
누구나 GitHub에 별표를 표시할 수 있습니다.
분산형 풀링크 인과 학습 시스템 OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
대규모 모델 기반 지식 그래프 OpenSPG: https://github.com/OpenSPG/openspg
대규모 그래프 학습 시스템 OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
5년도 채 되지 않아 대형 모델과 Transformers 기술은 자연어 처리 분야를 거의 완전히 변화시켰으며 컴퓨터 비전 및 컴퓨터 생물학과 같은 분야에 혁명을 일으키기 시작했습니다. Sebastian Raschka 박사는 학술 연구 논문에 중점을 두고 기계 학습 연구자 및 실무자를 위한 입문 독서 목록을 준비했습니다. 순서대로 읽으면 대형 모델 기술이라는 현재 분야를 실제로 시작할 수 있습니다.
물론 Sebastian Raschka 박사는 다음과 같은 다른 유용한 리소스도 많이 언급했습니다.
- Jay Alammar의 《일러스트레이티드 트랜스포머》;
- Lilian Weng의 추가 기술 블로그 게시물
- Xavier Amatriain이 정리한 Transformers의 모든 카탈로그 및 계보;
- Andrej Karpathy가 교육 목적으로 작성한 생성 언어 모델의 최소 코드 구현입니다.
- 이 기사의 저자가 쓴 강의 시리즈와 책 장도 있습니다.
주요 아키텍처 및 작업 이해
Transformers/대형 모델을 처음 사용하는 경우 처음부터 시작하는 것이 가장 합리적입니다.
1. 정렬 및 번역을 위한 공동 학습을 통한 신경 기계 번역(2014)
저자: Bahdanau, Cho Wa Bengio
논문 링크: https://arxiv.org/abs/1409.0473
몇 분의 여유가 있다면 이 문서부터 시작하는 것이 좋습니다. 본 논문에서는 긴 시퀀스의 모델링 기능을 향상시키기 위해 순환 신경망(RNN)에 주의 메커니즘을 소개합니다. 이를 통해 RNN은 긴 문장을 더 정확하게 번역할 수 있습니다. 이는 원래 Transformer 아키텍처 개발의 동기였습니다.
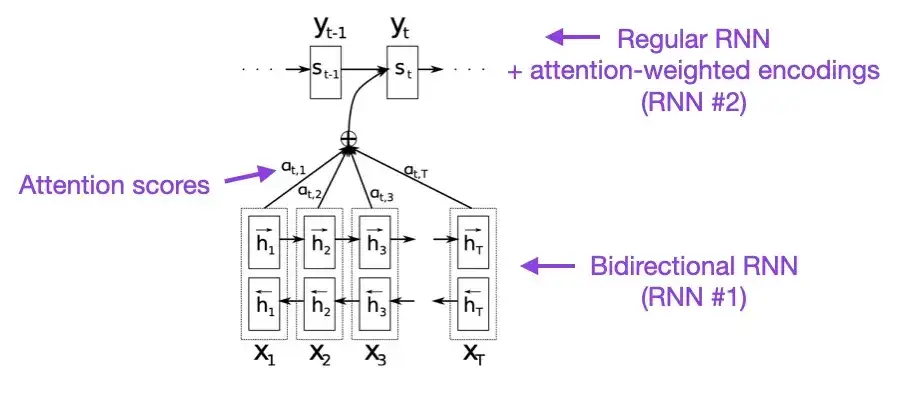
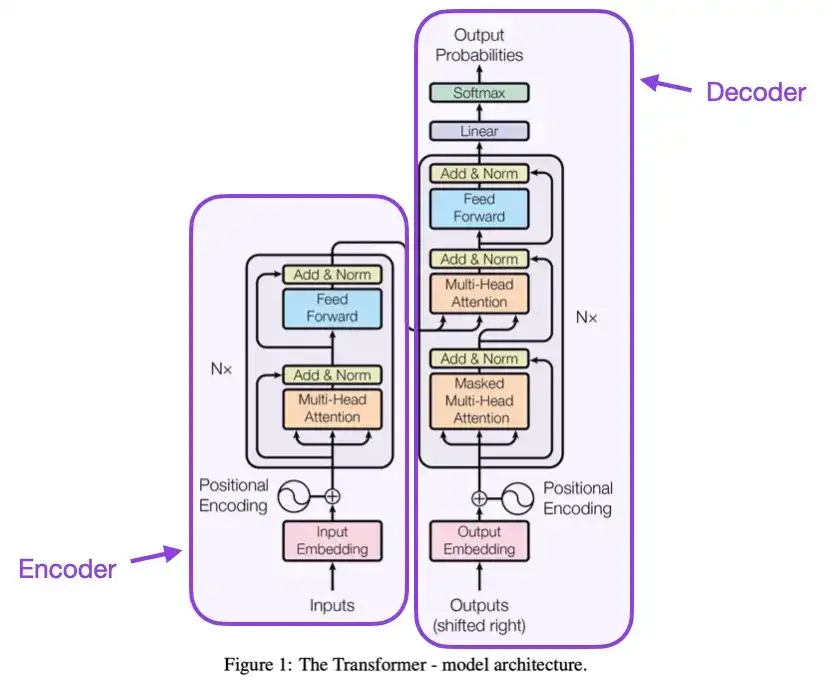
2. 관심만 있으면 된다 (2017)
크레딧: Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser 및 Polosukhin
논문 링크: https://arxiv.org/abs/1706.03762
이 문서에서는 인코더와 디코더라는 두 부분으로 구성된 원래 Transformer 아키텍처를 소개합니다. 이 두 부분은 나중에 설명을 위해 독립적인 모듈이 됩니다. 또한 이 논문에서는 여전히 현대 Transformer 모델의 기초가 되는 스케일링 내적 주의 메커니즘, 다중 헤드 주의 블록, 위치 입력 인코딩과 같은 개념도 소개했습니다.
3. 트랜스포머 아키텍처의 레이어 정규화에 대하여 __ (2020)
저자: Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
논문 링크: https://arxiv.org/abs/2002.04745
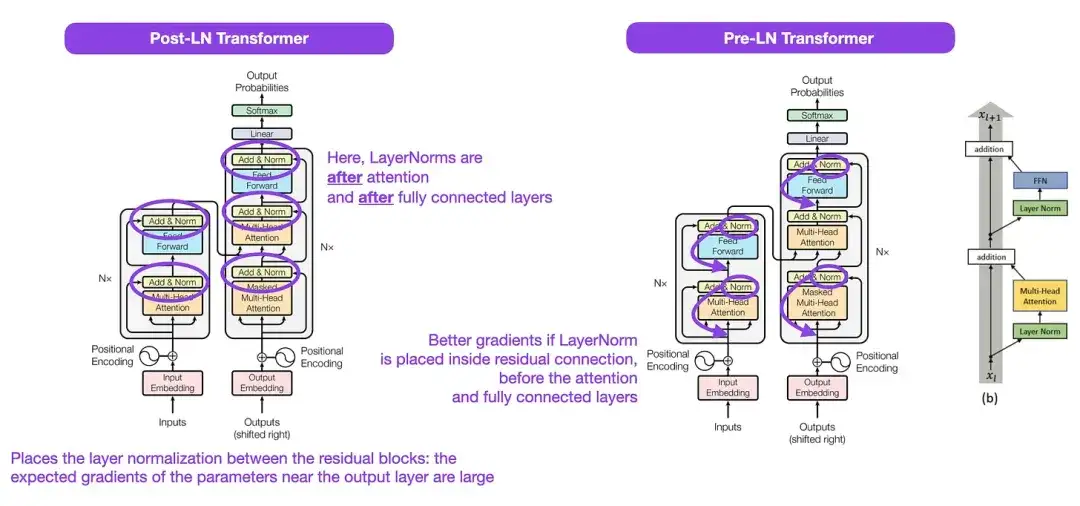
위 그림에 표시된 원래 Transformer 구조는 원래 인코더-디코더 아키텍처를 매우 잘 요약한 것이지만 그림에서 LayerNorm의 위치는 논란의 여지가 있었습니다. 예를 들어, "Attention Is All You Need"의 Transformer 구조 다이어그램은 원본 Transformer 문서와 함께 제공되는 공식(업데이트된) 코드 구현과 일치하지 않는 잔여 블록 사이에 LayerNorm을 배치합니다. "Attention Is All You Need" 그림에 표시된 변형은 Post-LN Transformer라고 하며, 업데이트된 코드 구현에서는 기본적으로 Pre-LN 변형을 사용합니다.
