
La magie du code eBPF, propageant les adresses homologues directement dans le flux TCP pour reconstruire la topologie de communication
译自Créer une topologie réseau d'une application Kubernetes de manière non intrusive,作者 Ilya Shakhat。
introduire
Une application Kubernetes est logiquement divisée en deux parties : une partie est constituée des ressources informatiques (représentées par des pods), et l'autre partie donne accès à l'application (représentée par des services). Les clients de l'application peuvent y accéder en utilisant le nom abstrait sans se soucier du pod qui gère réellement la demande. Et comme un seul service peut avoir plusieurs pods comme backends, il agit également comme un équilibreur de charge. Dans un déploiement Kubernetes par défaut, cette fonction d'équilibrage de charge est implémentée à l'aide d'iptables ou d'IPVS Linux très simples - les deux fonctionnent au niveau de la couche L4 (comme TCP) et implémentent un mécanisme de round-robin naïf et aléatoire. Bien entendu, les fournisseurs de cloud peuvent également proposer des solutions d'équilibrage de charge plus traditionnelles pour exposer les applications, mais commençons simplement.
Lorsque l'on réfléchit aux différents problèmes qui peuvent survenir dans les applications déployées dans Kubernetes, il existe une classe de problèmes qui nécessitent de comprendre l'instance spécifique de traitement des demandes des clients. Par exemple : (1) un pod d'application est déployé sur un hôte avec une mauvaise connexion réseau et met plus de temps à établir une nouvelle connexion que les autres pods, ou (2) les performances d'un pod se dégradent avec le temps, tandis que les performances des autres pods restent stables. , ou (3) la demande d'un client spécifique affecte les performances de l'application. Le traçage distribué est souvent l'un des moyens d'obtenir des informations sur des problèmes comme celui-ci, et il est évidemment utilisé pour tracer le chemin d'une requête client vers l'application backend. Traditionnellement, le traçage distribué nécessite une certaine forme d’instrumentation, qui peut passer de l’ajout manuel de code à une injection entièrement automatisée dans le runtime. Mais le même effet peut-il être obtenu sans aucune modification du code client ?
Pour déboguer le problème ci-dessus, nous avons essentiellement besoin de deux fonctionnalités de traçage distribué : (1) collecter des métriques liées à la latence des requêtes et (2) savoir exactement où va chaque requête. La première fonctionnalité peut être facilement implémentée de manière non intrusive à l'aide de l'un des nombreux outils pris en charge par eBPF (une technologie qui permet d'attacher dynamiquement des sondes aux fonctions du noyau), par exemple la journalisation du processus qui a établi une nouvelle connexion, l'obtention des métriques liées au socket/connexion. et même vérifier les retransmissions ou les réinitialisations de connexion malveillantes. Dans l'écosystème openEuler, un tel outil est gala-gopher, qui fournit un grand nombre de sondes différentes, notamment des sondes socket, TCP et L7/HTTP(s). Cependant, la deuxième fonctionnalité (savoir où va une demande individuelle) est beaucoup plus difficile à réaliser. Dans un cadre de traçage distribué, cela est réalisé en injectant un ID span/trace dans la charge utile de l'application, puis en corrélant les observations du client et du backend en utilisant le même ID span. Être non intrusif dans le code de l'application signifie que les mêmes informations doivent être injectées de manière générique, mais faire cela dans le protocole d'application n'est tout simplement pas réalisable car cela nécessiterait d'intercepter le trafic sortant, de l'analyser, d'injecter l'ID et c'est sérialisé et transmis. On dirait que nous venons de réinventer un maillage de services !
Avant de continuer, examinons les données disponibles dans la surveillance du réseau. Ici, nous supposons que le moniteur obtiendra des informations de tous les nœuds hébergeant le pod d'application, puis que ces données seront traitées, par exemple, par Prometheus. Collectez-les. Pour y parvenir, nous avons besoin d’un environnement expérimental.
environnement de test
Tout d’abord, nous avons besoin d’un cluster Kubernetes multi-nœuds déployé. Dans Huawei Cloud, le service correspondant s'appelle Cloud Container Engine (CCE).
Ensuite, nous avons besoin d'une application de test, et pour cela nous utiliserons un programme Python très simple qui accepte une requête HTTP et est capable d'envoyer des requêtes HTTP sortantes à l'adresse spécifiée dans la requête d'origine. De cette façon, nous pouvons facilement relier les applications.
Ces applications seront nommées avec les lettres latines A, B, etc. L'application A est déployée en tant que déploiement A et service A, et ainsi de suite. La première application sera également exposée au monde extérieur afin de pouvoir être appelée de l'extérieur.
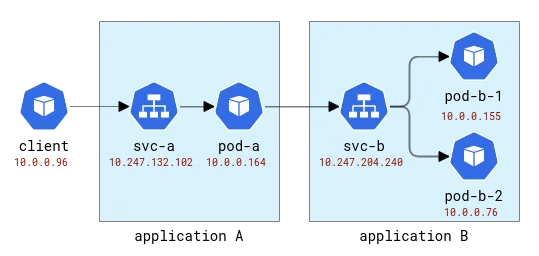
Topologie des applications A et B
Dans Kubernetes, Gala-gopher est déployé en tant qu'ensemble de démons et s'exécute sur chaque nœud Kubernetes. Il fournit des métriques qui sont consommées par Prometheus et finalement visualisées par Grafana. La topologie du service est construite sur la base de métriques et visualisée par le plugin NodeGraph.
Observabilité
Envoyons quelques requêtes à l'application A et transmettons-les à l'application B comme ceci :
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
Dans le résultat, nous voyons que l’une des requêtes pour l’application B a été envoyée à un pod et que l’autre requête a été envoyée à un autre pod. Voici comment la topologie apparaît dans Grafana :
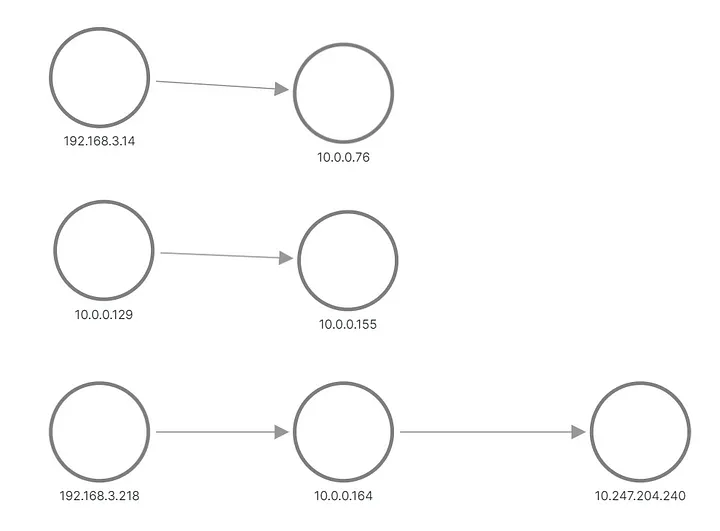
A et B appliquent une topologie, reconstruite à partir de métriques
Les rangées du haut et du milieu montrent quelque chose qui envoie une requête au pod de l'application B, tandis que la rangée du bas montre l'un des pods de A qui envoie une requête à l'adresse IP virtuelle du service B. Mais cela ne ressemble pas du tout à ce à quoi nous nous attendions, n’est-ce pas ? Nous ne voyons que trois ensembles de nœuds sans liens entre eux. Les adresses IP du sous-réseau 192.168.3.0/24 sont les adresses de nœud du réseau privé de cluster (VPC) et 10.0.0.1/24 est l'adresse du pod, à l'exception de 10.0.0.129, qui est l'adresse de nœud utilisée pour l'intra-réseau. communication des nœuds.
