引用转载请注明出处,Thanks!
1 本文适合群体:
a.刚接触爬虫还不知道如何下手的同学
b.学完爬虫苦于没有框架的同学
c.简言之老少皆宜,共同进步
2 WebMagic介绍:
WebMagic一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。[注释1]
既然是牛刀小试,对于框架的具体结构和工作原理在这里就不一一的介绍,只需了解该框架的四大组件:Downloader、PageProcessor、Scheduler、Pipeline,今天我们需要用到的是PageProcessor,因为针对不同的页面,我们需要对PageProcessor做定制。
3 WebMagic环境集成
一款框架的使用,当然是需要我们获得其类库来进行调用,下面根据官方文档介绍两种使用方法:
a. 直接下载Jar包使用
进入 http://webmagic.io/download.html 下载jar包,选择版本号下载所有依赖jar包,并导入到工程中,下面会进行演示。

b. 通过Maven管理引用
在Maven下的pom.xml中添加如下依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
注意:WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
4 WebMagic牛刀小试
a. 打开eclipse
b. 新建Java Project :WebMagicTestDemo

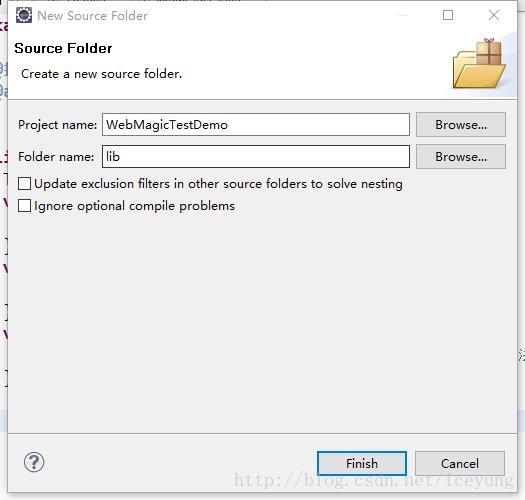
c. 新建源文件夹(选中项目名右键:new Source Folder)
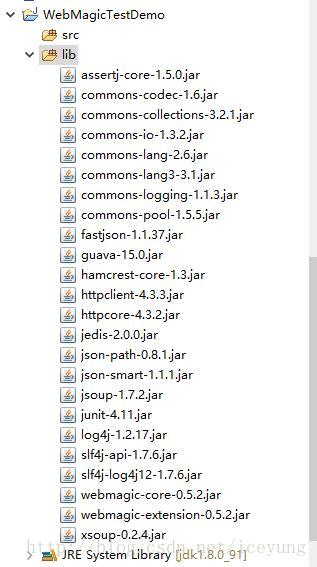
d. 将解压的jar包放入到lib目录下,供调用
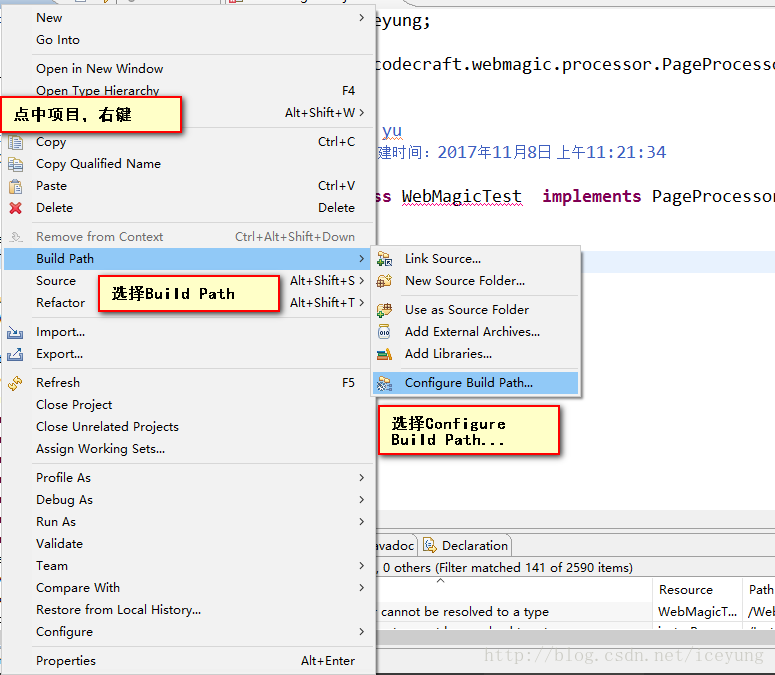
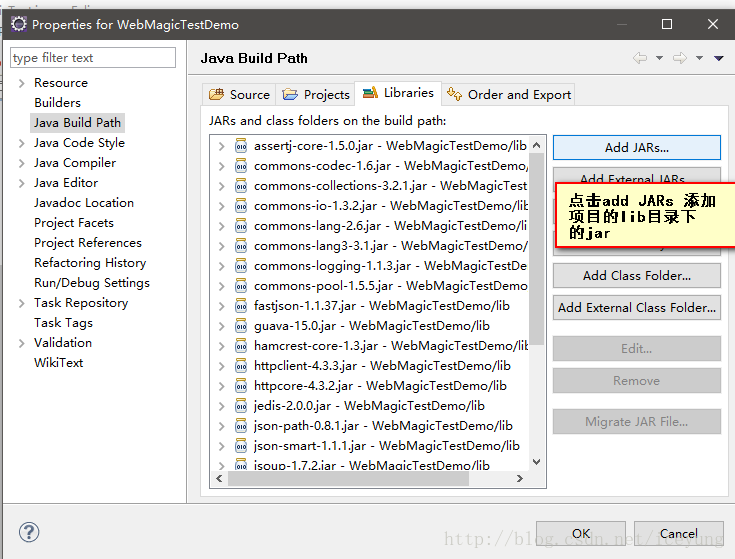
e. 添加lib下的jar包添加到项目的环境中
f. 新建WebMagicTest类,并实现PageProcessor接口
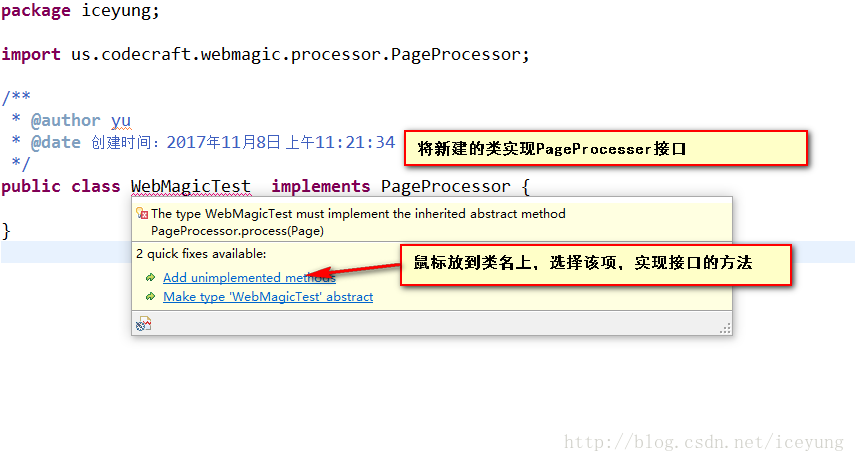
g. 具体实现代码如下:
package iceyung;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @author yu
* @date 创建时间:2017年11月8日 上午11:21:34
*/
public class WebMagicTest implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me()
.setRetryTimes(3)
.setSleepTime(100)
//添加cookie之前一定要先设置主机地址,否则cookie信息不生效
//.setDomain("lt.gdou.com")
//添加抓包获取的cookie信息
//.addCookie("xx", "xx")
//添加请求头,有些网站会根据请求头判断该请求是由浏览器发起还是由爬虫发起的
.addHeader("User-Agent",
"ozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.516.400 QQBrowser/9.4.8188.400")
.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
.addHeader("Accept-Encoding", "gzip, deflate, sdch").addHeader("Accept-Language", "zh-CN,zh;q=0.8")
.addHeader("Connection", "keep-alive");
//接口方法的实现,返回我们配置的site
public Site getSite() {
return site;
}
//PageProcessor最重要的部分,需要我们根据具体的页面进行定制
public void process(Page page) {
//直接从浏览器获取的xpath信息
// page.getHtml().xpath("//*[@id=\"article_list\"]/div[2]/div[1]/h1/span/a");
//不写[2]时代表所有的标题,所有修改删去[2],使用all()方法获得全部的标题此时返回的是List<String>对象
List<String> list = page.getHtml().xpath("//*[@id=\"article_list\"]/div/div[1]/h1/span/a/text()").all();
for(String name : list){
System.out.println(name);
}
}
public static void main(String[] args) {
//加入待爬去的衔接
String[] urls = {"http://blog.csdn.net/iceyung"};
Spider.create(new WebMagicTest())
.addUrl(urls)
//开启5个线程抓取
.thread(1)
//启动爬虫
.run();
System.out.println("爬取结束");
}
}
h. 运行结果如下:
JAVA课程学习九:类训练-学生管理实现
JAVA课程学习八:类训练-家中的电视
JAVA课程学习七:带格式字符串反转
JAVA课程学习六:简易两个数计算器
JAVA课程学习五:猜数字游戏
JAVA课程学习四:遍历与复制数组
JAVA课程学习三:查询日历表
JAVA课程学习二:99乘法表的编写
JAVA课程学习一:Hello World
androidstudio小知识记录-那些年遇到的坑儿
Android个人学习笔记之实战时间的获取相关-DateUtils
我的物联网之路-Android手机传感器概况(地磁为主)
androidstudio小知识记录-Genymotion安装与使用
Android个人学习笔记之ListView知识应用-仿IOS百度云条目点击显示菜单模块实现
Android个人学习笔记-底部导航切换Fragment的实现
get page: http://blog.csdn.net/iceyung
i. 源代码下载:
>详细见码云 [https://gitee.com/iceyung/WebMagicTestDemo.git](https://gitee.com/iceyung/WebMagicTestDemo.git)
引用: