
Invité commun :
Fu Qingwu - architecte Big Data du groupe d'architecture de données OPPO
Dans l'application actuelle d'OPPO, nous avons parfaitement combiné le Shuttle auto-développé avec Alluxio, ce qui a considérablement amélioré les performances de l'ensemble du service de navette, doublant essentiellement les performances. Grâce à cette optimisation, nous avons réussi à réduire la pression du système d'environ la moitié et à doubler directement le débit. Cette combinaison résout non seulement les problèmes de performances, mais injecte également une nouvelle vitalité dans le système de service d'OPPO.
Version texte intégral partageant du contenu↓
Sujet de partage : "Pratique d'Alluxio en matière d'intégration de Data&AI Lake et d'entrepôt"
Architecture d'entrepôt de lac de données intégrée Data&AI
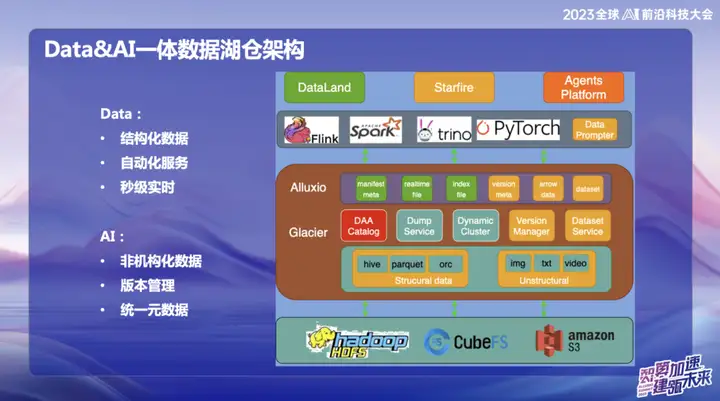
L’image ci-dessus montre l’architecture globale actuelle d’OPPO, qui est principalement divisée en deux parties :
1、Données
2、AI
Dans le domaine des données, OPPO se concentre principalement sur les données structurées, c'est-à-dire les données généralement traitées à l'aide de SQL. Dans le domaine de l’IA, l’accent est mis principalement sur les données non structurées. Afin de parvenir à une gestion unifiée des données structurées et non structurées, OPPO a mis en place un système appelé Données et Catalogue, qui est géré sous la forme de métadonnées de catalogue. Dans le même temps, il s'agit également d'un service de lac de données, dans lequel la couche supérieure d'accès aux données utilise le cache distribué Alluxio.
Pourquoi avons-nous choisi d'utiliser Alluxio ?
En raison de la grande taille de la salle informatique domestique d'OPPO, la quantité de mémoire inutilisée sur les nœuds informatiques est considérable. Nous estimons qu'en moyenne environ 1 Po de mémoire est inutilisée chaque jour et nous espérons pouvoir l'utiliser pleinement grâce à ce système de gestion de mémoire distribuée. La partie orange représente la gestion des données non structurées. Notre objectif est d'utiliser les services de lac de données pour rendre les données non structurées aussi faciles à gérer que les données structurées et accélérer la formation de l'IA.
Catalogue DAA
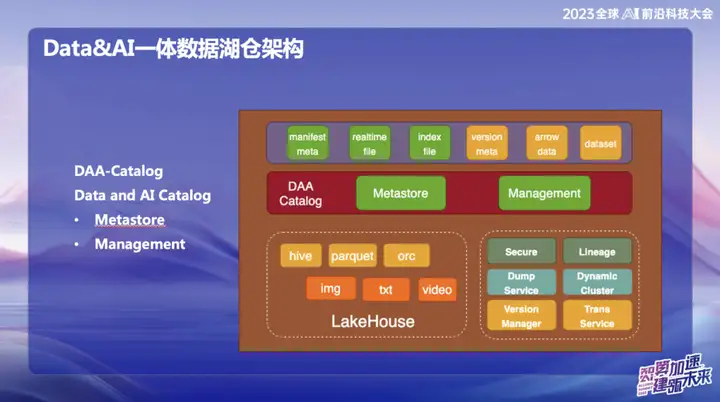
DAA-Catalog, ou Data and AI Catalog, est l'objectif poursuivi par notre équipe au bas de l'architecture de données. Nous avons choisi ce nom car OPPO s'engage à rivaliser avec les meilleures entreprises du secteur. Actuellement, nous pensons que Databricks est l'une des entreprises les plus remarquables dans le domaine des données et de l'IA. Qu'il s'agisse de technologie, de concepts avancés ou de modèles économiques, Databricks a bien performé.
Inspiré par l'Unicatalog de Databricks, nous voyons que le processus de formation des données de service et de l'IA de Databricks tourne principalement autour du catalogue Unity. Par conséquent, nous avons décidé de créer DAA-Catalog pour poursuivre notre objectif de rivaliser avec les meilleurs du secteur dans le domaine de l'entreposage de lacs de données.
Concrètement, cette fonctionnalité est divisée en deux modules principaux :
- Metastore (stockage des métadonnées) : Cette partie est responsable de la gestion des métadonnées, et la couche sous-jacente est basée sur la gestion des métadonnées Iceberg. Comprend les validations simultanées et la gestion du cycle de vie. Dans le même temps, nous utilisons Down Service pour la gestion, car nos données entreront d'abord dans l'énorme pool de cache mémoire d'Alluxio et réaliseront l'insertion et l'interrogation en temps réel de chaque enregistrement.
- Gestion : Cette partie est le service DOM. Pourquoi choisir Down Service ? Étant donné que les données sont d'abord stockées dans la mémoire d'Alluxio après leur saisie, elles atteignent des performances en temps réel de deuxième niveau. Pendant tout le processus, les données seront automatiquement transférées vers Iceberg via Catalog après leur arrivée, et les métadonnées se trouvent essentiellement dans Alluxio.
Pourquoi avons-nous besoin de mettre en œuvre une telle fonction temps réel de deuxième niveau ?
Principalement parce que nous avons déjà rencontré un problème sérieux lors de l'utilisation d'Iceberg. Cela nécessite essentiellement une validation toutes les 5 minutes. Chaque validation générera un grand nombre de petits fichiers, ce qui exerce beaucoup de pression sur le système informatique Flink et les métadonnées de HDFS. Dans le même temps, ces fichiers doivent également être nettoyés et fusionnés manuellement. Grâce au service Alluxio, les données peuvent être directement saisies en mémoire et le service Down est également géré via le catalogue. Pendant tout le processus, les données seront automatiquement transférées vers Iceberg après y avoir été saisies, et les métadonnées sont essentiellement toutes dans Alluxio.
Étant donné qu'OPPO coopère beaucoup avec Alluxio, nous avons effectué quelques ajustements basés sur la version 2.9 et les performances ont été considérablement améliorées. La lecture et l'écriture de fichiers de streaming sont implémentées sur le lac de données. Chaque élément de données peut être traité comme une validation sans qu'il soit nécessaire de valider l'intégralité du fichier.
Accélération des données structurées
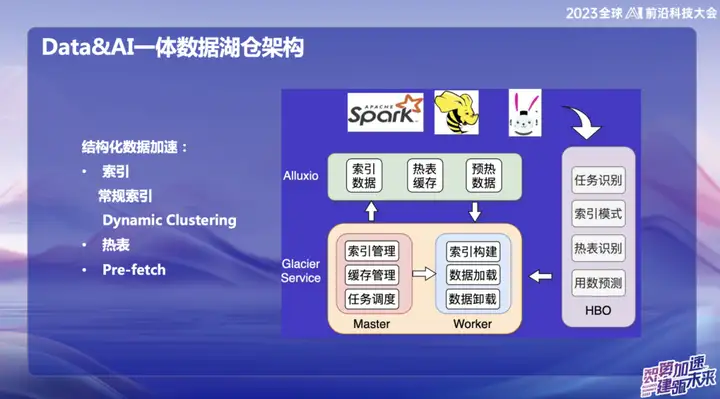
Avec le développement du Big Data, de nombreuses infrastructures sont devenues assez complètes, résolvant des problèmes dans de nombreux scénarios différents. Cependant, notre objectif est de savoir comment utiliser plus efficacement les ressources inutilisées et la mémoire. Par conséquent, nous nous engageons à partir de deux aspects : l’un est l’accélération du cache et l’autre est l’optimisation des tables actives et des index.
