一.算法简介
1.二分法
对于区间[a,b]上连续不断且f(a)·f(b)<0的函数y=f(x),通过不断地把函数f(x)的零点所在的区间一分为二,使区间的两个端点逐步逼近零点,进而得到零点近似值的方法叫二分法。
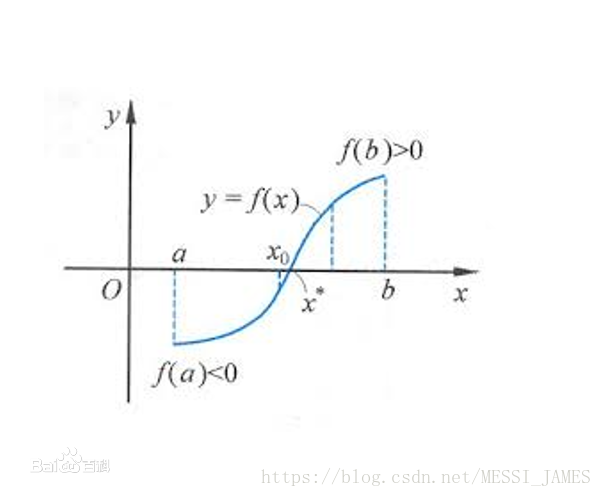
当数据量很大适宜采用该方法。采用二分法查找时,数据需是排好序的。时间复杂度:O(log(n))
例子:猜一个在1~100之间的数字。
你的目标是以最少的次数猜到这个数字。你每次猜测后,我会说小了、大了或对了。假设你从1开始依次往上猜,猜测过程会是这样。
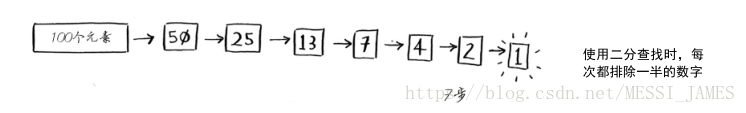
2.大 O 表示法
大O表示法是一种特殊的表示法,指出了算法的速度有多快。
我们 常用大O表示法表示时间复杂度,注意它是某一个算法的时间复杂度。
例子:
假设检查一个元素需要1毫秒。使用简单查找时,Bob必须检查100个元素,因此需要100毫秒才能查找完毕。而使用二分查找时,只需检查7个元素(log 2 100大约为7),因此需要7毫秒就能查找完毕。然而,实际要查找的列表可能包含10亿个元素,在这种情况下,简单查找需要多长时间呢?二分查找又需要多长时间呢?
简单查找:10亿毫秒
二分查找:log 2 10,0000,0000=7毫秒
3一些常见的大 O 运行时间
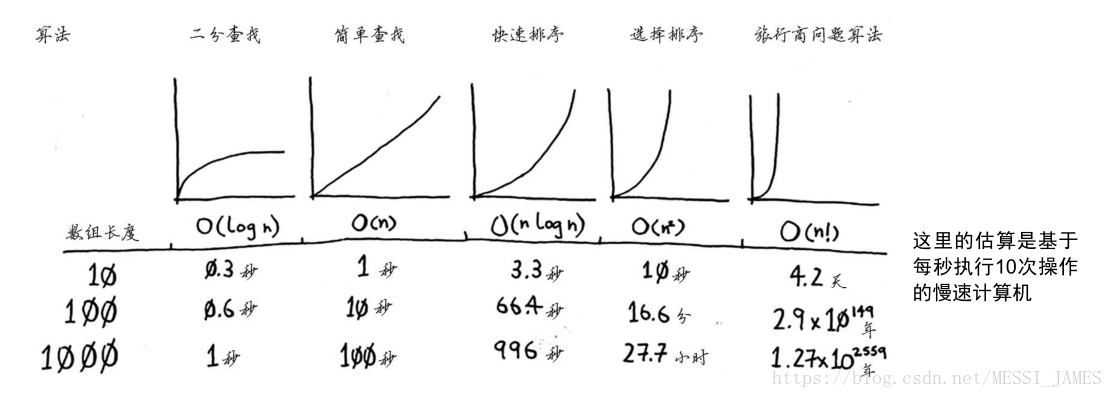
O(log n),也叫对数时间,这样的算法包括二分查找。
O(n),也叫线性时间,这样的算法包括简单查找。
O(n * log n),这样的算法包括快速排序——一种速度较快的排序算法。
O(n**2 ),这样的算法包括选择排序——一种速度较慢的排序算法。
O(n!),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法
4.旅行商——> n!
这个算法要解决的是计算机科学领域非常著名的旅行商问题,其计算时间增加得非常快,而有些非常聪明的人都认为没有改进空间。
有一位旅行商。他需要前往5个城市。这位旅行商要前往这5个城市,同时要确保旅程最短。为此,可考虑前往这些城市的各种可能顺序。对于每种顺序,他都计算总旅程,再挑选出旅程最短的路线。5个城市有120种不同的排列方式。因此,在涉及5个城市时,解决这个问题需要执行120次操作。涉及6个城市时,需要执行720次操作(有720种不同的排列方式)。涉及7个城市时,需要执行5040次操作!
二.选择排序
1.内存的工作原理
假设你去看演出,需要将东西寄存。寄存处有一个柜子,柜子有很多抽屉。每个抽屉可放一样东西,你有两样东西要寄存,因此要了两个抽屉。你将两样东西存放在这里。现在你可以去看演出了!
…..
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
2.数组
在数组中添加新元素很麻烦
有时候,需要在内存中存储一系列元素。假设你要编写一个管理待办事项的应用程序,为此需要将这些待办事项存储在内存中。
…
你需要请求计算机重新分配一块可容纳4个待办事项的内存,再将所有待办事项都移到那里。
如果计算机没有空间,就得移到内存的其他地方,因此添加新元素的速度会很慢。
…
数组添加元素缺点:
(1)额外请求的内存可能用不上,导致浪费。
(2)待办事项超过10个后,你还得转移。
3.链表
链表中的元素可存储在内存的任何地方
链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
…
这犹如寻宝游戏。你前往第一个地址,那里有一张纸条写着“下一个元素的地址为123”。因此,你前往地址123,那里又有一张纸条,写着“下一个元素的地址为847”,以此类推。在链表中添加元素很容易:只需将其放入内存,并将其地址存储到前一个元素中。
…
使用链表时,根本就不需要移动元素。
只要有足够的内存空间,就能为链表分配内存
(1)数组的优势
查找元素迅速
需要随机地读取元素时,数组的效率很高,因为可迅速找到数组的任何元素。在链表中,元素并非靠在一起的,你无法迅速计算出第五个元素的内存地址,而必须先访问第一个元素以获取第二个元素的地址,再访问第二个元素以获取第三个元素的地址,以此类推,直到访问第五个元素。
(2)链表的优势
插入,删除元素简单
使用链表时,插入元素很简单,只需修改 它前面的那个元素指向的地址。而使用数组时,则必须将后面的元素都向后移。
…
删除元素时链表也是更好的选择,因为只需修改前一个元素指向的地址即可。而使用数组时,删除元素后,必须将后面的元素都向前移。
4.选择排序
选择排序是一种灵巧的算法,但其速度不是很快。
例子:
假设你的计算机存储了很多乐曲。对于每个乐队,你都记录了其作品被播放的次数。你要将这个列表按播放次数从多到少的顺序排列,从而将你喜欢的乐队排序。该如何做呢?