"변환기 아키텍처의 레이어 정규화" 기사에서는 Pre-LN이 더 잘 작동하고 그래디언트 문제를 해결할 수 있다고 지적했습니다. 아래에 표시된 것처럼 많은 아키텍처가 실제로 이 접근 방식을 채택하지만 표현 붕괴로 이어질 수 있습니다. 따라서 Post-LN을 사용할지 Pre-LN을 사용할지에 대한 논의가 계속되는 동안 새로운 논문 "ResiDual: Transformer with Dual Residual Connections"( https://arxiv.org/abs/2304.14802 )에서는 두 가지 장점을 모두 활용할 것을 제안합니다. 실제로 그 효과는 아직 밝혀지지 않았습니다.
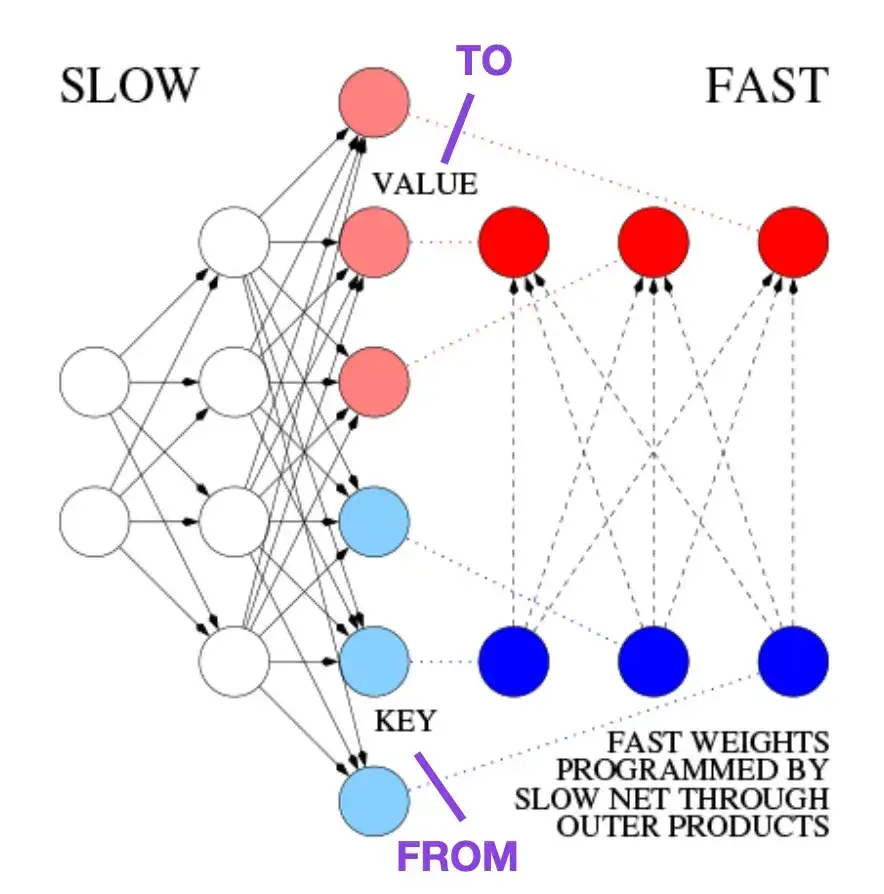
4. 빠른 가중치 기억 제어 학습: 동적 순환 신경망의 대안 __ (1991)
저자: 슈미트후버
논문 링크:
이 문서는 현대 Transformer 아키텍처와 유사한 역사적 일화 및 초기 기술에 관심이 있는 독자에게 권장됩니다. 예를 들어, 원래 Transformer 논문 Attention Is All You Need가 나오기 약 25년 전인 1991년에 Juergen Schmidhuber는 순환 신경망의 대안으로 FWP(Fast Weight Programmer)를 제안했습니다. FWP 방법에는 다른 신경망의 빠른 가중치 변화를 프로그래밍하기 위해 경사하강법을 통해 천천히 학습하는 피드포워드 신경망이 포함됩니다. 다음 블로그 게시물에서는 최신 Transformer에 대한 비유를 설명합니다.
오늘날의 Transformer 용어에서는 FROM과 TO를 각각 키와 값이라고 부릅니다. 빠른 네트워크에서 사용되는 INPUT을 쿼리라고 합니다. 기본적으로 쿼리는 키와 값의 외부 곱의 합인 빠른 가중치 행렬을 통해 처리됩니다(정규화 및 투영 무시). 두 네트워크의 모든 작업은 미분 가능하므로 외부 곱 또는 2차 텐서 곱을 추가하여 빠른 가중치 변화에 대한 엔드투엔드 미분 가능 능동 제어를 얻습니다. 따라서 느린 네트워크는 경사하강법을 통해 학습할 수 있으며 시퀀스 처리 중에 빠른 네트워크를 빠르게 수정할 수 있습니다. 이는 선형 셀프 어텐션 변환기(또는 선형 변환기)로 알려진 것과 수학적으로 동일합니다(정규화 제외).
위의 블로그 게시물에서 발췌한 것처럼 이 접근 방식은 이제 "선형 변환기" 또는 "선형화된 self-attention을 갖춘 변환기"로 알려져 있습니다. 그 후, 선형화된 self-attention과 1990년대의 빠른 웨이트 프로그래머 사이의 동등성은 2021년 논문 "Linear Transformers Are Secretly Fast Weight Programmers"에서 명확하게 입증되었습니다.
5. 텍스트 분류를 위한 범용 언어 모델 미세 조정 (2018)
저자 하워드, 루더
논문 주소: https://arxiv.org/abs/1801.06146
역사적 관점에서 볼 때 매우 흥미로운 기사입니다. "Attention Is All You Need"가 출시된 지 1년 후에 작성되었지만 Transformer는 포함되지 않고 순환 신경망에 중점을 두었습니다. 그러나 다운스트림 작업을 위해 사전 훈련된 언어 모델과 전이 학습을 효과적으로 제안한다는 점에서 여전히 주목할 만합니다. 전이 학습은 컴퓨터 비전 분야에서 잘 확립되어 있지만 자연어 처리(NLP)에서는 아직 대중화되지 않았습니다. ULMFit은 사전 훈련된 언어 모델을 시연하고 이를 특정 작업에 맞게 미세 조정하여 많은 NLP 작업에서 최첨단 결과를 가져온 최초의 논문 중 하나입니다.