Nous avons proposé un concept appelé « Dynamic Cluster », qui est une fonction d'agrégation dynamique de données, inspiré d'une technologie de Databricks. Bien que la courbe Hallway soit également utilisée en interne, nous avons implémenté des algorithmes de tri « l'ordre » et « l'ordre incrémentiel » par-dessus, en les fusionnant pour former un cluster dynamique. Cette innovation peut agréger dynamiquement les données après la saisie des données pour améliorer l'efficacité des requêtes. Par rapport à la courbe Hallway, l'algorithme « ordre » est plus efficace, mais la courbe Hallway est supérieure en termes de changements en temps réel. Cette intégration nous offre un moyen plus flexible et plus efficace d'interroger et d'agréger les données.
Gestion des données non structurées
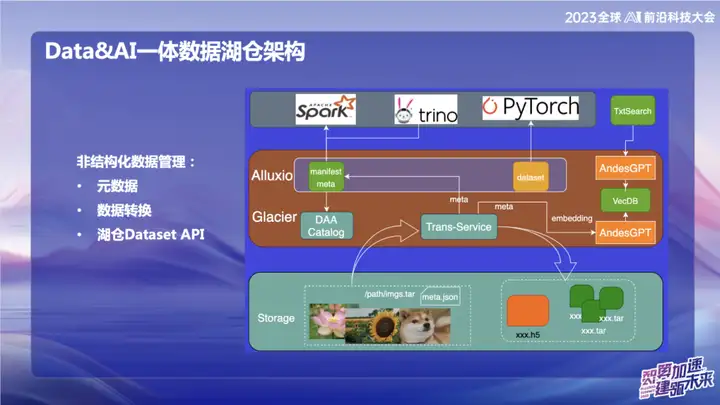
L'image ci-dessus montre certains de nos travaux dans le domaine des données non structurées, principalement liés au domaine de l'IA. Au sein d'OPPO, les outils utilisés pour la formation à l'IA au début sont relativement anciens. Les données sont généralement lues directement via des scripts, ou les données sont stockées sur un stockage objet sous la forme de fichiers txt nus ou de fichiers image nus. Avec le service de transfert, nous pouvons importer automatiquement des données dans le lac de données et découper les données d'image packagées au format d'ensemble de mise à jour. Dans le domaine de l'IA, notamment dans le domaine du traitement d'images, l'ensemble de mise à jour est une interface d'ensemble de données efficace. Il est non seulement compatible avec les interfaces d'ensemble de données Web, mais peut également être converti au format H5.
Notre objectif est de rendre la gestion des données non structurées aussi pratique que les données structurées en traitant les métadonnées. Pendant le processus de conversion des données, les métadonnées des données non structurées sont écrites dans le catalogue. Dans le même temps, nous avons combiné avec le grand modèle et écrit certaines informations sur les métadonnées dans la base de données vectorielles pour faciliter l'interrogation des données dans l'entrepôt du lac à l'aide du grand modèle ou du langage naturel. Le but de ce travail d'intégration est d'améliorer l'efficacité de la gestion des données non structurées et de la rendre plus cohérente avec la gestion des données structurées.