遍历找出播放次数最多的乐队,再找出第二多的乐队,得到一个有序列表。
检查列表中的每个元素,需要的时间为O(n),因此对于这种时间为O(n)的操作,你需要执行n次。
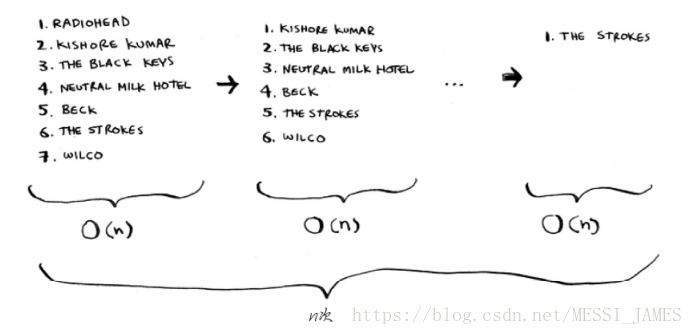
需要的总时间为 O(n × n),即O(n**2 )。
…
第一次需要检查n个元素,但随后检查的元素数依次为n 1, n – 2, …, 2和1。平均每次检查的元素数为1/2 × n,因此运行时间为O(n × 1/2 × n)。但大O表示法省略诸如1/2这样的常数(有关这方面的完整讨论,请参阅第4章),因此简单地写
作O(n × n)或O(n 2 )。
三.递归和栈
1.递归( recursion)
程序调用自身的编程技巧称为递归。递归的能力在于用有限的语句来定义对象的无限集合。
…
Stack Overflow上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能
更容易理解。如何选择要看什么对你来说更重要。”
2.栈(stack)
栈是限定仅在表头进行插入和删除操作的线性表。栈是一种简单的数据结构,数据暂时存储的地方。
3.递归调用栈
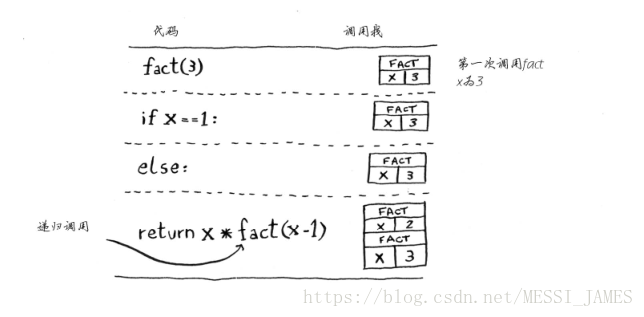
递归函数也使用调用栈!来看看递归函数 factorial 的调用栈。 factorial(5) 写作5!,其定义如下:5! = 5 * 4 * 3 * 2 * 1。同理, factorial(3) 为3 * 2 * 1。下面是计算阶乘的递归函数。
def fact(x):
if x == 1:
return 1
else:
return x * fact(x-1)
下面来详细分析调用 fact(3) 时调用栈是如何变化的。别忘了,栈顶的方框指出了当前执行
到了什么地方。
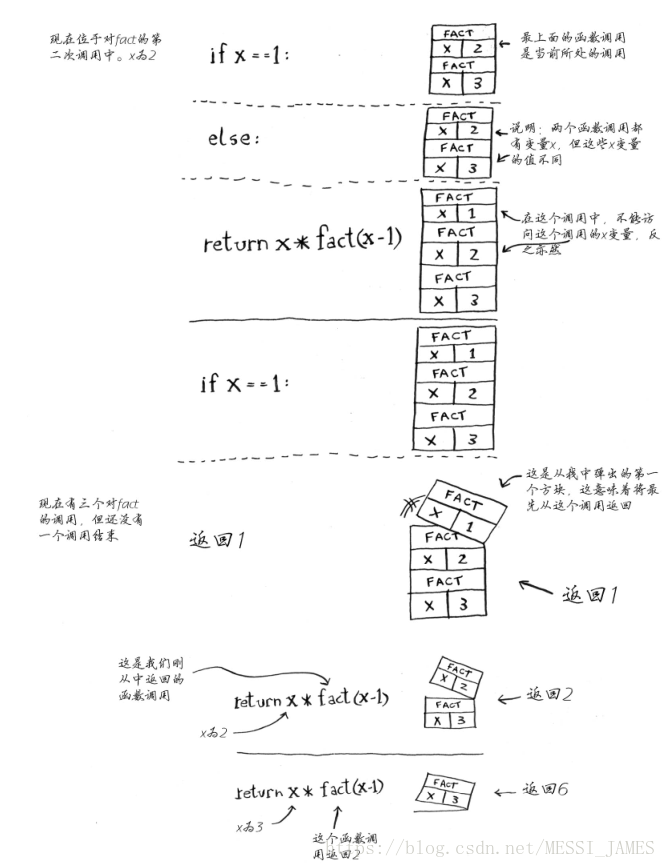
注意,每个 fact 调用都有自己的 x 变量。在一个函数调用中不能访问另一个的 x 变量。
4栈的缺陷
占内存
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。
5.递归和迭代的区别
迭代:利用变量的原值推算出变量的一个新值.如果递归是自己调用自己的话,迭代就是A不停的调用B。
…
递归中一定有迭代,但是迭代中不一定有递归,大部分可以相互转换.能用迭代的不用递归,递归调用函数,浪费空间,并且递归太深容易造成堆栈的溢出。
四.广度优先搜索
1.定义
广度优先搜索算法(又称宽度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
2.例子
假设你经营着一个芒果农场,需要寻找芒果销售商,以便将芒果卖给他。在Facebook,你与
芒果销售商有联系吗?为此,你可在朋友中查找。

