2025-04-10 ,由浙江大学、上海人工智能实验室、斯坦福大学、香港中文大学和南洋理工大学联合创建了 DataDoP 数据集。该数据集包含 29K 真实世界的自由运动相机轨迹、深度图和详细的动作描述,目的为艺术化相机轨迹生成提供高质量的训练数据,推动基于学习的电影摄影技术发展。
一、研究背景
在视频制作中,相机轨迹设计是传达导演意图和增强视觉叙事的关键工具。传统方法依赖于几何优化或手工设计的程序系统,而近年来的基于学习的方法则继承了结构偏差或缺乏文本对齐,限制了创意合成。
目前遇到困难和挑战:
1、传统方法的局限性:传统方法依赖于几何建模或成本函数工程,限制了创意合成。
2、现有数据集的不足:现有数据集缺乏复杂的艺术化轨迹,且缺乏与场景互动和导演意图的详细描述。
3、学习方法的偏差:现有的基于学习的方法继承了人类中心跟踪数据集的结构偏差,限制了相机运动的多样性。
数据集地址:DataDoP|电影制作数据集|计算机视觉数据集
二、让我们一起看一下DataDoP数据集
DataDoP 数据集包含 29K 真实世界的自由运动相机轨迹、深度图和详细的动作描述。
这些数据从艺术电影中提取,涵盖了复杂的相机运动和场景互动。数据集分为四种类型:静态、对象/场景中心、跟踪和自由运动。每个样本都包含 RGBD 图像和两种类型的描述:运动描述和导演意图描述。
数据集特点:
大规模:包含 29K 样本,总计 11M 帧。
多模态:包含 RGBD 图像和详细的文字描述。
艺术化:专注于自由运动轨迹,捕捉导演的创意愿景。
高质量:通过用户研究验证,数据集具有高对齐度和质量。
基准测试:
通过对比现有方法,DataDoP 数据集在文本对齐、轨迹质量和复杂性方面表现出色。
文本对齐:DataDoP 数据集在文本对齐方面表现优异,其 CLaTr-CLIP 分数达到了 0.400,显著高于其他现有方法。
轨迹质量:在轨迹质量方面,DataDoP 的 CLaTr-FID 分数为 22.714,远低于其他方法,表明其生成的轨迹与真实轨迹的一致性更高。
复杂性:DataDoP 数据集在轨迹复杂性方面也表现出色,其复杂性指标达到了 4.713,这表明其能够生成更为复杂和多样化的轨迹。
基准测试结果表明,基于 DataDoP 训练的模型在生成艺术化轨迹方面具有显著优势。
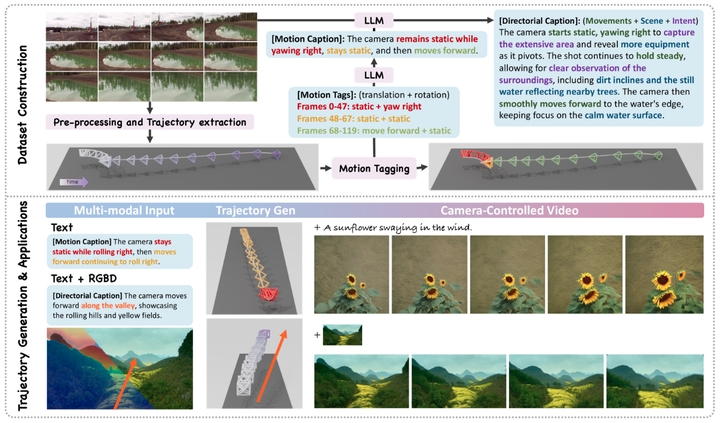
数据集构建
1、视频筛选:从互联网上筛选艺术视频,去除字幕,合并公开数据集。
2、轨迹提取:使用 MonST3R 提取相机轨迹和深度图。
3、运动标记:将轨迹分割为运动标签,包括平移和旋转。
4、描述生成:使用 GPT-4o 生成运动描述和导演意图描述。
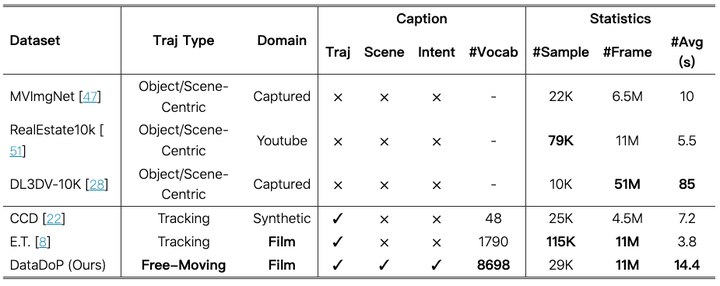