Désormais, ces métriques sont collectées au niveau du socket, ce qui signifie qu’elles correspondent exactement à ce que le processus de candidature peut voir. La collecte se fait via des sondes eBPF, la première idée est donc de vérifier si le noyau du système d'exploitation en sait plus sur la connexion de l'application que les informations disponibles dans le socket. Le cluster est configuré avec un CNI par défaut et le service Kubernetes est implémenté en tant que règle iptables. La sortie d'iptables-save montre la configuration. Les plus intéressantes sont ces règles qui configurent réellement l’équilibrage de charge :
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
L'équilibrage de charge est effectué sur le même nœud que le client. Donc, si nous mappons les pods aux nœuds, cela ressemble à ceci :
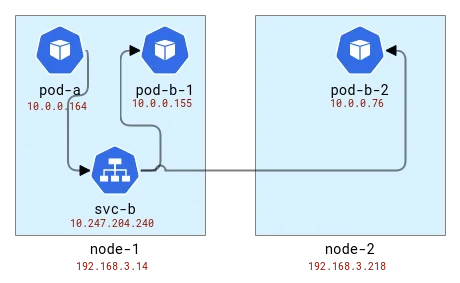
Mapper la topologie des applications A et B aux nœuds Kubernetes
En interne, iptables (en fait nftables ) utilise le module conntrack pour comprendre que les paquets appartiennent à la même connexion et doivent être traités de la même manière. Conntrack est également responsable de la traduction des adresses, de sorte que les nœuds avec des applications clientes doivent savoir où envoyer les paquets. Vérifions-le à l'aide de l'outil CLI conntrack.
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
D'accord, nous voyons donc que sur le premier nœud, l'adresse a été traduite à partir du pod de l'application A et nous avons obtenu une adresse de nœud avec un port aléatoire. Sur le deuxième nœud, les informations de connexion sont inversées car son propre paquet est en fait une réponse, mais en gardant cela à l'esprit, nous voyons que la demande provient du premier nœud et du même port aléatoire. Notez qu'il y a deux requêtes sur le nœud-1 car nous avons envoyé 2 requêtes et elles ont été traitées par des pods différents : pod-b-1 sur le même nœud et pod-b-2 sur un autre nœud.
La bonne nouvelle ici est qu'il est possible de connaître le destinataire réel de la requête sur le nœud client, mais pour le côté serveur, il doit être corrélé avec les informations collectées sur le nœud client . comme ça:
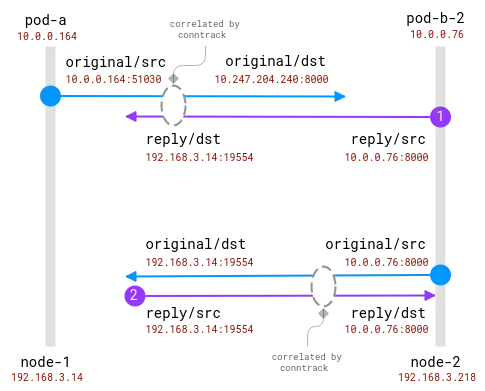
Les connexions sont suivies par le module conntrack. Le cercle bleu est l'adresse locale observée dans le socket et le violet est l'adresse distante. Le défi est de relier le violet et le bleu.
Lorsque les pods client et serveur se trouvent sur le même nœud, la corrélation devient plus simple, mais certaines hypothèses subsistent quant aux adresses réelles et à celles qui doivent être ignorées :
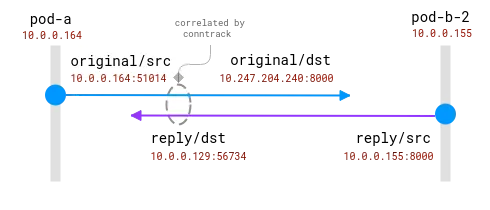
Une connexion entre deux Pods sur le même nœud. L'adresse source est réelle, mais l'adresse de destination doit être mappée
Ici, le système d'exploitation a une visibilité totale sur le NAT et peut fournir un mappage entre la source réelle et la destination réelle. Il est _possible_ de reconstruire le flux complet de 10.0.0.164 à 10.0.0.155.
Pour conclure cette section, il devrait être possible d'étendre les sondes eBPF existantes pour inclure des informations sur la traduction d'adresses à partir du module conntrack. Le client peut savoir où va la demande. Mais le serveur n’est pas toujours capable de savoir qui est le client, il n’existe pas directement d’algorithme de corrélation centralisé. En revanche, les méthodes de traçage distribuées fournissent aux clients et aux serveurs des informations sur leurs pairs, directement et immédiatement à partir des données de communication. Alors voici FlowTracer !
Traceur de flux
L'idée est simple : transférer des données entre pairs directement au sein de la connexion. Ce n'est pas la première fois qu'une telle fonctionnalité est nécessaire, par exemple, l'équilibreur de charge HTTP insérera l'en-tête HTTP X-Forwarded-For pour informer le serveur backend de l'existence du client. La limitation ici est que nous voulons rester au niveau L4, prenant ainsi en charge n'importe quel protocole de niveau application. Une telle fonctionnalité existe également, et certains équilibreurs de charge L4 (comme celui-ci ) peuvent injecter l'adresse d'origine en tant qu'option d'en-tête TCP et la rendre disponible au serveur.
Résumé des exigences :
- Adresse homologue de transport de couche L4.
- Possibilité d'activer dynamiquement l'injection d'adresses (tout en déployant facilement des applications dans les K8).
- Non invasif et rapide.
L'approche la plus simple semble consister à utiliser les options d'en-tête TCP (également appelées TOA). La charge utile est l'adresse IP et le numéro de port (car ils changent lors de la traduction de l'adresse). Étant donné que le déploiement de Huawei Kubernetes ne prend en charge qu'IPv4, nous pouvons limiter la prise en charge à IPv4 uniquement. Les adresses IPv4 sont constituées de 32 bits, tandis que les numéros de port nécessitent 16 bits, soit un total de 6 octets, plus 1 octet pour le type d'option et 1 octet pour la longueur de l'option. Voici à quoi ressemblent les spécifications de l'en-tête TCP :
L'en-tête peut contenir plusieurs options jusqu'à 40 octets. Chaque option peut avoir une longueur et un type variables.
En général, les paquets TCP Linux disposent déjà de certaines options, telles que MSS ou l'horodatage. Mais il nous reste encore environ 20 octets d’espace disponible.
Maintenant que nous savons où placer les données, la question suivante est de savoir où devons-nous ajouter le code ? Nous souhaitons que la solution soit aussi générale que possible et puisse être utilisée pour toutes les connexions TCP. L'emplacement idéal se situe quelque part dans le noyau de la pile réseau, dans ce qu'on appelle un tampon de socket (une structure qui représente les informations de connexion réseau), depuis le niveau supérieur jusqu'aux paquets prêts à être transmis sur le réseau. Du point de vue de la mise en œuvre, le code doit être du code eBPF (bien sûr !) et la fonctionnalité d'injection d'adresse peut ensuite être activée dynamiquement.
L'endroit le plus évident pour ce type de code est TC, un module de contrôle de flux. Au niveau du TC, le programme eBPF a accès au paquet créé et peut lire et écrire des données à partir du paquet. Un inconvénient est que le paquet doit être analysé depuis le début, c'est-à-dire que même si la fonction bpf_skb_load_bytes_relative fournit un pointeur vers le début de l'en-tête L3, la position L4 doit toujours être calculée manuellement. Le plus problématique est l’opération d’insertion. Il existe 2 fonctions avec des noms prometteurs, bpf_skb_adjust_room et bpf_skb_change_tail , mais elles autorisent un redimensionnement de paquets jusqu'à L3, pas L4. Une solution alternative consiste à vérifier si l'en-tête TCP existant contient certaines options et à les remplacer, mais vérifions d'abord ce que contient un paquet typique.
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
Il s'agit du paquet TCP SYN envoyé lorsque le client établit une connexion avec l'application backend. L'en-tête contient plusieurs options : MSS pour spécifier la taille maximale du segment, puis un accusé de réception facultatif, un horodatage spécifique pour garantir l'ordre des paquets, un opcode NOP éventuellement pour l'alignement des mots, et enfin pour l'alignement, la mise à l'échelle de la fenêtre pour la taille de la fenêtre. Dans cette liste, l'option d'horodatage est la meilleure candidate à couvrir (selon Wikipédia, l'adoption est encore d'environ 40%), tandis que DeepFlow - l'un des leaders du suivi non intrusif des eBPF - a cette opération a été réalisée en .
Même si cette approche semble réalisable, elle n’est pas facile à mettre en œuvre. Le programme TC a accès aux adresses traduites, ce qui signifie que la carte de traduction doit d'une manière ou d'une autre être récupérée du module conntrack et stockée. Le programme TC se connecte à la carte réseau, donc si un nœud possède plusieurs cartes réseau, le déploiement doit identifier correctement l'emplacement de connexion. Le module lecteur doit analyser tous les paquets pour trouver le TCP, puis parcourir les en-têtes pour trouver où se trouve notre en-tête. Est-ce qu'il y a un autre moyen?
Lorsque vous recherchez cette question via Google en août 2023, il est courant de voir Plus de résultats en bas de la page des résultats de recherche (j'espère que cet article de blog changera cela !). La référence la plus utile est un lien vers un correctif du noyau Linux produit par les ingénieurs de Facebook en 2020. Ce patch montre ce que nous recherchons :
Les premiers travaux sur BPF-TCP-CC ont permis d'écrire des algorithmes de contrôle de congestion TCP en BPF. Il offre la possibilité d'améliorer les délais d'exécution dans les environnements de production lors du test/de la publication de nouvelles idées de contrôle de la congestion. La même flexibilité peut être étendue à l’écriture d’options d’en-tête TCP.
Il n'est pas rare que des personnes souhaitent tester de nouvelles options d'en-tête TCP pour améliorer les performances TCP. Un autre cas d'utilisation concerne les centres de données qui disposent d'un environnement plus contrôlé et peuvent placer des options d'en-tête dans le trafic interne uniquement, ce qui offre plus de flexibilité.
Le Saint Graal, ce sont ces fonctions : bpf_store_hdr_opt et bpf_load_hdr_opt ! Les deux appartiennent à un type spécial de programme sock ops , disponible depuis le noyau 5.10, ce qui signifie qu’ils peuvent être utilisés dans presque toutes les versions après 2022. Le programme Sock ops est une fonction unique attachée au cgroup v2 qui lui permet d'être activé uniquement pour certains sockets (par exemple, appartenant à un conteneur spécifique). Le programme reçoit une seule opération indiquant l'état actuel du socket. Lorsque nous voulons écrire une nouvelle option d'en-tête, nous devons d'abord activer l'écriture pour une connexion active ou passive, puis nous devons indiquer la nouvelle longueur d'en-tête avant que la charge utile de l'en-tête puisse être écrite. L'opération de lecture est plus simple, cependant, nous devons également activer la lecture avant de pouvoir lire les options d'en-tête. Lorsqu'un paquet TCP est créé, le rappel de l'en-tête TCP est appelé. Cela se produit avant la traduction de l'adresse, nous pouvons donc copier l'adresse source du socket dans les options d'en-tête. Le lecteur peut facilement extraire la valeur de l'option d'en-tête et la stocker dans une carte BPF afin que plus tard, le consommateur puisse lire et mapper l'adresse distante observée vers l'adresse réelle. La partie BPF du code de première exécution compte bien moins de 100 lignes. Très bon!