这样一来,你不仅在朋友中查找,还在朋友的朋友中查找。别忘了,你的目标是在你的人际关系网中找到一位芒果销售商。因此,如果Alice不是芒果销售商,就将其朋友也加入到名单中。这意味着你将在她的朋友、朋友的朋友等中查找。使用这种算法将搜遍你的整个人际关系网,直到找到芒果销售商。这就是广度优先搜索算法。

3.队列
队列是一种先进先出(First In First Out,FIFO)的数据结构,而栈是一种后进先出(Last In First Out,LIFO)的数据结构。
…
如果你将两个元素加入队列,先加入的元素将在后加入的元素之前出队。因此,你可使用队列来表示查找名单!这样,先加入的人将先出队并先被检查。

4.广度优先搜索工作原理
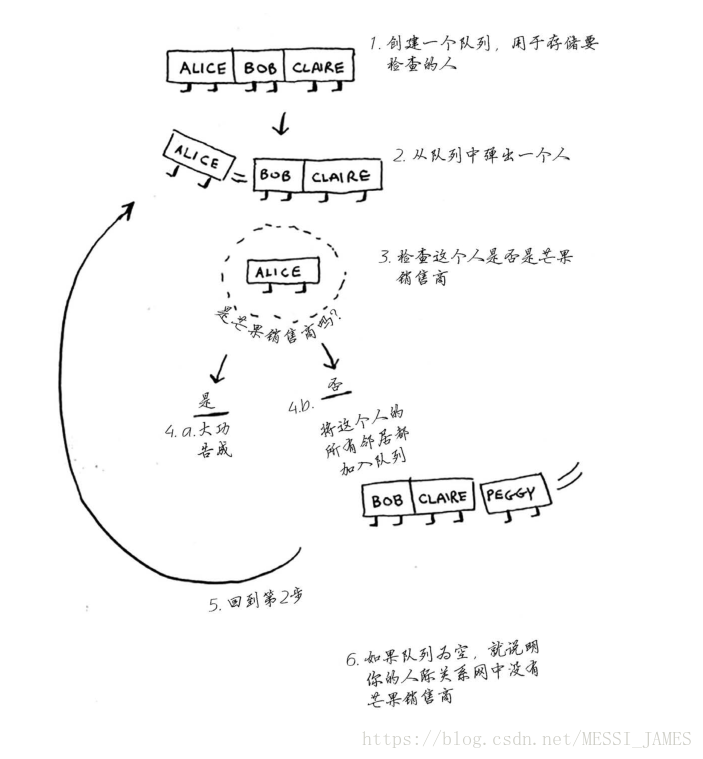
这个算法将不断执行,直到满足以下条件之一:
(1)找到一位芒果销售商;
(2)队列变成空的,这意味着你的人际关系网中没有芒果销售商。
五.狄克斯特拉算法
1.与广度优先算法比较
!
广度优先搜索:它找出的是段数最少的路径(如第一个图所示)。
狄克斯特拉算法:找出最快的路径(如第二个图所示)
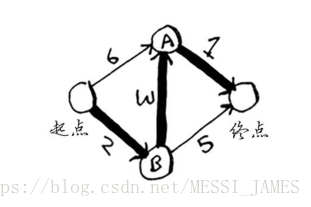
如果使用广度优先搜索,找到的最短路径将不是这条,因为这条路径包含3段,而有一条从起点到终点的路径只有两段。
2.狄克斯特拉算法流程
(1) 找出最便宜的节点,即可在最短时间内前往的节点。
(2) 对于该节点的邻居,检查是否有前往它们的更短路径,如果有,就更新其开销。
(3) 重复这个过程,直到对图中的每个节点都这样做了。
(4) 计算最终路径。
3.术语
(1) 狄克斯特拉算法用于每条边都有关联数字的图,这些数字称为权重(weight)。
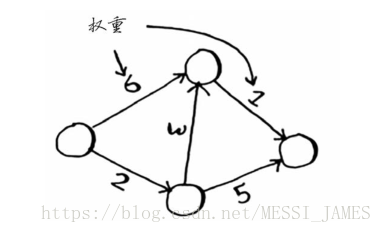
(2)带权重的图称为加权图(weighted graph),不带权重的图称为非加权图(unweighted graph)。
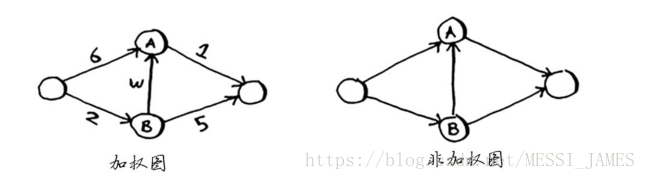
(3)要计算非加权图中的最短路径,可使用广度优先搜索。要计算加权图中的最短路径,可使用狄克斯特拉算法。
六.贪婪算法
1.定义
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
2.基本思想
从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件。若下一个数据和部分最优解连在一起不再是可行解时,就不把该数据添加到部分解中,直到把所有数据枚举完,或者不能再添加算法停止
3.过程
(1)建立数学模型来描述问题;
(2)把求解的问题分成若干个子问题;
(3)对每一子问题求解,得到子问题的局部最优解;
(4)把子问题的解局部最优解合成原来解问题的一个解。
4.背包问题
