目录
P-R 曲线绘制
Precision-查准率-预测出来的正例中正确的比例---找得对-(查准率高-宁缺毋滥
Recall-查全率-衡量正例被预测出来的比例---找得全-(查全率高-宁可错杀一百不能放过一个
在机器学习中分类器往往输出的不是类别标号,而是属于某个类别的概率值,根据分类器的预测结果从大到小对样例进行排序,逐个把样例加入正例进行预测,算出此时的P、R值。
如下图:
Inst#是样本序号,图中有20个样本,真实情况正例反例各有10个。
Class是ground truth(ground truth是什么?见文末!) 标签,p是positive样本(正例),n当然就是negative(负例)
score是我的分类器对于该样本属于正例的可能性的打分。因为一般模型输出的不是0,1的标注,而是小数,相当于置信度。
然后设置一个从高到低的阈值y,大于等于阈值y的被我正式标注为正例,小于阈值y的被我正式标注为负例。
显然,我设置n个阈值,我就能得到n种标注结果,评判我的模型好不好使,也就可能得到n个PR值对用来画PR曲线。
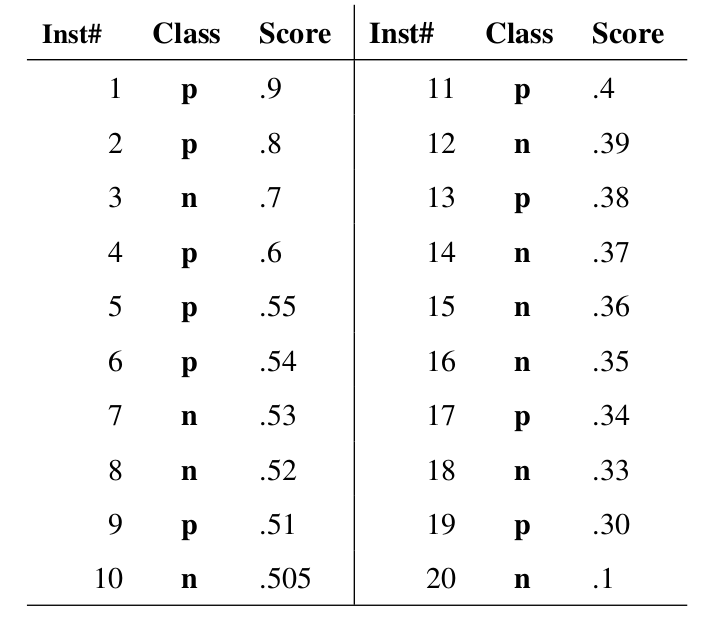
先用分数(score):0.9作为阈值(大于等于1为正例,小于1为反例),此时TP=1,FP=0,FN=9,故P=1,R=0.1。
用0.8作为阈值,P=1,R=0.2。
用0.7作为阈值,P=0.67,R=0.2。
用0.6作为阈值,P=0.75,R=0.3。
以此类推。。。
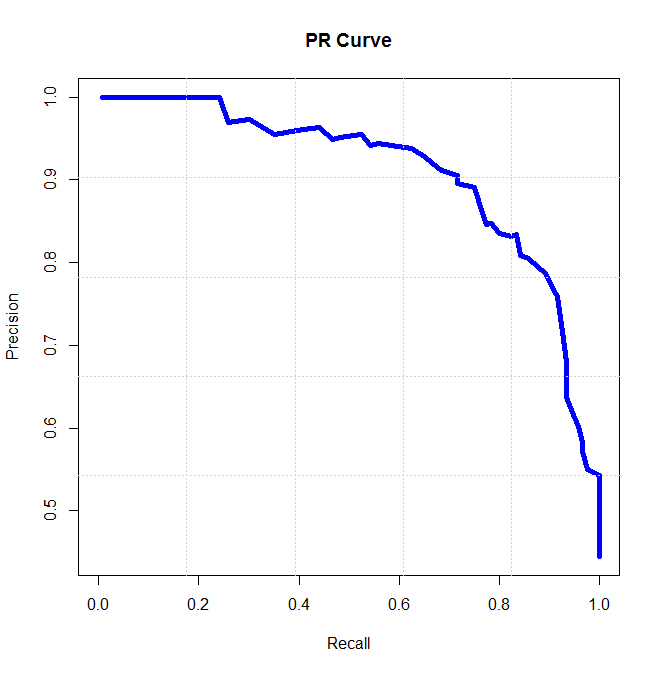
最后得到一系列P、R值序列,就画出P-R曲线(示意图,不对应上面数据):
Ground Truth
在看英文文献的时候,经常会看到Ground Truth这个词汇,翻译的意思是地面实况,放到机器学习里面,再抽象点可以把它理解为真值、真实的有效值或者是标准的答案。
维基百科对Ground Truth在机器学习领域的解释是:
在机器学习中,“ground truth”一词指的是训练集对监督学习技术的分类的准确性。这在统计模型中被用来证明或否定研究假设。“ground truth”这个术语指的是为这个测试收集适当的目标(可证明的)数据的过程。
今天在看《Outlier Analysis》时,有句话: However, it is generally much harder to reduce bias in outlier ensembles because of the absence of ground truth.
放到对异常点的检测方面来理解这个ground truth就好理解了。在对异常点进行检测的时候,通过一些ensemble methods可以在一定程度上提高准确性,从而减少bias,但是由于对于异常点的定义本身就是一个问题,所以在对这些数据进行label的过程中,保证labeled data是正确的异常点也是个问题。
再举个例子,在图像识别中,一张图片是猫还是狗这个没有什么争议性,但是如果在时间序列中让你指出什么样的数据是 normal,什么样的数据是 abnormal,100个人可能会有100种回答,因为 normal 和 abnormal 之间没有什么明确的界限,所以在研究时间序列中的 outlier analysis 时,Ground Truth 也是一个不可避免的问题。
————————————————
版权声明:本文为CSDN博主「敲代码的quant」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FrankieHello/article/details/80486167
P-R曲线
原文链接:https://blog.csdn.net/teminusign/article/details/51982877
原文链接:https://blog.csdn.net/u013249853/article/details/96132766