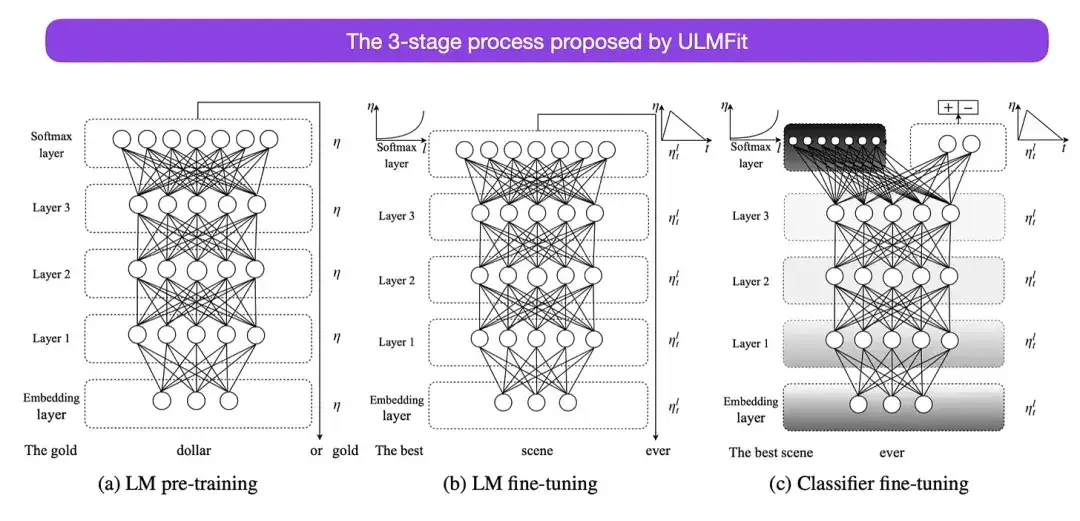
ULMFit이 제안한 언어 모델 미세 조정의 3단계 프로세스는 다음과 같습니다.
- 큰 텍스트 코퍼스에서 언어 모델을 훈련합니다.
- 특정 텍스트의 스타일과 어휘에 맞게 작업별 데이터에 대해 사전 훈련된 언어 모델을 미세 조정합니다.
- 작업별 데이터에 대한 분류기를 미세 조정하는 동시에 레이어 고정을 점진적으로 해제하여 치명적인 망각을 방지합니다.
먼저 대규모 코퍼스에서 언어 모델을 학습시킨 후 다운스트림 작업으로 미세 조정하는 이 방법은 Transformer 기반 모델 및 기본 모델(BERT, GPT-2/3/4, RoBERTa 등)의 핵심 방법입니다. 등.). 그러나 ULMFit의 핵심 부분인 점진적 동결 해제는 일반적으로 변환기 아키텍처를 실제로 작동할 때 일상적으로 수행되지 않으며 일반적으로 모든 레이어가 한 번에 미세 조정됩니다.
6. BERT: 언어 이해를 위한 심층 양방향 변환기 사전 훈련 ****(2018)
작곡: Devlin, Chang, Lee, Toutanova
논문 링크: https://arxiv.org/abs/1810.04805
원래 Transformer 아키텍처에 따르면 대규모 언어 모델에 대한 연구는 예측 모델링 작업(예: 텍스트 분류)을 위한 인코더 기반 Transformer와 생성적 모델링 작업(예: 번역, 요약 및 A 디코더)이라는 두 가지 방향으로 갈라지기 시작했습니다. 다른 텍스트 생성 양식의 경우 스타일 변환기).
앞서 언급한 BERT 논문은 마스크된 언어 모델링과 다음 문장 예측의 원래 개념을 소개했으며 여전히 가장 영향력 있는 인코더 스타일 아키텍처로 남아 있습니다. 이 연구 분야에 관심이 있다면 다음 문장 예측 작업을 제거하여 사전 학습 목표를 단순화하는 RoBERTa에 대해 계속 학습하는 것이 좋습니다.
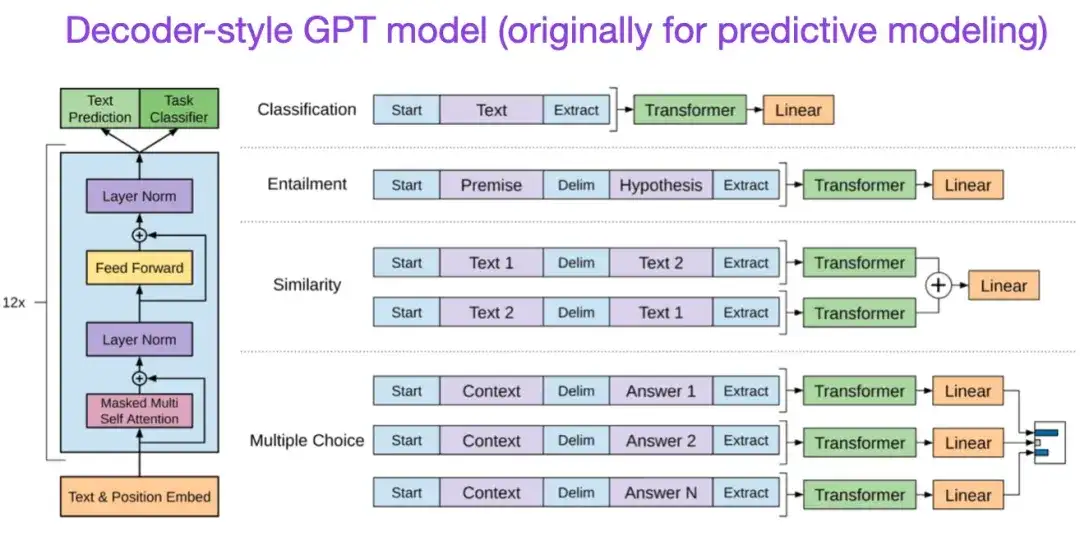
** 7. 생성적 사전 훈련을 통한 언어 이해 개선 (2018)** 저자: Radford 및 Narasimhan 논문 주소:
원본 GPT 논문에서는 널리 사용되는 디코더 스타일 아키텍처와 다음 단어 예측을 통한 사전 학습을 소개했습니다. BERT는 마스크된 언어 모델 사전 학습 목표로 인해 양방향 변환기로 볼 수 있는 반면, GPT는 단방향 자동 회귀 모델입니다. GPT 임베딩을 분류에 사용할 수도 있지만 GPT 방법은 ChatGPT와 같은 오늘날 가장 영향력 있는 LLM(대형 언어 모델)의 핵심입니다.
본 연구 방향에 관심이 있으시면 GPT-2 및 GPT-3 관련 논문에 대해 계속해서 자세히 알아보시기를 권합니다. 이 두 논문은 LLM이 제로샷 및 퓨샷 학습을 달성할 수 있음을 보여주고 LLM의 새로운 기능을 강조합니다. GPT-3은 현재 LLM 교육을 위해 여전히 가장 일반적으로 사용되는 기준이자 기본 모델입니다. ChatGPT를 탄생시킨 InstructGPT 기술은 나중에 별도의 항목에서 소개됩니다.
GPT3 관련 논문: https://arxiv.org/abs/2005.14165
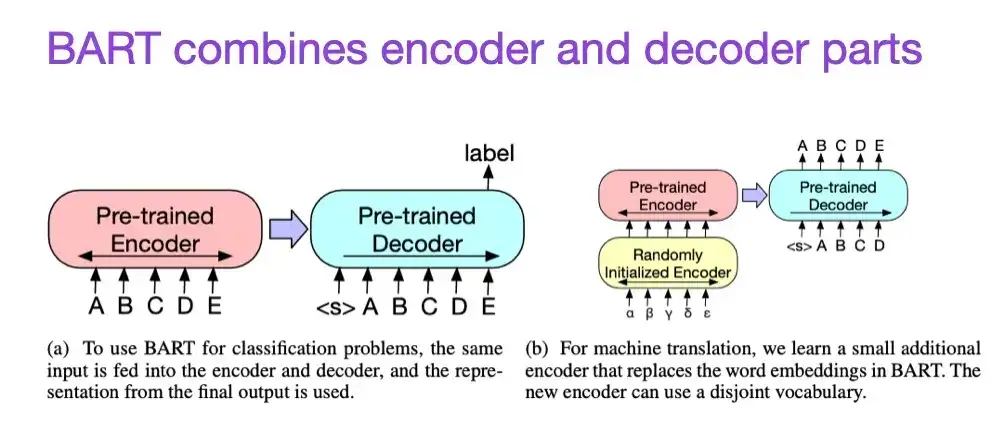
8. BART: 자연어 생성, 번역 및 이해를 위한 시퀀스 간 사전 훈련 (2019)
작곡: Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
논문 링크: https://arxiv.org/abs/1910.13461 .
