定义:
一些定义:
1.节点之间的路径长度:在树中从一个结点到另一个结点所经历的分支,构成了这两个结点间的路径上的经过的分支数称为它的路径长度
2.树的路径长度:从树的根节点到树中每一结点的路径长度之和。在结点数目相同的二叉树中,完全二叉树的路径长度最短。
3.结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
4.结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
5.树的带权路径长度(Weighted Path Length of Tree:WPL):定义为树中所有叶子结点的带权路径长度之和
- 最优二叉树:从已给出的目标带权结点(单独的结点) 经过一种方式的组合形成一棵树.使树的权值最小.。最优二叉树是带权路径长度最短的二叉树。根据结点的个数,权值的不同,最优二叉树的形状也各不相同。它们的共同点是:带权值的结点都是叶子结点。权值越小的结点,其到根结点的路径越长。
如,给定4个叶子结点a,b,c和d,分别带权7,5,2和4。构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:
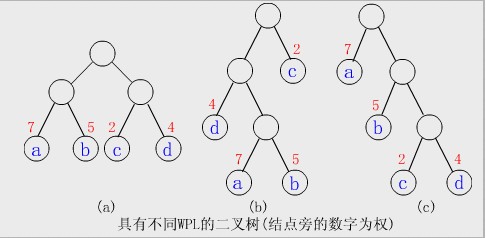
(a)WPL=7*2+5*2+2*2+4*2=36
(b)WPL=7*3+5*3+2*1+4*2=46
(c)WPL=7*1+5*2+2*3+4*3=35
其中(c)树的WPL最小,可以验证,它就是哈夫曼树。
注意:
① 叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
② 最优二叉树中,权越大的叶子离根越近。
③ 最优二叉树的形态不唯一,WPL最小。
构造哈夫曼树:
1) 根据给定的n个权值{w1, w2, w3, w4......wn}构成n棵二叉树的森林 F={T1 , T2 , T3.....Tn},其中每棵二叉树只有一个权值为wi 的根节点,其左右子树都为空;
2) 在森林F中选择两棵根节点的权值最小的二叉树,作为一棵新的二叉树的左右子树,且令新的二叉树的根节点的权值为其左右子树的权值和;
3)从F中删除被选中的那两棵子树,并且把构成的新的二叉树加到F森林中;
4)重复2 ,3 操作,直到森林只含有一棵二叉树为止,此时得到的这棵二叉树就是哈夫曼树。
构造过程如下图:

Java代码实现:
package fanzhenhua.sort;
import java.util.ArrayList;
import java.util.List;
import qiuzhitest.SequenceStack;
//构造一棵最优二叉树
public class HuffmanTree {
//使用内部类定义节点数据
public static class Node{
private Object data;
private double weight;
private Node left;
private Node right;
public Node(){}
public Node(Object data,double weight){
this.data=data;
this.weight=weight;
}
public String toString(){
return "Node[data=" + data + ", weight=" + weight + "]";
}
}
public static void main(String[] args){
List<Node> nodes = new ArrayList<Node>();
nodes.add(new Node("A", 40.0));
nodes.add(new Node("B", 8.0));
nodes.add(new Node("C", 10.0));
nodes.add(new Node("D", 30.0));
nodes.add(new Node("E", 10.0));
nodes.add(new Node("F", 2.0));
Node root=createTree(nodes);
printTree(root);
}
//创建最优二叉树
public static Node createTree(List<Node> nodes){
//如果集合元素大于1个则循环
while(nodes.size()>1){
//首先对集合元素进行排序
quickSort(nodes,0,nodes.size()-1);
//取出两个权重最小的结点
Node left=nodes.get(0);
Node right=nodes.get(1);
//定义一个父节点
Node parent=new Node(null,left.weight+right.weight);
//父节点指向两个子节点
parent.left=left;
parent.right=right;
//移除两个子节点
nodes.remove(0);
nodes.remove(0);
//将父节点添加到集合中