Données non structurées – Exemple de gestion des métadonnées
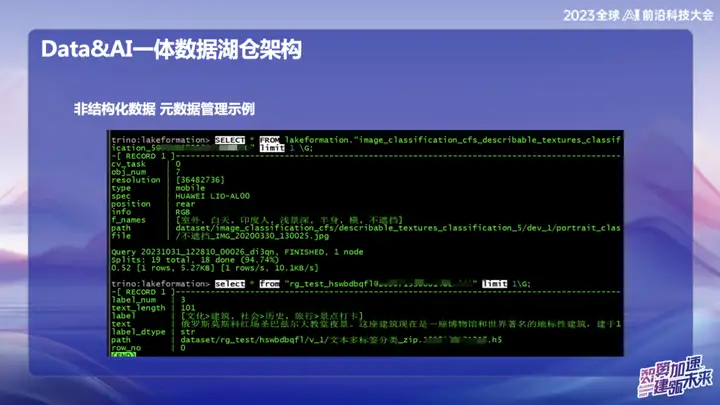
L'image ci-dessus est un exemple de gestion de données non structurées d'OPPO, qui peut rechercher l'emplacement du texte et des images comme SQL.
Invite de données
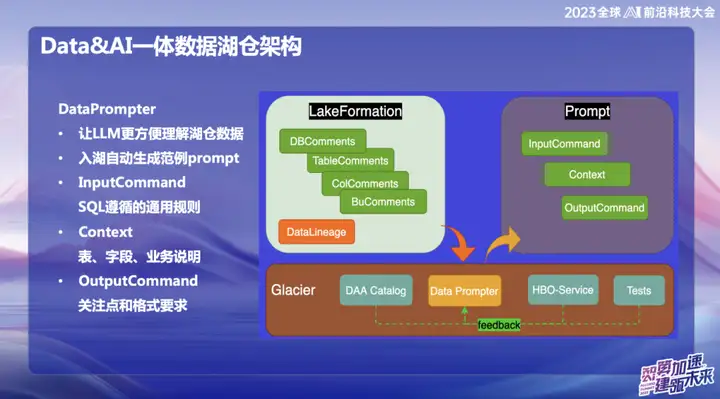
L'intention initiale du choix de créer DataPrompter découle de la recherche d'une meilleure utilisation des grands modèles. OPPO s'engage dans le domaine de la combinaison de données avec de grands modèles et a lancé un produit appelé Data Chart Grâce à un logiciel de chat interne, les utilisateurs peuvent facilement interroger toutes les données. Par exemple, les utilisateurs peuvent facilement vérifier le volume des ventes de téléphones mobiles hier, ou comparer la différence de ventes avec les ventes de téléphones mobiles Xiaomi et effectuer une analyse des données en langage naturel.
Au cours du processus de création du produit, les tableaux de données de chaque champ nécessitent que le personnel professionnel de l'entreprise saisisse l'invite. Cela pose des défis pour la promotion de l'ensemble de l'entrepôt ou du produit du lac de données, car l'invite de chaque table prend beaucoup de temps. Par exemple, si vous souhaitez saisir des données de tableau financier, vous devez remplir en détail des informations professionnelles et techniques telles que les champs du tableau, la signification du domaine d'activité et les tableaux de dimensions développés.
Notre objectif ultime est de permettre au grand modèle de comprendre facilement les données de niveau supérieur une fois que les données entrent dans l'entrepôt du lac. Au cours du processus d'entrée des données dans le lac, l'entreprise doit afficher certaines informations prescrites, combinées à notre expérience accumulée dans Data Prompter, et utiliser certaines requêtes courantes fournies par le service HBO pour enfin générer un modèle de prompteur qui rend le grand modèle facile à comprendre. . Cette combinaison vise à permettre au modèle de mieux comprendre les données commerciales et à rendre plus fluide l'intégration de Hucang et des grands modèles.
Alluxio aide à entrer dans le lac en temps réel en quelques secondes
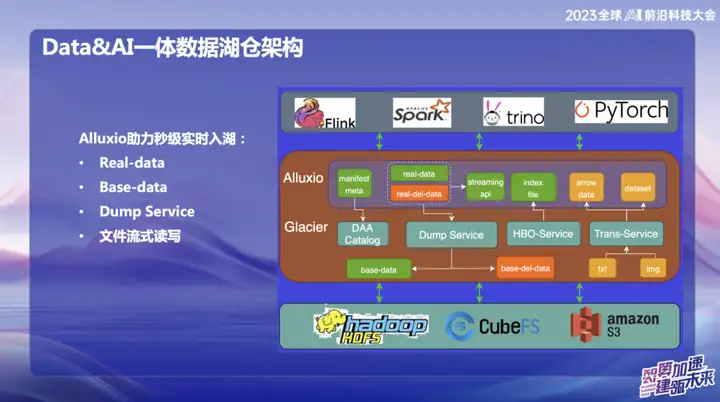
Alluxio aide à entrer dans le lac en temps réel en quelques secondes, qui se divise principalement en :
1、Données réelles
2、Données de base
3、Service de vidage
4. Lecture et écriture de fichiers en streaming
La pratique d'Alluxio dans l'architecture Hucang
Alluxio combiné avec Spark RSS
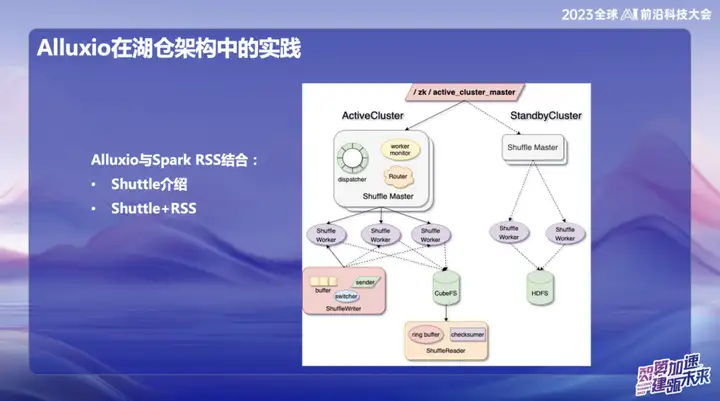
Nous avons initialement choisi de combiner Alluxio avec le service Spark RSS via le service Spark Shuttle auto-développé et de l'ouvrir en source au nom de Shuttle. Initialement, notre base sous-jacente était basée sur un système de fichiers distribué, mais nous avons ensuite rencontré des problèmes de performances, nous avons donc trouvé Alluxio.
La combinaison parfaite de Shuttle et d'Alluxio a considérablement amélioré les performances de l'ensemble du service Shuttle, les doublant pratiquement. Grâce à cette optimisation, nous avons réussi à réduire la pression du système d'environ la moitié et à doubler directement le débit. Cette combinaison résout non seulement le problème de performances, mais injecte également une nouvelle vitalité dans notre système de service.
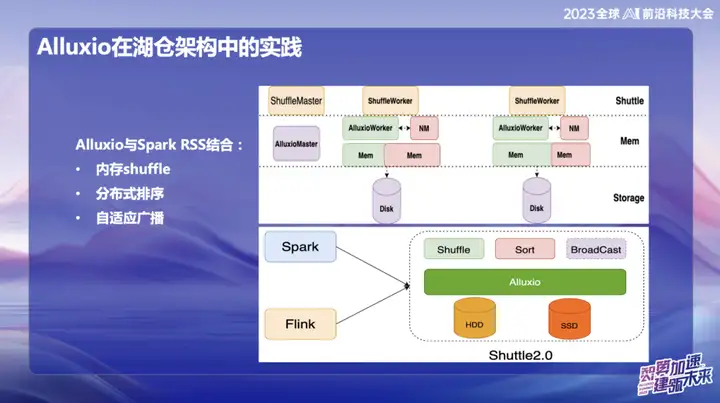
Dans les recherches et développements ultérieurs d'OPPO, le cadre basé sur Alluxio+Shuttle a réalisé davantage d'innovations. Nous optimisons à la fois l'opérateur de la navette et l'opérateur de diffusion au niveau des données en mémoire. Grâce à une interaction efficace des données en mémoire, en particulier lors du traitement d'un point unique, lorsque les données sont asymétriques, l'opération de tri qui prenait initialement jusqu'à 50 minutes peut être migrée. Après l’adoption de la nouvelle solution, le temps de traitement a été réduit à moins de 10 minutes. Cette optimisation améliore non seulement considérablement l'efficacité du traitement, mais atténue également efficacement l'impact de la distorsion des données sur les performances du système.
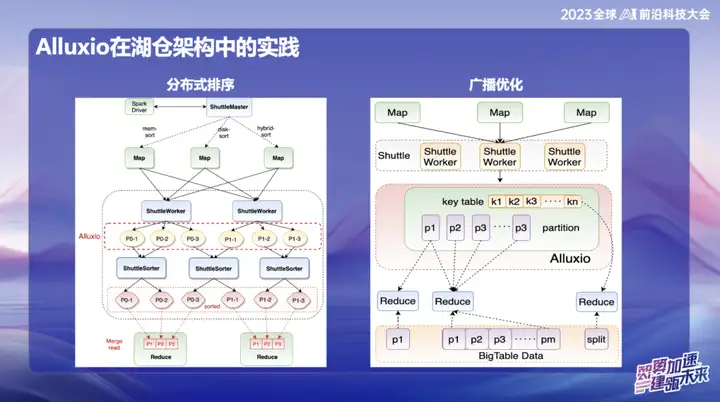
Les résultats de diffusion sont très significatifs, en particulier dans Spark. La taille de diffusion par défaut est de 10 Mo. Étant donné que toutes les données de diffusion doivent être stockées côté Java, elles sont sujettes à une expansion après la sérialisation Java, ce qui entraîne des problèmes de MOO (mémoire insuffisante). . Cela arrive souvent dans les environnements en ligne.
Pour résoudre ce problème, nous stockons actuellement les données de diffusion dans Alluxio. Cela permet de diffuser presque n'importe quelle taille de données, jusqu'à 10 gigaoctets. Cette innovation a été mise en œuvre avec succès dans plusieurs cas en ligne chez OPPO et a eu un impact significatif sur l'amélioration de l'efficacité.
Pratique applicative Alluxio sur cloud public/cloud hybride
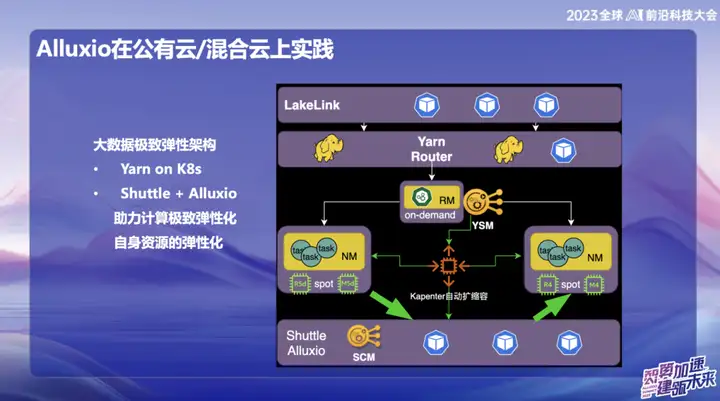
Dans le système Big Data de cloud public d'OPPO, en particulier à Singapour, nous utilisons principalement AWS comme infrastructure. Au début, nous avons utilisé le service de calcul élastique (EMR) fourni par AWS. Cependant, ces dernières années, la situation économique globale du secteur a été moins optimiste et de nombreuses entreprises cherchent à réduire leurs coûts et à améliorer leur efficacité. Face à cette tendance, nous avons proposé des solutions auto-développées dans le domaine du cloud public outre-mer, utilisant les ressources élastiques du cloud pour construire une nouvelle architecture. Le cœur de cette solution innovante repose sur la combinaison Alluxio+Shuttle, qui fournit un support clé pour notre système Big Data.

L'avantage significatif de la solution Alluxio+Shuttle est que le cluster Alluxio n'est pas exclusif à Shuttle et peut prendre en charge d'autres services, notamment la mise en cache des données et la mise en cache des métadonnées. Dans le cloud public, nous savons que les opérations de liste sur S3 prennent beaucoup de temps lors de la soumission. En combinant Alluxio et les solutions open source Magic commit et Shuttle, nous avons obtenu des effets de réduction de coûts significatifs, réduisant les coûts informatiques d'environ 80 %. .
Dans un environnement cloud hybride, nous fournissons des services aux équipes IA. Puisqu'il y a un stockage d'objets au fond du lac de données, nous avons utilisé la carte GPU sur Alibaba Cloud pendant le processus de formation et l'avons également combinée avec des ressources GPU auto-construites. En raison de la bande passante limitée et du coût élevé des lignes dédiées, une couche de cache efficace est requise pour la copie des données. Initialement, nous avons adopté une solution fournie par l'équipe de stockage, mais son évolutivité et ses performances n'étaient pas idéales. Après avoir introduit Alluxio, nous avons obtenu plusieurs fois l'accélération des E/S dans plusieurs scénarios, offrant ainsi une prise en charge plus efficace du traitement des données.
Perspectives

L'échelle du cluster d'OPPO a atteint des dizaines de milliers d'unités en Chine, formant une échelle assez grande. Nous prévoyons d'approfondir les ressources mémoire à l'avenir pour utiliser davantage l'espace de stockage interne. L'équipe dispose à la fois du cadre informatique en temps réel Flink et du cadre de traitement hors ligne Spark. Les deux peuvent apprendre de leur expérience respective en matière d'application d'Alluxio pour réaliser un développement intégré en profondeur d'Alluxio et du lac de données.
Dans la vague de combinaison du big data et du machine learning, nous suivons les tendances du secteur. Intégrez profondément l'architecture de données avec l'intelligence artificielle (IA) depuis le bas pour fournir des services de haute qualité pour l'IA comme priorité absolue. Cette intégration n'est pas seulement une avancée technologique, mais aussi un plan stratégique pour le développement futur.
Enfin, nous explorerons plus en détail les avantages d'Alluxio pour nous aider à réduire les coûts dans les environnements de cloud public. Cela implique non seulement une optimisation technique, mais également une gestion plus efficace des ressources de cloud computing, apportant un soutien solide au développement durable de l'entreprise.
Les ressources piratées de "Qing Yu Nian 2" ont été téléchargées sur npm, obligeant npmmirror à suspendre le service unpkg. Zhou Hongyi : Il ne reste plus beaucoup de temps à Google. Je suggère que tous les produits soient open source. time.sleep(6) joue ici un rôle. Linus est le plus actif dans la « consommation de nourriture pour chiens » ! Le nouvel iPad Pro utilise 12 Go de puces mémoire, mais prétend disposer de 8 Go de mémoire. Le People's Daily Online examine la charge de type matriochka des logiciels de bureau : Ce n'est qu'en résolvant activement « l'ensemble » que nous pourrons avoir un avenir avec Flutter 3.22 et Dart 3.4 . nouveau paradigme de développement pour Vue3, sans avoir besoin de « ref/reactive », pas besoin de « ref.value » Publication du manuel chinois MySQL 8.4 LTS : vous aider à maîtriser le nouveau domaine de la gestion de bases de données Tongyi Qianwen niveau GPT-4 prix du modèle principal réduit de 97%, 1 yuan et 2 millions de jetons