假设你是个贪婪的小偷,背着可装35磅(1磅≈0.45千克)重东西的背包,在商场伺机盗窃各种可装入背包的商品。你力图往背包中装入价值最高的商品,你会使用哪种算法呢?同样,你采取贪婪策略,这非常简单。
(1) 盗窃可装入背包的最贵商品。
(2) 再盗窃还可装入背包的最贵商品,以此类推。
只是这次这种贪婪策略不好使了!例如,你可盗窃的商品有下面三种。

分析:
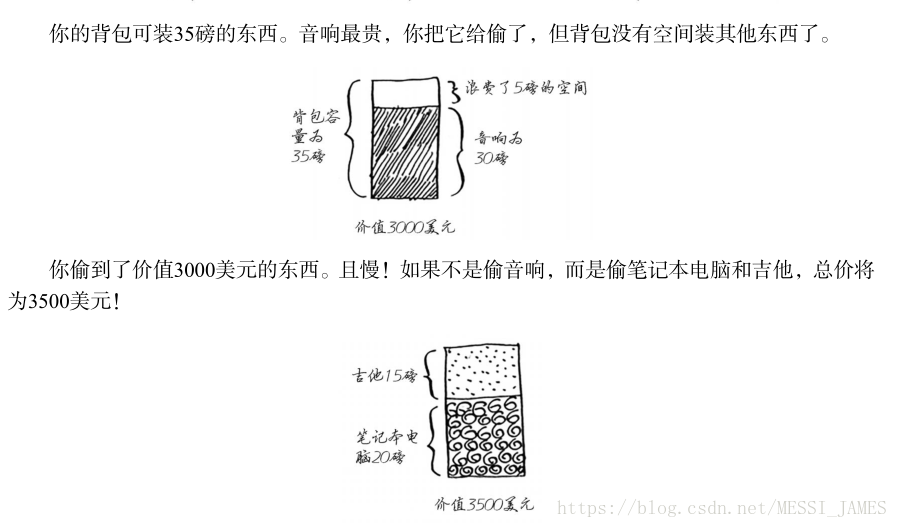
在这里,贪婪策略显然不能获得最优解,但非常接近。下一章将介绍如何找出最优解。不过
小偷去购物中心行窃时,不会强求所偷东西的总价最高,只要差不多就行了。
5.集合覆盖问题
假设你办了个广播节目,要让全美50个州的听众都收听得到。为此,你需要决定在哪些广播台播出。在每个广播台播出都需要支付费用,因此你力图在尽可能少的广播台播出。现有广播台名单如下。

每个广播台都覆盖特定的区域,不同广播台的覆盖区域可能重叠。
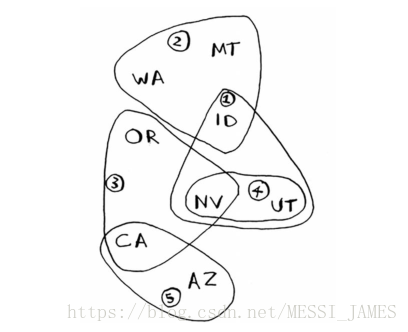
方法如下:
(1) 列出每个可能的广播台集合,这被称为幂集(power set)。可能的子集有2^n个。
(2) 在这些集合中,选出覆盖全美50个州的最小集合。 问题是计算每个可能的广播台子集需要很长时间。由于可能的集合有2 n个,因此运行时间为 O (2 n )。如果广播台不多,只有5~10个,这是可行的。但如果广播台很多,结果将如何呢?随着 广播台的增多,需要的时间将激增。假设你每秒可计算10个子集,所需的时间将如下。
近似算法

5.NP 完全问题(NPC)
(1)P类问题
这类问题是最简单的一类问题,即所有这类问题都可以用一个确定性算法在多项式时间内求出解。
此类问题的复杂度是此类问题的一个实例的规模n的多项式函数。
比如排序问题,求最短路径问题等。
(2)NP问题
(Non-deterministic Polynomial,即多项式复杂程度的非确定性问题)
有些问题很难找到多项式时间的解法(也许根本就不存在),但是如果给出了该问题的一个解,我们可以在多项式时间内判断这个解是否正确,比如对于哈密尔顿回路问题,如果给出一个任意的回路,我们可以很容易的判断出该回路是否是哈密尔顿回路(看是不是所有顶点都在回路中)。
…
P类问题是NP问题的子集,原因是P类问题既然能在多项式时间内求解,也必然能在多项式时间在验证它的解,满足NP类问题的定义。
(3)NP完全问题
如果所有NP问题都能在多项式时间内转化为A,则称A为NPC问题。NPC是NP的子集。
举例:
在一个周六的晚上,你参加了一个盛大的晚会。由于感到局促不安,你想知道这一大厅中是否有你已经认识的人。你的主人向你提议说,你一定认识那位正在甜点盘附近角落的女士罗丝。不费一秒钟,你就能向那里扫视,并且发现你的主人是正确的。然而,如果没有这样的暗示,你就必须环顾整个大厅,一个个地审视每一个人,看是否有你认识的人。
(4)NPH问题
NP-hard,NP困难问题
问题A不一定是一个NP问题,但所有的NPC问题都可以在多项式时间内转化为A,则称A为NPH问题。
举例详谈NPC问题
Jonah正为其虚构的橄榄球队挑选队员。他列了一个清单,指出了对球队的要求:优秀的四分卫,优秀的跑卫,擅长雨中作战,以及能承受压力等。他有一个候选球员名单,其中每个球员都满足某些要求。
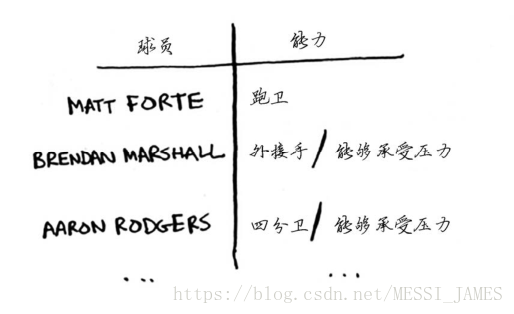
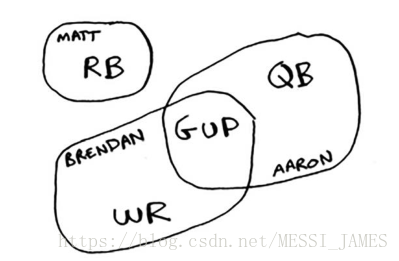
Jonah需要组建一个满足所有这些要求的球队,可名额有限。等等,Jonah突然间意识到,这不就是一个集合覆盖问题吗!方法:
Jonah可使用前面介绍的近似算法来组建球队。
(1) 找出符合最多要求的球员。
(2) 不断重复这个过程,直到球队满足要求(或球队名额已满)。
如何判定NPC问题
元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。
涉及“所有组合”的问题通常是NP完全问题。
不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。
如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。
如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。
如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。
区别
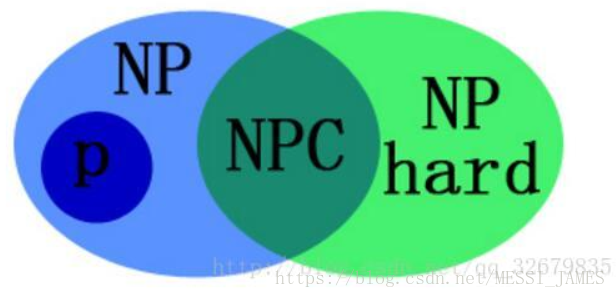
p问题:能够在多项式时间内解决的问题
NP问题:能够在多项式时间内验证的问题,P问题与NP问题考虑维度不同,p问题从解决上来考虑问题,而NP问题只是你给出一个解决方案,是否能够在多项式时间内验证
约化/规约(Reducibility):一个问题A可以约化为问题B的含义即是,可以用问题B的解法解决问题A
NPC问题:(1)是一个NP问题(2)NP问题都可以约化到它NPC问题
NPH问题:满足(2)不一定满足(1)
(5)总结
贪婪算法寻找局部最优解,企图以这种方式获得全局最优解。
对于NP完全问题,还没有找到快速解决方案。
面临NP完全问题时,最佳的做法是使用近似算法。
贪婪算法易于实现、运行速度快,是不错的近似算法。
六.动态规划之最长公共子串
假设你管理着网站dictionary.com。用户在该网站输入单词时,你需要给出其定义。但如果用户拼错了,你必须猜测他原本要输入的是什么单词。例如,Alex想查单词fish,但不小心输入了hish。在你的字典中,根本就没有这样的单词,但有几个类似的单词。在这个例子中,只有两个类似的单词,真是太小儿科了。实际上,类似的单词很可能有数千个。Alex输入了hish,那他原本要输入的是fish还是vista呢?
