并将它作为列添加到DataFrame中
df_reset_level_1 = df.reset_index(level=1)
print(df_reset_level_1)
# 重置所有索引级别,但不将它们作为列添加到DataFrame中
df_reset_drop = df.reset_index(drop=True)
print(df_reset_drop) Max Speed
Falcon Captive 390.0
Wild 350.0
Parrot Captive 30.0
Wild 20.0
level_0 level_1 Max Speed
0 Falcon Captive 390.0
1 Falcon Wild 350.0
2 Parrot Captive 30.0
3 Parrot Wild 20.0
level_1 Max Speed
Falcon Captive 390.0
Falcon Wild 350.0
Parrot Captive 30.0
Parrot Wild 20.0
Max Speed
0 390.0
1 350.0
2 30.0
3 20.03.8.6 info
用于显示DataFrame的概要信息的一个便捷方法,它提供了关于DataFrame的列、 非空值数量、数据类型以及内存使用情况的信息。
DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None)| 描述 | 说明 |
|---|---|
| verbose=None | 控制输出信息的详细程度。 |
| buf=None | 一个打开的文件对象或类似文件的对象。如果提供,则输出将被写 入这个缓冲区而不是标准输出。 |
| max_cols=None | 要显示的最大列数。如果DataFrame的列数超过这个值,则只 会显示部分列的信息。 |
| memory_usage=None | 控制是否显示内存使用情况。可以设置为True或False, 或者是一个字符串,'deep’表示深度计算内存使用情况,考虑对象内部数据。 |
| show_counts=None | 控制是否显示非空值的数量。如果设置为True,则会在每 个列旁边显示非空值的数量。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 3, None],
'B': ['a', 'b', 'c', 'd'],
'C': [1.1, 2.2, 3.3, 4.4]
})
print(df)
# 显示DataFrame的概要信息
df.info(verbose=False, memory_usage=True, show_counts=True) A B C
0 1.0 a 1.1
1 2.0 b 2.2
2 3.0 c 3.3
3 NaN d 4.4
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Columns: 3 entries, A to C
dtypes: float64(2), object(1)
memory usage: 228.0+ bytes3.8.7 apply
允许你对DataFrame中的每个元素、行或列应用一个函数。
DataFrame.apply(func, axis=0, raw=False, result_type=None, args= (), **kwargs)| 描述 | 说明 |
|---|---|
| func | 函数,应用于每个元素、行或列。这个函数需要你自定义,或者使用内置 的函数。 |
| axis=0 | 指定应用函数的轴。 |
| raw=False | 布尔值,默认为False,则每行或每列将作为Series使用,如果为 True,则将作为Ndarray数组,性能会更好。 |
| result_type=None | 控制返回类型。可以是以下之一: ‘reduce’:如果应用函数返回一个列表,这个列表会被转换成 一个 Series。 ‘broadcast’:结果会被广播到原始 DataFrame 的形状,保留原始的索引和 列。 ‘expand’:如果应用函数返回一个列表(或类似列表的结构),则这个列表会 被转换为多个列。这意味着每个列表元素都会变成 DataFrame 的一列。 |
| args=() | 元组,包含传递给函数的位置参数。 |
| **kwargs | 关键字参数,将被传递给函数。 |
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
print(df)
# 定义一个函数,计算每行的平均值
def mean_row(row):
return row.mean()
# 应用函数到每行
result = df.apply(mean_row, axis=0, result_type='expand')
print(result) A B C
0 1 4 7
1 2 5 8
2 3 6 9
A 2.0
B 5.0
C 8.0
dtype: float64四、Pandas的读取与保存
4.1、读取数据
4.1.1、Pandas读取Excel文件
说明
使用Pandas模块操作Excel时候,需要安装openpyxl
pip install openpyxl==3.1.2
pandas.read_excel是pandas库中用于读取Excel文件( .xls 或 数。它可以将Excel文件中的数据读取为DataFrame对象,便于进行数据分析和处 理。
pandas.read_excel(io, sheet_name=0, header=0, index_col=None, usecols=None, squeeze=False,dtype=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, parse_dates=False, date_parser=None,skipfooter=0, convert_float=True, **kwds)| 描述 | 说明 |
|---|---|
| io | 文件路径或文件对象。这是唯一必需的参数,用于指定要读取的Excel文件。 |
| sheet_name=0 | 要读取的表名或表的索引号。默认为0,表示读取第一个工作 表。可以指定工作表名或索引号,如果指定多个,将返回一个字典,键为工作表 名,值为对应的DataFrame。 |
| header=0 | 用作列名的行号,默认为0,即第一行作为列名。如果没有标题行, 可以设置为None。 |
| index_col=None | 用作行索引的列号或列名。默认为None,表示不使用任何列 作为索引。可以是一个整数、字符串或列名的列表。 |
| usecols=None | 要读取的列。默认为None,表示读取所有列。可以是一个整数 列表、字符串列表或Excel列的位置(如 [0, 1, 2])或字母标记(如 ['A', 'B', 'C'])。 |
| squeeze=False | 如果读取的数据只有一列,当设置为True时,返回一个Series 而不是DataFrame。 |
| dtype=None | 指定某列的数据类型。默认为None,表示自动推断。可以是一个 字典,键为列名,值为NumPy数据类型。 |
| skiprows=None | 要跳过的行号或行号列表。默认为None,表示不跳过任何行。 可以是整数或整数列表。 |
| nrows=None | 读取的行数,从文件头开始。默认为None,表示读取所有行。 |
| na_values=None | 将指定的值替换为NaN。默认为None,表示不替换。可以是 一个值或值的列表。 |
| keep_default_na=True | 如果为True(默认),则除了通过 na_values指定的值外,还将默认的NaN值视为NaN。 |
| parse_dates=False | 是否尝试将列解析为日期。默认为False。可以是一个布尔 值、列名列表或列号的列表。 |
| date_parser=None | 用于解析日期的函数。默认为None,表示使用pandas默认 的日期解析器。 |
| skipfooter=0 | 要跳过的文件底部的行数。默认为0,表示不跳过任何底部的 行。 |
| convert_float=True | 是否将所有浮点数转换为64位浮点数。默认为True,以 避免数据类型推断问题。 |
| **kwds | 允许用户传递其他关键字参数,这些参数可能会被引擎特定的读取器所 识别。 |
import pandas as pd
pd.read_excel('stu_data.xlsx')
指定导入哪个Sheet
pd.read_excel('stu_data.xlsx',sheet_name='Target') pd.read_excel('stu_data.xlsx',sheet_name=0)
通过index_col指定行索引
pd.read_excel('stu_data.xlsx',sheet_name=0,index_col=0)
通过header指定列索引
pd.read_excel('stu_data.xlsx',sheet_name=0,header=1) pd.read_excel('stu_data.xlsx',sheet_name=0,header=None)
通过usecols指定导入列
pd.read_excel('stu_data.xlsx',usecols=[1,2,3])
4.1.2、Pandas读取数据_CSV文件
pandas.read_csv 是一个非常强大的函数,用于从文件、URL、文件-like对象等读 取逗号分隔值(CSV)文件。这个函数有很多参数,允许你以多种方式自定义数据加 载过程。
pandas.read_csv(filepath_or_buffer, sep, header, usercols, na_values, parse_dates, skiprows, nrows)| 描述 | 说明 |
|---|---|
| filepath_or_buffer | 指定要读取的 CSV 文件的路径或文件对象。可以是一个 字符串,表示文件的绝对路径或相对路径;也可以是一个已经打开的文件对象 (例如通过 open() 函数打开的文件)。 |
| sep | 字符串,用于分隔字段的字符。默认是逗号,,但可以是任何字符,例如 ';' 或 '\t'(制表符)。 |
| header | 整数或整数列表,用于指定行号作为列名,或者没有列名, |
| usecols | 列表或 callable,用于指定要读取的列。可以是列名的列表,也可以是 列号的列表。 |
| na_values | 字符串、列表或字典,用于指定哪些其他值应该被视为NA/NaN |
| parse_dates | 列表或字典,用于指定将哪些列解析为日期。 |
| skiprows | 整数或列表,用于指定要跳过的行号或条件。 |
| nrows | 整数,用于指定要读取的行数。 |
导入csv文件时除了指明文件路径,还需要设置编码格式。
在国内,Python中用得比较多的两种编码格式是UTF-8和gbk,默认编码格式是UTF-8。
通过设置参数encoding来设置导入的编码格式。
pd.read_csv('stu_data.csv',encoding='gbk')4.1.4、Pandas读取txt文件
导入.txt文件用得方法时read_table(),read_table()是将利用分隔符分开的文件导入。DataFrame的通用函数。它不仅仅可以导入.txt文件,还可以导入.csv文件。
导入.txt文件
pd.read_table('test_data.txt',encoding='utf-8',sep='\t')
导入.csv文件,指明分隔符
pd.read_table('stu_data.csv',encoding='gbk',sep=',')
4.1.5、读取数据库数据
配置 MySQL 连接引擎
conn = pymysql.connect( host = 'localhost', user = 'root', passwd = 'root', db = 'mydb', port=3306, charset = 'utf8' )读取数据表
pd.read_sql( sql :需要执行的 SQL 语句/要读入的表名称 con : 连接引擎名称 index_col = None :将被用作索引的列名称 columns = None :当提供表名称时,需要读入的列名称 list ) tab1 = pd.read_sql('SELECT * FROM t_menus',con=conn) tab1 = pd.read_sql('SELECT count(1) FROM t_menus',con=conn) number = 10 tab1 = pd.read_sql( f'SELECT * FROM t_menus LIMIT {number}', con=conn, index_col = ['empno'], )数据sql
CREATE TABLE `t_menus` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(32) NOT NULL, `path` varchar(32) DEFAULT NULL, `level` int(11) DEFAULT NULL, `pid` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `name` (`name`), KEY `pid` (`pid`), CONSTRAINT `t_menus_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `t_menus` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=52 DEFAULT CHARSET=utf8mb4; INSERT INTO `t_menus` VALUES (-1,'全部',NULL,0,NULL),(1,'用户管理',NULL,1,-1),(2,'权限管理',NULL,1,-1),(3,'商品管理',NULL,1,-1),(4,'订单管理',NULL,1,-1),(5,'数据统计',NULL,1,-1),(11,'用户列表','/user_list',2,1),(21,'角色列表','/author_list',2,2),(22,'权限列表','/role_list',2,2),(31,'商品列表','/product_list',2,3),(32,'分类列表','/group_list',2,3),(33,'属性列表','/attribute_list',2,3),(41,'订单列表','/order_list',2,4),(51,'统计列表','/data_list',2,5);
4.2、保存数据
df.to_csv(
filepath_or_buffer :要保存的文件路径
sep =:分隔符
columns :需要导出的变量列表
header = True :指定导出数据的新变量名,可直接提供 list
index = True :是否导出索引
mode = 'w' : Python 写模式,读写方式:r,r+ , w , w+ , a , a+
encoding = 'utf-8' :默认导出的文件编码格式
)
df2.to_csv('temp.csv')
#===========================
df.to_excel(
filepath_or_buffer :要读入的文件路径
sheet_name = 1|Sheet :要保存的表单名称
)
df2.to_excel('temp.xlsx', index = False, sheet_name = data)
4.2.1、to_csv
用于将DataFrame对象保存为CSV(逗号分隔值)文件的方法。
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, mode='w', encoding=None, quoting=None, quotechar='"', **kwargs)| 描述 | 说明 |
|---|---|
| path_or_buf | 指定输出文件的路径或文件对象。 |
| sep | 字段分隔符,通常使用逗号,或制表符\t。 |
| na_rep | 缺失值的表示方式,默认为空字符串 ''。 |
| float_format | 浮点数的格式化方式,例如 '%.2f'用于格式化为两位小数。 |
| columns | 要写入的列的子集,默认为None,表示写入所有列。 |
| header | 是否写入行索引,通常设置为True或False,取决于是否需要索引。 |
| index | 是否写入列名,通常设置为True。 |
| mode | 写入模式,通常使用’w’(写入,覆盖原文件)或’a’(追加到文件末尾)。 |
| encoding | 文件编码,特别是在处理非ASCII字符时很重要 |
| quoting | 控制字段引用的行为,通常用于确保字段中的分隔符被正确处理。 |
| quotechar | 用于包围字段的字符,默认为双引号"。 |
| **kwargs | 其他关键字参数。 |
import pandas as pd
# 创建一个简单的DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [28, 34, 29],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
# 将DataFrame保存为CSV文件
df.to_csv('人员信息.csv', index=False, encoding='utf_8_sig')4.2.2、to_excel
Pandas中的 to_excel用于将DataFrame保存为Excel文件。
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, inf_rep='inf', freeze_panes=None, storage_options=None)| 描述 | 说明 |
|---|---|
| excel_writer | 字符串或ExcelWriter对象,指定输出文件的路径或文件对象。 |
| sheet_name='Sheet1' | 要写入的工作表名称。 |
| na_rep='' | 指定缺失值的表示方式。 |
| float_format=None | 浮点数的格式化方式,例如’%.2f’。 |
| columns=None | 要写入的列的子集,默认为None,表示写入所有列。 |
| header=True | 是否写入列名,默认为True。 |
| index_label=None | 是否写入行索引,默认为True。 |
| index=True | 指定行索引列的列名,如果为None,并且 : header为True,则使用索引名。 |
| startrow= | 写入DataFrame的起始行位置,默认为0。 |
| startcol=0 | 写入DataFrame的起始列位置,默认为0。 |
| engine=None | 指定用于写入文件的引擎,可以是’openpyxl’(默认) 或’xlsxwriter’。 |
| merge_cells=True | 是否合并单元格,这在有合并单元格的Header时很有用。 |
| inf_rep='inf' | 指定无限大的表示方式。 |
| freeze_panes=None | 指定冻结窗口的单元格范围,例如’A2’。 |
| storage_options=None | 指定存储连接的参数,例如认证凭据。 |
import pandas as pd
# 创建一个简单的DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [28, 34, 29],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
# 将DataFrame保存为Excel文件
df.to_excel('人员信息.xlsx', index=False)4.2.3、保存数据到数据库
注意
需要安装sqlalchemy
pip install sqlalchemy
df.to_sql(
name :将要存储数据的表名称
con : 连接引擎名称
if_exists = 'fail' :指定表已经存在时的处理方式
fail :不做任何处理(不插入新数据)
replace :删除原表并重建新表
append :在原表后插入新数据
index = True :是否导出索引 )
from sqlalchemy import create_engine
con = create_engine('mysql+pymysql://root:root@localhost:3306/mydb?charset=utf8')
df.to_sql('t_stu',con,if_exists=append)