论文简介
Abstract
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。但是现存的方法总是忽视了高阶或低阶组合特征的联系,或者要求专门的特征工程,因此作者建立了DeepFM模型,将FM与DNN结合起来。
Introduction
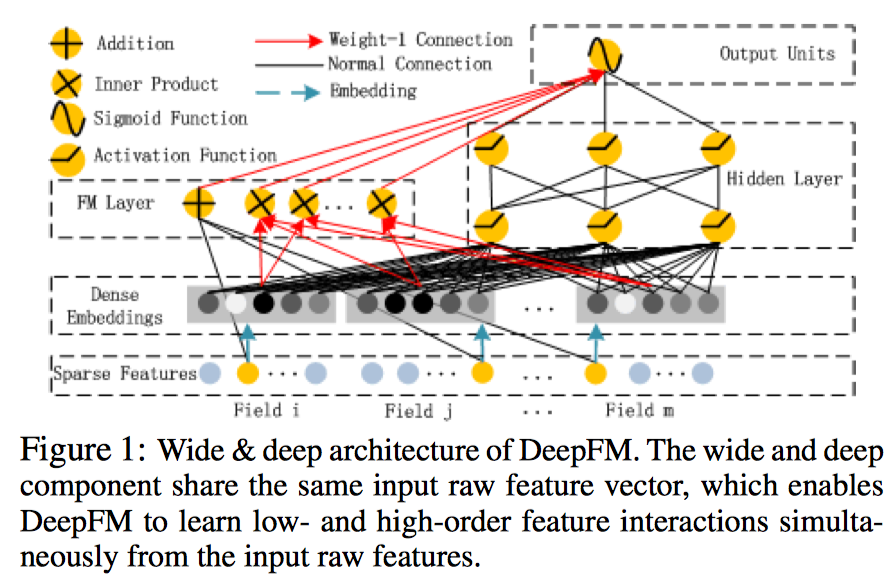
DeepFM的预测结果可以写为:
FM部分
FM部分的详细结构如下:
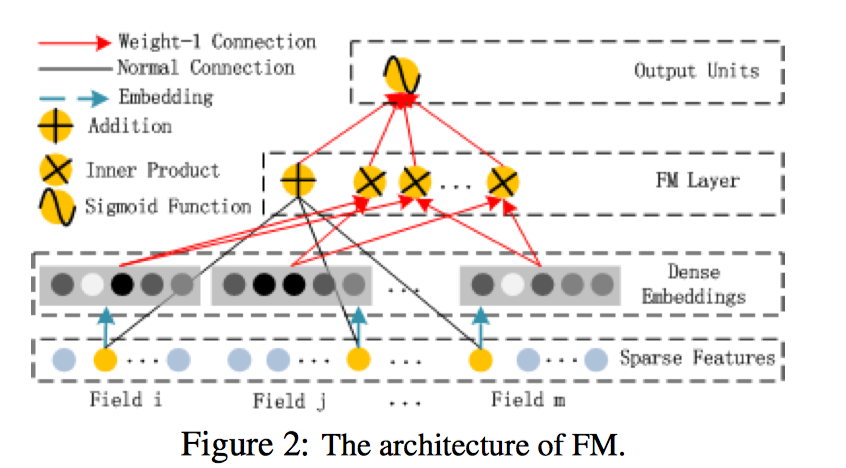
已知我们FM公式如下:
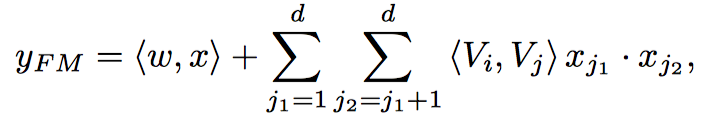
在目前很多的DNN模型中,都是借助了FM这种形式来做的embedding,具体推导如下:参考自该博客
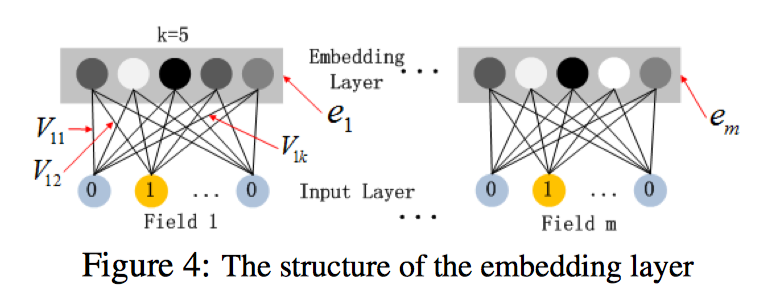

借助原文的图,这里k表示隐向量的维数, 表示第i个特征embeding之后在隐向量的第j维。假设已经给出了V矩阵,

其中第5-15个特征是同一个field经过one-hot编码后的表示,这是隐向量按列排成矩阵,同时,它也可看作embedding层的参数矩阵,按照神经网络前向传播的方式,embedding后的该slot下的向量值应该表示为:

可以看到这个结果就是一个5维的向量,而这个普通的神经网络传递时怎么和FM联系到一起的,仔细观察这个式子可以发现,由于是离散化或者one-hot之后的X,所以对于每一个field的特征而言,截断向量X都只有一个值为1,其他都为0。那么假设上述slot的V中,j为7的特征值为1,那么矩阵相乘之后的结果为:
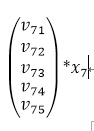
从结果中可以看到,实质上,每个slot在embedding后,其结果都是one-hot后有值的那一维特征所对应的隐向量。看到这里,在来解释模型中FM部分是如何借助这种方式得到的。回到模型的示意图,可以看到在FM层,是对每两个embedding向量做内积,那么我们来看,假设两个slot分别是第7和第20个特征值为1:
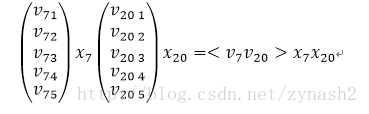
是不是感觉特别熟悉,没错,这个乘积的结果就是FM中二阶特征组合的其中一例,而对于所有非0组合(embedding向量组合)求和之后,就是FM中所有二阶特征的部分,这就是模型中FM部分的由来。
当然,FM中的一阶特征,则直接在embedding之前对于特征进行组合即可。
DNN部分
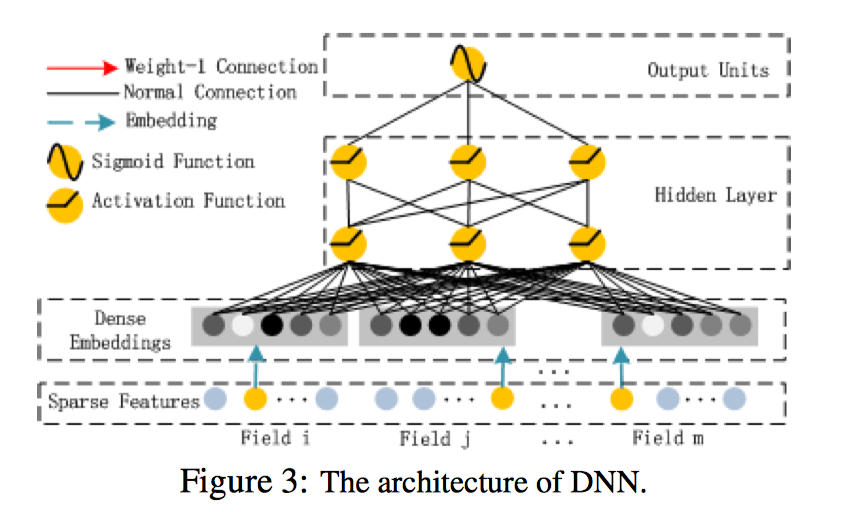
两个主要的特点:
- 每个field的embedding保持相同的size
- FM中的隐向量v被用作embedding 权重压缩数据
FM部分和深度部分分享一样的特征嵌入层能够带来两个好处:
- 可以学到低阶和高阶特征联系
- 不需要对输入进行专门的特征工程
代码实现
import tensorflow as tf
class Config(object):
"""
用来存储一些配置信息
"""
def __init__(self):
self.feature_dict = None
self.feature_size = None
self.field_size = None
self.embedding_size = 8
self.epochs = 100
self.deep_layers_activation = tf.nn.relu
self.loss = "logloss"
self.l2_reg = 0.1
self.learning_rate = 0.1
self.deep_layers=[32,32]
train_file = "./data/train.csv"
test_file = "./data/test.csv"
IGNORE_FEATURES = [
'id', 'target'
]
CATEGORITAL_FEATURES = [
'feat_cat_1', 'feat_cat_2'
]
NUMERIC_FEATURES = [
'feat_num_1', 'feat_num_2'
]
import pandas as pd
import DeepFM1.config as config
import gc
def FeatureDictionary(dfTrain=None, dfTest=None, numeric_cols=None, ignore_cols=None):
"""
目的是给每一个特征维度都进行编号。
1. 对于离散特征,one-hot之后每一列都是一个新的特征维度。所以,原来的一维度对应的是很多维度,编号也是不同的。
2. 对于连续特征,原来的一维特征依旧是一维特征。
返回一个feat_dict,用于根据 原特征名称和特征取值 快速查询出 对应的特征编号。
:param dfTrain: 原始训练集
:param dfTest: 原始测试集
:param numeric_cols: 所有数值型特征
:param ignore_cols: 所有忽略的特征. 除了数值型和忽略的,剩下的全部认为是离散型
:return: feat_dict, feat_size
1. feat_size: one-hot之后总的特征维度。
2. feat_dict是一个{}, key是特征string的col_name, value可能是编号(int),可能也是一个字典。
如果原特征是连续特征: value就是int,表示对应的特征编号;
如果原特征是离散特征:value就是dict,里面是根据离散特征的 实际取值 查询 该维度的特征编号。 因为离散特征one-hot之后,一个取值就是一个维度,
而一个维度就对应一个编号。
"""
assert not (dfTrain is None), "train dataset is not set"
assert not (dfTest is None), "test dataset is not set"
# 编号肯定是要train test一起编号的
df = pd.concat([dfTrain, dfTest], axis=0)
# 返回值
feat_dict = {}
# 目前为止的下一个编号
total_cnt = 0
for col in df.columns:
if col in ignore_cols: # 忽略的特征不参与编号
continue
# 连续特征只有一个编号
if col in numeric_cols:
feat_dict[col] = total_cnt
total_cnt += 1
else:
# 离散特征,有多少个取值就有多少个编号
unique_vals = df[col].unique()
unique_cnt = df[col].nunique()
feat_dict[col] = dict(zip(unique_vals, range(total_cnt, total_cnt + unique_cnt)))
total_cnt += unique_cnt
feat_size = total_cnt
return feat_dict, feat_size
def parse(feat_dict=None, df=None, has_label=False):
"""
构造FeatureDict,用于后面Embedding
:param feat_dict: FeatureDictionary生成的。用于根据col和value查询出特征编号的字典
:param df: 数据输入。可以是train也可以是test,不用拼接
:param has_label: 数据中是否包含label
:return: Xi, Xv, y
"""
assert not (df is None), "df is not set"
assert not (feat_dict is None), "feat_dict is not set"
dfi = df.copy()
if has_label:
y = df['target'].values.tolist()
dfi.drop(['id','target'],axis=1, inplace=True)
else:
ids = dfi['id'].values.tolist() # 预测样本的ids
dfi.drop(['id'],axis=1, inplace=True)
# dfi是Feature index,大小和dfTrain相同,但是里面的值都是特征对应的编号。
# dfv是Feature value, 可以是binary(0或1), 也可以是实值float,比如3.14
dfv = dfi.copy()
for col in dfi.columns:
if col in config.IGNORE_FEATURES: # 用到的全局变量: IGNORE_FEATURES, NUMERIC_FEATURES
dfi.drop([col], axis=1, inplace=True)
dfv.drop([col], axis=1, inplace=True)
continue
if col in config.NUMERIC_FEATURES: # 连续特征1个维度,对应1个编号,这个编号是一个定值
dfi[col] = feat_dict[col]
else:
# 离散特征。不同取值对应不同的特征维度,编号也是不同的。
dfi[col] = dfi[col].map(feat_dict[col])
dfv[col] = 1.0
# 取出里面的值
Xi = dfi.values.tolist()
Xv = dfv.values.tolist()
del dfi, dfv
gc.collect()
if has_label:
return Xi, Xv, y
else:
return Xi, Xv, ids
import numpy as np
import pandas as pd
import tensorflow as tf
from DeepFM1.DataReader import FeatureDictionary
from DeepFM1.DataReader import parse
import DeepFM1.config as con
##################################
# 1. 配置信息
##################################
config = con.Config()
##################################
# 2. 读取文件
##################################
dfTrain = pd.read_csv(con.train_file)
dfTest = pd.read_csv(con.test_file)
##################################
# 3. 准备数据
##################################
# FeatureDict
config.feature_dict, config.feature_size = FeatureDictionary(dfTrain=dfTrain, dfTest=dfTest, numeric_cols=con.NUMERIC_FEATURES, ignore_cols=con.IGNORE_FEATURES)
print(config.feature_dict)
print(config.feature_size)
# Xi, Xv
Xi_train, Xv_train, y = parse(feat_dict=config.feature_dict, df=dfTrain, has_label=True)
Xi_test, Xv_test, ids = parse(feat_dict=config.feature_dict, df=dfTest, has_label=False)
config.field_size = len(Xi_train[0])
print(Xi_train)
print(Xv_train)
print(config.field_size)
##################################
# 4. 建立模型
##################################
# 模型参数
# BUILD THE WHOLE MODEL
tf.set_random_seed(2018)
# init_weight
weights = dict()
# Sparse Features 到 Dense Embedding的全连接权重。[其实是Embedding]
weights['feature_embedding'] = tf.Variable(initial_value=tf.random_normal(shape=[config.feature_size, config.embedding_size],mean=0,stddev=0.1),
name='feature_embedding',
dtype=tf.float32)
# Sparse Featues 到 FM Layer中Addition Unit的全连接。 [其实是Embedding,嵌入后维度为1]
weights['feature_bias'] = tf.Variable(initial_value=tf.random_uniform(shape=[config.feature_size, 1],minval=0.0,maxval=1.0),
name='feature_bias',
dtype=tf.float32)
# Hidden Layer
num_layer = len(config.deep_layers)
input_size = config.field_size * config.embedding_size
glorot = np.sqrt(2.0 / (input_size + config.deep_layers[0])) # glorot_normal: stddev = sqrt(2/(fan_in + fan_out))
weights['layer_0'] = tf.Variable(initial_value=tf.random_normal(shape=[input_size, config.deep_layers[0]],mean=0,stddev=glorot),
dtype=tf.float32)
weights['bias_0'] = tf.Variable(initial_value=tf.random_normal(shape=[1, config.deep_layers[0]],mean=0,stddev=glorot),
dtype=tf.float32)
for i in range(1, num_layer):
glorot = np.sqrt(2.0 / (config.deep_layers[i - 1] + config.deep_layers[i]))
# deep_layer[i-1] * deep_layer[i]
weights['layer_%d' % i] = tf.Variable(initial_value=tf.random_normal(shape=[config.deep_layers[i - 1], config.deep_layers[i]],mean=0,stddev=glorot),