Préparez le code pour la production
Cependant, le diable se cache dans les détails. Tout d’abord, nous avons besoin d’un moyen de supprimer les anciens enregistrements de la carte BPF. Le meilleur moment pour le faire est lorsque le module conntrack supprime la connexion de sa table. Cet article d'Arthur Chiao fournit une bonne description du module conntrack et de la structure interne du cycle de vie de la connexion, il est donc facile de trouver la fonction correcte dans les sources du noyau - nf_conntrack_destroy . Cette fonction reçoit l'entrée conntrack avant de la supprimer de la table interne. Puisque c'est à ce moment-là que la connexion se termine officiellement, nous pouvons également ajouter une sonde qui supprimera également la connexion de notre table de mappage.
Dans le programme sock ops, nous ne spécifions pas dans quels paquets la nouvelle option d'en-tête est injectée, en supposant qu'elle s'applique à tous les paquets. En fait, cela est vrai, mais la lecture n'est efficace que lorsque la connexion est dans l'état établi/reconnu, ce qui signifie que le côté serveur ne peut pas lire les options d'en-tête du paquet SYN entrant. SYN-ACK est également traité avant la pile TCP standard, et les options d'en-tête ne peuvent ni être injectées ni lues. En fait, cette fonctionnalité ne fonctionne aux deux extrémités que si la connexion s'exécute entièrement avec le premier PSH (paquet). C'est parfaitement bien pour une connexion fonctionnelle, mais si la tentative de connexion échoue, le client ne sait pas à quel endroit il essayait de se connecter. Il s'agit d'une erreur critique ; ces informations sont utiles pour déboguer les problèmes de réseau. Comme nous le savons, l'équilibrage de charge Kubernetes est implémenté sur le nœud client, afin que nous puissions extraire les informations de conntrack et les stocker dans le même format que les données reçues via le flux. La fonction Conntrack ___nf_conntrack_confirm_ est utile ici - elle est appelée lorsqu'une nouvelle connexion est sur le point d'être confirmée, ce qui pour les connexions TCP client actives (sortantes) se produit lorsque le premier paquet SYN est envoyé.
Avec tous ces ajouts, le code devient un peu pléthorique, mais reste tout de même bien inférieur à 1000 lignes au total. Le patch complet est disponible dans ce MR . Il est temps de l'activer dans notre configuration d'expérimentation et de vérifier à nouveau les métriques et la topologie !
Regarder:
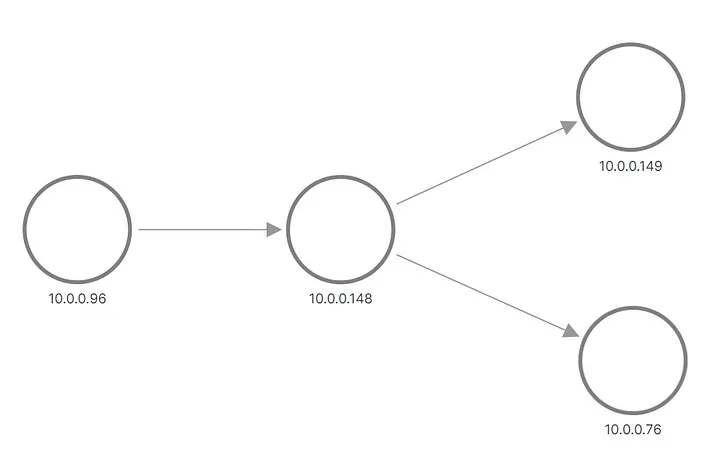
Topologie d'application A/B correcte
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenirCet article a été publié pour la première fois sur Yunyunzhongsheng ( https://yylives.cc/ ), tout le monde est invité à le visiter.