DataDoP 数据集。 与其他数据集进行了比较。DataDoP 是一个大型数据集,专注于艺术性、自由移动的轨迹,每个轨迹都附有高质量的字幕注释。提供的字幕详细介绍了摄像机移动、它们与场景内容的交互以及潜在的导演意图。为了捕捉更复杂的摄像机运动,每个视频剪辑时长为 10-20 秒,平均为 14.4 秒。
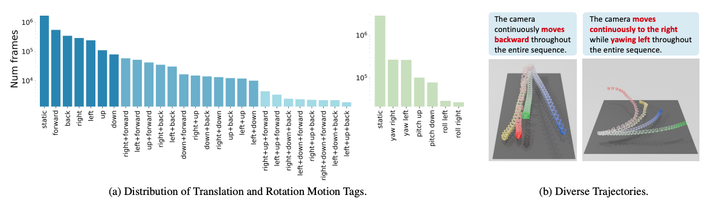
(a) 数据集统计和 (b) 多样的轨迹。a说明了 27 个平移运动(左)和 7 个旋转运动(右)的组成和分布,强调了 DataDoP 数据集中轨迹的复杂性和多样性. b基于相同的标题,我们的数据集包括仍然符合给定标题的不同轨迹。如图所示,轨迹在长度、方向和速度方面表现出变化,有效地展示了我们数据集中的多样

数据集用户研究。 我们的用户研究表明,我们的数据集表现出卓越的质量和人际一致性,结果的可靠性得到了证明。
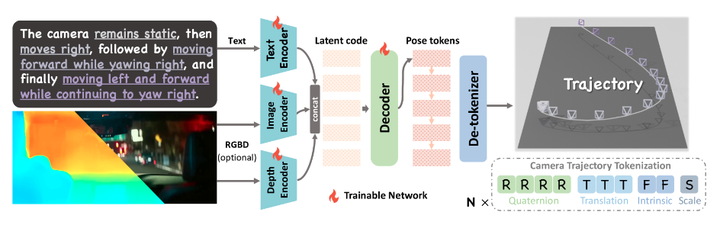
我们的自回归生成模型。 我们的模型支持多模态输入,并根据这些输入生成轨迹。通过将任务视为自回归的 next-token 预测问题,该模型按顺序生成轨迹,每个新姿势预测都受先前相机状态和输入条件的影响。
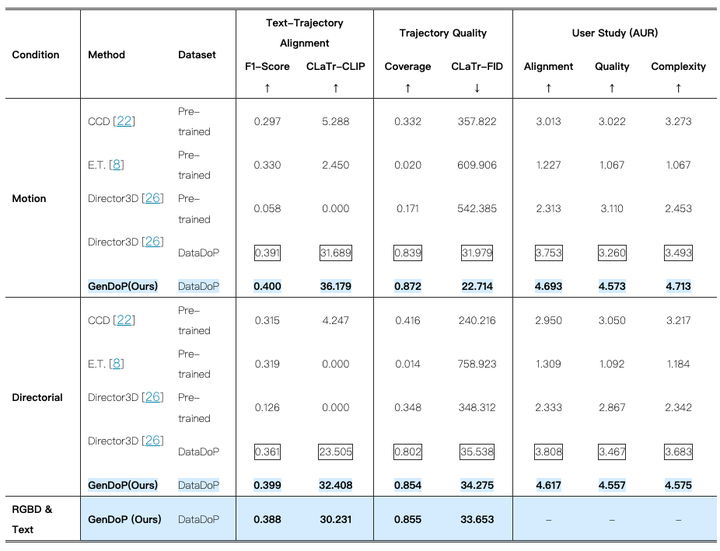
定量结果。我们展示了我们的 GenDoP 在两个文本条件生成任务和一个 RGBD 和文本条件任务中的定量结果,将其与人类跟踪方法 CCD [22]和 E.T. [8]以及以对象/场景为中心的方法 Director3D [26]进行比较。我们的模型在所有指标和标题子集中始终优于所有基线,证实了我们的数据集和自回归框架的有效性。
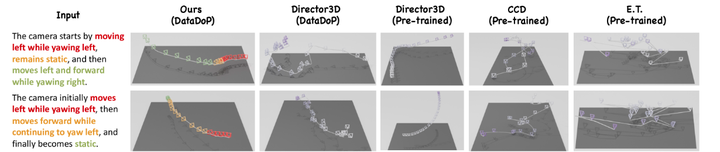
文本条件轨迹生成的定性结果。 我们在图中提供了文本条件轨迹生成的比较分析。我们模型的轨迹(颜色编码以突出显示文本对齐方式)保持稳定并紧密遵循说明,而其他模型则表现出明显的抖动或无法很好地与说明匹配。
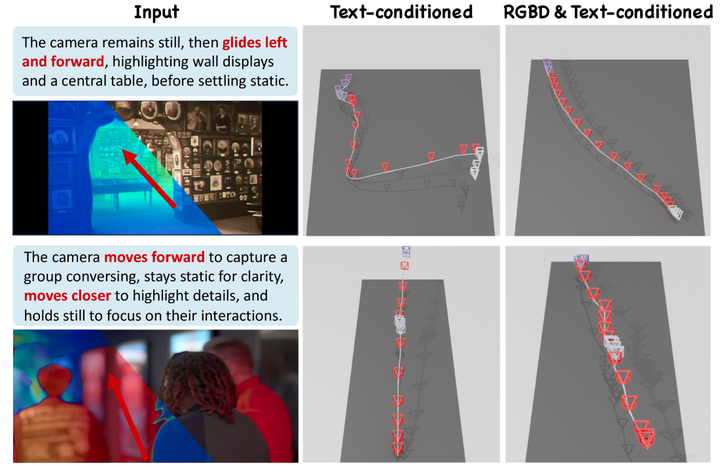
RGBD 和文本条件生成的定性结果。 此图比较了在相同文本条件下合并 RGBD 输入对轨迹生成的影响。虽然两种模型都能生成符合命令的轨迹,但 RGBD 和文本条件模型通过利用 RGBD 数据来集成几何和上下文约束,展示了卓越的场景适应性。
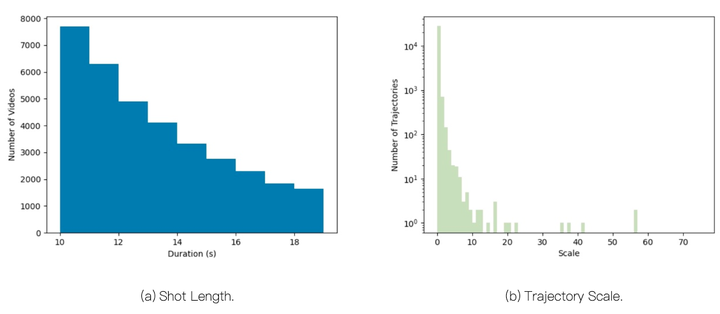
视频拍摄长度和轨迹比例的数据集统计数据。

语义过滤。 按照第 3.2 节中的定义,对射击进行分类。利用 GPT-4o ,我们自动将镜头分类为静态 、 自由移动和跟踪 。归类为以对象/场景为中心的镜头在多视图数据集中很常见,在电影中不考虑。