앞서 언급했듯이 BERT 유형 인코더 스타일 LLM(대형 언어 모델)은 일반적으로 예측 모델링 작업에 더 적합한 반면, GPT 유형 디코더 스타일 LLM은 텍스트 생성에 더 적합합니다. 위에서 언급한 BART 논문은 두 가지 장점을 결합하기 위해 인코더와 디코더 부분을 결합합니다(두 번째 논문에 소개된 원래 Transformer 구조와 유사함).
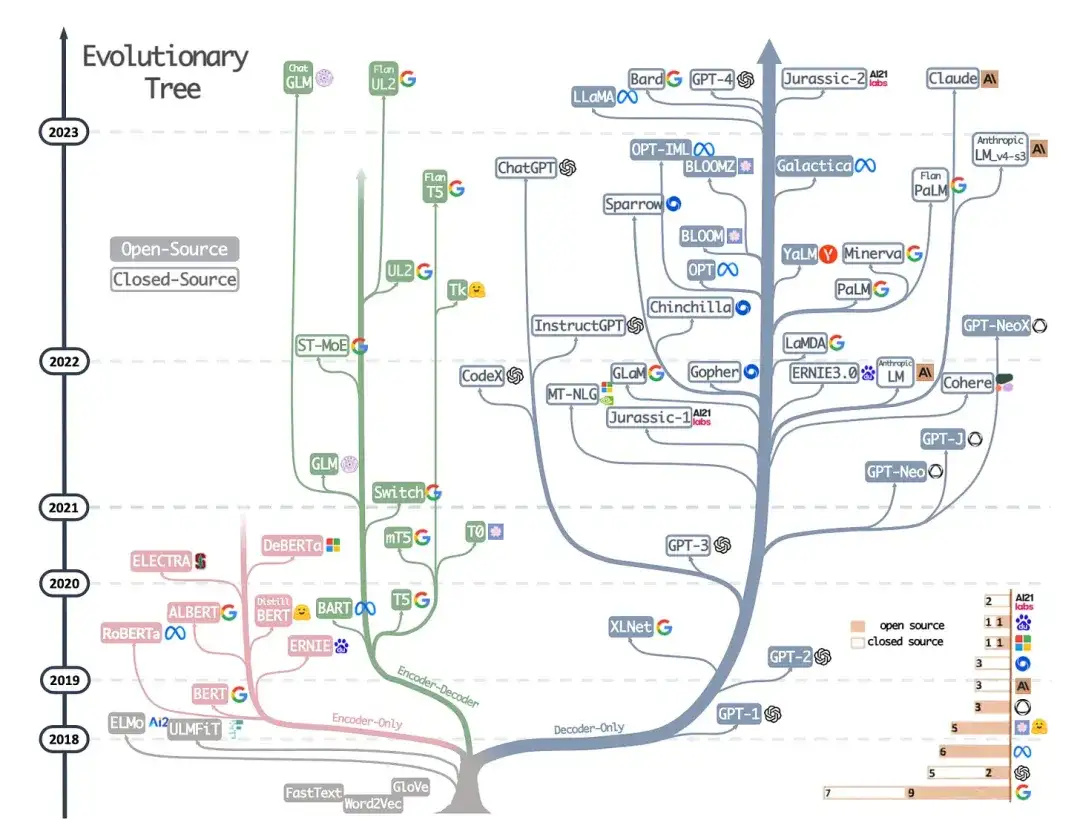
9. 실제로 LLM의 힘 활용: ChatGPT 및 그 이상에 대한 설문조사 (2023)
저자: Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
논문 링크: https://arxiv.org/abs/2304.13712
이것은 연구 논문은 아니지만 아마도 아직까지 최고의 아키텍처 개요 기사일 것이며, 다양한 아키텍처가 어떻게 진화해왔는지 생생하게 보여줍니다. 그러나 BERT 스타일 마스크 언어 모델(인코더) 및 GPT 스타일 자동 회귀 언어 모델(디코더)에 대해 논의하는 것 외에도 사전 학습 및 데이터 미세 조정에 대한 유용한 토론과 지침도 제공합니다.
법률 확장 및 효율성 향상
Transformer 효율성을 향상시키는 다양한 기술에 대해 자세히 알아보려면 2020년 논문 "Efficient Transformers: A Survey"와 2023년 논문 "A Survey on Efficient Training of Transformers"를 읽어 보시기 바랍니다. 추가적으로 제가 특히 흥미롭고 읽을 가치가 있다고 생각하는 몇 가지 논문을 소개합니다.
- 《효율적인 변압기: 설문 조사》:
https://arxiv.org/abs/2009.06732
- 《효율적인 트랜스포머 훈련에 관한 조사》:
https://arxiv.org/abs/2302.01107
10. FlashAttention: IO 인식을 통한 빠르고 메모리 효율적인 정확한 주의 (2022)
저자: Dao, Fu, Ermon, Rudra, Ré
논문 링크: https://arxiv.org/abs/2205.14135 .
대부분의 Transformer 논문은 self-attention을 달성하기 위해 원래의 스케일링된 내적 메커니즘을 교체하는 데 신경을 쓰지 않지만, 가장 최근에 인용된 메커니즘은 FlashAttention입니다.
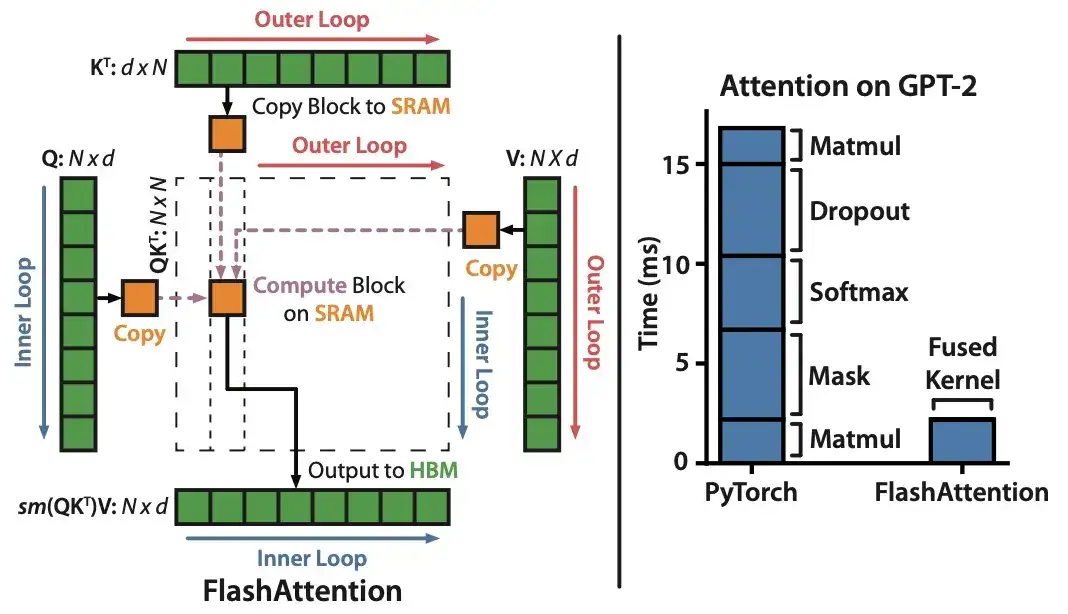
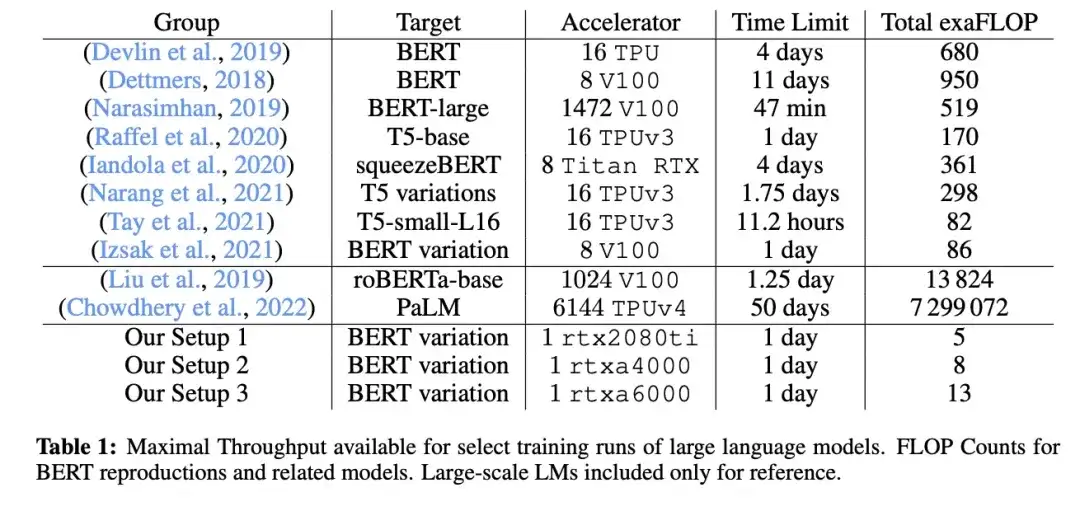
11. 크래밍: 단일 GPU에서 하루 만에 언어 모델 학습(2022)
_저자:_Geiping과 Goldstein,
논문 링크: https://arxiv.org/abs/2212.14034
이 논문에서 연구원들은 단일 GPU를 사용하여 마스크된 언어 모델/인코더 스타일의 대규모 언어 모델(여기서는 BERT)을 24시간 동안 훈련했습니다. 비교를 위해 2018년 원본 BERT 논문은 4일 동안 16개의 TPU에 대해 훈련되었습니다. 흥미로운 발견은 작은 모델이 더 높은 처리량을 가지더라도 덜 효율적으로 학습한다는 것입니다. 따라서 더 큰 모델은 특정 예측 성능 임계값에 도달하기 위해 더 긴 훈련 시간이 필요하지 않습니다.
12. LoRA: 대규모 언어 모델의 낮은 순위 적응(2021)
저자: Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen 작성
논문 링크: https://arxiv.org/abs/2106.09685 .
현대의 대규모 언어 모델은 대규모 데이터 세트에 대한 사전 교육을 통해 새로운 기능을 나타내며 언어 번역, 요약 생성, 프로그래밍, 질문 답변을 포함한 다양한 작업을 잘 수행합니다. 그러나 도메인별 데이터 및 전문 작업에 대한 기능을 향상시키기 위해 변환기를 미세 조정하는 데는 가치가 있습니다. LoRA(Low-Rank Adaptation)는 대규모 언어 모델의 매개변수 효율적인 미세 조정을 위한 가장 영향력 있는 방법 중 하나입니다.
효율적인 매개변수 미세 조정을 위한 다른 방법이 존재하지만 LoRA는 우아하고 매우 일반적이며 다른 유형의 모델에 적용될 수 있기 때문에 특별한 주의를 기울일 가치가 있습니다. 사전 훈련된 모델의 가중치는 사전 훈련된 작업에 대한 전체 순위를 갖는 반면, LoRA의 작성자는 대규모 언어 모델이 새로운 작업에 적응할 때 "내재적 차원성"이 낮다는 점에 주목합니다. 따라서 LoRA의 핵심 아이디어는 가중치 변화 ΔW를 하위 순위 표현으로 분해하여 더 높은 매개변수 효율성을 달성하는 것입니다.

13_. 축소에서 확장으로: 매개변수 효율적인 미세 조정을 위한 가이드(2022)_
저자: Lialin, Deshpande, Rumshisky
논문 링크: https://arxiv.org/abs/2303.15647 .
이 검토에서는 미세 조정 프로세스를 (극도로) 계산적으로 효율적으로 만드는 것을 목표로 효율적인 매개변수 미세 조정 방법(접두사 조정, 어댑터 및 낮은 순위 적응과 같은 널리 사용되는 기술을 다룸)에 대한 40개 이상의 논문을 검토합니다.
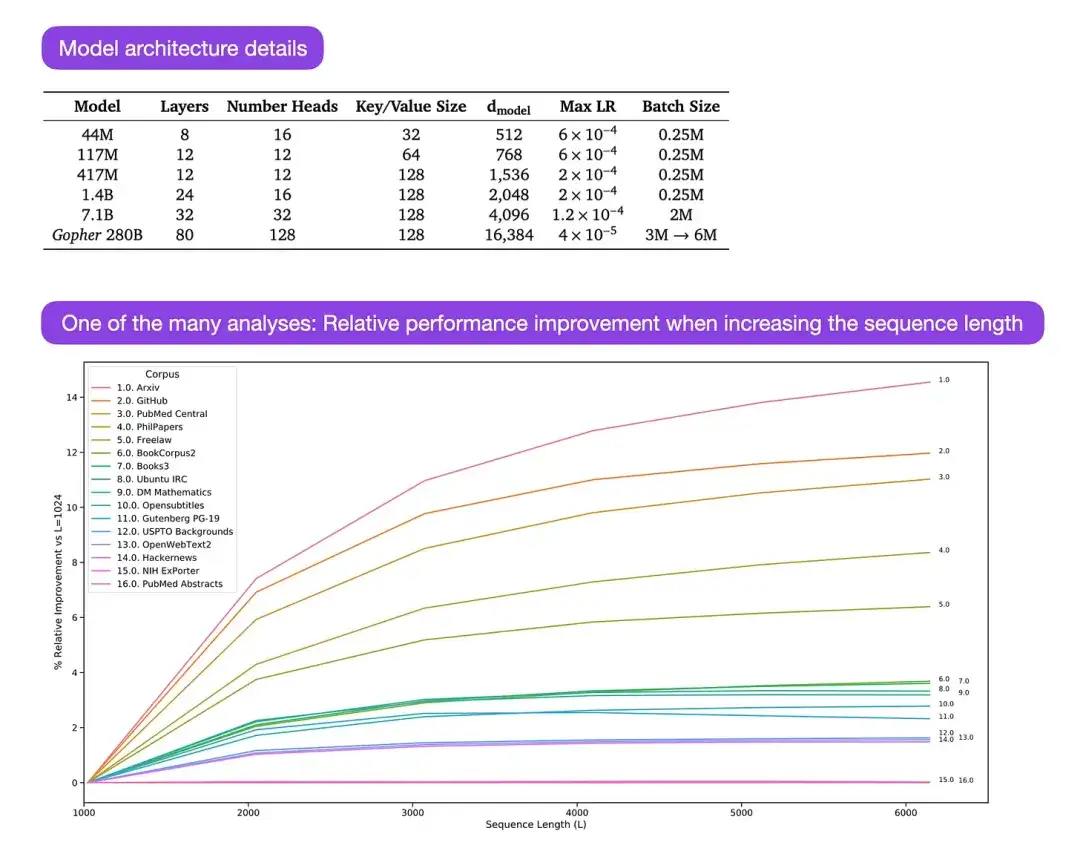
** 14. 언어 모델 확장: Gopher 교육의 방법, 분석 및 통찰력 (2022)** 작성자: Rae 및 78명의 동료
논문 링크: https://arxiv.org/abs/2112.11446
Gopher는 LLM(Large Language Model)의 학습 과정을 이해하기 위한 많은 분석이 포함된 특히 좋은 논문입니다. 연구원은 여기서 280B 매개변수와 80개 레이어로 모델을 훈련했습니다. 이 모델은 300B 토큰을 기반으로 훈련되었습니다. 여기에는 LayerNorm(레이어 정규화) 대신 RMSNorm(제곱평균제곱근 정규화)을 사용하는 등 몇 가지 흥미로운 아키텍처 개선 사항이 포함되어 있습니다. LayerNorm과 RMSNorm은 모두 배치 크기에 의존하지 않고 동기화가 필요하지 않기 때문에 BatchNorm보다 선호됩니다. 이는 분산 설정에서 더 작은 배치를 사용할 때 특히 유리합니다. 그러나 일반적으로 RMSNorm은 심층 아키텍처의 훈련 프로세스를 안정화하는 데 더 효과적이라고 믿어집니다.