nodes.add(parent);
}
return nodes.get(0);
}
//采用非递归中序遍历二叉树
public static void printTree(Node root){
SequenceStack<Node> stack=new SequenceStack<Node>();
List<Node> list=new ArrayList<Node>();
Node node=root;
//刚开始先把根节点压入栈,往后每次判断节点不为空则压栈
do {
while(node!=null){
stack.push(node);
node=node.left;
}
node=stack.pop();
list.add(node);
//如果出栈的结点存在右节点,则指向该节点
if(node.right!=null){
node=node.right;
}else{//否则设置为空,下次循环继续出栈
node=null;
}//当栈不为空,或者当前节点引用不为空时循环
} while (!stack.isEmpty()||node!=null);
System.out.println(list);
}
//使用快速排序对集合中的结点根据权重进行排序
private static void quickSort(List<Node> nodes,int start,int end){
if(start<end)
{
//取得每一趟排序后基值的位置
int key=subSort(nodes,start,end);
//递归左边排序
quickSort(nodes,start,key-1);
//递归右边排序
quickSort(nodes,key+1,end);
}
}
//部分排序,每一趟排序
private static int subSort(List<Node> nodes,int start,int end){
Node temp=nodes.get(start);
while(start<end){
//找出右边第一个小于基值的位置
while(start<end&&nodes.get(end).weight>=temp.weight){
end--;
}
//将该值移动到左边
nodes.set(start, nodes.get(end));
//找出左边第一个大于基值的位置
while(start<end&&nodes.get(start).weight<=temp.weight){
start++;
}
//将该值移动到右边
nodes.set(end, nodes.get(start));
}
//最后基值存放的位置为end、或者start的位置
nodes.set(end, temp);
//返回基值的位置
return start;
}
}
运行结果:
[Node[data=A, weight=40.0],
Node[data=null, weight=100.0],
Node[data=D, weight=30.0],
Node[data=null, weight=60.0],
Node[data=F, weight=2.0],
Node[data=null, weight=10.0],
Node[data=B, weight=8.0],
Node[data=null, weight=30.0],
Node[data=C, weight=10.0],
Node[data=null, weight=20.0],
Node[data=E, weight=10.0]
]以上代码中的关键步骤包括:
(1)对list集合中所有节点进行排序;
(2)找出list集合中权值最小的两个节点;
(3)以权值最小的两个节点作为子节点创建新节点;
(4)从list集合中删除权值最小的两个节点,将新节点添加到list集合中
程序采用循环不断地执行上面的步骤,直到list集合中只剩下一个节点,最后剩下的这个节点就是哈夫曼树的根节点
哈夫曼编码:
根据哈夫曼树可以解决报文编码的问题。假设需要把一个字符串,如“abcdabcaba”进行编码,将它转换为唯一的二进制码,但是要求转换出来的二进制码的长度最小。
假设每个字符在字符串中出现频率为W,其编码长度为L,编码字符n个,则编码后二进制码的总长度为W1L1+W2L2+…+WnLn,这恰好是哈夫曼树的处理原则。因此可以采用哈夫曼树的构造原理进行二进制编码,从而使得电文长度最短。
对于“abcdabcaba”,共有a、b、c、d4个字符,出现次数分别为4、3、2、1,相当于它们的权值,将a、b、c、d以出现次数为权值构造哈夫曼树,得到下左图的结果。
从哈夫曼树根节点开始,对左子树分配代码“0”,对右子树分配“1”,一直到达叶子节点。然后,将从树根沿着每条路径到达叶子节点的代码排列起来,便得到每个叶子节点的哈夫曼编码,如下右图。

从图中可以看出,a、b、c、d对应的编码分别为0、10、110、111,然后将字符串“abcdabcaba”转换为对应的二进制码就是0101101110101100100,长度仅为19。这也就是最短二进制编码,也称为哈夫曼编码。
参考文章: