
01 배경 한 눈에 보기
시계열 데이터가 데이터베이스에 기록되는 시나리오에서는 네트워크 지연 등의 문제로 인해 기록되는 데이터의 타임스탬프가 기록되는 데이터의 최대 타임스탬프보다 작은 경우가 발생할 수 있습니다. 데이터를 집합적으로 순서가 잘못된 데이터라고 합니다. 비순차적 데이터의 생성은 거의 불가피합니다. 동시에 비순차적 데이터 작성은 모든 데이터의 정렬 및 쿼리에 영향을 미치므로 비순차적 데이터 작성을 지원해야 합니다. 데이터를 주문하고 효율적인 데이터 쿼리도 지원합니다.
02 프로세스 개요
비순차적 데이터 처리 시 지정된 시간 범위(10분, 1시간 등) 내의 비순차적 데이터는 중복제거 전략에 따라 처리되어 저장되며, 그 시간 외의 비순차적 데이터는 창이 삭제됩니다. 다음 그림은 비순차적 데이터를 쓰는 기본 프로세스입니다.

그 중에서 3가지 핵심 사항을 명확히 해야 합니다.
- 시간 창은 테이블의 최신 데이터 타임스탬프 시점 이전의 기간을 나타냅니다. 테이블에 새 데이터가 기록되지 않으면 해당 시간 창은 변경되지 않습니다.
- 구성 파일에는 ts_st_iot_disorder_interval 매개변수가 있습니다. 이는 잘못된 데이터 쓰기를 위한 시간 창(단위: 초)을 지원하는 데 사용됩니다. 이 구성 항목의 값은 파티션 간격 값을 초과할 수 없습니다.
- 데이터의 이상 여부를 판단하는 기준은 작성된 데이터의 타임스탬프가 작성된 테이블 객체에 저장된 모든 데이터의 최대 타임스탬프보다 작거나 같다는 것입니다.
03 시나리오 예시
1. 일반적인 쓰기 과정
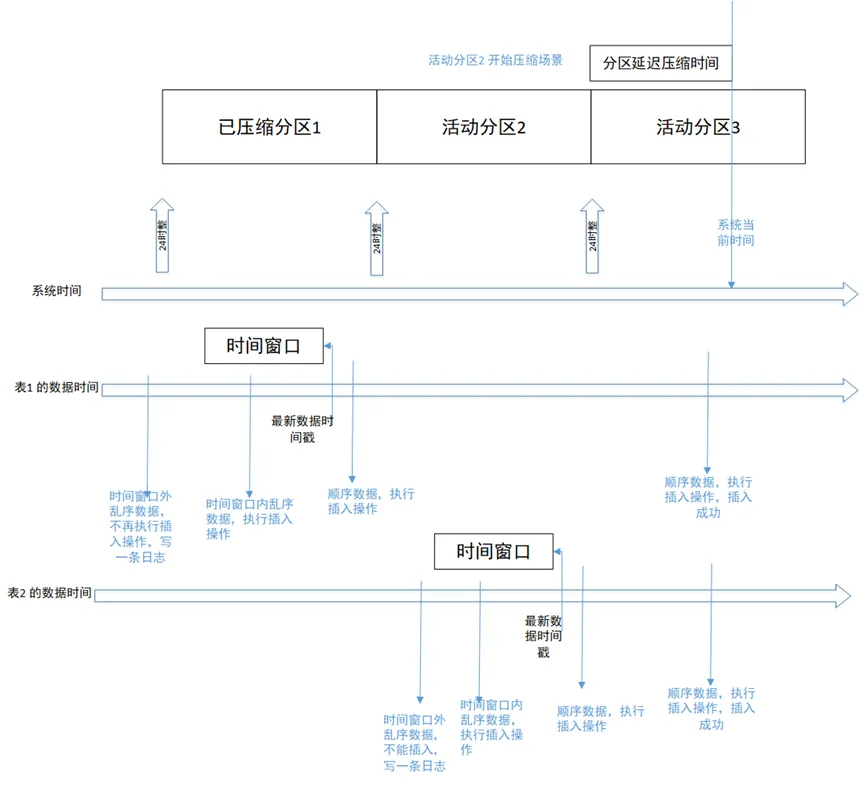
시간은 시스템 시간과 데이터 시간의 두 줄로 구분됩니다. 테이블마다 데이터 시간이 다르기 때문에 표 1의 데이터 시간과 표 2의 데이터 시간, 두 줄로 나누어진다.
-
시나리오 1: 이틀 전 데이터를 순차적으로 쓰는 시나리오는 위 그림과 같습니다. 표 1의 시나리오는 기록 파티션 1에 순차적으로 기록됩니다. 기록된 순차적 데이터는 해당 파티션에 저장됩니다. 파티션이 실패하고 잘못 발생합니다.
-
시나리오 2: 시간 창 내에서 순서가 잘못된 데이터 쓰기 위 그림과 같이 표 2는 시간 창 내에서 순서가 잘못된 데이터를 씁니다. 작성된 데이터는 처리 중인 활성 파티션 2에 저장됩니다. 다른 스레드에서는 파티션 압축을 수행하면 쓰기 작업도 성공합니다.
-
시나리오 3: 시간 창을 초과하는 비순차적 데이터 쓰기 데이터베이스가 압축 기능을 켜고 비순차적 시간 창을 1시간으로 구성한 경우 1시간 전의 비순차적 데이터를 씁니다. 테이블의 최신 레코드 타임스탬프보다 실패합니다. 기록된 데이터는 필터링되어 로그에 기록됩니다.
2. 데이터 가져오기 프로세스
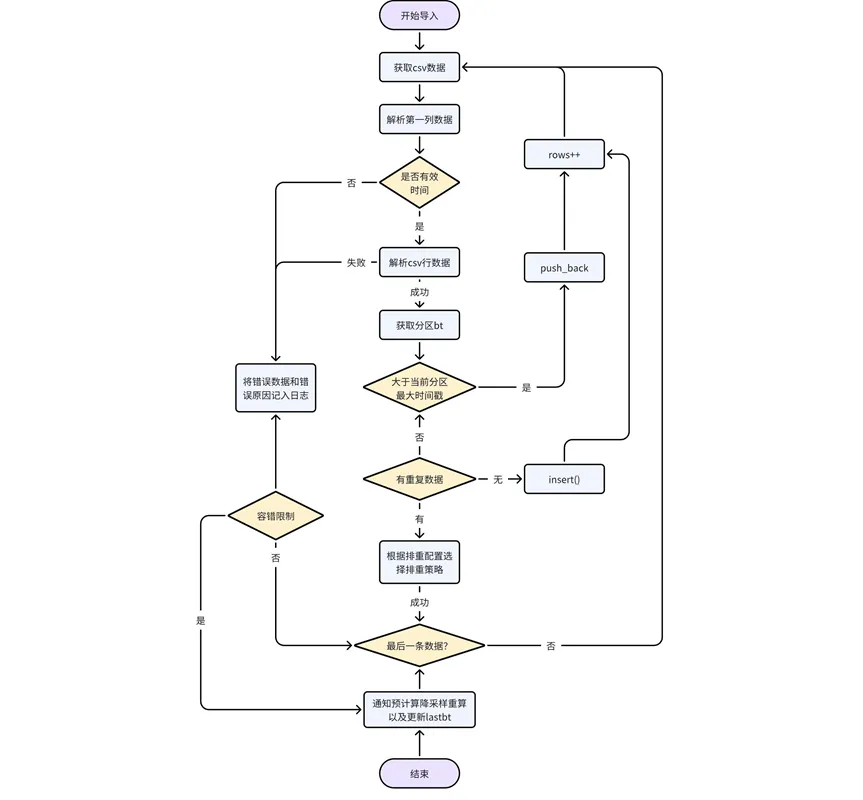
가져온 데이터에 잘못된 데이터가 있을 수도 있습니다. 이 시나리오에서 잘못된 데이터 처리는 일반적인 쓰기 프로세스와 일치합니다.
-
데이터 자체 처리: CSV 파일의 데이터를 한 줄씩 구문 분석하고, 데이터의 첫 번째 열이 유효한 시간/타임스탬프 유형인지 확인하고, 그렇지 않은 경우 오류를 반환하고, 파티션을 결정합니다. 데이터가 속한 파티션 bt를 얻습니다. 데이터 타임스탬프가 현재 파티션에 있는 기존 데이터의 최대 타임스탬프보다 크면 직접 푸시백하세요. 그렇지 않으면 순서가 잘못된 데이터를 중복 제거 구성 논리에 따라 처리해야 합니다.
-
다운샘플링 및 사전 계산 논리 적용: 데이터를 가져오는 과정에서 kaiwudb_jobs 시스템 작업 테이블에 있는 url의 레코드 상태를 만료되도록 업데이트해야 합니다. 가져오기가 완료된 후 사전 계산/다운샘플링을 알리고, 관련된 데이터를 다시 계산/처리해야 합니다. 다음 단계를 기다립니다. 사전 계산 작업은 시스템에 의해 예약될 때 다시 계산됩니다.
가져오기가 완료된 후 사전 계산 및 다운샘플링에 알림이 전달되어 결과를 다시 계산하거나 업데이트하고 lastbt를 업데이트합니다.
3. 다운샘플링 프로세스
비순차적 데이터가 기록된 후에는 최신 데이터를 기반으로 다운샘플링 결과를 업데이트해야 합니다.

-
기록 파티션으로 가져온 잘못된 데이터 처리: 기록 파티션에 속한 잘못된 데이터를 가져올 때 kaiwudb_jobs 시스템 작업 테이블에서 url=[database/partition/table_name]의 레코드 상태를 만료로 업데이트하고, 그러면 샘플링 규칙 처리에 따라 파티션 테이블이 다시 다운로드됩니다.
-
기록 파티션 데이터 삽입 및 쓰기 처리: 삽입 데이터 테이블의 기록 파티션 압축을 풀 때 kaiwudb_jobs 시스템 작업 테이블의 url=[database/partition/table_name] 레코드 상태를 만료로 업데이트하면 파티션 테이블이 다시 생성됩니다. 향후에는 다운샘플링 규칙을 처리합니다.
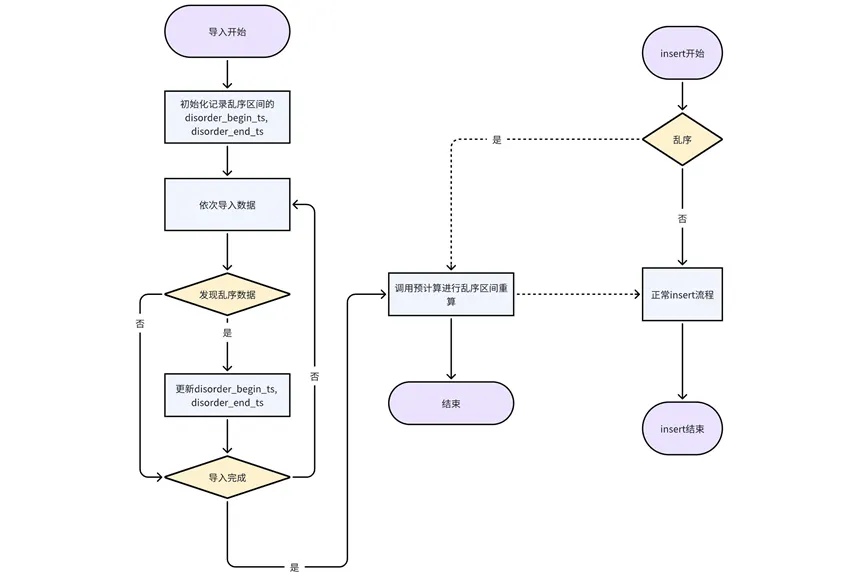
4. 사전 계산 과정에서 잘못된 데이터를 작성한 후 최신 데이터를 기반으로 사전 계산 결과를 업데이트해야 합니다.
-
잘못된 데이터 삽입 및 쓰기: 잘못된 데이터 조각이 삽입에 나타날 때마다 삽입합니다. 이 접근 방식은 사전 계산 결과의 정확성을 더 크게 보장할 수 있습니다.
-
가져온 비순차적 데이터 처리: 현재 파티션 테이블 단위로 가져오기가 처리되고 있으며, 각 파티션 테이블의 가져오기 과정에서 현재 가져오기 후 비순차적 시작 타임스탬프와 종료 타임스탬프가 기록됩니다. 파티션 테이블이 완성되면 재계산을 위해 사전 계산 인터페이스가 호출됩니다.
04 요약
비순차적 데이터 처리 시나리오에는 동기화 및 업데이트가 필요한 많은 기능과 연결 모듈이 관련되어 있습니다. 데이터베이스에 완전한 비순차적 데이터 처리가 포함되면 사용자 비즈니스 시나리오에 더 잘 적응할 수 있으며 여러 시나리오에서 데이터베이스의 적용 가능성이 크게 향상됩니다.
오픈 소스 산업용 소프트웨어를 포기하기로 결정했습니다 . 주요 이벤트 - OGG 1.0 출시, Huawei가 모든 소스 코드를 제공했습니다. Google Python Foundation 팀이 "코드 똥산"에 의해 해고되었습니다 . ". Fedora Linux 40이 정식 출시되었습니다. 유명 게임 회사가 출시했습니다. 새로운 규정: 직원의 결혼 선물은 100,000위안을 초과할 수 없습니다. China Unicom은 세계 최초로 오픈 소스 모델의 Llama3 8B 중국어 버전을 출시했습니다. Pinduoduo는 보상금을 선고 받았습니다 . 불공정 경쟁에 500만 위안 국내 클라우드 입력 방식 - 화웨이만 클라우드 데이터 업로드 보안 문제 없음