1.绘制网格
(1)在动态规划中,你要将某个指标最大化。在这个例子中,你要找出两个单词的最长公共子串。hish和fish都包含的最长子串是什么呢?hish和vista呢?这就是你要计算的值。单元格中的值通常就是你要优化的值。在这个例子中,这很可能是一个数字:两个字符串都包含的最长子串的长度。
…
(2)先比较his和fis。每个单元格都将包含这两个子串的最长公共子串的长度。这也给你提供了线索,让你觉得坐标轴很可能是这两个单词。因此,网格可能类似于下面这样。
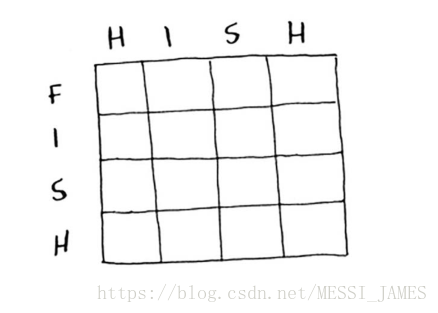
2.填充网格
现在,你很清楚网格应是什么样的。填充该网格的每个单元格时,该使用什么样的公式呢?由于你已经知道答案——hish和fish的最长公共子串为ish,所以先填充部分.
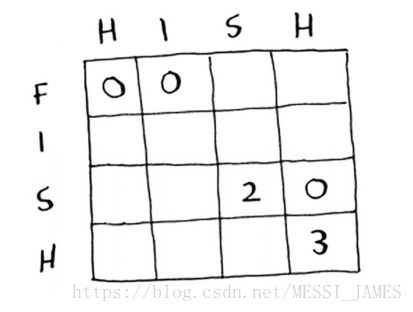
3.揭晓答案
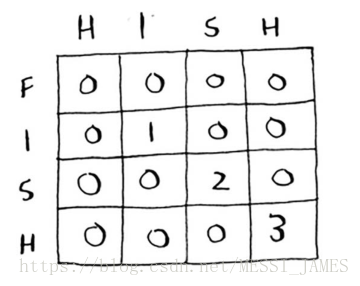
解释
4.分析
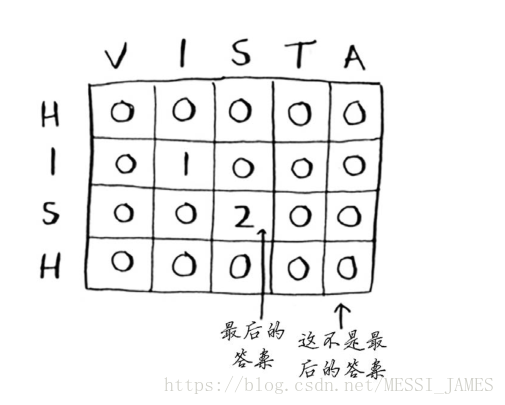
需要注意的一点是,这个问题的最终答案并不在最后一个单元格中!对于前面的背包问题,最终答案总是在最后的单元格中。但对于最长公共子串问题,答案为网格中最大的数字——它可能并不位于最后的单元格中。我们回到最初的问题:哪个单词与hish更像?hish和fish的最长公共子串包含三个字母,而hish和vista的最长公共子串包含两个字母。
…
因此Alex很可能原本要输入的是fish。