dtype=tf.float32)
# 1 * deep_layer[i]
weights['bias_%d' % i] = tf.Variable(initial_value=tf.random_normal(shape=[1, config.deep_layers[i]],mean=0,stddev=glorot),
dtype=tf.float32)
# Output Layer
deep_size = config.deep_layers[-1]
fm_size = config.field_size + config.embedding_size
input_size = fm_size + deep_size
glorot = np.sqrt(2.0 / (input_size + 1))
weights['concat_projection'] = tf.Variable(initial_value=tf.random_normal(shape=[input_size,1],mean=0,stddev=glorot),
dtype=tf.float32)
weights['concat_bias'] = tf.Variable(tf.constant(value=0.01), dtype=tf.float32)
# build_network
feat_index = tf.placeholder(dtype=tf.int32, shape=[None, config.field_size], name='feat_index') # [None, field_size]
feat_value = tf.placeholder(dtype=tf.float32, shape=[None, config.field_size], name='feat_value') # [None, field_size]
label = tf.placeholder(dtype=tf.float16, shape=[None,1], name='label')
# Sparse Features -> Dense Embedding
embeddings_origin = tf.nn.embedding_lookup(weights['feature_embedding'], ids=feat_index) # [None, field_size, embedding_size]
feat_value_reshape = tf.reshape(tensor=feat_value, shape=[-1, config.field_size, 1]) # -1 * field_size * 1
# --------- 一维特征 -----------
y_first_order = tf.nn.embedding_lookup(weights['feature_bias'], ids=feat_index) # [None, field_size, 1]
w_mul_x = tf.multiply(y_first_order, feat_value_reshape) # [None, field_size, 1] Wi * Xi
y_first_order = tf.reduce_sum(input_tensor=w_mul_x, axis=2) # [None, field_size]
# --------- 二维组合特征 ----------
embeddings = tf.multiply(embeddings_origin, feat_value_reshape) # [None, field_size, embedding_size] multiply不是矩阵相乘,而是矩阵对应位置相乘。这里应用了broadcast机制。
# sum_square part 先sum,再square
summed_features_emb = tf.reduce_sum(input_tensor=embeddings, axis=1) # [None, embedding_size]
summed_features_emb_square = tf.square(summed_features_emb)
# square_sum part
squared_features_emb = tf.square(embeddings)
squared_features_emb_summed = tf.reduce_sum(input_tensor=squared_features_emb, axis=1) # [None, embedding_size]
# second order
y_second_order = 0.5 * tf.subtract(summed_features_emb_square, squared_features_emb_summed)
# ----------- Deep Component ------------
y_deep = tf.reshape(embeddings, shape=[-1, config.field_size * config.embedding_size]) # [None, field_size * embedding_size]
for i in range(0, len(config.deep_layers)):
y_deep = tf.add(tf.matmul(y_deep, weights['layer_%d' % i]), weights['bias_%d' % i])
y_deep = config.deep_layers_activation(y_deep)
# ----------- output -----------
concat_input = tf.concat([y_first_order, y_second_order, y_deep], axis=1)
out = tf.add(tf.matmul(concat_input, weights['concat_projection']), weights['concat_bias'])
out = tf.nn.sigmoid(out)
config.loss = "logloss"
config.l2_reg = 0.1
config.learning_rate = 0.1
# loss
if config.loss == "logloss":
loss = tf.losses.log_loss(label, out)
elif config.loss == "mse":
loss = tf.losses.mean_squared_error(label, out)
# l2
if config.l2_reg > 0:
loss += tf.contrib.layers.l2_regularizer(config.l2_reg)(weights['concat_projection'])
for i in range(len(config.deep_layers)):
loss += tf.contrib.layers.l2_regularizer(config.l2_reg)(weights['layer_%d' % i])
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=config.learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(loss)
##################################
# 5. 训练
##################################
# init session
sess = tf.Session(graph=tf.get_default_graph())
sess.run(tf.global_variables_initializer())
# train
feed_dict = {
feat_index: Xi_train,
feat_value: Xv_train,
label: np.array(y).reshape((-1,1))
}
for epoch in range(config.epochs):
train_loss,opt = sess.run((loss, optimizer), feed_dict=feed_dict)
print("epoch: {0}, train loss: {1:.6f}".format(epoch, train_loss))
##################################
# 6. 预测
##################################
dummy_y = [1] * len(Xi_test)
feed_dict_test = {
feat_index: Xi_test,
feat_value: Xv_test,
label: np.array(dummy_y).reshape((-1,1))
}
prediction = sess.run(out, feed_dict=feed_dict_test)
sub = pd.DataFrame({"id":ids, "pred":np.squeeze(prediction)})
print("prediction:")
print(sub)
数据集
train.csv
id,target,feat_cat_1,feat_cat_2,feat_num_1,feat_num_2
1,0,1,2,3.1,2.2
2,0,2,3,2.1,3.1
3,1,0,2,1.0,3.4
4,1,1,1,2.1,1.6
5,0,0,0,0.5,1.8
test.csv
id,target,feat_cat_1,feat_cat_2,feat_num_1,feat_num_2
6,0,1,2,3.1,2.2
7,0,2,3,2.1,3.1
8,1,0,2,1.0,3.4
9,1,1,1,2.1,1.6
10,0,0,0,0.5,1.8
以上数据纯属手工捏造,感兴趣的朋友可以使用
kaggle上的数据集,挺多大佬的deepfm代码实现使用该数据集。