이러한 흥미로운 세부 사항 외에도 본 논문의 주요 초점은 다양한 규모의 작업 성능을 분석하는 것입니다. 152개 다양한 작업을 평가한 결과, 모델 크기를 늘릴수록 이해력, 사실 확인, 유해 언어 식별 등의 작업에 가장 큰 개선 효과가 있는 것으로 나타났습니다. 그러나 논리적, 수학적 추론과 관련된 작업은 아키텍처 확장으로 인한 이점이 적습니다.
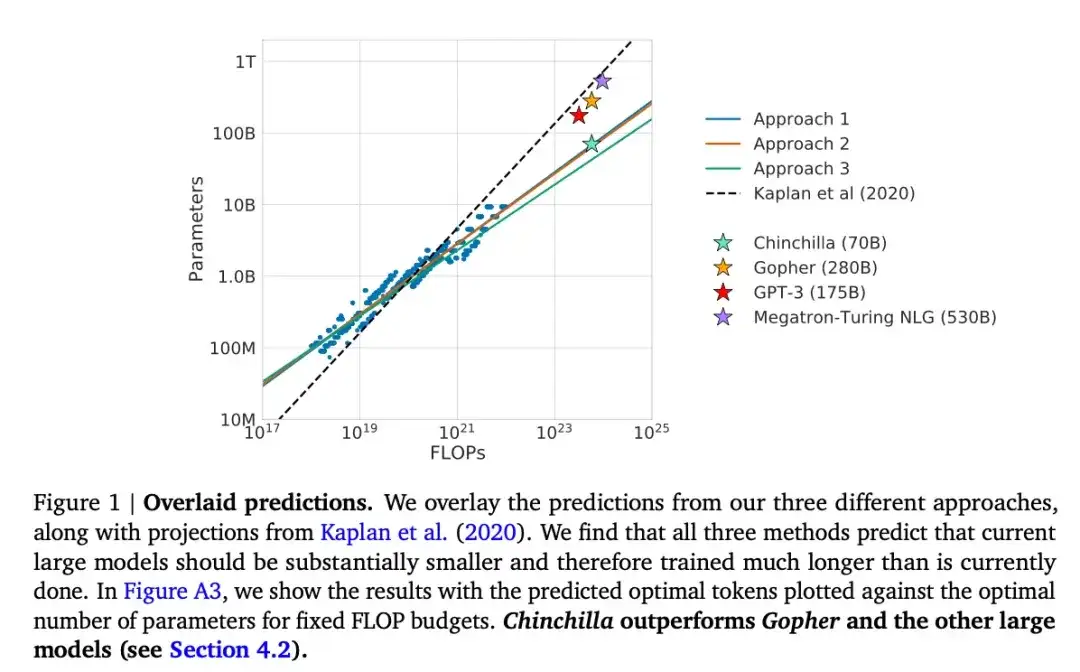
15. 컴퓨팅 최적의 대형 언어 모델 교육 (2022)
작곡: Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, Sifre
논문 링크: https://arxiv.org/abs/2203.15556 .
이 기사에서는 생성 모델링 작업에서 널리 사용되는 175B 매개변수 GPT-3 모델을 능가하는 Chinchilla라는 70B 매개변수 모델을 소개합니다. 그러나 핵심은 현재의 대규모 언어 모델이 "상당히 훈련이 부족하다"는 점을 지적하는 것입니다. 이 논문에서는 대규모 언어 모델 훈련을 위한 선형 확장 법칙을 정의합니다. 예를 들어 Chinchilla는 크기가 GPT-3의 절반에 불과하지만 (단지 3000억 개가 아닌) 1조 4000억 개의 토큰으로 훈련되었기 때문에 GPT-3를 능가합니다. 즉, 훈련 토큰의 수는 모델 크기만큼 중요합니다.
16.Pythia : 학습 및 확장 전반에 걸쳐 대규모 언어 모델을 분석하기 위한 제품군 (2023)
작곡: Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika, 和van der Wal
논문 링크: https://arxiv.org/abs/2304.01373
Pythia는 훈련 과정에서 대규모 언어 모델의 진화를 연구하도록 설계된 일련의 오픈 소스 대규모 언어 모델(700M에서 12B 매개변수 범위)입니다. 아키텍처는 GPT-3과 유사하지만 Flash Attention(LLaMA와 유사) 및 Rotary Positional Embeddings(PaLM과 유사)와 같은 몇 가지 개선 사항이 포함되어 있습니다. Pythia는 The Pile 데이터 세트(825Gb)에서 훈련되었으며 훈련에는 300B 토큰이 사용되었습니다(일반 PILE의 1 에포크 또는 중복 제거된 PILE의 1.5 에포크에 해당).
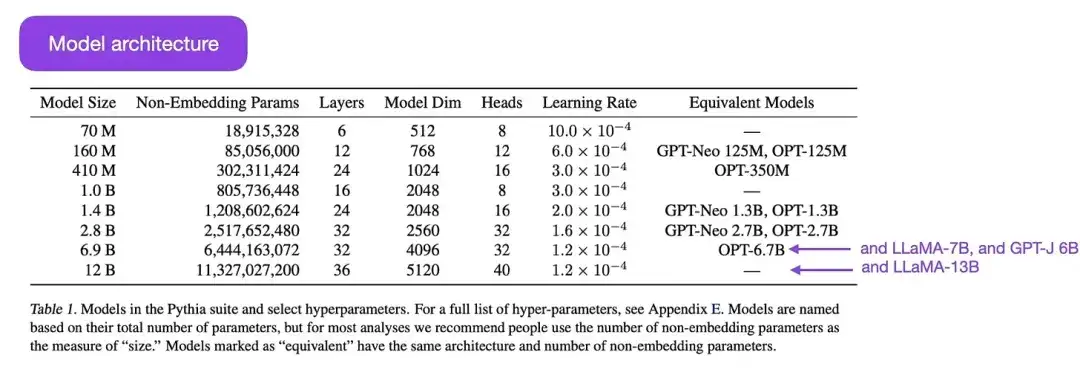
Pythia 연구의 주요 결과는 다음과 같습니다.
- 반복되는 데이터에 대한 훈련(대규모 언어 모델이 훈련되는 방식으로 인해 한 시대 이상에 대한 훈련을 의미함)은 성능에 도움이 되지도, 해를 끼치지도 않습니다.
- 훈련 순서는 기억 효과에 영향을 미치지 않습니다. 이는 불행한 일입니다. 그 반대가 사실이라면 훈련 데이터를 재정렬하여 바람직하지 않은 축어적 메모리 문제를 완화할 수 있기 때문입니다.
