本文旨在分享通过cuda进行的一种二维矩阵运算方法
具体的二维矩阵内存分配,以及参数传递,通过以下的一个二维矩阵加法例子进行展示。
运行环境:cuda8.0; visual studio 2015
源码如下所示:
#include <stdio.h>
#include <stdlib.h>
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include"iostream"
using namespace std;
/* Example:2维矩阵加法 */
const int N = 10;
const int M = 5;
__global__ void add_2D(float A[][M], float B[][M], float C[][M]);
int main()
{
/*cpu上开空间*/
float(*h_a)[M] = new float[N][M];
float(*h_b)[M] = new float[N][M];
float(*h_c)[M] = new float[N][M];
cout << "h_a:" << endl;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
h_a[i][j] = i + j;
h_b[i][j] = i + j;
cout << h_a[i][j] << " ";
}
cout << endl;
}
/*gpu上开空间*/
float(*d_a)[M], (*d_b)[M], (*d_c)[M];
cudaMalloc((void **)&d_a, sizeof(float)*N*M);
cudaMalloc((void **)&d_b, sizeof(float)*N*M);
cudaMalloc((void **)&d_c, sizeof(float)*N*M);
/*cpu 到 gpu*/
cudaMemcpy(d_a, h_a, sizeof(float)*N*M, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, sizeof(float)*N*M, cudaMemcpyHostToDevice);
cudaMemcpy(d_c, h_c, sizeof(float)*N*M, cudaMemcpyHostToDevice);
/*核函数*/
dim3 blockNum(1);
dim3 threadNum(N, M);
add_2D << <blockNum, threadNum >> >(d_a, d_b, d_c);
/*gpu 到 cpu*/
cudaMemcpy(h_c, d_c, sizeof(float)*N*M, cudaMemcpyDeviceToHost);
cout << "h_c:" << endl;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
cout << h_c[i][j] << " ";
}
cout << endl;
}
return 0;
}
__global__ void add_2D(float A[][M], float B[][M], float C[][M])
{
unsigned int ix = threadIdx.x + blockDim.x*blockIdx.x;
unsigned int iy = threadIdx.y + blockDim.y*blockIdx.y;
if (ix < N && iy < M) {
C[ix][iy] = A[ix][iy] + B[ix][iy];
}
}
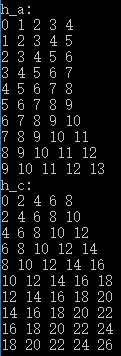
运行结果: