目录
一、模型微调基础
模型微调(Fine-tuning)指在预训练大模型(如GPT、BERT)基础上,通过特定领域或任务的数据进行额外训练,使模型适应新任务的过程。其核心目标是通过调整模型参数,提升模型在垂直领域的专业性、企业业务逻辑适配性、用户偏好匹配度及任务执行效率。
微调的主要场景包括:
-
领域专业化:如医疗、法律、金融等领域,需注入领域知识以提升任务精度;
-
资源优化:通过参数高效微调(PEFT)技术(如LoRA、Adapter)降低显存占用,适应低资源设备;
-
数据安全与隐私:本地微调敏感数据,避免云端暴露风险。
二、主流微调框架对比
以下从核心特性、适用场景及技术优势等维度,对比分析四大主流框架:
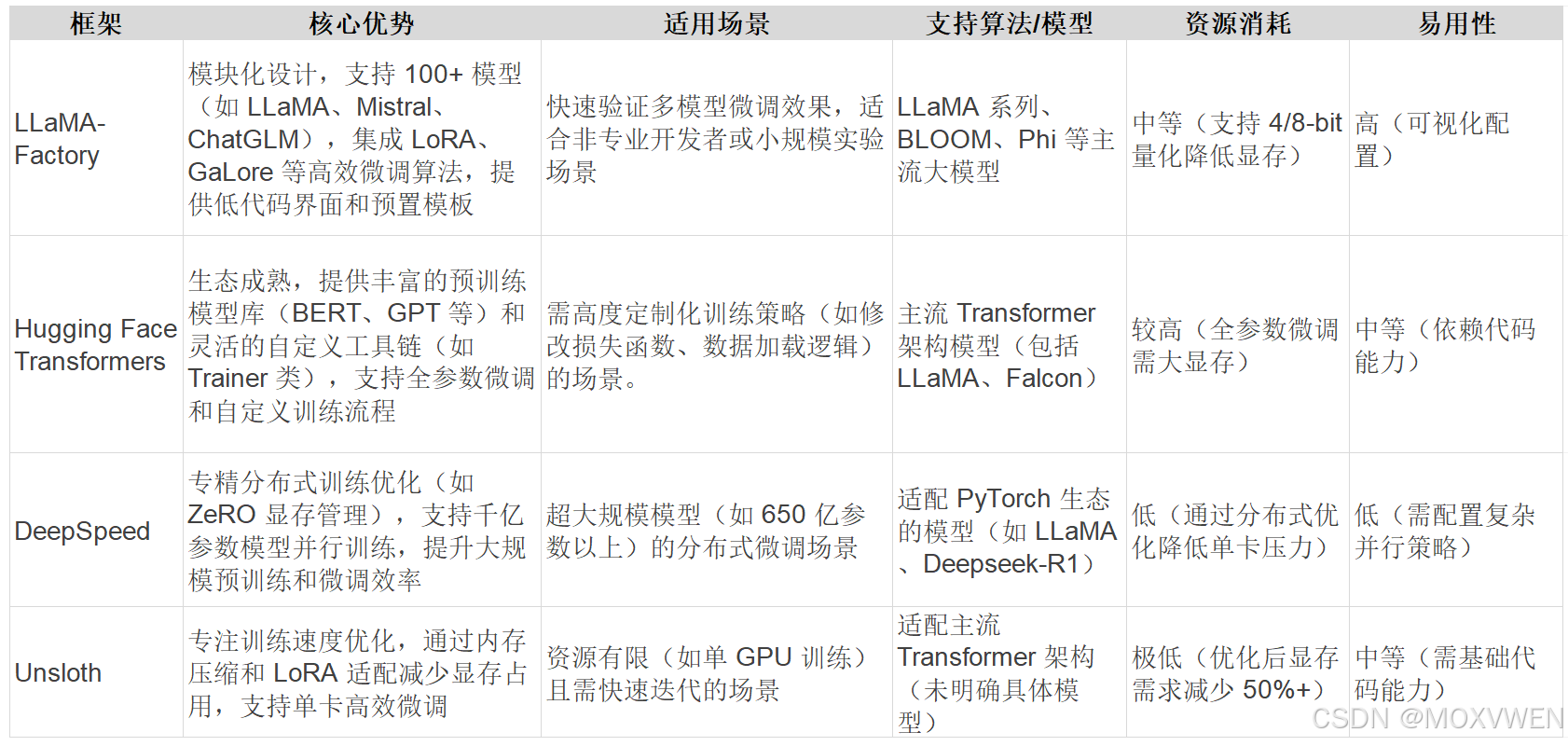
1. LLaMA-Factory
-
核心特性:
国产开源框架,支持LLaMA、BLOOM、Mistral等上百种模型,集成LoRA、QLoRA等参数高效微调方法,提供无代码Web UI界面(LlamaBoard)和CLI/API调用方式。其模块化设计简化了模型加载、补丁应用和量化适配流程,支持NVIDIA GPU、Ascend NPU等多硬件,并支持4/8位量化以降低推理内存占用。 -
优势:
-
低门槛:图形化界面适合非开发者快速上手;
-
高兼容性:适配多种模型架构及数据集格式(Alpaca、ShareGPT);
-
资源高效:量化技术优化显存使用,单卡可微调7B模型。
-
-
适用场景:
多硬件环境下的轻量化微调,尤其是需要快速原型设计或资源受限的场景。
2. Hugging Face Transformers
-
核心特性:
NLP领域标准化框架,提供超30万预训练模型(涵盖BERT、GPT、LLaMA等),支持文本、图像、音频多模态任务。其生态系统包含社区贡献的微调模型、教程及工具链(如Datasets、Accelerate)。 -
优势:
-
社区活跃:丰富的案例和文档支持快速问题解决;
-
灵活性:通过简单API实现模型加载、微调与部署;
-
全流程覆盖:覆盖从数据预处理到模型评测的全生命周期。
-
-