- 사전 훈련 중 단어 빈도는 작업 성능에 영향을 미칩니다. 예를 들어, 더 자주 나타나는 단어의 경우 샘플 수가 적을수록 정확도가 더 높아지는 경향이 있습니다.
- 배치 크기를 두 배로 늘리면 수렴에 영향을 주지 않고 훈련 시간이 절반으로 줄어듭니다.
정렬: 대규모 언어 모델을 원하는 목표와 관심 사항에 맞게 안내
최근 몇 년 동안 우리는 상대적으로 강력하고 사실적인 텍스트를 생성할 수 있는 다수의 대규모 언어 모델(GPT-3 및 Chinchilla 등)을 목격했습니다. 일반적으로 사용되는 사전 훈련 패러다임 하에서 달성할 수 있는 한계에 도달한 것 같습니다.
언어 모델을 더욱 유용하게 만들고 잘못된 정보와 유해한 언어의 생성을 줄이기 위해 연구원들은 사전 훈련된 기본 모델을 미세 조정하기 위한 추가 훈련 패러다임을 설계했습니다.
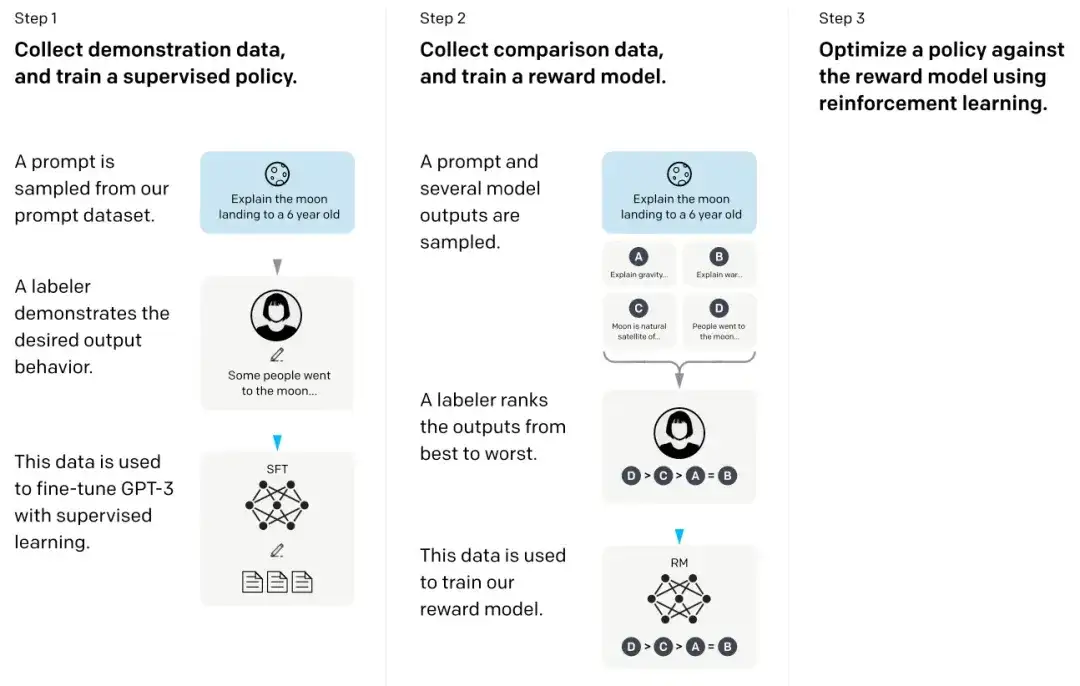
17. 인간의 피드백을 통해 지침을 따르도록 언어 모델 훈련 ****(2022)
작곡자: Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, 와 Lowe,
논문 링크: https://arxiv.org/abs/2203.02155 .
소위 InstructGPT 논문에서 연구원들은 인간 피드백(RLHF)과 결합된 강화 학습 메커니즘을 사용했습니다. 그들은 먼저 사전 훈련된 GPT-3 기본 모델을 사용하고 인간이 생성한 큐-응답 쌍에 대한 지도 학습을 통해 이를 추가로 미세 조정했습니다(1단계). 다음으로, 인간이 모델 출력의 순위를 매기도록 하여 보상 모델을 훈련했습니다(2단계). 마지막으로 보상 모델을 사용하여 근접 정책 최적화의 강화 학습 방법을 통해 사전 훈련되고 미세 조정된 GPT-3 모델을 업데이트했습니다(3단계).
덧붙여서, 이 논문은 ChatGPT의 기본 아이디어를 설명하는 논문으로도 간주됩니다. 최근 소문에 따르면 ChatGPT는 더 큰 데이터 세트로 미세 조정된 InstructGPT의 확장 버전입니다.
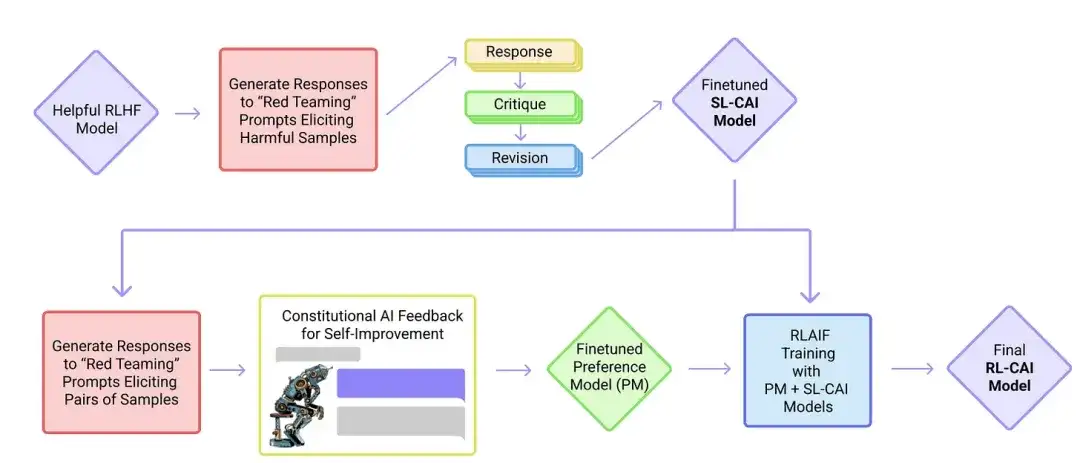
18. 헌법적 AI: AI 피드백의 무해성 (2022년 )
추천:Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann , Amodei, 조셉, McCandlish, 브라운, 카플란
논문 링크: https://arxiv.org/abs/2212.08073 .
본 논문에서 연구자들은 "정렬"이라는 개념을 더욱 발전시키고 "무해한" AI 시스템을 만들기 위한 훈련 메커니즘을 제안합니다. 연구자들은 직접적인 인간 감독 대신 인간이 제공하는 규칙 목록을 기반으로 하는 자가 훈련 메커니즘을 제안합니다. 위에서 언급한 InstructGPT 논문과 유사하게 제안하는 방법은 강화학습 방법을 사용합니다.
19. 자가 학습: 언어 모델을 자가 생성 명령어와 정렬 (2022)
논문의 저자: Wang, Kordi, Mishra, Liu, Smith, Khashabi 및 Hajishirzi
논문 링크: https://arxiv.org/abs/2212.10560
지침 미세 조정은 GPT-3과 같은 사전 훈련된 기본 모델에서 ChatGPT와 같은 보다 강력한 LLM으로 전환하는 방법입니다. databricks-dolly-15k와 같은 오픈 소스, 인간이 생성한 명령 데이터 세트는 이 프로세스를 가능하게 하는 데 도움이 될 수 있습니다. 그러나 규모를 달성하는 방법은 무엇입니까? 한 가지 접근 방식은 LLM이 자체 생성된 콘텐츠를 기반으로 부트스트랩 학습을 수행하도록 하는 것입니다.
Self-Instruct는 사전 학습된 LLM을 지침에 맞춰 조정하는 (주석이 거의 없는) 방법입니다. 이 과정은 어떻게 진행되나요? 간단히 말해서 다음 네 단계로 구성됩니다.
- 사람이 작성한 명령어 세트(이 경우 175개)와 샘플 명령어를 사용하여 작업 풀을 초기화합니다.
- 사전 훈련된 LLM(예: GPT-3)을 사용하여 작업 범주를 결정합니다.
- 새로운 지침의 경우 사전 훈련된 LLM이 응답을 생성하도록 하세요.
- 이러한 응답은 작업 풀에 추가되기 전에 수집, 필터링 및 필터링됩니다.
이러한 방식으로 자가 지시 방법은 수동 주석을 줄이면서 지시를 따르고 생성하는 사전 훈련된 언어 모델의 능력을 효과적으로 향상시켜 모델의 능력을 확장하고 최적화할 수 있습니다.
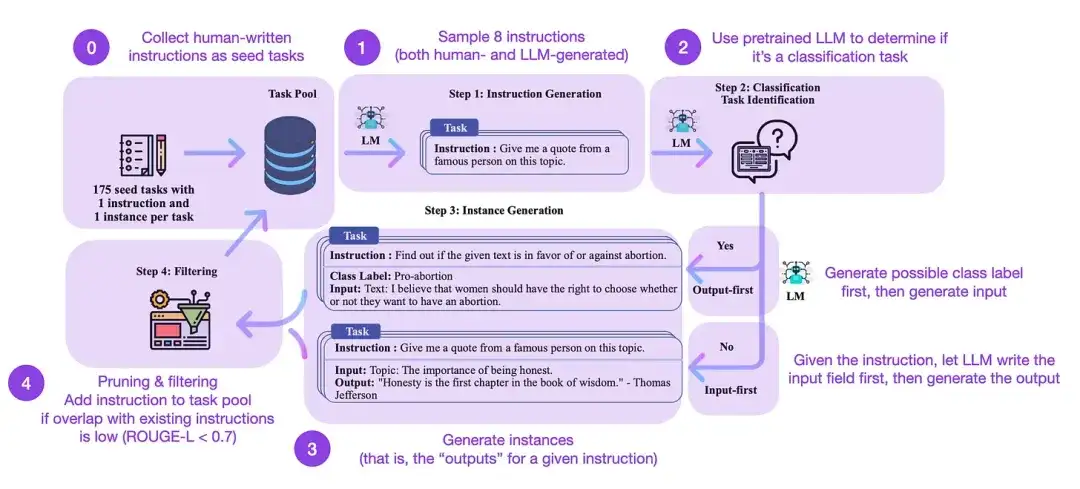
실제로 이 방법은 ROUGE 점수를 기준으로 비교적 잘 수행됩니다. 예를 들어, LLM(대형 언어 모델)의 자체 유도 미세 조정은 GPT-3 기본 모델보다 성능이 뛰어났으며 사람이 작성한 대규모 명령 세트에 대해 사전 훈련된 LLM과 경쟁할 수 있었습니다. 더욱이, 자가 안내는 인간의 지시에 따라 미세 조정된 LLM에도 도움이 될 수 있습니다.
물론 LLM 평가의 가장 좋은 기준은 인간 평가자가 참여하도록 초대하는 것입니다. 인간의 평가를 기반으로 하는 자가 유도 방법은 기본 LLM뿐만 아니라 감독 방식으로 인간 지시 데이터 세트에 대해 훈련된 LLM(예: SuperNI, T0 Trainer)을 뛰어넘습니다. 그러나 흥미롭게도 자기 지도는 인간 피드백(RLHF)을 통합한 강화 학습 방법을 통해 훈련된 사람들보다 뛰어난 성능을 발휘하지 못했습니다.
인간이 생성한 명령 데이터 세트와 자가 유도 데이터 세트 중 어느 것이 더 유망합니까? 나는 두 가지 모두에 대해 낙관적이다. databricks-dolly-15k의 15,000개 명령어와 같이 인간이 생성한 명령어 데이터 세트로 시작한 다음 이를 자체적으로 확장하는 것은 어떨까요?
강화 학습 및 인간 피드백(RLHF) 강화 학습 및 인간 피드백(RLHF)에 대한 자세한 설명과 RLHF 구현을 위한 근접 정책 최적화에 대한 관련 논문을 보려면 아래의 자세한 기사를 참조하세요.
연구 업데이트나 튜토리얼에서 LLM(대형 언어 모델)을 논의할 때 인간 피드백을 통한 강화 학습(RLHF)이라는 프로세스를 자주 언급합니다. RLHF는 인간의 선호도를 최적화 프레임워크에 통합하여 모델의 유용성과 안전성을 향상시킬 수 있기 때문에 현대 LLM 교육 파이프라인의 중요한 부분이 되었습니다.
전체 기사 읽기:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
결론 및 추가 자료
나는 현대 대규모 언어 모델의 설계, 한계 및 진화를 이해하는 상위 10개 논문(RLHF에 대한 3개 논문 포함)에 초점을 맞춰 위 목록을 간결하고 간결하게 유지하려고 노력했습니다. 추가적인 연구를 위해서는 위의 논문에서 인용된 문헌을 참고하는 것이 좋습니다. 다음은 몇 가지 추가 리소스입니다.
GPT에 대한 오픈 소스 대안:
- BLOOM: 176B 매개변수 개방형 액세스 다국어 언어 모델(2022), https://arxiv.org/abs/2211.05100
- OPT: 사전 훈련된 변환기 언어 모델 공개(2022), https://arxiv.org/abs/2205.01068
- UL2: 언어 학습 패러다임 통합(2022), https://arxiv.org/abs/2205.05131
ChatGPT 대안:
- LaMDA: 대화 응용 프로그램을 위한 언어 모델(2022), https://arxiv.org/abs/2201.08239
- (Bloomz) 멀티태스크 미세 조정을 통한 교차 언어 일반화(2022), https://arxiv.org/abs/2211.01786
- (참새) 표적화된 인간 판단을 통한 대화 에이전트의 정렬 개선(2022), https://arxiv.org/abs/2209.14375
- BlenderBot 3: 책임감 있게 참여하는 방법을 지속적으로 학습하는 배포된 대화 에이전트, https://arxiv.org/abs/2208.03188
바이오컴퓨팅의 대형 모델:
- ProtTrans: 자기 지도형 딥 러닝 및 고성능 컴퓨팅을 통해 생명 코드의 언어 해독을 향하여(2021), https://arxiv.org/abs/2007.06225
- AlphaFold를 통한 매우 정확한 단백질 구조 예측(2021), https://www.nature.com/articles/s41586-021-03819-2
- 대규모 언어 모델은 다양한 가족에 걸쳐 기능성 단백질 서열을 생성합니다(2023), https://www.nature.com/articles/s41587-022-01618-2
기사 추천
평균 월급은 46,000이 넘습니다! 하버드, 스탠포드, 마이크로소프트, 구글 등이 제작하는 AI 분야의 가장 중요한 강좌를 총정리!
AI와의 대화를 더욱 효과적으로 만드는 7가지 즉각적인 팁
모두가 개발자인 시대에도 프로그래밍을 배우는 것이 도움이 될까요?
침해가 있는 경우 당사에 연락하여 삭제하시기 바랍니다. 참조 링크:
https://magazine.sebastianraschka.com/p/understanding-large-언어-모델
우리를 따르라
OpenSPG:
공식 웹사이트: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
공식 웹사이트: https://openasce.openfinai.org/
GitHub: [https://github .com /Open-All-Scale-Causal-Engine/OpenASCE ]