标签分布。Translation (平移) 和 Rotation (旋转) 组合的分布如图所示。不同的标记模式由黄色阴影表示,范围从深到浅:静态、仅平移、仅旋转以及平移和旋转。

字幕生成。我们通过结合上下文、指令、约束和示例来构建运动标签,然后利用 GPT-4o 生成单独描述相机运动的运动字幕。接下来,我们从镜头中提取 16 个均匀分布的帧,创建一个 4×444\times 44 × 4 网格,促使 GPT-4o 同时考虑前面的标题和图像序列。
三、展望DataDoP数据集应用场景
比如你是一个知名的导演
你现在要拍摄一个主角在高科技实验室中探索的场景,镜头需要跟随主角的移动,同时还要展现出实验室的各种高科技设备和复杂的结构。
以前的拍摄方式:
前期准备:你这个大导演需要和摄影师、美术指导等团队成员反复讨论镜头的运动轨迹。他们要在实际场景中多次走位,确定镜头的起始位置、移动方向、速度变化等细节。这个过程可能需要花费数小时甚至数天时间,而且一旦场景搭建完成,调整镜头轨迹的成本会很高。
拍摄过程:在实际拍摄时,摄影师要根据之前的规划,手动操作摄影设备,或者依靠一些简单的机械装置来实现镜头运动。但这种方式很难做到完美,可能会出现镜头抖动、轨迹不自然等问题,导致需要多次重拍。
后期调整:如果拍摄效果不理想,后期可能需要通过特效软件进行调整,但这会增加后期制作的难度和成本,而且效果可能还是不够理想。
现在有了 DataDoP 数据集的加持:
前期准备:你这个大导演只需要简单地描述一下镜头的大概需求,比如“镜头从主角的左后方开始,缓慢移动到主角的正前方,同时稍微向上仰角,展现出实验室的天花板和各种设备”。然后将这个描述输入到基于 DataDoP 数据集训练的模型中。
生成轨迹:模型会根据输入的描述,快速生成一个详细的、艺术化的相机轨迹。这个轨迹不仅考虑了镜头的运动,还结合了场景的布局和导演的意图,比如会自动避开场景中的障碍物,确保镜头能够平稳、自然地移动。
模拟拍摄:在实际拍摄之前,导演和团队可以通过虚拟现实设备或者电脑软件,预览这个生成的轨迹,看看镜头运动是否符合预期。如果需要调整,只需要修改一下描述,模型就会重新生成新的轨迹,非常方便。
实际拍摄:在拍摄时,摄影设备可以根据生成的轨迹进行自动拍摄,大大提高了拍摄效率和质量。而且由于轨迹是经过精心设计的,拍摄出来的画面更加流畅、自然,减少了后期调整的工作量。
有了 DataDoP 数据集的加持,你这个大导演呀在拍摄复杂镜头时更加轻松高效,能够更好地实现自己的创意,提升电影的视觉效果。给大家带来更多的作品。
更多免费的数据集,请打开:遇见数据集
遇见数据集-让每个数据集都被发现,让每一次遇见都有价值。遇见数据集,领先的千万级数据集搜索引擎,实时追踪全球数据集,助力把握数据要素市场。![]() https://www.selectdataset.com/
https://www.selectdataset.com/