局限性:
超大规模模型全参数微调时存在性能瓶颈,需依赖DeepSpeed等扩展工具。 -
适用场景:
需要快速实验和社区支持的开发者,尤其是多任务原型设计。
3. DeepSpeed
-
核心特性:
微软开发的分布式训练引擎,核心技术为ZeRO(Zero Redundancy Optimizer),通过参数分片、CPU Offloading和混合精度训练,支持百亿级模型全参数微调。典型应用包括GPT-3等超大规模模型训练。 -
优势:
-
扩展性强:支持多节点训练与显存优化,适合企业级大规模训练;
-
高效并行:结合数据并行、模型并行与流水并行,提升吞吐量。
-
-
局限性:
配置复杂,需深入理解分布式系统与底层优化。 -
适用场景:
千亿参数级模型的预训练或全参数微调,需高性能计算集群支持。
4. Unsloth
-
核心特性:
专注于加速LLM微调的框架,通过算法优化实现2倍以上训练速度提升,并减少80%内存占用。支持Llama、Mistral、Gemma等主流模型。 -
优势:
-
极致效率:优化计算图与内存管理,适合快速迭代;
-
低资源需求:可在有限显存下训练更大模型。
-
-
适用场景:
资源受限环境下的快速微调,如单卡训练或实时响应需求场景。
三、框架选择建议
- LLaMA-Factory:推荐优先用于多模型实验和低代码需求场景,尤其在量化微调和模块化扩展中表现突出。
- Hugging Face Transformers:适合需灵活调整底层逻辑或复用成熟生态的场景(如学术研究)。
- DeepSpeed:专为超大规模模型设计,需配合多节点 GPU 集群使用。
- Unsloth:资源受限时的高效选择,单卡训练速度显著优于传统方案。
四、总结
模型微调框架的选择需综合任务规模、硬件条件及开发效率。
LLaMA-Factory和Hugging Face Transformers覆盖了大多数轻量级到中规模需求,而DeepSpeed和Unsloth分别专精于超大规模训练与极致效率优化。
开发者可根据具体场景灵活组合工具链,例如使用Hugging Face生态构建原型,再通过DeepSpeed扩展至生产环境。